Python开发运维:Python 3.8 常用标准库
目录
一、理论
1.Python3.8 标准库
2.常用标准库
二、问题
1.Python 正则表达式如何实现
一、理论
1.Python3.8 标准库
(1)官网
Python 标准库 — Python 3.8.17 文档
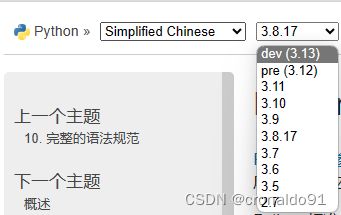
(2)其他版本下拉列表查询
2.常用标准库
(1)分类
表1 常用标准库分类
| 模块 | 描述 |
| os | 操作系统管理 |
| sys | 解释器交互 |
| platform | 操作系统信息 |
| glob | 查找文件 |
| shutil | 文件管理 |
| random | 随机数 |
| subprocess | 执行Shell命令 |
| pickle | 对象数据持久化 |
| json | JSON编码和解码 |
| time | 时间访问和转换 |
| datetime | 日期和时间 |
| urllib | HTTP访问 |
(2)标准库os
表2 os库主要对目标和文件操作
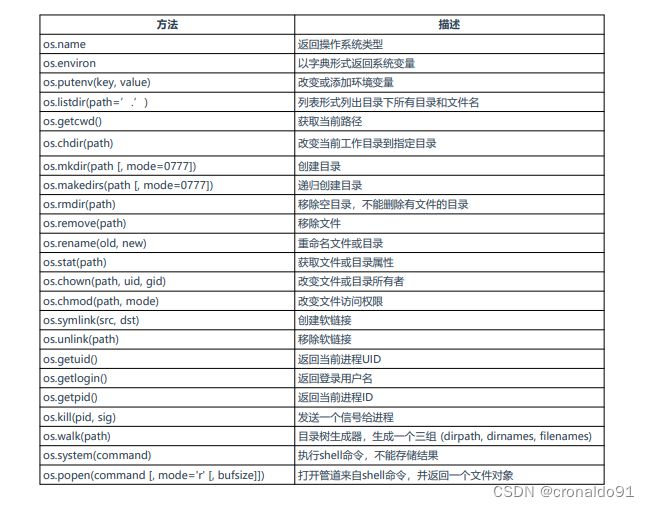
表3 os.path类用于获取文件属性

(3)标准库sys
表4 sys库用于与Python解释器交互

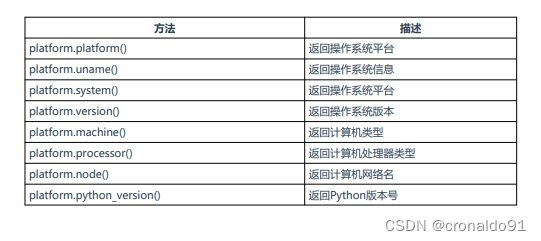
(4)标准库platform
表5 platform库用于获取操作系统详细信息
(5)标准库glob
glob库用于文件查找,支持通配符(*、?、[])
(6)标准库random
表6 random库用于生成随机数

(7)标准库subprocess
表7 subprocess库用于执行Shell命令
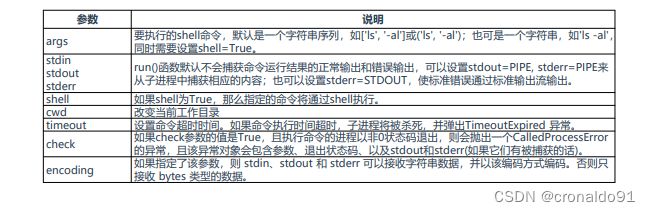
subprocess库用于执行Shell命令,工作时会fork一个子进程去执行任务,连接到子进程的标准输入、输出、错误,并获得
它们的返回代码。
这个模块将取代os.system、os.spawn*、os.popen*、popen2.*和commands.*。
subprocess的主要方法:
subprocess.run(),subprocess.Popen(),subprocess.call
语法:subprocess.run(args, *, stdin=None, stdout=None, stderr=None, shell=False, cwd=None, timeout=None,
check=False, encoding=None)(8)标准库pickle
pickle模块实现了对一个Python对象结构的二进制序列化和反序列化。
主要用于将对象持久化到文件存储。
pickle模块主要有两个函数:
1)dump() 把对象保存到文件中(序列化),使用load()函数从文件中读取(反序列化)
2)dumps() 把对象保存到内存中,使用loads()函数读取
(9)标准库json
JSON是一种轻量级数据交换格式,一般API返回的数据大多是JSON、XML,如果返回
JSON的话,需将获取的数据转换成字典,方面在程序中处理。
json与pickle有相似的接口,主要提供两种方法:
1)dumps() 对数据进行编码
2)loads() 对书籍进行解码
(10)标准库time
表8 time库用于满足简单的时间处理
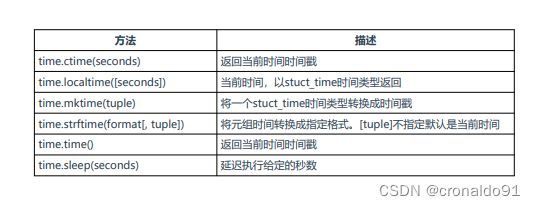
time库用于满足简单的时间处理,例如获取当前时间戳、日期、时间、休眠。
(11)标准库:datetime
表9 datetime库用于处理更复杂的日期和时间
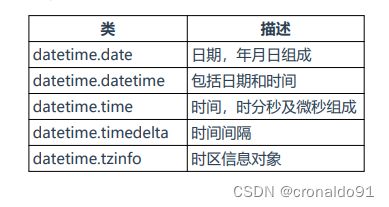
(12)标准库urllib
urllib包含以下类:
1)urllib.request 打开和读取 URL,用的最多,它定义了适用于在各种复杂情况下打开 URL,例如基本认证、重定向、Cookie、代理等
2)urllib.error 包含 urllib.request 抛出的异常
3)urllib.parse 用于解析 URL
4)urllib.robotparser 用于解析 robots.txt 文件
表10 res是一个HTTPResponse类型的对象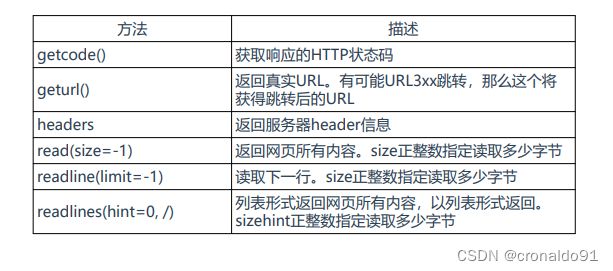
二、问题
1.Python 正则表达式如何实现
(1)re 标准库
表1 re标准库
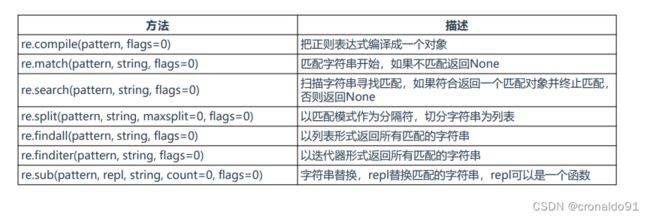
Python正则表达式主要由re标准库提供,拥有了基本所有的表达式。(2)re.compile方法
语法:re.compile(pattern, flags=0)
pattern 指的是正则表达式。flags是标志位的修饰符,用于控制表达式匹配模式(3)re.match()方法
语法:re.match(pattern, string, flags=0)
(4)代表字符
表2 字符表达式

(5)原始字符串符号“r”
“r”表示原始字符串,有了它,字符串里的特殊意义符号就会自动加转义符。
(6)代表数量
表3 数量表达式

(7)代表分组
表4 分组表达式

(8)贪婪和非贪婪匹配
1)贪婪模式:尽可能最多匹配
2)非贪婪模式:尽可能最少匹配,一般在量词(*、+)后面加个?问号就是非贪婪模式。(9)其他方法
表5 其他方法
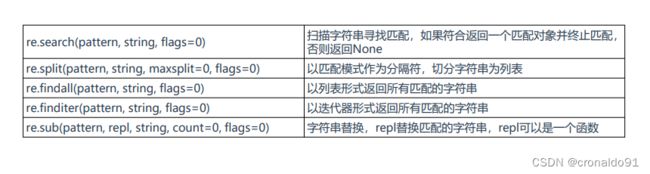
(10)标志位
表6 标志位
