SparkSQL运行流程浅析
写了有相当长一段时间的SparkSQL了,所以结合网上其他大神的分析,写一篇文章,谈谈我对SparkSQL整个运行流程的一个简单的理解。哈哈,毕竟程序员要做到知其然,还要知其所以然不是。 SparkSQL的核心是Catalyst,SQL语句的解析以及最终执行计划的运行都是Catalyst来实现的,所以对SparkSQL的学习就是对Catalyst的学习。
SparkSQL(Catalys)整体流程介绍:
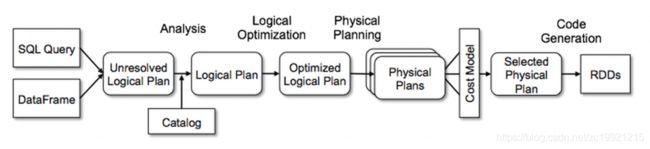
无论是使用 SQL语句还是直接使用 DataFrame 或者 DataSet 算子,都会经过Catalyst一系列的分析和优化,最终转换成高效的RDD的操作,主要流程如下:
1. sqlParser 解析 SQL,生成 Unresolved Logical Plan(未解析的逻辑计划)
2. 由 Analyzer 结合 Catalog 信息生成 Resolved Logical Plan(解析的逻辑计划)
3. Optimizer根据预先定义好的规则(RBO),对 Resolved Logical Plan 进行优化并生成 Optimized Logical Plan(优化后的逻辑计划)
4. Query Planner 将 Optimized Logical Plan 转换成多个 Physical Plan(物理计划)。然后由CBO 根据 Cost Model 算出每个 Physical Plan 的代价并选取代价最小的 Physical Plan 作为最终的 Physical Plan(最终执行的物理计划)
5. Spark运行物理计划,先是对物理计划再进行进一步的优化,最终映射到RDD的操作上,和Spark Core一样,以DAG图的方式执行SQL语句。 在最新的Spark3.0版本中,还增加了Adaptive Query Execution功能,会根据运行时信息动态调整执行计划从而得到更高的执行效率
整体的流程图如下所示:
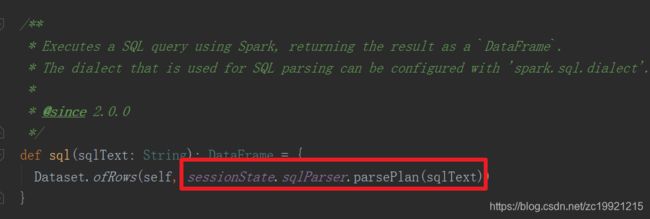
sqlParser 解析 SQL语句,得到Unresolved Logical Plan:
主要是借助于Antlr4这个强大的组件,识别SQL语句中的关键词,然后把SQL语句解析成一颗语法树。例如SQL语句: SELECT * FROM (SELECT * FROM src) a join (select * from src)b on a.key=b.key解析之后,会得到如下这样的一棵树:
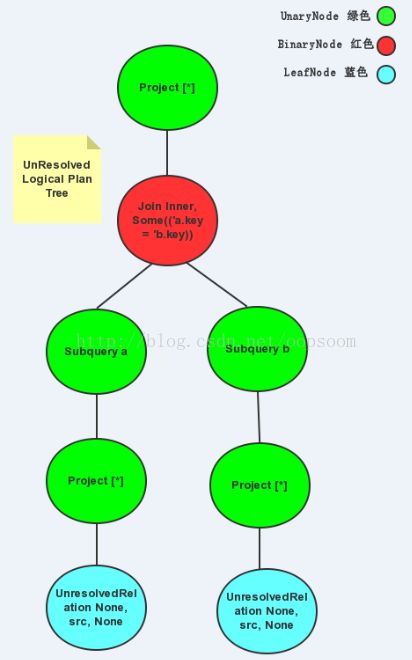
树中的每一个节点的数据结构是LogicalPlan,它是TreeNode类的子类。TreeNode类是非常基础且重要的一个类,语法树中的各类节点的具体实现类都是它的子类,TreeNode类内部定义遍历树的方法。LogicalPlan继承了TreeNode,它增加了一些对于表达式Expression操作的方法,Expression是指不需要执行引擎计算,而可以直接计算或处理的节点,例如Cast操作、Porjection操作、四则运算和逻辑操作符运算等等。
上图中的BinaryNode(二元节点)、 UnaryNode(一元节点)、 Leaf Node(叶子节点)是LogicalPlan的子类,它们分别代表了不同类型的操作,例如Join对应的是BinaryNode,Filter对应的是UnaryNode,AddJarCommand/AddFileCommand对应的是叶子节点等等...
解析成树的代码有点复杂...以后时间再研究了,这个不是当前我要关心的重点。接下来的Analyse、Optimizer、SparkPlan等等后续操作都在这个qe对象中进行了,qe对象全称是QueryExecution:

Analyzer 结合 Catalog 信息生成 Resolved Logical Plan:
Analyzer会使用事先定义好的一些规则(Rule)以及Catalog 等信息对 Unresolved Logical Plan 进行解析。解析的目的是确定表对应的字段是否存在,字段类型是啥,数据存储的具体位置等等。 Rule也是用来解析SQL语句中的一些信息,所有的Rule如下所示:
lazy val batches: Seq[Batch] = Seq( Batch("Hints", fixedPoint, new ResolveHints.ResolveBroadcastHints(conf), ResolveHints.ResolveCoalesceHints, ResolveHints.RemoveAllHints), Batch("Simple Sanity Check", Once, LookupFunctions), Batch("Substitution", fixedPoint, CTESubstitution, WindowsSubstitution, EliminateUnions, new SubstituteUnresolvedOrdinals(conf)), Batch("Resolution", fixedPoint, ResolveTableValuedFunctions :: ResolveRelations :: ResolveReferences :: ResolveCreateNamedStruct :: ResolveDeserializer :: //解析反序列化方式 ResolveNewInstance :: ResolveUpCast :: ResolveGroupingAnalytics :: ResolvePivot :: //解析pivot函数 ResolveOrdinalInOrderByAndGroupBy :: ResolveAggAliasInGroupBy :: ResolveMissingReferences :: ExtractGenerator :: ResolveGenerate :: ResolveFunctions :: ResolveAliases :: ResolveSubquery :: ResolveSubqueryColumnAliases :: ResolveWindowOrder :: ResolveWindowFrame :: ResolveNaturalAndUsingJoin :: ResolveOutputRelation :: ExtractWindowExpressions :: GlobalAggregates :: ResolveAggregateFunctions :: TimeWindowing :: ResolveInlineTables(conf) :: ResolveHigherOrderFunctions(catalog) :: ResolveLambdaVariables(conf) :: ResolveTimeZone(conf) :: ResolveRandomSeed :: TypeCoercion.typeCoercionRules(conf) ++ extendedResolutionRules : _*), Batch("Post-Hoc Resolution", Once, postHocResolutionRules: _*), Batch("Nondeterministic", Once, PullOutNondeterministic), Batch("UDF", Once, HandleNullInputsForUDF), //解析UDF Batch("FixNullability", Once, FixNullability), Batch("Subquery", Once, UpdateOuterReferences), Batch("Cleanup", fixedPoint, CleanupAliases) )
多个类似的Rule是封装在同一个Batch中的,每个Batch会被执行一次或者多次。停止执行Batch的条件有两个:一是在执行一定次数后发现Plan没有变化,二是执行次数达到了一定的上限 。这些Rule在真正应用时,是在RuleExecutor.scala类中执行的,在execute方法里就是遍历这些Batchs,将所有的规则应用到LogicalPlan上:
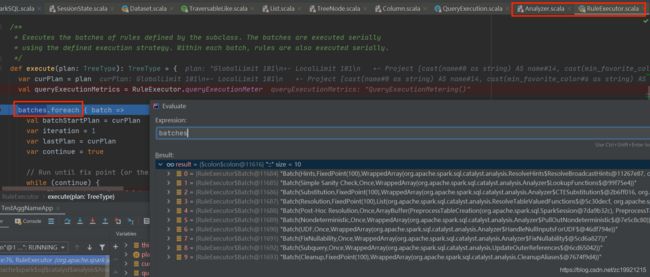
这些Rule是如何应用到LogicalPlans上的,具体的实现在各个Rule实现类的apply方法中,太多了......
Optimizer 对 Resolved Logical Plan进行优化:
Optimizer的执行流程和上面Analyzer的执行流程几乎一模一样。这个阶段的优化器主要是基于启发式规则(Rule-based Optimizer,简称 RBO)对LogicalPlan进行优化,规则举例有:列裁剪、谓词下推、常量累加等等。具体的Rule在Optimizer.scala的 defaultBatches 变量中,执行时也是在RuleExecutor中执行的,规则太多了,就不列举了...
Physical Plan生成:
经过上述一系列处理之后,接下来就是生成真正可以执行的Physical Plans。但是Spark会生成多个Physical Plans,然后再通过代价模型(Cost Model)得到"最优的"物理计划:
但是代码的注释里又明确的有说: // TODO: We use next(), i.e. take the first plan returned by the planner, here for now, // but we will implement to choose the best plan.从源码注释中可以看到,实际上选取的是这些Physical Plans中的第一个...所以并不一定是最优的那个
LogicalPlan生成Physical Plan的时候,是经过下面一些Strategy的优化之后得到的。例如下面的JoinSelection,内部就是选择Join方式再运行时,到底是使用BHJ、SHJ、SMJ中的哪一种:
override def strategies: Seq[Strategy] = experimentalMethods.extraStrategies ++ extraPlanningStrategies ++ ( PythonEvals :: DataSourceV2Strategy :: FileSourceStrategy :: DataSourceStrategy(conf) :: SpecialLimits :: Aggregation :: Window :: JoinSelection :: InMemoryScans :: BasicOperators :: Nil)
最后的最后,我们就得到了一个比较高效的PhysicalPlan(数据结构的实现类是SparkPlan),准备拿着这个物理计划开始运行了。
Physical Plan的执行:
经过上述一系列处理之后,接下来就是正式的进行物理计划的执行了。但是执行之前还要先执行prepareForExecution方法,进一步做一些优化工作,然后才是真正的去执行RDD。吐槽下,SparkSQL优化工作真的是太多了,真是厉害佩服!具体有如下这些优化规则:
/** A sequence of rules that will be applied in order to the physical plan before execution. */ protected def preparations: Seq[Rule[SparkPlan]] = Seq( PlanSubqueries(sparkSession),//生成子查询 EnsureRequirements(sparkSession.sessionState.conf),//根据分区数量是否变化,适时的插入Shuffle操作 CollapseCodegenStages(sparkSession.sessionState.conf),//全代码生成,将多个操作放在同一个方法中执行,减少函数的调用 ReuseExchange(sparkSession.sessionState.conf),//重复使用Shuffle数据 ReuseSubquery(sparkSession.sessionState.conf))//重复使用子查询结果/** * 使用上面这些规则,对SparkPlan进行进一步的优化 * Prepares a planned [[SparkPlan]] for execution by inserting shuffle operations and internal * row format conversions as needed. */ protected def prepareForExecution(plan: SparkPlan): SparkPlan = { preparations.foldLeft(plan) { case (sp, rule) => rule.apply(sp) } }
优化之后,SparkPlan就真的真的是最最终待执行的计划了(当然,Spark3.0中的AQE自适应再执行的过程中还会优化一波...)。SparkPlan树中的节点都是***Exec后缀的节点,***Exec就是各种操作的具体实现了:

比如这里的HiveTableScanExec节点,就是用来执行Hive表的扫描;FilterExec就是用来执行Filter操作。
至此,SQL语句就正式转换成对RDD的操作,正式运行起来了!
参考:
https://blog.csdn.net/oopsoom/article/details/38084079(TreeNode类解析,TreeNode是各种Plan的父类)
https://zhuanlan.zhihu.com/p/267425728(SparkSQL解析过程中对Tree遍历源码解析)
https://juejin.cn/post/6844904181178826766(Spark Web UI上的各种执行计划节点对应的含义)
https://zhuanlan.zhihu.com/p/367590611(Code Generator的作用)