Load mlir(mhlo/lmhlo) and execute on GPU
main.cc
#include "mlir/Dialect/Func/IR/FuncOps.h" // from @llvm-project
#include "mlir/Dialect/Arith/IR/Arith.h" // from @llvm-project
#include "mlir/Dialect/MemRef/IR/MemRef.h" // from @llvm-project
#include "mlir/Dialect/Bufferization/IR/Bufferization.h"
#include "llvm/Support/Debug.h"
#include "llvm/Support/SourceMgr.h"
#include "llvm/Support/FileUtilities.h"
#include "mlir/Support/FileUtilities.h"
#include "mlir/Parser/Parser.h"
#include "mlir/IR/MLIRContext.h" // from @llvm-project
#include "mlir/Target/LLVMIR/Dialect/LLVMIR/LLVMToLLVMIRTranslation.h" // from @llvm-project
#include "tensorflow/compiler/xla/stream_executor/device_memory.h"
#include "tensorflow/compiler/xla/service/backend.h"
#include "tensorflow/compiler/xla/service/executable.h"
#include "tensorflow/compiler/xla/service/gpu/gpu_compiler.h"
#include "tensorflow/compiler/xla/service/gpu/target_constants.h"
#include "tensorflow/compiler/xla/mlir_hlo/include/mlir-hlo/Dialect/mhlo/IR/hlo_ops.h"
#include "tensorflow/compiler/xla/mlir_hlo/include/mlir-hlo/Dialect/lhlo/IR/lhlo_ops.h"
// custom gpu compile library: mhlo -> hlo -> lmhlo -> GpuExecutable
#include "tensorflow/compiler/plugin/custom/gpu/gpu_backend.h"
namespace se = stream_executor;
void LoadMLIRDialects(mlir::MLIRContext& context) {
context.loadDialect<
mlir::arith::ArithDialect,
mlir::memref::MemRefDialect,
mlir::mhlo::MhloDialect,
mlir::lmhlo::LmhloDialect,
mlir::func::FuncDialect,
mlir::bufferization::BufferizationDialect
>();
mlir::registerLLVMDialectTranslation(context);
}
auto GetBackend(){
se::Platform* platform = se::MultiPlatformManager::PlatformWithName("CUDA").value();
xla::BackendOptions options;
options.set_platform(platform);
return xla::Backend::CreateBackend(options).value();
}
auto CachedBackend(){
// init on use, can not be initialized as a global variable
static std::shared_ptr<xla::Backend> backend = GetBackend();
return backend;
}
mlir::OwningOpRef<mlir::ModuleOp> readFromMlirFile(mlir::MLIRContext& context, const std::string& mlir_path){
std::string errorMessage;
auto file = mlir::openInputFile(mlir_path, &errorMessage);
if (!file) {
llvm::errs() << errorMessage << "\n";
return nullptr;
}
std::unique_ptr<llvm::MemoryBuffer> buffer = std::move(file);
// Tell sourceMgr about this buffer, which is what the parser will pick up.
llvm::SourceMgr sourceMgr;
sourceMgr.AddNewSourceBuffer(std::move(buffer), llvm::SMLoc());
// Prepare the parser config, and attach any useful/necessary resource handlers.
mlir::ParserConfig config(&context);
// Parse the input file and reset the context threading state.
mlir::OwningOpRef<mlir::ModuleOp> module(mlir::parseSourceFile<mlir::ModuleOp>(sourceMgr, config));
module->dump();
return module;
}
tsl::StatusOr<std::unique_ptr<xla::Executable>> CompileMlirModule(
std::shared_ptr<xla::Backend> backend,
mlir::ModuleOp module, se::Stream* stream) {
llvm::LLVMContext llvm_context;
auto llvm_module = std::make_unique<llvm::Module>("", llvm_context);
#if TENSORFLOW_USE_ROCM
llvm_module->setTargetTriple(xla::gpu::amdgpu::TargetTriple());
llvm_module->setDataLayout(xla::gpu::amdgpu::DataLayout());
#else
llvm_module->setTargetTriple(xla::gpu::nvptx::TargetTriple());
llvm_module->setDataLayout(xla::gpu::nvptx::DataLayout());
#endif
se::StreamExecutor* stream_exec = stream->parent();
xla::gpu::GpuDeviceInfo gpu_device_info = xla::gpu::GetGpuDeviceInfo(stream_exec);
xla::gpu::IrEmitterContext ir_emitter_context(
/*hlo_module=*/nullptr, /*buffer_assignment=*/nullptr,
backend->platform()->Name(), gpu_device_info,
stream_exec->GetDeviceDescription().cuda_compute_capability(),
stream_exec->GetDeviceDescription().rocm_compute_capability(),
/*mlir_context=*/nullptr, llvm_module.get());
xla::HloModuleConfig module_config;
module_config.set_debug_options(xla::GetDebugOptionsFromFlags());
return CompileLmhloToExecutable(
static_cast<xla::gpu::GpuCompiler*>(backend->compiler()), module, "TestModule",
module_config, xla::Compiler::CompileOptions(), "main", stream_exec,
std::move(llvm_module), &ir_emitter_context);
}
tsl::StatusOr<xla::ExecutionOutput> RunMlirModule(
std::shared_ptr<xla::Backend> backend,
mlir::ModuleOp module, se::Stream* stream,
absl::Span<const se::DeviceMemoryBase> arguments) {
TF_ASSIGN_OR_RETURN(auto executable, CompileMlirModule(CachedBackend(), module, stream));
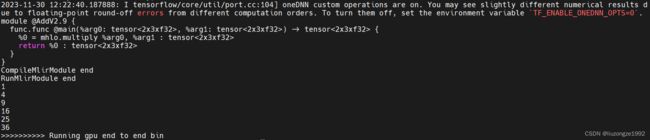
std::cout << "CompileMlirModule end\n";
xla::ExecutableRunOptions executable_run_options;
executable_run_options.set_stream(stream);
executable_run_options.set_allocator(backend->memory_allocator());
xla::ServiceExecutableRunOptions run_options(executable_run_options,
backend->StreamBorrower());
std::vector<xla::ExecutionInput> execution_inputs;
execution_inputs.reserve(arguments.size());
for (auto arg : arguments) {
xla::Shape shape =
xla::ShapeUtil::MakeShape(xla::U8, {static_cast<int64_t>(arg.size())});
execution_inputs.emplace_back(shape);
execution_inputs.back().SetBuffer({}, xla::MaybeOwningDeviceMemory(arg));
}
TF_ASSIGN_OR_RETURN(auto output,
executable->ExecuteAsyncOnStream(
&run_options, std::move(execution_inputs),
/*hlo_execution_profile=*/nullptr));
TF_CHECK_OK(stream->BlockHostUntilDone());
return std::move(output);
}
tsl::StatusOr<std::vector<std::vector<uint8_t>>>
RunMlirModuleWithHostBuffers(
std::shared_ptr<xla::Backend> backend,
mlir::ModuleOp lmhlo_module, std::vector<absl::Span<uint8_t>> arguments) {
auto* allocator = backend->memory_allocator();
std::vector<se::OwningDeviceMemory> owning_memory;
owning_memory.reserve(arguments.size());
for (auto host_buffer : arguments) {
owning_memory.push_back(
allocator
->Allocate(backend->default_device_ordinal(), host_buffer.size())
.value());
}
auto stream =
backend->BorrowStream(backend->default_device_ordinal()).value();
std::vector<se::DeviceMemoryBase> args;
for (int i = 0; i < owning_memory.size(); i++) {
se::DeviceMemoryBase memory(*owning_memory[i]);
stream->ThenMemcpy(&memory, static_cast<void*>(arguments[i].data()),
memory.size());
args.push_back(memory);
}
TF_ASSIGN_OR_RETURN(xla::ExecutionOutput output,
RunMlirModule(CachedBackend(), lmhlo_module, stream.get(), args));
std::cout << "RunMlirModule end\n";
std::vector<std::vector<uint8_t>> host_outputs;
for (const auto& result : output.Result().buffers().leaves()) {
host_outputs.emplace_back();
host_outputs.back().resize(result.second.size());
stream->ThenMemcpy(static_cast<void*>(host_outputs.back().data()),
result.second, result.second.size());
}
TF_CHECK_OK(stream->BlockHostUntilDone());
return host_outputs;
}
tsl::StatusOr<xla::ExecutionOutput> RunMlirModule(
mlir::MLIRContext& context,
std::shared_ptr<xla::Backend> backend,
mlir::OwningOpRef<mlir::ModuleOp> mhlo_module,
se::Stream* stream,
absl::Span<const se::DeviceMemoryBase> arguments) {
// TF_ASSIGN_OR_RETURN(auto executable, CompileMlirModule(CachedBackend(), module, stream));
TF_ASSIGN_OR_RETURN(auto executable, mygpu::custom_gpu_compile(nullptr, std::move(mhlo_module), context));
std::cout << "CompileMlirModule end\n";
xla::ExecutableRunOptions executable_run_options;
executable_run_options.set_stream(stream);
executable_run_options.set_allocator(backend->memory_allocator());
xla::ServiceExecutableRunOptions run_options(executable_run_options,
backend->StreamBorrower());
std::vector<xla::ExecutionInput> execution_inputs;
execution_inputs.reserve(arguments.size());
for (auto arg : arguments) {
xla::Shape shape =
xla::ShapeUtil::MakeShape(xla::U8, {static_cast<int64_t>(arg.size())});
execution_inputs.emplace_back(shape);
execution_inputs.back().SetBuffer({}, xla::MaybeOwningDeviceMemory(arg));
}
TF_ASSIGN_OR_RETURN(auto output,
executable->ExecuteAsyncOnStream(
&run_options, std::move(execution_inputs),
/*hlo_execution_profile=*/nullptr));
TF_CHECK_OK(stream->BlockHostUntilDone());
return std::move(output);
}
tsl::StatusOr<std::vector<std::vector<uint8_t>>>
RunMlirModuleWithHostBuffers(
mlir::MLIRContext& context,
std::shared_ptr<xla::Backend> backend,
mlir::OwningOpRef<mlir::ModuleOp> mhlo_module,
std::vector<absl::Span<uint8_t>> arguments
) {
auto* allocator = backend->memory_allocator();
std::vector<se::OwningDeviceMemory> owning_memory;
owning_memory.reserve(arguments.size());
for (auto host_buffer : arguments) {
owning_memory.push_back(
allocator
->Allocate(backend->default_device_ordinal(), host_buffer.size())
.value());
}
auto stream =
backend->BorrowStream(backend->default_device_ordinal()).value();
std::vector<se::DeviceMemoryBase> args;
for (int i = 0; i < owning_memory.size(); i++) {
se::DeviceMemoryBase memory(*owning_memory[i]);
stream->ThenMemcpy(&memory, static_cast<void*>(arguments[i].data()),
memory.size());
args.push_back(memory);
}
TF_ASSIGN_OR_RETURN(xla::ExecutionOutput output,
RunMlirModule(context, CachedBackend(), std::move(mhlo_module), stream.get(), args));
std::cout << "RunMlirModule end\n";
std::vector<std::vector<uint8_t>> host_outputs;
for (const auto& result : output.Result().buffers().leaves()) {
host_outputs.emplace_back();
host_outputs.back().resize(result.second.size());
stream->ThenMemcpy(static_cast<void*>(host_outputs.back().data()),
result.second, result.second.size());
}
TF_CHECK_OK(stream->BlockHostUntilDone());
return host_outputs;
}
template <typename T>
static absl::Span<uint8_t> ToUint8Span(std::vector<T>* v) {
return absl::Span<uint8_t>(reinterpret_cast<uint8_t*>(v->data()),
v->size() * sizeof(T));
}
template <typename T>
static absl::Span<const T> FromUint8Span(absl::Span<const uint8_t> span) {
CHECK_EQ(0, span.size() % sizeof(T));
return absl::Span<const T>(reinterpret_cast<const T*>(span.data()),
span.size() / sizeof(T));
}
int main(){
mlir::MLIRContext context;
LoadMLIRDialects(context);
std::vector<float> arg0 = {1,2,3,4,5,6};
auto path = "add-mhlo.mlir";
mlir::OwningOpRef<mlir::ModuleOp> module = readFromMlirFile(context, path);
auto outputs = RunMlirModuleWithHostBuffers(context, CachedBackend(), std::move(module), {ToUint8Span(&arg0), ToUint8Span(&arg0)}).value();
// auto path = "add-lmhlo.mlir";
// mlir::OwningOpRef module = readFromMlirFile(context, path);
// auto outputs = RunMlirModuleWithHostBuffers(CachedBackend(), module.get(), {ToUint8Span(&arg0), ToUint8Span(&arg0)}).value();
auto floats = FromUint8Span<float>(outputs[0]);
std::cout << floats[0] << "\n";
std::cout << floats[1] << "\n";
std::cout << floats[2] << "\n";
std::cout << floats[3] << "\n";
std::cout << floats[4] << "\n";
std::cout << floats[5] << "\n";
std::cout << ">>>>>>>>>> Running gpu end to end bin" << "\n";
return 0;
}
bazel 配置:
tf_cc_binary(
name = "gpu_bin",
testonly = True,
srcs = [
"main.cc",
],
deps = [
":gpu_backend",
"@llvm-project//llvm:Support",
"@llvm-project//mlir:AllPassesAndDialects",
"@llvm-project//mlir:IR",
"@llvm-project//mlir:MlirOptLib",
"@llvm-project//mlir:Pass",
"@llvm-project//mlir:Support",
],
)