GPT:Generative Pre-Training
1. 概述
随着深度学习在NLP领域的发展,产生很多深度网络模型用于求解各类的NLP问题,从word2vec词向量工具的提出后,预训练的词向量成了众多NLP深度模型中的重要组成部分。然而传统的word2vec生成的词向量都是上下文无关的,其生成的词向量式固定,不会随着上下文的改变而改变,这种固定的词向量无法解决一词多义的问题。比如“bank”这个词,既可以表示“河岸”,也可以表示“银行”。Embeddings from Language Models(ELMo)[1]是2018年提出的一种基于上下文的预训练模型,通过大量语料学习到每个词的一般性embedding形式,学习到与上下文无关的语义向量表示,以此实现对多义词的建模。
Generative Pre-Training(GPT)[2]也是在2018年提出的实现对多义词建模的语义模型,与ELMo相同的是,在GPT中,也是采用了两阶段的过程,第一阶段是利用无监督的方式对语言模型进行预训练,第二阶段通过监督的方式在具体语言任务上进行Fine-tuning。不同的是在GPT中采用的特征提取算法是transformer,且是单向的语言模型,而在ELMo中采用的双向的LSTM算法。
2. 算法原理
2.1. GPT的基本原理
与ELMo模型的训练一样,在GPT的训练过程中采用两阶段的过程,第一个阶段是GPT模型的预训练,得到与上下文无关的语义向量的表示,第二阶段在具体任务上Fine-tuning,以解决具体的下游任务。具体的两阶段过程可由下图表示:

2.2. 第一阶段——GPT模型预训练
2.2.1. 与ELMo模型的对比
GPT模型的预训练与ELMo模型的预训练的主要不同集中在两点:
- GPT中采用的是Transformer作为语义特征的提取,而ELMo中采用的是LSTM;
- GPT中采用的是单向的语言模型,即通过上文预测当前的词,而ELMo中采用的是双向的语言模型,即上下文预测当前的词。
GPT模型与ELMo模型的对比可以由下图表示:

完整的Transformer是一个典型的Seq2seq的结构,包括了Encoder和Decoder两个部分,如下图所示:
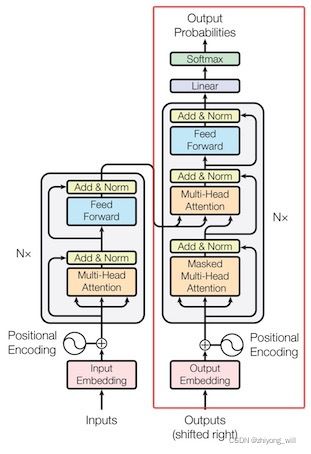
在GPT模型中使用的是Transformer结构中的Decoder结构,如上图中的右半部分,并对上述的Decoder部分进行了一些改动,原本的Decoder中包含了两个Multi-Head Attention结构,分别为Masked Multi-Head Attention和Multi-Head Attention,而在GPT中只保留了Mask Multi-Head Attention。
Q1:GPT采用的是单向的语言模型?
A1:在GPT中采用了Masked Multi-Head Attention,而Masked Multi-Head Attention只利用上文对当前位置的值预测,所以GPT被认为是单向的语言模型。
Q2:GPT中Position Encoding的操作?
A2:在Transformer中,由于Self-Attention无法捕获文本的位置信息,因此需要对输入的词的Embedding加入Position Encoding,在Transformer中采用了sin和cos的计算方法,而在GPT中,不再使用正弦和余弦的位置编码,而是采用与词向量相似的随机初始化,并在训练中进行更新。
2.2.2. GPT模型的预训练
对于GPT模型的预训练,同样采用的是语言模型,即通过上文预测当前的词。假设词的集合为 U = { u 1 , ⋯ , u n } U=\left \{ u_1,\cdots ,u_n \right \} U={u1,⋯,un},语言模型的目标函数为:
L 1 ( U ) = ∑ i l o g P ( u i ∣ u i − k , ⋯ , u i − 1 ; Θ ) L_1\left ( U \right )=\sum _ilog\; P\left ( u_i\mid u_{i-k},\cdots ,u_{i-1};\Theta \right ) L1(U)=i∑logP(ui∣ui−k,⋯,ui−1;Θ)
其中, k k k是窗口的大小。此时需要求此目标函数的最大值。在GPT模型的预训练中,采用的基本特征提取模块是Transformer中的Decoder结构,模型的输入向量 h 0 h_0 h0为:
h 0 = U W e + W p h_0=UW_e+W_p h0=UWe+Wp
其中, U = ( u − k , ⋯ , u − 1 ) U=\left ( u_{-k},\cdots ,u_{-1} \right ) U=(u−k,⋯,u−1)表示的当前词 u u u的以 k k k为窗口的上文, W e W_e We表示的词向量, W p W_p Wp表示的是位置向量,通过上文的词向量和位置向量的和得到当前词的输入向量。经过多个Transformer结构,得到第 l l l层的输出:
h l = t r a n s f o r m e r _ b l o c k ( h l − 1 ) h_l=transformer\_block\left ( h_{l-1} \right ) hl=transformer_block(hl−1)
由于是decoder结构,我们希望得到当前词的位置是词 u u u的概率,即为:
P ( u ) = s o f t m a x ( h n W e T ) P\left ( u \right )=softmax\left ( h_nW_e^T \right ) P(u)=softmax(hnWeT)
以此,我们便可以得到预训练的GPT模型,同时 W e W_e We即为训练好的词向量。
2.3 第二阶段——Fine-tuning
2.3.1. Fine-tuning具体计算
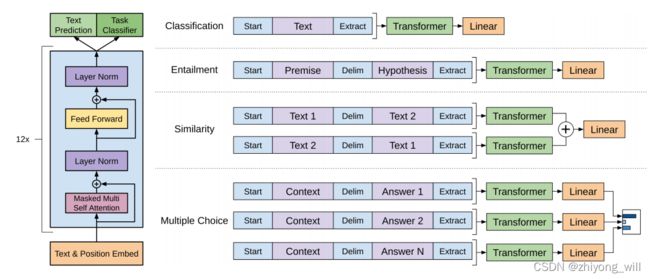
在GPT模型的下游任务中,需要根据GPT的网络结构,对下游任务做适当的修改,具体如下图所示:
假设带有标签的数据集为 C C C,其中,词的序列为 x 1 , ⋯ , x m x^1,\cdots ,x^m x1,⋯,xm,标签为 y y y。实际上就是通过标签 y y y的上文预测当前词是 y y y,假设通过上述第一阶段,得到最后一个词的输出 h l m h_l^m hlm,此时需要预测标签 y y y,即为:
P ( y ∣ x 1 , ⋯ , x m ) = s o f t m a x ( h l m W y ) P\left ( y\mid x^1,\cdots ,x^m \right )=softmax\left ( h_l^mW_y \right ) P(y∣x1,⋯,xm)=softmax(hlmWy)
此时,目标函数为:
L 2 ( C ) = ∑ ( x , y ) l o g P ( y ∣ x 1 , ⋯ , x m ) L_2\left ( C \right )=\sum _{\left ( x,y \right )}log\; P\left ( y\mid x^1,\cdots ,x^m \right ) L2(C)=(x,y)∑logP(y∣x1,⋯,xm)
此时需要使得 L 2 L_2 L2取得极大值,为了能够对原先的网络结构fine-tuning,对具体任务可结合目标函数 L 1 L_1 L1和 L 2 L_2 L2:
L 3 ( C ) = L 2 ( C ) + λ ∗ L 1 ( C ) L_3\left ( C \right )=L_2\left ( C \right )+\lambda \ast L_1\left ( C \right ) L3(C)=L2(C)+λ∗L1(C)
2.3.2. 不同的下游任务构造
对于不同的下游任务,在Fine-tuning的过程中,需要不同的改造方法以适应GPT的模型结构,如上图所示:
- 对于分类任务,只需要在特征序列前后分别加上开始(Start)和结束(Extract)标记;
- 对于句子关系判断任务,如Entailment,除了开始和结束标记,在两个句子中间还需要加上分隔符(Delim);
- 对文本相似性判断任务,与句子关系判断任务相似,不同的是需要对两个句子的位置做变换;
- 对于多项选择任务,则需要根据Context与不同的Answer组合出不同的句子对,分别输入到模型中,句子对的形式与句子关系判断一致。
3. 总结
GPT模型中通过采用Transformer结构中的Decoder作为语义模型的提取模型,可以显著提升文本语义的学习能力,同时两阶段的学习方法对于可以方便的将GPT应用在不同的任务中。
参考文献
[1] Peters M , Neumann M , Iyyer M , et al. Deep Contextualized Word Representations[J]. 2018.
[2] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.