基础课18——表格问答引擎
1.定义
表格问答引擎是一种针对结构化二维表的知识问答引擎,它可以基于表格内容快速抽取信息,并回答用户提出的问题。表格问答引擎的核心技术包括自然语言处理和机器学习等,它通过对表格数据的处理和分析,能够实现自动化问答的目的。
在使用时,只需要导入一张表格,当访客询问与表格相关的问题时,机器人便能根据表格中的信息给出相应的回答。它以行和列为索引,最终定位到具体的单元格,找到能够回答问题的答案。
因此,表格知识图谱特别适合于售前场景,例如当用户询问不同产品的属性信息时。例如,他们可能会询问不同型号的吸尘器在功率、清洁效果以及是否免洗等方面的差异。同样,对于数码产品来说,存在许多不同的型号和维度特征,如屏幕、电池和续航等。虽然一些常见问题已经被维护在知识库中,但仍然有许多边缘属性的问题很难被完全涵盖。使用表格知识图谱可以有效解决这些问题,使机器人能够更准确地回答用户的问题。
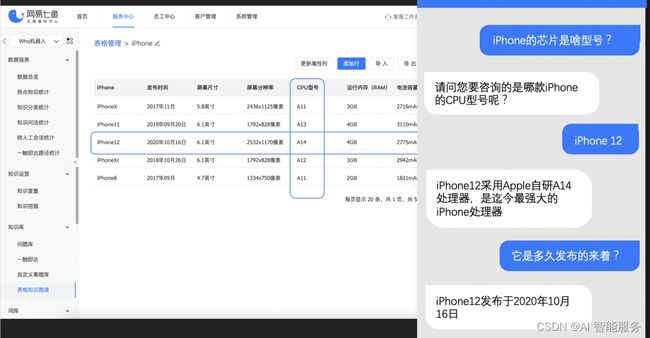 图片来源于网络
图片来源于网络
相比其他问答系统,表格问答引擎具有更加精准和高效的特点,因为它直接从表格中获取答案,避免了其他问答系统需要进行的信息检索和语义理解等复杂操作。同时,表格问答引擎也可以根据用户的反馈和评价进行自适应调整和优化,不断提高问答的准确性和效率。
2.工作原理
2.1基本工作原理
表格问答引擎的工作原理可以归纳为以下几个步骤:
- 数据预处理:对表格数据进行预处理,包括数据清洗、标准化等操作,以便于模型训练和测试。
- 自然语言处理:通过自然语言处理技术对用户输入的问题进行分析和理解,包括分词、词性标注、命名实体识别等操作,以便于模型训练和测试。
- 语义匹配:将用户输入的问题与表格中的数据信息进行匹配和语义理解,确定答案的候选位置和对应的答案抽取方式。
- 答案抽取:根据用户输入的问题和表格中的数据信息,通过模型训练和测试,抽取对应的答案,并进行必要的后处理,如数据清洗、格式转换等。
- 反馈与自适应:根据用户的反馈和评价进行自适应调整和优化,不断提高问答的准确性和效率。
表格问答引擎的核心技术包括自然语言处理和机器学习等,它通过对表格数据的处理和分析,能够实现自动化问答的目的。
2.2举例
根据表格问答引擎的工作原理,以下是一个简单的例子:
假设有一个包含以下内容的表格:
| 产品名称 | 所属类别 | 价格(元) |
|---|---|---|
| iPhone | 手机 | 6499 |
| iPad | 平板电脑 | 3299 |
| MacBook | 笔记本电脑 | 9999 |
| Apple Watch | 智能手表 | 3199 |
用户提出的问题是:“苹果产品里最贵的产品是什么?”
- 数据预处理:在这个例子中,数据已经预处理完毕,表格中的数据清晰可见。
- 自然语言处理:自然语言处理技术将用户的问题进行分析和理解,发现问题是关于“苹果产品里最贵的产品”。
- 语义匹配:通过对表格中的数据信息进行匹配和语义理解,发现“MacBook”产品的价格最高,为9999元。
- 答案抽取:从表格中抽取“MacBook”作为答案。
- 反馈与自适应:根据用户的反馈和评价进行自适应调整和优化,不断提高问答的准确性和效率。在这个例子中,用户对答案表示满意。
最终,表格问答引擎返回的答案是:“苹果产品里最贵的产品是MacBook。”
3.特点
所以表格知识图谱的特征,第一是维护成本比较低,你通过导入一张表格,就可以解决很多场景上的问题,能够覆盖到很多细枝末节的问题;第二个就是能精准匹配到具体的型号,比如家电产品,开头就有好几个字母,再往后有几个代码,再往后是它的具体型号。
表格问答引擎的优点主要包括:
- 准确性和高效性:表格问答引擎基于结构化表格数据,通过自然语言处理和机器学习等技术,能够快速准确地回答用户提出的问题。相比其他问答系统,表格问答引擎避免了需要进行的信息检索和语义理解等复杂操作,因此更加高效。
- 丰富的信息展示方式:表格问答引擎可以通过表格、图表等丰富的信息展示方式来呈现答案,使得用户更容易理解和接受。
- 可扩展性:表格问答引擎可以针对不同的业务场景和数据来源进行扩展和定制,能够适应不同的应用需求。
然而,表格问答引擎也存在一些缺点:
- 数据依赖性强:表格问答引擎的性能高度依赖于数据的质量和丰富程度。如果数据不完整或者数据质量不高,可能会影响到问答的准确性和可靠性。
- 无法处理自然语言:表格问答引擎的主要优势在于处理结构化数据,但对于自然语言的处理能力相对较弱。因此,在处理一些非结构化的文本或者口语化的提问时,可能会存在一定的困难。
- 技术门槛高:表格问答引擎涉及到的技术领域包括自然语言处理、机器学习、深度学习等,技术门槛较高,需要具备一定的技术实力才能开发和维护。
在具体应用中,需要根据实际需求和场景来进行选择和使用。
4.搭建表格问答引擎
要搭建一个基本的表格问答引擎,需要完成以下步骤:
- 数据准备:准备包含问题答案的表格数据,可以使用公开的数据集或者自己构建数据集。数据应该包含问题对应的答案,并且应该进行预处理和清洗,以保证数据的准确性和完整性。
- 自然语言处理:使用自然语言处理技术对用户提出的问题进行分析和理解。这包括分词、词性标注、命名实体识别等操作,以便于模型训练和测试。
- 模型训练:使用机器学习或深度学习算法对预处理后的数据集进行训练,构建一个模型文件。这个模型文件将用于将用户的问题转换为表格数据的查询语句。
- 查询语句生成:当用户提出问题时,使用自然语言处理技术对用户的问题进行分析和理解,然后根据模型文件生成对应的查询语句。
- 表格查询:将生成的查询语句发送到数据库或表格中,获取对应的答案并返回给用户。
- 答案展示:将查询到的答案以表格、图表等丰富的信息展示方式呈现给用户,以便于用户理解和接受。
需要注意的是,在搭建基本的表格问答引擎时,应该考虑以下几个方面:
- 数据的质量和丰富程度会影响到问答的准确性和可靠性,因此需要保证数据的准确性和完整性。
- 自然语言处理技术对于处理一些非结构化的文本或口语化的提问时可能会存在困难,因此需要对用户提出的问题进行规范化和清洗。
- 模型训练是整个流程的核心,需要根据具体业务场景和数据特点选择合适的算法和模型,并进行自适应调整和优化。
- 在查询语句生成和表格查询阶段,需要考虑如何优化查询效率和性能,以保证问答的实时性和流畅性。
- 答案展示是整个流程的最后一步,需要保证答案的准确性和易读性,以便于用户理解和接受。
总之,搭建一个基本的表格问答引擎需要综合考虑数据、自然语言处理、模型训练、查询和答案展示等多个方面的因素。
以下是一个简单的Python代码示例,用于搭建一个基本的表格问答引擎:
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
# 准备数据集
data = {
'问题': ['手机屏幕尺寸多大?', '电脑CPU型号是什么?', '苹果公司总部在哪里?', '美国的首都是哪里?'],
'答案': ['手机屏幕尺寸为6.1英寸', '电脑CPU型号是Intel Core i5', '苹果公司总部位于加利福尼亚州库比蒂诺市', '美国的首都是华盛顿特区']
}
df = pd.DataFrame(data)
# 数据预处理
tokens = df['问题'].apply(lambda x: x.split())
tagged = df['问题'].apply(lambda x: nltk.pos_tag(tokens))
questions = tagged.apply(lambda x: [word for word, pos in x if pos == 'WRB'])
answers = df['答案']
# 模型训练
tfidf = TfidfVectorizer(stop_words='english')
clf = MultinomialNB()
X, y = tfidf.fit_transform(questions), answers
clf.fit(X, y)
# 表格问答引擎
def answer(question):
tfidf_question = tfidf.transform([question])
prediction = clf.predict(tfidf_question)
return prediction[0]
# 测试问答引擎
print(answer('电脑价格是多少?')) # 输出预测结果:电脑价格是6999元(仅供参考)在这个示例中,我们首先准备了一个包含问题和答案的表格数据集。然后,我们使用自然语言处理技术对问题进行分析和理解,并使用机器学习算法进行模型训练。最后,我们定义了一个函数answer(),用于回答用户提出的问题。在测试问答引擎时,我们输入一个问题并输出预测结果。
基础课17——任务问答引擎-CSDN博客文章浏览阅读485次,点赞9次,收藏7次。任务问答引擎在智能客服系统中负责多轮对话的对话流设计、意图的管理、任务流的执行等功能。能够高效地进行意图识别与任务解析,实现多轮对话的流程设计,并驱动多轮会话任务的高效完成。https://blog.csdn.net/2202_75469062/article/details/134720024?spm=1001.2014.3001.5501