【玩转 TableAgent数据智能分析】-数据分析师的大模型
【玩转 TableAgent数据智能分析】-数据分析师的大模型
-
- 九章云极DataCanvas介绍
- TableAgent的新手入门指南:
-
- 官网首页
- 立刻体验
- 问题测试
-
- 问题1:
- 问题2:
- 问题3:
- 问题4:
- 问题5:
- 通用大模型对比分析
-
- 对csv数据集的支持比较:
-
- TableAgent对csv格式支持情况测试:
- 文心一言对csv格式支持情况测试:
- Chatglm2对csv格式支持情况测试:
- 数据分析支持测试:
-
- 问题1:
- 问题2:
- 问题3:
- 问题4:
- 问题5:
- 个人总结与建议:
本文是笔者关于TableAgent的使用心得,内容涵盖九章云极DataCanvas介绍、从零开始使用到友商产品评测,对新手友好。
九章云极DataCanvas介绍
对人工智能基础软件公司有了解的朋友可能听说九章云极,本文介绍的TableAgent就是九章云极DataCanvas推出的产品。
2023年国际权威机构Forrester发布了“首份中国人工智能/机器学习平台报告”,该报告调研了国内市场14家主流云厂商,包括百度智能云、阿里云、华为云、腾讯云等,从产品能力、战略规划和市场表现三个方面对其进行评测。基于25项细分标准的全面评估,Forrester将这14家主流厂商划分为4个象限:领导者、优秀表现者、竞争者和挑战者。其中九章云极DataCanvas位于竞争者象限。

据IDC发布的《中国人工智能软件2022年市场份额》报告。其中,2022年机器学习开发平台市场规模达35.4亿元人民币。其中第四范式(32.7%)、华为云(21.6%)、九章云极(7.6%)、创新奇智(7.0%)居中国机器学习开发平台市场前四。
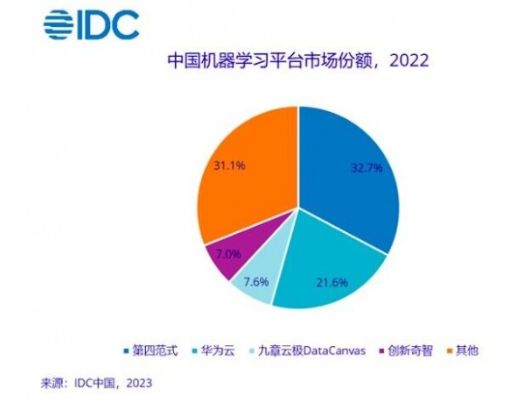
九章云极DataCanvas在大模型引领的新AI时代到来时,也进行了大模型的相关探索,推出自主研发的 DataCanvas Alaya九章元识大模型。而DataCanvas Alaya九章元识大模型也是TableAgent具有智能的基础。
下面开始介绍对于一个新手,该如何使用TableAgent。

TableAgent的新手入门指南:
TableAgent的公测链接地址为https://tableagent.datacanvas.com/,进入首页后,可以点击立即体验。

刚了解的朋友们先别点击立刻体验,稍等片刻,一般我们使用一个产品,都可以先看看官网的首页介绍,比如
XX比XX快几百倍
比如XX可以存储数十亿行数百万列等。
官网首页
官网首页介绍的是:
TableAgent是新AI时代的数据分析智能体
基于DataCanvas Alaya九章元识大模型,为你打造专属的数据分析师
我们咬文嚼字的说明下这个介绍啊:
第1句:TableAgent是产品的名称,新AI时代表明大模型出现的AI时代,数据分析智能体是TableAgent的功能介绍。初步判断TableAgent是可以自主做数据分析的智能体。
第2句:DataCanvas Alaya九章元识大模型是九章云极 DataCanvas自主研发的大模型,TableAgent数据分析智能体是基于 DataCanvasAlaya九章元识大模型的。所以TableAgent具备大模型的通用智能,这非常合理。
大模型出来后被传说最可以替代的几种行业中,就有数据分析师(也就是我的职业),所以我必须深入了解下TableAgent,这也十分合理。
立刻体验
现在点击立刻体验
进入注册环节,正常输入手机号就可以,需要注意的是,我用火狐注册会频繁提示:

这时可以切换edge浏览器,然后就顺利完成了,注册后,会提示有5次提问环节,次数使用完了,可以认证申请增加次数(每天15次)。


跳转后进入如下页面:
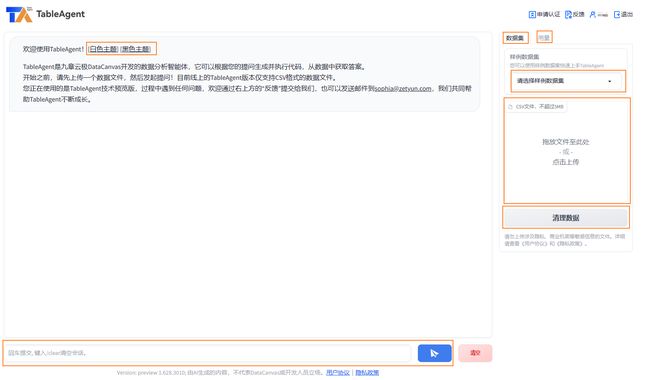
我们先从样例数据集进行快速测试,选择右侧的样例数据集,选择”银行客户流失预警数据集”

在左侧居中的对话区域会给出数据集的一些可能的分析,点击详情会显示数据集信息,内容如下:
数据中有多少客户,流失客户占比多少?
帮我统计流失客户主要集中在哪些年龄段
在持卡年限达8年以上的客户中,信用评分前10%和后10%的哪个群体流失率比较高?能否画图分析
从不同国家平均存款余额来看,第一名和第二名是否拉开较大差距?
帮我找出德国客诉率最高的卡片类型,画图并说说都有什么差异和建议
我想重点分析一下德国大部分客户收入水平如何,包括收入的最大、最小、平均水平以及不同收入水平的人数等方面,也画下图并说说
不考虑存款为0和流失的客户,客户的存款余额是否呈现明显的长尾分布?
从积分点来看,青年客户是否是主力军?帮忙画个饼状图
按照持卡年限,可以统计每年新增客户量,给出每年新增客户量同比
年龄段划分标准:45岁以下为青年,45-59岁为中年,60岁往上是老年,帮我拉一下每个客户的姓名、性别、国家以及年龄段

问题测试
问题1:
英语不优秀的数据分析师赶紧让TableAgent解释下数据集的相关字段含义:
请介绍下数据集中各个字段的含义,用中文描述,并描述各个字段的数据范围
返回结果如下:
可以查看到TableAgent对各个字段进行了介绍,点击回复中的详情,能看到TableAgent分析思考的步骤(好家伙,写了一段代码,会写程序的数据分析师):

经过分析,上面提示的部分问题信息可能不存在与数据表中,如客户的教育水平,原始数据集中并没有,但如果你问这个问题,TableAgent会提示你相关列不存在,如下。
问题2:
根据客户的教育水平,分析客户流失率是否有明显的差异。
返回结果如下:

这点还是比较严谨的,没有大模型的随意发挥现象,比较符合数据分析需求。
接下来问一个数据探索的问题。
问题3:
根据客户的预计薪资,绘制薪资水平分布,并绘制可视化图标
返回结果如下:

从结果可以看出,薪资分布没有明显的峰值,说明各个阶段的薪资收入都有大量的人。
接下来问一个数据预测的问题。
问题4:
根据客户的预计薪资,预测不同薪资对银行用户流失的影响。
返回结果如下:

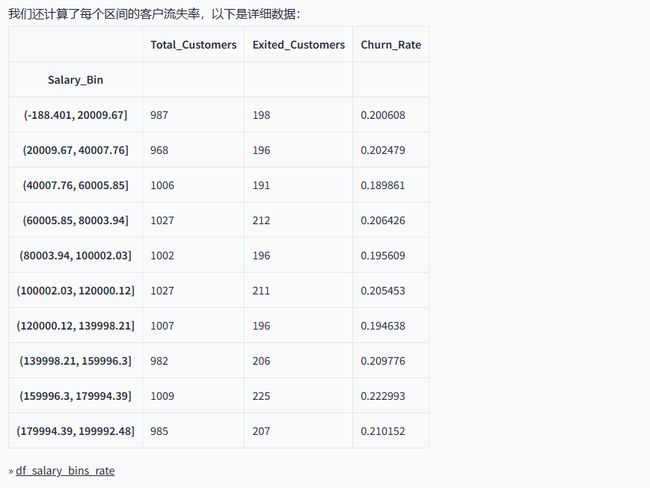
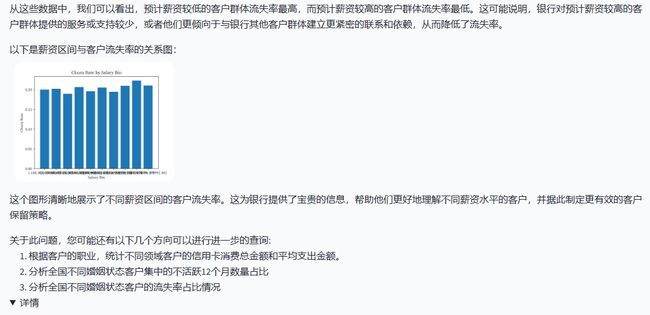
结果符合预期,点击详情,还可以看到明确的代码,用户可以根据代码自行调整。
最后再问一个让TableAgent发挥的问题,这个问题有一个问题就是需要TableAgent了解相关与因果推断的差别。
问题5:
请你自行对数据集进行探索性分析,并给出影响客户流失权重较大的几个因素,进行因果推断。
返回结果如下:

返回的结果还是有参考意义的。目前进入到第5个问题后,点击右侧的用量标签,会发现当前用户的剩余使用情况,如下:
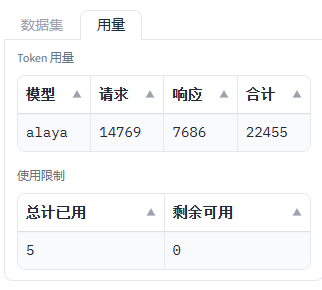
目前剩余用量为0,如果再提问,会提示

这时可以点击右侧上方的申请认证,然后填下如下表单,认证通过后,会从而增加可使用量。
经过大约1.5243600=12.96w秒,我收到了验证通过的短信:
【九章云极】您的TableAgent用户认证已审核通过!有效期15天,欢迎您继续使用。

有了库存,开始继续测试
通用大模型对比分析
下面针对类似的数据分析问题,与国产大模型文心一言和chatglm进行比较,看看二者在数据分析方向的比较。
这里提供一个数据集–网约车APP数据集.csv,该数据集为某打车APP,一周内,若干城市,每天,每小时内运营数据,一共840条数据。各列字段具有先后顺序,乘客先冒泡(在APP内输入起点、终点),再呼叫,司机看到呼叫信息后,可以选择应答,之后完成订单。司机在线是分小时统计的,一天之内加总的话可能有重复的情况。

首先看看大模型是否支持csv文件格式:
对csv数据集的支持比较:
TableAgent对csv格式支持情况测试:
在页面右侧的数据集区域,选择 拖拽文件或点击此处 按钮,可以弹出上传文件框,选择 《网约车APP数据集1.csv》,很容易的把数据集加载完成,选择详情,可以查看数据集的基本情况。

支持!
下面测试下文心一言。
文心一言对csv格式支持情况测试:
进入文心一眼官网,登录后选择上传文档插件,如下:

选择下载好的telecom_customer_churn_analysis.csv数据进行上传,提示
![]()
不支持csv格式。
再测试下Chatglm2。
Chatglm2对csv格式支持情况测试:
进入chatglm2官网,登录后选择文档,上传文档,如下:

选择下载好的telecom_customer_churn_analysis.csv数据进行上传,提示

好的,数据分析结束,不支持csv格式。
稍等,我再试一试!!!
选择左侧的代码。

可以看到chatglm2是擅长数据分析的,再选择下方中间的文件夹按钮,弹出的窗口可以选择所有文件,如下:

选择网约车APP数据集.csv成了,如下:

数据分析支持测试:
下面开始对比测试。
问题1:
你是一个数据分析师,请对上传的"网约车APP数据集.csv"进行分析,该数据集的解释如下:“该数据集为某打车APP,一周内,若干城市,每天,每小时内运营数据,一共840条数据。各列字段具有先后顺序,乘客先冒泡(在APP内输入起点、终点),再呼叫,司机看到呼叫信息后,可以选择应答,之后完成订单。司机在线是分小时统计的,一天之内加总的话可能有重复的情况。”。请说出对这种数据进行分析的一般流程。
TableAgent返回:


Chatglm2返回:

.
结果说明:
从结果可以看出,TableAgent的更多返回都是基于代码和特定数据集的,Chatglm2可以通过模型生成流程方案等信息。
问题2:
你是一个数据分析师,请对上传的"网约车APP数据集1.csv"进行分析,分析星期一到星期日的完单数分布情况。
TableAgent返回:



Chatglm2返回:

结果说明:
从结果可以看出,TableAgent的返回还是清晰的,有数据,也有分析,出现问题的地方是分布情况和下面的详细数据存在不一致的情况,Chatglm2可以采用的沙盒机制,每一个问题不可以等待太久。
再继续测试,把数据重新交给chatglm2,这个过程就不再演示。
问题3:
你是一个数据分析师,请对上传的"网约车APP数据集1.csv"进行分析,分析周一到周日的完单数分布情况。
TableAgent返回:


Chatglm2返回:


结果说明:
从结果可以看出,TableAgent是按照每天进行的计算,没有按照周一到周日进行分组。Chatglm2的输出应该和数据集是相关的,也给出了对应的解释,但中文显示不够友好。
较好的地方是,两者都给出下一步的分析方向。
问题4:
你是一个数据分析师,请对上传的"网约车APP数据集1.csv"进行分析,按照星期字段进行分组,分析星期这一字段分布情况。
TableAgent返回:


Chatglm2返回:
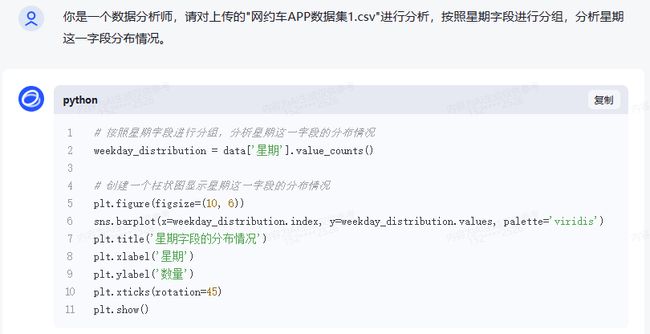


结果说明:
从结果可以看出,TableAgent是按照呼叫,应答,完单数进行了汇总操作,对司机在线进行了求平均,这点应该是考虑了数据集描述的信息。Chatglm2的这一步骤输出应该与数据集无关了,是提供了对应的代码示例,然后让我们带入对应的数据集。
问题5:
查看不同时间段和城市的完单数分布情况
TableAgent返回:


Chatglm2返回:


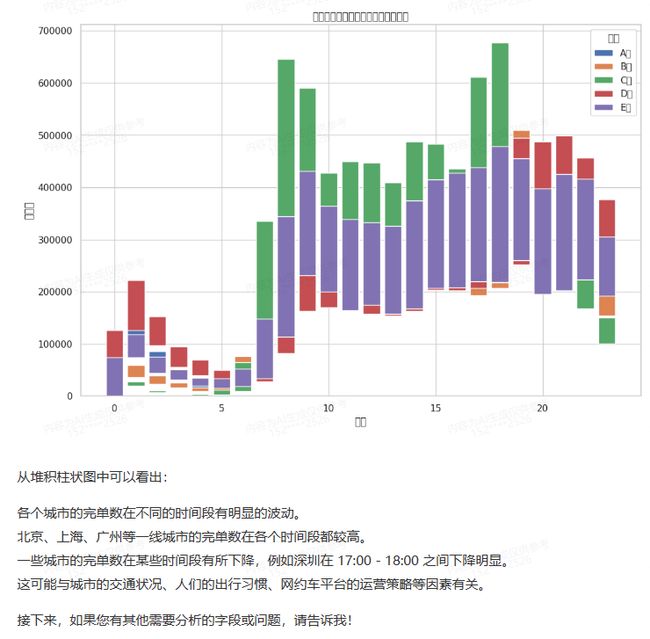
结果说明:
从结果可以看出,TableAgent的这个计算还是准确的,可视化的效果也说明了不同时间段与完单数的情况。Chatglm2的输出应该和数据集是无关的,再代码出现错误后,可以给出另外一个代码,觉得有点像大学生答辩,出现错误不要紧,再说一个可行的答案。
好的,就这吧。来一套:
神龙摆尾,黑龙偷心,双龙出海,战龙在田,龙飞凤舞,伏虎降龙,缩龙成寸,龙蛇混杂,龙的传人,龙凤呈祥,龙马精神,望夫成龙,评测结束,打完收工!
没有比较就没有伤害,目前大模型进行数据分析,TableAgent的确是一个很好的选择。
个人总结与建议:
本文主要完成了TableAgent的注册测试与个人认证,并进行初步测试,在测试中有如下体会:
1.对于不存在的字段分析,TableAgent表现实事求是,可以识别出字段不存在,并且给出反馈。
2.对于从数据中无法得出的因果推断,TableAgent也可以进行说明,可以解释相关与因果推断的差别,没有自行生成结论。
3.在常规问题分析中,点击详情可以看到具体的代码以及数据集,这点保证了数据分析的准确性。
在TableAgent与通用大模型框架进行数据分析方向的对比中,有如下感受:
1.对于数据集的上传方面,TableAgent会更为易用些,上传文件过程清晰,便于操作。
2.在数据集会话保持方面,TableAgent可以长期对数据集的读取,这点比较友好,减少频繁上传数据集的重复操作。
3.在中文支持度方面,TableAgent对中文的支持较为友好,可以绘制出较高可用性的图片。
4.在思维逻辑展示方面,TableAgent更符合数据分析的要求,对数据的转换过程清晰,可信度较高。
5.在对特定数据集的分析流程设计方面,如果TableAgent可以把通用的对话能力与特定的数据集结合起来,那么对数据分析师而言,是一个极大的帮助。
TableAgent是基于DataCanvas Alaya九章元识大模型的产品,有着数据分析垂直领域大模型,和多年的机器学习平台技术加持,TableAgent的易用性和可用性还是很高的。尤其是对于数据分析而言,可以看出具体的数据转换步骤(透明化过程),可以保障数据的准确性,也便于本地调试验证对应的分析结果。可以进行实时的交互式分析(会话式分析)。在不存在的字段分析时,TableAgent有一说一,减少了通用大模型信口开河,然后道歉的弊端,是一个很不错的数据分析产品。
作为数据分析师,有些惶恐也有些期待,但这就是技术的发展吧,不会因为个人而停止,我们只能顺势而起,齐头并进。
下面再附上几张官网的宣传截图,希望使用的朋友同行可以关注下,可以看看有没有自己需求的功能点。

