自然语言处理第3天:Word2Vec模型

☁️主页 Nowl
专栏 《自然语言处理》
君子坐而论道,少年起而行之

文章目录
- 什么是语言模型
- Word2Vec介绍
-
- 介绍
- CBOW模型
-
- 介绍
- 训练过程
- 图解训练过程
- 代码实现
- Skip-Gram模型
-
- 介绍
- 训练过程
- 图解训练过程
- 代码
什么是语言模型
语言模型的工作原理基于统计学习和概率论,其目标是捕捉语言的概率分布,即我们通过不同的任务训练模型,都是为了使语言模型获取这种概率关系,如文本生成模型,它会判断下一个应该生成什么词,一步步生成完整的文本序列
Word2Vec介绍
介绍

Word2Vec是一个经典的语言模型,它的模型参数是一个词嵌入向量矩阵,它的训练目的就是不断优化这个矩阵,以获得高性能的词嵌入向量矩阵,它有两个具体实现
- CBOW模型
- Skip-Gram模型
他们的区分标准是训练任务的不同,让我们继续看下去吧
CBOW模型
介绍
CBOW模型也叫词袋模型。它的训练任务是:给定某个词的上下文,通过这个上下文来预测这个词
- CBOW模型的输入与输出数据是one-hot向量
- 训练过程中会逐步更新参数,也就是词嵌入矩阵
训练过程
数据准备: 首先,需要准备训练数据,其中包含了大量的文本语料。文本数据需要进行分词等预处理,将文本转换为词语序列。
创建上下文窗口: 对于每个目标词语, CBOW模型定义了一个上下文窗口。这个窗口的大小由超参数window指定,表示目标词语左右两侧的词语数目。
构建训练样本: 对于每个目标词语,CBOW模型从其上下文窗口中收集上下文词语。每个训练样本由上下文词语构成,并且目标是预测目标词语。
模型结构:CBOW模型的神经网络结构相对简单。它包括一个嵌入层和一个平均池化层,然后是一个输出层,用于预测目标词语。嵌入层将上下文词语映射到词嵌入向量,平均池化层将这些向量取平均,最后通过输出层进行预测。
训练目标:CBOW模型的训练目标是最大化给定上下文词语的条件概率,即最大化目标词语在给定上下文下的概率。这通常通过最小化负对数似然来实现。
梯度下降: 使用梯度下降或其变种,通过反向传播算法来调整嵌入层的权重,使得模型的预测更接近实际的上下文词语。
重复迭代: 重复以上步骤多次,直到模型收敛到一个合适的状态。每一轮迭代都遍历整个训练数据。
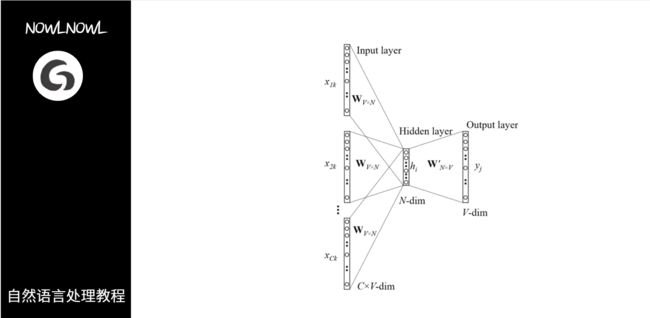
图解训练过程
1.经典CBOW模型结构
2.以下是拿具体例子做的详细讲解
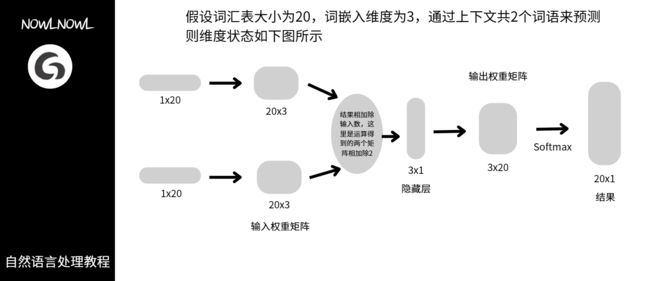
注意
- 图中的两个输入权重矩阵是相同的,这里只是方便表示而将它们拆开
- 最终结果就是单词的分布式表示,softmax函数可以展现每个词的概率
- 我们得到了两个权重矩阵——输入与输出权重矩阵,现在常见的方法是将输出权重矩阵作为我们要的词嵌入矩阵
代码实现
# 导入库
import torch
import torch.nn as nn
# 创建输入向量
c0 = torch.Tensor([0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
c1 = torch.Tensor([0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
# 创建神经网络层
W_in = nn.Linear(20, 3)
W_out = nn.Linear(3, 20)
softmax = nn.Softmax(dim=0)
# 进行传播
h0 = W_in.forward(c0)
h1 = W_in.forward(c1)
h = 0.5 * (h0 + h1)
s = W_out.forward(h)
out = softmax(s)
# 打印结果
print(out)
Skip-Gram模型
介绍
与CBOW模型不同的是,Skip-Gram模型的训练任务是给定某个词,来预测它的上下文,这点与CBOW正好相反
训练过程
-
数据准备: 和CBOW一样,需要准备包含大量文本语料的训练数据,并对文本进行分词等预处理。
-
创建训练样本: 对于每个中心词(目标词语),Skip-gram模型选择一个上下文词语。与CBOW不同,Skip-gram关注的是从中心词到上下文词的映射。训练样本由(中心词,上下文词)组成。
-
模型结构: Skip-gram模型同样包括一个嵌入层和一个输出层。嵌入层将中心词映射到词嵌入向量,然后通过输出层进行预测。与CBOW相反,Skip-gram模型的输出层通常是一个softmax层,用于计算给定中心词的上下文词的条件概率。
-
训练目标: Skip-gram模型的训练目标是最大化给定中心词的条件概率,即最大化上下文词在给定中心词的情况下的概率。
-
梯度下降: 使用梯度下降或其变种,通过反向传播算法来调整嵌入层的权重和输出层的权重,以最小化损失函数。
-
重复迭代: 重复以上步骤多次,直到模型收敛到一个合适的状态。每一轮迭代都遍历整个训练数据。
图解训练过程
Skip-gram的训练过程就是CBOW倒转过来,如图,就不具体做详细说明了
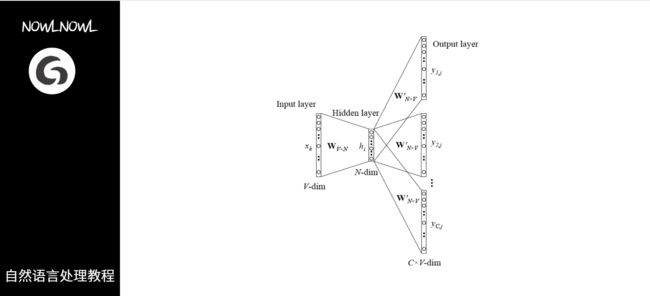
代码
以下是基于CBOW模型的调用了库的示例代码
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# 示例文本数据
corpus = [
"This is the first sentence.",
"Word embeddings are interesting.",
"Word2Vec is a popular embedding model.",
]
# 对文本进行分词
tokenized_corpus = [word_tokenize(sentence.lower()) for sentence in corpus]
# 训练Word2Vec模型
model = Word2Vec(sentences=tokenized_corpus, vector_size=100, window=5, min_count=1, workers=4)
# 获取"word"的词向量
word_vector = model.wv["word"]
# 打印词向量
print(f"Embedding for 'word': {word_vector}")
