扩散模型实战(十四):扩散模型生成音频
推荐阅读列表:
扩散模型实战(一):基本原理介绍
扩散模型实战(二):扩散模型的发展
扩散模型实战(三):扩散模型的应用
扩散模型实战(四):从零构建扩散模型
扩散模型实战(五):采样过程
扩散模型实战(六):Diffusers DDPM初探
扩散模型实战(七):Diffusers蝴蝶图像生成实战
扩散模型实战(八):微调扩散模型
扩散模型实战(九):使用CLIP模型引导和控制扩散模型
扩散模型实战(十):Stable Diffusion文本条件生成图像大模型
扩散模型实战(十一):剖析Stable Diffusion Pipeline各个组件
扩散模型实战(十二):使用调度器DDIM反转来优化图像编辑
扩散模型实战(十三):ControlNet结构以及训练过程
在之前的文章中,我们主要介绍了扩展模型在文本生成和文本生成图像的应用,本文将介绍在音频领域的应用。
一、安装环境
!pip install -q datasets diffusers torchaudio accelerateimport torch, randomimport numpy as npimport torch.nn.functional as Ffrom tqdm.auto import tqdmfrom IPython.display import Audiofrom matplotlib import pyplot as pltfrom diffusers import DiffusionPipelinefrom torchaudio import transforms as ATfrom torchvision import transforms as IT
二、从预训练的音频扩散模型Pipeline中进行采样
加载预训练好的音频扩散模型Audio Diffusion(用于生成音频的梅尔谱图)
# 加载一个预训练的音频扩散模型管线device = "cuda" if torch.cuda.is_available() else "cpu"pipe = DiffusionPipeline.from_pretrained("teticio/audio-diffusion-instrumental-hiphop- 256").to(device)Fetching 5 files: 0%| | 0/5 [00:00
对pipe进行一次采样
# 在管线中采样一次并将采样结果显示出来output = pipe()display(output.images[0])display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))
采样结果,如下图所示:

上述代码中,rate参数表示音频的采样率,下面我们查看一下音频序列和频谱
# 音频序列output.audios[0].shape# 输出(1, 130560)
# 输出的图像(频谱)output.images[0].size# 输出(256, 256)
音频并非由扩散模型直接生成的,而是类似于无条件图像生成管道那样,使用一个2D UNet网络结构来生成音频的频谱,之后经过后处理转换为最终的音频。
三、从音频转换为频谱
音频的”波形“在时间上展示了源音频,例如,音频的”波形“可能是从麦克风接收到的电信号。这种”时域“上的表示处理起来比较棘手,因此通常会转换为频谱来处理,频谱能够直接展示不同频率(y轴)和时间(x轴)的强度。
# 使用torchaudio模块计算并绘制所生成音频样本的频谱,如图8-2所示spec_transform = AT.Spectrogram(power=2)spectrogram = spec_transform(torch.tensor(output.audios[0]))print(spectrogram.min(), spectrogram.max())log_spectrogram = spectrogram.log()lt.imshow(log_spectrogram[0], cmap='gray');tensor(0.) tensor(6.0842)
频谱图,如下所示:

以上图刚刚生成的音频样本为例,频谱的取值范围是0.0000000000001~1,其中大部分值接近取值下限,这对于可视化和建模来说不太理想,为此,我们使用了梅尔频谱(Mel spectrogram)对不同频率进行一些变换来符合人耳感知特性,下图展示了torchaudio音频转换方法:
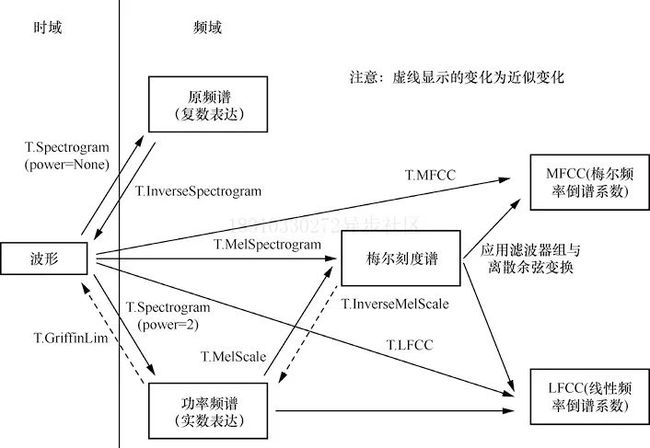
幸运的是,我们使用mel功能可以忽略这些细节,就能吧频谱转换成音频:
a = pipe.mel.image_to_audio(output.images[0])a.shape# 输出(130560,)
读取源音频数据,然后调用audio_slice_to_image()函数,将源音频数据转换为频谱图像。同时较长的音频片段也会自动切片,以便可以正常输出256X256像素的频谱图像,代码如下:
pipe.mel.load_audio(raw_audio=a)im = pipe.mel.audio_slice_to_image(0)im

音频被表示成一长串数字数组。若想播放音频,我们需要采样率这个关键信息。
我们查看一下单位时间音频的采样点有多少个?
sample_rate_pipeline = pipe.mel.get_sample_rate()sample_rate_pipeline# 输出22050
如果设置别的采样率,那么会得到一个加速或者减速播放的音频,比如:
display(Audio(output.audios[0], rate=44100)) # 播放速度被加倍四、微调音频扩散模型数据准备
在了解了音频扩散模型Pipeline使用之后,我们在新的数据集上对其进行微调,我们使用的数据集由不同类别的音频片段集合组成的,代码如下:
from datasets import load_datasetdataset = load_dataset('lewtun/music_genres', split='train')dataset
查看一下该数据集不同类别样本所占的比例:
for g in list(set(dataset['genre'])):print(g, sum(x==g for x in dataset['genre']))
输出内容如下:
Pop 945Blues 58Punk 2582Old-Time / Historic 408Experimental 1800Folk 1214Electronic 3071Spoken 94Classical 495Country 142Instrumental 1044Chiptune / Glitch 1181International 814Ambient Electronic 796Jazz 306Soul-RnB 94Hip-Hop 1757Easy Listening 13Rock 3095
该数据集已将音频存储为数组,代码如下:
audio_array = dataset[0]['audio']['array']sample_rate_dataset = dataset[0]['audio']['sampling_rate']print('Audio array shape:', audio_array.shape)print('Sample rate:', sample_rate_dataset)# 输出Audio array shape: (1323119,)Sample rate: 44100
PS:该音频的采样率更高,要使用该Pipeline,就需要对其进行”重采样“。音频也比Pipeline预设的长度要长,在调用pipe.mel加载该音频时,会被自动切片为较短的片段。代码如下:
a = dataset[0]['audio']['array'] # 得到音频序列pipe.mel.load_audio(raw_audio=a) # 使用pipe.mel加载音频pipe.mel.audio_slice_to_image(0) # 输出第一幅频谱图像

sample_rate_dataset = dataset[0]['audio']['sampling_rate']sample_rate_dataset# 输出44100
从上述代码结果可以看出,该数据集的数据在每一秒都拥有两倍的数据点,因此需要调整采样率。这里我们使用torchaudio transforms(导入为AT)进行音频重采样,并使用Pipeline的mel功能将音频转换为频谱图像,然后使用torchvision transforms(导入为IT)将频谱图像转换为频谱张量。一下代码中的to_image()函数可以将音频片段转换为频谱张量,供训练使用:
resampler = AT.Resample(sample_rate_dataset, sample_rate_pipeline,dtype=torch.float32)to_t = IT.ToTensor()def to_image(audio_array):audio_tensor = torch.tensor(audio_array).to(torch.float32)audio_tensor = resampler(audio_tensor)pipe.mel.load_audio(raw_audio=np.array(audio_tensor))num_slices = pipe.mel.get_number_of_slices()slice_idx = random.randint(0, num_slices-1) # 每次随机取一张(除了# 最后那张)im = pipe.mel.audio_slice_to_image(slice_idx)return im
整理微调数据
def collate_fn(examples):# 图像→张量→缩放至(-1,1)区间→堆叠audio_ims = [to_t(to_image(x['audio']['array']))*2-1 for x inexamples]return torch.stack(audio_ims)# 创建一个只包含Chiptune/Glitch(芯片音乐/电子脉冲)风格的音乐batch_size=4 # 在CoLab中设置为4,在A100上设置为12chosen_genre = 'Electronic' # <<< 尝试在不同的风格上进行训练 <<<indexes = [i for i, g in enumerate(dataset['genre']) if g ==chosen_genre]filtered_dataset = dataset.select(indexes)dl = torch.utils.data.DataLoader(filtered_dataset.shuffle(), batch_size=batch_size,collate_fn=collate_fn, shuffle=True)batch = next(iter(dl))print(batch.shape)# 输出torch.Size([4, 1, 256, 256])
五、开始微调音频扩散模模型
epochs = 3lr = 1e-4pipe.unet.train()pipe.scheduler.set_timesteps(1000)optimizer = torch.optim.AdamW(pipe.unet.parameters(), lr=lr)for epoch in range(epochs):for step, batch in tqdm(enumerate(dl), total=len(dl)):# 准备输入图片clean_images = batch.to(device)bs = clean_images.shape[0]# 为每一张图片设置一个随机的时间步timesteps = torch.randint(0, pipe.scheduler.num_train_timesteps, (bs,),device=clean_images.device).long()# 按照噪声调度器,在每个时间步为干净的图片加上噪声noise = torch.randn(clean_images.shape).to(clean_images.device)noisy_images = pipe.scheduler.add_noise(clean_images,noise, timesteps)# 得到模型的预测结果noise_pred = pipe.unet(noisy_images, timesteps, return_dict=False)[0]# 计算损失函数loss = F.mse_loss(noise_pred, noise)loss.backward(loss)# 使用优化器更新模型参数optimizer.step()optimizer.zero_grad()# 装载之前训练好的频谱样本,如图8-6所示pipe = DiffusionPipeline.from_pretrained("johnowhitaker/Electronic_test").to(device)output = pipe()display(output.images[0])display(Audio(output.audios[0], rate=22050))# 输入一个不同形状的起点噪声张量,得到一个更长的频谱样本,如图8-7所示noise = torch.randn(1, 1, pipe.unet.sample_size[0],pipe.unet.sample_size[1]*4).to(device)output = pipe(noise=noise)display(output.images[0])display(Audio(output.audios[0], rate=22050))
生成的频谱,如下图所示:

生成更长的频谱样本,如下图所示:

思考:
-
我们使用的是256X256像素的方形频谱图像,这会限制batch size,能否从128X128像素的频谱图像中恢复出质量足够好的音频呢?
-
为了替代随机图像增强,我们每次都挑选了不同的音频片段,但这种方法在训练循环后期是否可以用其他增强方法进行优化呢?
-
是否有其他办法可以用来生成更长的音频呢?或者可以先生成开头的5s音频,之后再采用类似图像修复的思路继续生成后续的音频。
-
扩散模型生成的内容与Img2Img生成的内容有什么相同之处?