DataFrame和Series的索引
一直对dataframe和series的索引弄得不清楚,现在梳理一下:
如何创建一个df?
pd.DataFrame(data, index = XX, columns=XXX)
data是必须的参数,注意,要使data作为一个整体,而不能是:
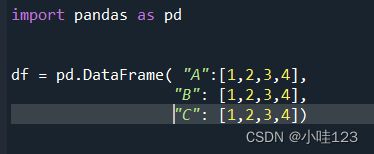 ,因为逗号前面的是date,注意正确传参。
,因为逗号前面的是date,注意正确传参。
df的数据来源有多种,可以从列表,词典,集合,数组等,只要有符合要求的数据,都可以创建df。下面看一下不同数据来源形成的df:
【list形成的df】
pd.DataFrame(df数据源)
#----------df from list------------
lst = [1,2,3,4,5]
df = pd.DataFrame(lst)
print(type(df))
df虽然只有一列,但是仍然是一个datafram,并不是series,因为在一开始创建的时候,就指定了
是df,而不是series
ser = df.iloc[:, 0]
print(type(ser))
这里相当于取了df的某行或某列中的某些部分,所以会得到一个series,虽然在内容上和df是一样的。
【多层list形成的df】
多层list形成的df,list中的每个元素(list)按行进行排序,对应位置上没有元素的,填为nan。
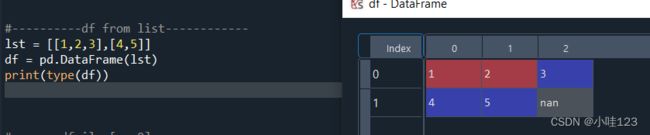
通过index和columns指定df的index名称和列名:

如果对于一个多列列表,希望列表中的每个元素能够作为df中的列,那么可以使用transpose:

下面来看用dict转化成的df:
dict的键就是df的columns,注意:对于dict形成的df,dict的key就是df的column
看一下面的结果:
import pandas as pd
dic1 = {"key1": [1,2,3,4],
"key2": [5,6,7,8],}
dic2 = {"key3": [3,3,3,3],
"key4": [4,4,4,4],}
a = [dic1]
print(len(a))
# 转换为DataFrame
df = pd.DataFrame(dic1)
df1 = pd.DataFrame([dic1])
df2 = pd.DataFrame([[dic1]])
df3 = pd.DataFrame([dic1, dic2])
df4 = pd.DataFrame([[dic1, dic2]])
逐条分析:
df = pd.DataFrame(dic1):典型的df数据来自于词典:词典的key就是df的column,value依次展开:
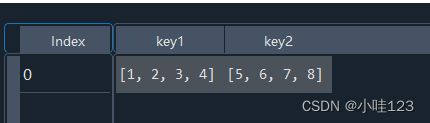
df1 = df1 = pd.DataFrame([dic1]): 把=将dic1放在一个list中,df的来源是一个list,这个list中有只有一个元素,也就是dic1,相当于把dic1当成一个元素来处理,整体都作为df的一行:
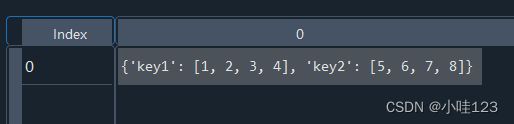
df2 = pd.DataFrame([[dic1]]): 两层列表,相当于列表中只有一个元素,就是【dic1】,这相当于直接把【dic1】作为df的一个值,也就是把整个词典放在一起,作为一个元素:
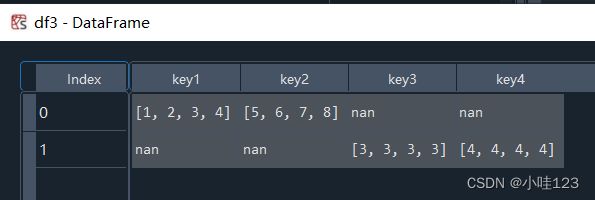
df3 = pd.DataFrame([dic1, dic2]):
这个相当于df的数据来源是一个具有多个元素的列表,也就是这是一个词典列表,对于多个词典列表组成的df:如下,就是这么处理的:注意,这里没有把key对应的value再展开
lst1 = [1,[2,3]]
lst2 = [[4,5],6]
lst3 = [[7],8,9]
lst = [lst1, lst2, lst3]
df_lst = pd.DataFrame(lst)
df_lst1 = pd.DataFrame(lst1)
df_lst11 = pd.DataFrame([lst1])看一下下面的输出吧:
df_lst:把嵌套列表中的元素平铺
df_lst1: 按照列进行排布
df_lst11:将lst1作为一个整体去排布,一行两列

主要是很多规则就是这样的,要记住。
查找df中的元素:
以此df为例:
df的列名索引:df["column1"]
df.iloc[行索引数字,列索引数字]
df.loc[行索引名称,列索引名称]
df的bool条件索引:df[ bool表达式 ]
df[df["column"]>1],这其实也是条件索引
df.loc[行标签,列标签]:一定是中间有个逗号的,注意,一定是既有行标签,也有列标签。
df.iloc也是这样,必须有行索引和列索引。
通过np.array对df以列为单位进行整体计算
np.array可以很方便的对df的某些列进行计算
如何讲df的某列转化以一个array:array = df["column"].values
(通过.values即可。)
使用np.array进行计算:np.sin( array), np.cos(array)等,通常前面会加上np.fuc( array_para),
如果是四则运算一般就直接写加减乘除符号就可以了。
报错:A value is trying to be set on a copy of a slice from a DataFrame
这个报错常出现在对一个切片进行操作的时候,因为系统不确定是对原始的数据进行改变还是对切片形成的新个体进行改变。
合并多个df:
pd.concat([df, df2,df3], other_para), 第一个参数是要合并的所有df,注意为什么非要加个[], 而不是直接把要合并的df直接写上呢?因为不同情况下要合并的df的数量不一样啊,直接放会引起混乱,从如何方便使用函数的角度想想,一般都是放在一个整体中的,除非有那种明确的,这个函数的作用就是支队固定个数的参数进行操作,那样才有可能是相对“随意”的方式,因为在别处固定了。就像merge,一般是对两个df进行merge,所以可以写成pd.merge(df2, df2, on=...)
df的索引:
pandas之行列选择 - 代码先锋网 (codeleading.com)
Pandas数据选取中df[]、df.loc[]、df.iloc[]、df.at[]、df.iat[]的区别及用法-CSDN博客
import pandas as pd
import numpy as np
data = {'name': ['Joe', 'Mike', 'Jack', 'Rose', 'David', 'Marry', 'Wansi', 'Sidy', 'Jason', 'Even'],
'age': [25, 32, 18, np.nan, 15, 20, 41, np.nan, 37, 32],
'gender': [1, 0, 1, 1, 0, 1, 0, 0, 1, 0],
'isMarried': ['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(data, index=labels)
df[ ],这种索引方式是一次性完成的,也就是只接受行或者列的判断条件,不会把行和列一起判断,
只选择满足条件的行或者只选择满足条件的列。
df.iloc和df.loc既看行的条件,也看列的条件,当对列没有条件时, ,: 可以省略。
df.iloc和df.loc对某行或者某列的结果,会得到一个series。
df对某列的筛选结果也会得到一个series,对某行还是一个df。
df.loc可以结合标签索引设置条件,df.iloc不能结合标签索引设置条件。
特定的行或者,写在[]中,比如[1,2]或者["name", "age"],
如果shi某个范围内的选择,直接写0:3或者"name" : "age"就可以了,
比如:ss = df.loc[:, "name" : "gender"]
a = df[0:1] #df 取第一行
b = df.iloc[0, :] #series 取第一行,得到一个series
zs = df.iloc[:, 1] #series 取第二列,得到一个series
sf = df.loc[:, "name"] #series 得到name列的series
e = df.loc["a", ["name", "age"]]#df
f = df.loc[["a", "b"], ["name", "age"]] #df
b1 = df.iloc[0] #series
c = df.loc["a", :] #series
c1 = df.loc["a"] #series
#c和c1:用df.loc和df.iloc,当没有对列的要求时,这两种表达方式是一样的
k = df["name"] #取“name”列,是一个series
#用df.iloc或者df.loc取某行或者某列的数据,将会得到一个series。
#如果用df取某行或者某列的数据,
#取前两行
front_lin2_1 = df.iloc[0: 2, :] #df
front_lin2_2 = df[0: 2]
#取前三行
front_lin2_3 = df[[True,True,True,False,False,False,False,False,False,False]]
# 选取所有age大于30的行
s = df[df["age"] > 35] #df, 即使只有一行
#选择某两行
g = df.loc[["a", "c"]] #特定的行的名称用[ ],形成一个列表
#选择某行到某行
x = df.loc["a" : "c"] #范围,直接写就可以,不需要在 [ ]中。
#注意g,x 两种表达方式的差别,一个表示求某个范围内的,另一个表示哪些特定的行或者列的标签索引或者整数索引。
#什么时候会得到一个series: df.loc取某行或者某列/df.iloc取某行或者某列/df取某列,得到的结果是series。
#用df取某一行,得到的结果是一个df。
cd = df.loc[df['age']>30,:] #df.loc还可以用标签索引进行判断
cd1 = df.loc[df['age']>30] #和上面是一样的
# cd2 = df.iloc[df['age']>30] #df.iloc不能用标签索引作为判断,报错:
#ValueError: iLocation based boolean indexing cannot use an indexable as a mask
ef1 = df.iloc[:,[True,True,True,False]] #这样直接给出true或者false是可以的,但是不能把标签
#索引和df.iloc一起用。
ss = df.loc[:, "name" : "gender"]
#------------------------------------------------------------
data = {'name': ['Joe', 'Mike', 'Jack', 'Rose', 'David', 'Marry', 'Wansi', 'Sidy', 'Jason', 'Even'],
'age': [25, 32, 18, np.nan, 15, 20, 41, np.nan, 37, 32],
'gender': [1, 0, 1, 1, 0, 1, 0, 0, 1, 0],
'isMarried': ['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']}
df = pd.DataFrame(data)
c = df.loc[0:2, ["name", "age"]]
c1 = df.loc["0":"2", ["name", "age"]] #c=c1
对于没有index label的df,也可以使用df.loc,并且对于行的索引,用数字和用字符是一样的。
对于df.loc 有范围的索引,是前闭后闭的,对于df.loc是前闭后开的。
如何判断筛选的时候用什么样的筛选条件:
1.如果是只对行或者列进行选择,那么用df就可以。
2.如果是即对行有条件,也对列有条件,那么可以用df.iloc或者df.loc
需要用到标签索引,用df.loc,需要用到整数索引,用df.iloc.
用df.iloc的时候不能出现行/列的标签判断条件。
df.iloc前闭后开,df.loc前闭后闭。
用df取某一列,得到series, 用df.iloc或者df.loc取某行或者某列,得到series。series的取值:
import pandas as pd
import numpy as np
data = {'name': ['Joe', 'Mike', 'Jack', 'Rose', 'David', 'Marry', 'Wansi', 'Sidy', 'Jason', 'Even'],
'age': [25, 32, 18, np.nan, 15, 20, 41, np.nan, 37, 32],
'gender': [1, 0, 1, 1, 0, 1, 0, 0, 1, 0],
'isMarried': ['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(data, index=labels)
s = df["name"]
# series取某个index的值
a = s["a"]
b = s.loc["a"]
c = s.iloc[0]
# 取series的值形成列表
lst = s.tolist()
#index的list
aa = s.index.tolist()