Hadoop高可用(主备切换)---配合Zookeeper
1. Hadoop高可用(Hadoop High Availability)概述
HA(High Available), 高可用,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,分为活动节点(Active)及备用节点(Standby)。通常把正在执行业务的称为活动节点(Active),而作为活动节点的一个备份的则称为备用节点(Standby)。当活动节点出现问题,导致正在运行的业务(任务)不能正常运行时,备用节点此时就会侦测到,并立即接续活动节点来执行业务。从而实现业务的不中断或短暂中断。
hadoop2.x之后,Cloudera提出了QJM/Qurom Journal Manager,这是一个基于Paxos算法(分布式一致性算法)实现的HDFS HA方案,它给出了一种较好的解决思路和方案。
QJM主要优势如下:
1.不需要配置额外的高共享存储,降低了复杂度和维护成本。
2.消除spof(单点故障)。
3.系统鲁棒性(Robust)的程度可配置、可扩展。
2. 高可用服务
框架以及原理
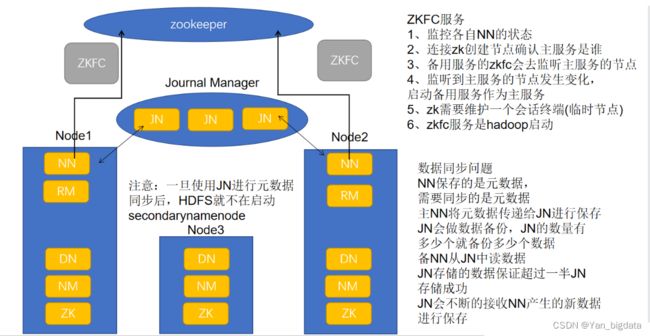
在HA架构里面SecondaryNameNode已经不存在了,为了保持standby NN实时的与Active NN的元数据保持一致,他们之间交互通过JournalNode进行操作同步。
任何修改操作在 Active NN上执行时,JournalNode进程同时也会记录修改log到至少半数以上的JN中,这时 Standby NN 监测到JN 里面的同步log发生变化了会读取 JN 里面的修改log,然后同步到自己的目录镜像文件里面
当发生故障时,Active的 NN 挂掉后,Standby NN 会在它成为Active NN 前,读取所有的JN里面的修改日志,这样就能高可靠的保证与挂掉的NN的目录镜像文件一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的。
在HA模式下,datanode需要确保同一时间有且只有一个NN能命令DN。为此:每个NN改变状态的时候,向DN发送自己的状态和一个序列号。
DN在运行过程中维护此序列号,当failover时,新的NN在返回DN心跳时会返回自己的active状态和一个更大的序列号。DN接收到这个返回则认为该NN为新的active。
如果这时原来的active NN恢复,返回给DN的心跳信息包含active状态和原来的序列号,这时DN就会拒绝这个NN的命令。
JournalNode进程作用: 任何修改操作在 Active NN上执行时,JournalNode进程同时也会记录修改log到至少半数以上的JN中,这时 Standby NN 监测到JN 里面的同步log发生变化了会读取 JN 里面的修改log,然后同步到自己的目录镜像文件里面
DFSZKFailoverController进程作用:
1. 健康监测:周期性的向它监控的NN发送健康探测命令,从而来确定某个NameNode是否处于健康状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于一个不健康的状态。
2.会话管理:如果NN是健康的,zkfc就会在zookeeper中保持一个打开的会话,如果NameNode同时还是Active状态的,那么zkfc还会在Zookeeper中占有一个类型为短暂类型的znode,当这个NN挂掉时,这个znode将会被删除,然后备用的NN将会得到这把锁,升级为主NN,同时标记状态为Active。
3.master选举:通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机制,从而判断那个NameNode为Active状态。
4.当宕机的NN新启动时,它会再次注册zookeper,发现已经有znode锁了,便会自动变为Standby状态,如此往复循环,保证高可靠。
Failover Controller
HA模式下,会将FailoverController部署在每个NameNode的节点上,作为一个单独的进程用来监视NN的健康状态。
Failover Controller主要包括三个组件:
HealthMonitor: 监控NameNode是否处于unavailable或unhealthy状态。当前通过RPC调用NN相应的方法完成。
ActiveStandbyElector: 监控NN在ZK中的状态。
ZKFailoverController: 订阅HealthMonitor 和ActiveStandbyElector 的事件,并管理NN的状态,另外zkfc还
负责解决fencing(也就是脑裂问题)。
每台服务器上的节点/服务
HDFS
NN: NameNode
DN: DataNode
YARN
RM: ResourceManager
NM: NodeManager
Zookeeper
JN: JournalNode
ZK: ZooKeeper
ZKFC: DFSZKFailoverController

3. 启动Hadoop高可用环境
命令启动
# 1.先恢复快照到高可用环境
# 2.三台服务器启动zookeeper服务
[root@node1 ~]# zkServer.sh start
[root@node2 ~]# zkServer.sh start
[root@node3 ~]# zkServer.sh start
# 3.在node1中启动hadoop集群
[root@node1 ~]# start-all.sh
# 4.检查服务
[root@node1 ~]# jps
[root@node2 ~]# jps
[root@node3 ~]# jps
每台虚拟机上的服务进程

4. NameNode高可用
web链接:
node1:50070
node2:50070
可以使用kill -9 NN进程号把其中主服务杀掉,观察效果,然后使用 hdfs --daemon start namenode 重启,再次观察效果

5. ResourceManager高可用
web链接:
node1:8088
node2:8088
可以使用kill -9 RM进程号把其中主服务杀掉,观察效果,然后使用 yarn --daemon start resourcemanager 重启,再次观察效果
注意: 两个服务同时启动,按照上述链接去访问会自动跳到同一个主节点页面
