MMDetection3D :openmmlab环境搭建及模拟kitti数据集跑pointpillars模型
点云训练—openmmlab环境搭建及模拟kitti数据集跑pointpillars模型
1 环境搭建
在我的 linux 服务器上,基于ubuntu20.04
参见:开始你的第一步 — MMDetection3D 1.3.0 文档
1.1 本地环境已安装anaconda.
anaconda的安装参见博文:DS6.1-YOLOv5部署 爱吃油淋鸡的莫何 .详解如下:
!!!【执行脚本时不要sudo,否则会安装到root】
进入安装包目录,运行Anaconda脚本
bash Anaconda3-5.2.0-Linux-x86_64.sh
或
bash Anaconda3-2020.02-Linux-x86_64.sh
一路 Enter 或 Yes , 如有是否安装Microsoft VSCode 选择No。
涉及到询问是否切换路径,可以切换安装路径,也可以不管它。
【naconda3 will now be installed into ths location: ...】
将Anaconda添加到用户环境变量中
vim ~/.bashrc 然后“i”表示插入。
添加下面内容
export PATH="/home/mec/anaconda3/bin:$PATH"
然后“Esc”,":wq"退出再回车
source一下
source ~/.bashrc
# 执行 anaconda-navigator有画面生成,成功
再检查是否安装成功
conda --version
conda -V
【注】 如果复制安装包的时候复制不进去,参照如下
进入DL目录下
sudo su
ls
chmod 777 -R /home/mec/DL/ # 命令表示对该文件夹设置为可读可写权限
1.2 创建并激活一个conda环境
conda create --name openmmlab python=3.8 -y
conda activate openmmlab
1.3 基于 PyTorch 官方说明安装 PyTorch
我自己的nvidia的安装详情如下:
4090的卡
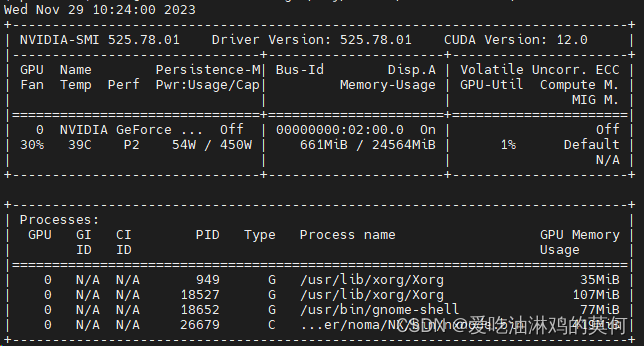
由于在pytorch的官网没有找到适配cuda12.0的历史版本。又担心装12.1的对应torch会冒版本不匹配的问题。所以安装了如下版本。命令如下
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
装好之后,通过python命令查看,依次输入如下命令:
python
输出如下
Python 3.8.18 (default, Sep 11 2023, 13:40:15)
[GCC 11.2.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
导入torch库查看版本
import torch
print(torch.cuda.is_available(), torch.version.cuda, torch.__version__)
可以看到,打印的输出如下:
True 10.2 1.9.0+cu102
然后通过 ‘exit()’ 退出python命令行。
1.4 使用 MIM 安装 MMEngine,MMCV 和 MMDetection
依次执行如下命令:
pip install -U openmim
安装好之后,保留一个numpy版本的问题所以重新安装了numpy的版本
pip install numpy==1.23.0
继续使用mim安装
mim install mmengine
安装完成提示如下
uccessfully installed contourpy-1.1.1 cycler-0.12.1 fonttools-4.45.1 importlib-resources-6.1.1 kiwisolver-1.4.5 matplotlib-3.7.4 mmengine-0.10.1 pyparsing-3.1.1 termcolor-2.3.0
继续使用mim安装
mim install 'mmcv>=2.0.0rc4'
安装完成提示如下
Successfully installed mmcv-2.1.0
继续使用mim安装
mim install 'mmdet>=3.0.0'
安装完成提示如下
Successfully installed mmdet-3.2.0 pycocotools-2.0.7 shapely-2.0.2 terminaltables-3.1.10
1.5 安装 MMDetection3D
因为要开发并直接运行 mmdet3d,从源码安装它
# 我拉下来的代码包取自:
# 如下命令是直接通过git拉取源码
# git clone https://github.com/open-mmlab/mmdetection3d.git -b dev-1.x
# "-b dev-1.x" 表示切换到 `dev-1.x` 分支。
cd mmdetection3d
pip install -v -e .
# "-v" 指详细说明,或更多的输出
# "-e" 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效,从而无需重新安装。
安装完成包含如下:
Successfully installed Flask-3.0.0 PyWavelets-1.4.1 Shapely-1.8.5.post1 absl-py-2.0.0 ansi2html-1.8.0 asttokens-2.4.1 attrs-23.1.0 backcall-0.2.0 black-23.11.0 blinker-1.7.0 cachetools-5.3.2 comm-0.2.0 configargparse-1.7 dash-2.14.2 dash-core-components-2.0.0 dash-html-components-2.0.0 dash-table-5.0.0 decorator-5.1.1 descartes-1.1.0 exceptiongroup-1.2.0 executing-2.0.1 fastjsonschema-2.19.0 fire-0.5.0 flake8-6.1.0 google-auth-2.23.4 google-auth-oauthlib-1.0.0 grpcio-1.59.3 imageio-2.33.0 iniconfig-2.0.0 ipython-8.12.3 ipywidgets-8.1.1 itsdangerous-2.1.2 jedi-0.19.1 joblib-1.3.2 jsonschema-4.20.0 jsonschema-specifications-2023.11.1 jupyter-core-5.5.0 jupyterlab-widgets-3.0.9 lazy_loader-0.3 llvmlite-0.41.1 lyft_dataset_sdk-0.0.8 matplotlib-3.5.3 matplotlib-inline-0.1.6 mccabe-0.7.0 mmdet3d mypy-extensions-1.0.0 nbformat-5.7.0 nest-asyncio-1.5.8 numba-0.58.1 numpy-1.24.4 nuscenes-devkit-1.1.11 oauthlib-3.2.2 open3d-0.17.0 parso-0.8.3 pathspec-0.11.2 pexpect-4.9.0 pickleshare-0.7.5 pkgutil-resolve-name-1.3.10 plotly-5.18.0 pluggy-1.3.0 plyfile-1.0.2 prompt-toolkit-3.0.41 protobuf-4.25.1 ptyprocess-0.7.0 pure-eval-0.2.2 pyasn1-0.5.1 pyasn1-modules-0.3.0 pycodestyle-2.11.1 pyflakes-3.1.0 pyquaternion-0.9.9 pytest-7.4.3 referencing-0.31.0 requests-oauthlib-1.3.1 retrying-1.3.4 rpds-py-0.13.1 rsa-4.9 scikit-image-0.21.0 scikit-learn-1.3.2 scipy-1.10.1 stack-data-0.6.3 tenacity-8.2.3 tensorboard-2.14.0 tensorboard-data-server-0.7.2 threadpoolctl-3.2.0 tifffile-2023.7.10 traitlets-5.14.0 trimesh-4.0.5 werkzeug-3.0.1 widgetsnbextension-4.0.9
1.6 验证安装
为了验证 MMDetection3D 是否安装正确,官方提供了示例代码来执行模型推理。
步骤 1. 下载配置文件和模型权重文件。
mim download mmdet3d --config pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car --dest .
下载将需要几秒钟或更长时间,这取决于您的网络环境。完成后,您会在当前文件夹中发现两个文件 pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py 和 hv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20220331_134606-d42d15ed.pth。
步骤 2. 推理验证(方法)。
如果您从源码安装 MMDetection3D,那么直接运行以下命令进行验证:
python demo/pcd_demo.py demo/data/kitti/000008.bin pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py hv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20220331_134606-d42d15ed.pth --show
您会看到一个带有点云的可视化界面,其中包含有在汽车上绘制的检测框。
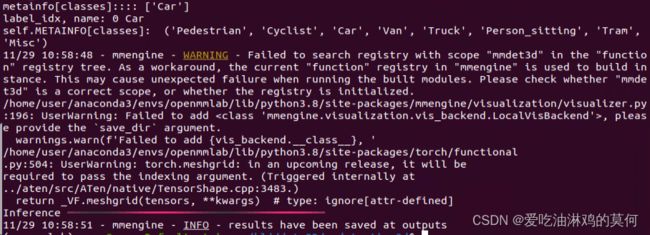
但是我在执行命令后,由于可能是open3D的问题,无法show,(可能是由于我的服务器没有连显示器的原因) 所以我通过如下命令验证推理
python demo/pcd_demo.py demo/data/kitti/000008.bin pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py hv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20220331_134606-d42d15ed.pth
之后会提示推理结果保存在了Outputs中
2 模拟kitti数据集跑pointpillars模型
2.1 先跑kitti_mini数据集
2.1.1 kitti_mini的数据地址:
链接:https://pan.baidu.com/s/1lKP9xViH3jVR1XBbv19VlQ
提取码:kitt
注意:将文件名kitti_mini修改名称为kitti, 放在mmdetection3d/data/路径下。
2.1.2 修改config文件
mmdetection3d/configs/pointpillars/pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class.py
中的相关内容,包含如下:
数据:
# dataset settings
data_root = 'data/kitti/'
class_names = ['Pedestrian', 'Cyclist', 'Car', 'Truck', 'Van', 'Tram', 'Misc']
注意:kitti_mini的数据集中还有一种类型是’DontCare’,它不属于检测的目标,所以不放在class_names列表中。
其它参数:
lr = 0.001
epoch_num = 10
... ...
train_cfg = dict(by_epoch=True, max_epochs=epoch_num, val_interval=15)
注意,我这里设置的val_interval > max_epochs。
2.1.3 训练
首先通过命令生成信息文件
python tools/create_data.py kitti --root-path ./data/kitti --out-dir ./data/kitti --extra-tag kitti
上述create_data.py程序部分打印如下:

通过如下命令训练
cd ....../mmdetection3d
python ./tools/train.py ./configs/pointpillars/pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class.py
若报错缺pandas、typing_extensions包,则通过pip命令安装一下
【1】问题如下
ModuleNotFoundError: No module named 'pandas'
ModuleNotFoundError: No module named 'typing_extensions'
解决如下
pip install pandas
pip install typing_extensions
train运行起来后,会打印环境信息,模型配置参数,数据的信息,过程等

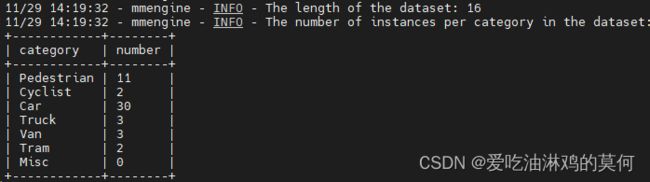

训练完成 后,会提示输出。
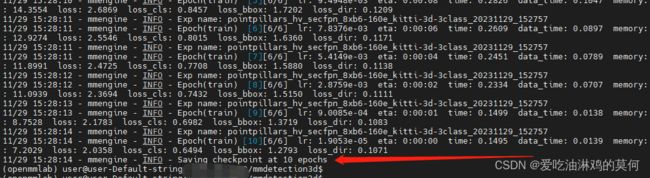
可以看到在路径/home/user/hlj/data3D/mmdetection3d/work_dirs/pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class/下可以找到 epoch_10.pth的权重文件
注意:上述训练的时候,config中的参数设置的val_interval > max_epochs。
epoch_num = 10
train_cfg = dict(by_epoch=True, max_epochs=epoch_num, val_interval=15)
若设成
epoch_num = 16
train_cfg = dict(by_epoch=True, max_epochs=epoch_num, val_interval=8)
则在训练epoch=8结束之后,会进行验证。
由于数据集标签和./mmdetection3d/mmdet3d/evaluation/functional/kitti_utils/eval.py中的不一致,所以会报一下由于CLASS长度不一致导致的问题
如下过程为遇到的问题及解决的过程:
问题1
File "/mmdet3d/evaluation/functional/kitti_utils/eval.py", line 721, in kitti_eval
min_overlaps = min_overlaps[:, :, current_classes]
IndexError: index 5 is out of bounds for axis 2 with size 5
问题1解决方法:将eval.py中的700多行添加overlap_0_7_kitimini和overlap_0_7_kitimini,生成新的min_overlaps。同时,class_to_name也需要根据自己在配置文件中的标签设置。
overlap_0_7 = np.array([[0.7, 0.5, 0.5, 0.7, 0.5],
[0.7, 0.5, 0.5, 0.7, 0.5],
[0.7, 0.5, 0.5, 0.7, 0.5]])
overlap_0_5 = np.array([[0.7, 0.5, 0.5, 0.7, 0.5],
[0.5, 0.25, 0.25, 0.5, 0.25],
[0.5, 0.25, 0.25, 0.5, 0.25]])
overlap_0_7_kitimini = np.array([[0.5, 0.5, 0.7, 0.8, 0.7, 0.5, 0.5],
[0.5, 0.5, 0.7, 0.8, 0.7, 0.5, 0.5],
[0.5, 0.5, 0.7, 0.8, 0.7, 0.5, 0.5]])
overlap_0_5_kitimini = np.array([[0.5, 0.5, 0.7, 0.8, 0.7, 0.5, 0.5],
[0.25, 0.25, 0.5, 0.6, 0.5, 0.25, 0.25],
[0.25, 0.25, 0.5, 0.6, 0.5, 0.25, 0.25]])
overlap_0_7, overlap_0_5 = overlap_0_7_kitimini, overlap_0_5_kitimini
min_overlaps = np.stack([overlap_0_7, overlap_0_5], axis=0)
class_to_name_kittimi = {0: 'Pedestrian', 1: 'Cyclist', 2: 'Car', 3: 'Truck', 4: 'Van', 5:'Tram', 6:'Misc'}
class_to_name = class_to_name_kittimi
问题2:
File "/mmdet3d/evaluation/functional/kitti_utils/eval.py", line 39, in clean_data
current_cls_name = CLASS_NAMES[current_class].lower()
IndexError: list index out of range
问题2解决方法:由于CLASS_NAMES没有匹配训练数据集的标签,将clean_data()函数内部的CLASS_NAMES改一下即可。
def clean_data(gt_anno, dt_anno, current_class, difficulty):
CLASS_NAMES = ['car', 'pedestrian', 'cyclist']
CLASS_NAMES_kittimi = ['Pedestrian', 'Cyclist', 'Car', 'Truck', 'Van', 'Tram', 'Misc']
CLASS_NAMES_my = ['Car', 'Truck', 'Bicycle',]
CLASS_NAMES = CLASS_NAMES_kittimi
问题3:
... ... ... ...
File "/mmdet3d/evaluation/functional/kitti_utils/eval.py", line 124, in bev_box_overlap
from .rotate_iou import rotate_iou_gpu_eval
File "/mmdet3d/evaluation/functional/kitti_utils/rotate_iou.py", line 285, in
def rotate_iou_kernel_eval(N,
... ... ... ...
File "/home/user/anaconda3/envs/openmmlab/lib/python3.8/site-packages/numba/core/typeinfer.py", line 1086, in propagate
raise errors[0]
numba.core.errors.TypingError: Failed in cuda mode pipeline (step: nopython frontend)
Failed in cuda mode pipeline (step: nopython frontend)
Failed in cuda mode pipeline (step: nopython frontend)
libNVVM cannot be found. Do 【`conda install cudatoolkit`】:
libnvvm.so: cannot open shared object file: No such file or directory
During: resolving callee type: type(CUDADispatcher())
During: typing of call at /mmdet3d/evaluation/functional/kitti_utils/rotate_iou.py (335)
... ... ... ...
File "mmdet3d/evaluation/functional/kitti_utils/rotate_iou.py", line 335:
def rotate_iou_kernel_eval(N,
dev_iou[offset] = devRotateIoUEval(block_qboxes[i * 5:i * 5 + 5],
问题3解决方法: 上述报错可以看出大致是cuda版本的问题,是在验证的时候,无法使用cuda加速。
通过报错,可以定位到mmdet3d/evaluation/functional/kitti_utils/rotate_iou.py。
考虑是涉及一些cuda的问题。所以把每一个函数前面的修饰器注释掉就可以了
只不过,这样处理的缺点就是在val的时候,没有用到cuda加速,有点可惜
上面的报错中,框了一个中文中括号,安装cudatoolkit,问题解决,可以正常跑val验证了。
conda install cudatoolkit
每次验证结束,会有一堆打印包含如下,同时,epoch_16.pth权重会保存在路径/work_dirs/pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class/中。
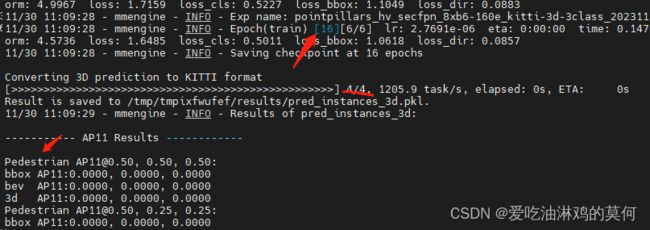
由于数据集比较小,验证的时候,基本不出结果。
2.2 跑自己 的数据集
2.2.1 模拟kitti数据格式构建自己的数据集
将自己的数据集命名为kitti_my。数据集路径:
链接:https://pan.baidu.com/s/1ElxDm0Rzjk8M-CSSt53ibQ
提取码:kitt
统计自己标注的json文件中类型总数如下
labels Statics = {'Car': 193, 'Truck': 57, 'Cyclist': 60}
2.2.1.1 数据集目录树如下:
kitti_my
————ImageSets
————————test.txt # 文件名(不包含路径和后缀)
————————train.txt # 文件名(不包含路径和后缀)
————————val.txt # 文件名(不包含路径和后缀)
————testing
————————calib
————————image_2
————————label_2
————————velodyne
————training
————————calib # 包含当前点云与相机的转换矩阵(.txt)
————————calibjson # 自己标注的json文件(.json),这个文件不是在当前目录i西安必备的
————————image_2 # 点云数据对应时刻的拍摄的图片(.png)
————————label_2 # 点云数据的标签(.txt)
————————velodyne # 点云数据(.bin的格式)
注意:在train之前,需将 kitti_my重命名为kitti。这样的话,不用修改包含数据集路径的相关源码了。如果已经有kitti文件夹,则先将已有的kitti重命名,然后再将 kitti_my重命名为kitti。
2.2.1.2 目录树内容详细介绍如下(截图表示):
calib/000000.txt:
这里的所有txt文件内容都一样(车端车在行走,需不断调整转换矩阵,路端相机,雷达是固定不变的)

calibjson/000000.json、000001.json、000002.json

images_2/000000.png、000001.png、000002.png:
每张图的内容都一样(复制来自kitti数据集),因为我们自己没有采集到图片,只有点云,就借助kitti的做一下转换。

label_2/000000.txt、000001.txt、000002.txt:
通过json文件转换而来

velodyne:
用于存放训练数据的点云数据
calib、image_2、label_2中的数据生成源码:
if __name__ == '__main__':
mycloudjson2kitticalibandlabel()
数据集中通过统计json标定文件,获得标签如下:
labels Statics = {'Car': 193, 'Truck': 57, 'Cyclist': 60}
2.2.2 通过命令生成数据集信息文件
将kitti_my拷贝在/mmdetection3d/data/路径下,并重命名为kitti。通过如下命令生成。
python tools/create_data.py kitti --root-path ./data/kitti --out-dir ./data/kitti --extra-tag kitti
运行结束后,data/kitti/目录下会生成如下文件
文件夹:
kitti_gt_database
文件:
kitti_dbinfos_train.pkl
kitti_infos_test.pkl
kitti_infos_train.pkl
kitti_infos_trainval.pkl
kitti_infos_val.pkl
并会打印如下信息

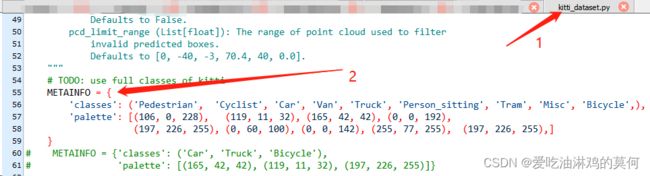
若上述打印的信息与自己数据标签的实际类型及数据不匹配,则需做如下调整
# mmdetection3d/mmdet3d/datasets/kitti_dataset.py
2.2.3 训练
2.2.3.1 修改配置文件参数
cd ./configs/pointpillars/
cp ./pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class.py ./pointpillars_hv_kitti.py
打开pointpillars_hv_kitti.py,修改如下参数
【1】
class_names = my_name = ['Car', 'Truck', 'Cyclist',]
epoch_num = 100
train_cfg = dict(by_epoch=True, max_epochs=epoch_num, val_interval=50)
【2】
2.2.3.2 修改其它相关文件参数
1 kitti_dataset.py
修改/mmdetection3d/mmdet3d/datasets/kitti_dataset.py的内容
【】修改class KittiDataset(Det3DDataset):
METAINFO = {
'classes': ('Pedestrian', 'Cyclist', 'Car', 'Van', 'Truck', 'Person_sitting', 'Tram', 'Misc',),
'palette': [(106, 0, 228), (119, 11, 32), (165, 42, 42), (0, 0, 192),
(197, 226, 255), (0, 60, 100), (0, 0, 142), (255, 77, 255), ]}
2 eval.py
/home/user/hlj/data3D/mmdetection3d/mmdet3d/evaluation/functional/kitti_utils/eval.py
#【1】修改clean_data(gt_anno, dt_anno, current_class, difficulty)函数中内容(约31行):
CLASS_NAMES_my = ['Car', 'Truck', 'Bicycle',]
CLASS_NAMES = CLASS_NAMES_my
#【2】修改def kitti_eval(gt_annos, dt_annos, current_classes, eval_types)函数中内容(约675行):
overlap_0_7_my = np.array([[0.7, 0.7, 0.5],
[0.7, 0.7, 0.5],
[0.7, 0.7, 0.5]])
overlap_0_5_my = np.array([[0.7, 0.7, 0.5],
[0.5, 0.5, 0.25],
[0.5, 0.5, 0.25]])
overlap_0_7, overlap_0_5 = overlap_0_7_my, overlap_0_5_my
# my_name = ['Car', 'Truck', 'Cyclist',]
class_to_name_my = {0: 'Car', 1: 'Truck', 2: 'Cyclist', }
class_to_name = class_to_name_my
# 【3】修改def kitti_eval_coco_style(gt_annos, dt_annos, current_classes)函数中内容(约900行):
class_to_name = {0: 'Car', 1: 'Truck', 2: 'Cyclist', }
class_to_range = {
0: [0.5, 0.95, 10],
1: [0.5, 0.95, 10],
2: [0.25, 0.7, 10],}
2.2.3.3 使用如下命令训练
python ./tools/train.py ./configs/pointpillars/pointpillars_hv_kitti.py
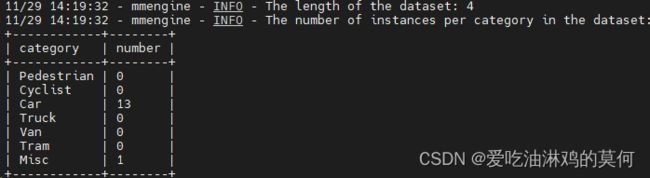
首先,数据集可以正常加载了,可以看到打印数据信息如下:
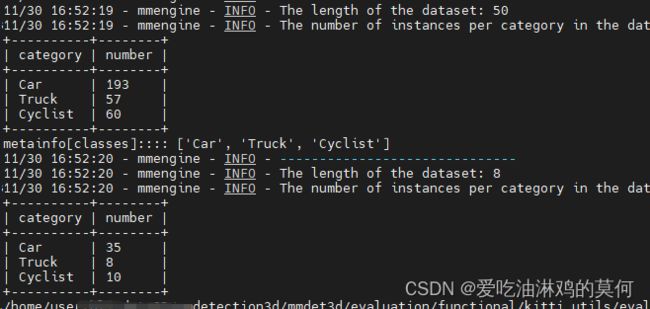
但是包含报错如下,及调试过程:
【问题1】
... ... ... ...
File "/mmdetection3d/mmdet3d/datasets/transforms/transforms_3d.py", line 424, in transform
sampled_dict = self.db_sampler.sample_all(
File "/mmdetection3d/mmdet3d/datasets/transforms/dbsampler.py", line 251, in sample_all
sampled_cls = self.sample_class_v2(class_name, sampled_num,
File "/mmdetection3d/mmdet3d/datasets/transforms/dbsampler.py", line 331, in sample_class_v2
sp_boxes = np.stack([i['box3d_lidar'] for i in sampled], axis=0)
File "<__array_function__ internals>", line 180, in stack
File "/home/user/anaconda3/envs/openmmlab/lib/python3.8/site-packages/numpy/core/shape_base.py", line 422, in stack
raise ValueError('need at least one array to stack')
ValueError: need at least one array to stack
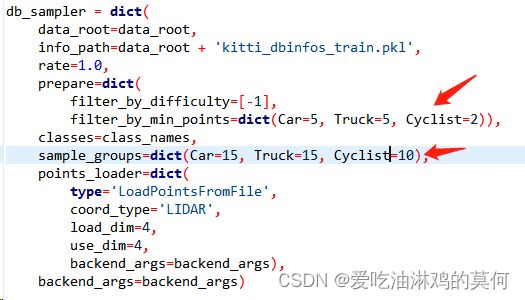
【问题1解决】这个问题好尴尬,是因为配置文件中包含如下图红色框起的内容的原因,把框起的内容注释掉可以正常运行。

【问题1解决说明】
db_sampler用于进行数据增强和样本平衡。它是一个数据采样器,用于在训练过程中从原始数据集中生成采样样本。如果注释掉的话,就是不做数据增强处理。
数据增强:db_sampler可以在训练过程中对原始数据进行增强,以扩充训练数据集。它可以通过随机选择、缩放、旋转、平移等操作来生成多样化的数据样本。这有助于提高模型的鲁棒性和泛化能力。
样本平衡:db_sampler还可以用于样本平衡,特别是在存在类别不平衡的情况下。它可以根据样本的类别标签进行采样,以使得各个类别的样本数量相对均衡。这有助于避免模型对于少数类别的偏好,提高整体的分类性能。
在配置文件中,db_sampler通常作为数据加载器的一部分出现,它会在每个训练迭代中生成采样样本,并将其提供给模型进行训练。通过配置不同的采样策略和参数,可以灵活地控制数据增强和样本平衡的效果,以适应具体的数据集和任务要求。
此时,可以看出模型正常训练完成,并在mmdetection3d/work_dirs/pointpillars_hv_kitti/目录下生成了epoch_80.pth的模型。同级目录下的pointpillars_hv_kitti.py是模型训练的配置文件。
【问题1最终解决】
哪位大神解决了麻烦留言一下,如果我解决了也会更新哟。
注释掉可以正常运行。
[外链图片转存中…(img-cECPihSd-1701654847560)]
【问题1解决说明】
db_sampler用于进行数据增强和样本平衡。它是一个数据采样器,用于在训练过程中从原始数据集中生成采样样本。如果注释掉的话,就是不做数据增强处理。
数据增强:db_sampler可以在训练过程中对原始数据进行增强,以扩充训练数据集。它可以通过随机选择、缩放、旋转、平移等操作来生成多样化的数据样本。这有助于提高模型的鲁棒性和泛化能力。
样本平衡:db_sampler还可以用于样本平衡,特别是在存在类别不平衡的情况下。它可以根据样本的类别标签进行采样,以使得各个类别的样本数量相对均衡。这有助于避免模型对于少数类别的偏好,提高整体的分类性能。
在配置文件中,db_sampler通常作为数据加载器的一部分出现,它会在每个训练迭代中生成采样样本,并将其提供给模型进行训练。通过配置不同的采样策略和参数,可以灵活地控制数据增强和样本平衡的效果,以适应具体的数据集和任务要求。
此时,可以看出模型正常训练完成,并在mmdetection3d/work_dirs/pointpillars_hv_kitti/目录下生成了epoch_80.pth的模型。同级目录下的pointpillars_hv_kitti.py是模型训练的配置文件。并打印如下相关信息,由于数据较少,验证貌似没出结果
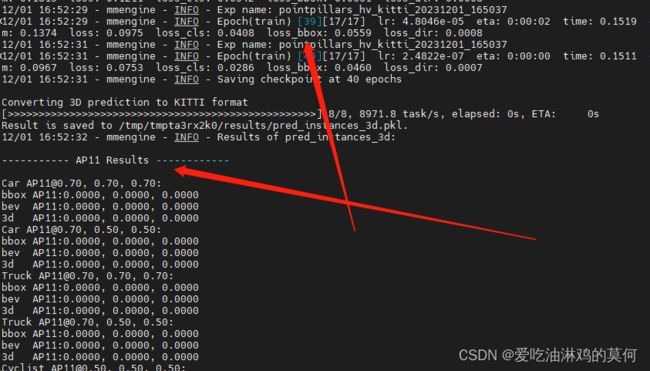

【问题1最终解决】
哪位大神解决了麻烦留言一下,如果我解决了也会更新哟。