深度学习之注意力机制
视频链接:8.2 人工神经网络中的注意力机制_哔哩哔哩_bilibili
注意力机制与外部记忆
注意力机制与记忆增强网络是相辅相成的,神经网络去从内存中或者外部记忆中选出与当前输入相关的内容时需要注意力机制,而在注意力机制的很多应用场景中,我们的外部信息也可以看作是一个外部的记忆
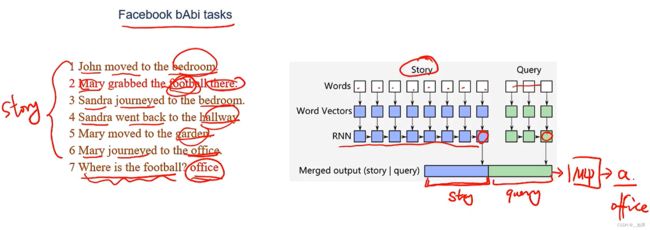
这是一个阅读理解任务,前六句是情景描述,第七句要求它回答足球在哪,这需要模型充分理解情景内容,并作出合理推断
我们用RNN作为编码器,将情景描述的每个词都做embedding,输入到RNN中,最后一个输入的向量得到的hidden state就是整个情景的表示,也就是整个情景的语义表示都隐含在这个story向量里了
再将问题也embedding之后输入另一个RNN,也把最后一个hidden state拿出来作为query
把story和query拼起来送到MLP中,softmax一下,得到分类结果是office
缺点:(1)RNN有长程依赖问题,只能保留短期的记忆,而长期的记忆会被遗忘掉
(2)很多句子是与题目无关的,比如1、3、4句是完全无关的
(3)向量的信息容量是有限的,当情景描述越长的时候,需要记忆的信息就越多,但我们很难用一个低秩的向量表示整个情景的内容。如果增加向量的维度,对于RNN来说,hidden state计算时的U也会随着维数的增加以平方级的形式增加,大大增加了参数量
注意力机制

自下而上的注意力是指某些信息十分突出,例如看报纸时的大标题、图片等,从而导致人将注意力集中过去。Maxpooling就可以起到这样的效果,抑制周边信息,突出强的信息
自上而下的注意力是指人带着某种目的去搜索信息,这时会忽略那些不在目的之内的信息。接下来我们将的attention都是指自上而下的注意力,且是软注意力
软注意力机制
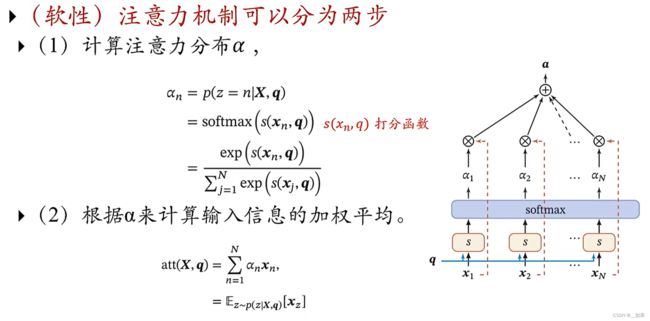
x1...xn是我们的候选信息,q是我们的查询向量,我们用q对每一个x进行打分
第一行式子的意思是在x与q的前提下注意力放在第n个信息的概率
Q:为什么用概率分布而不是01分布?
A:用概率分布表示软性注意力得到的函数是连续的,方便我们优化的时候求导
打分函数
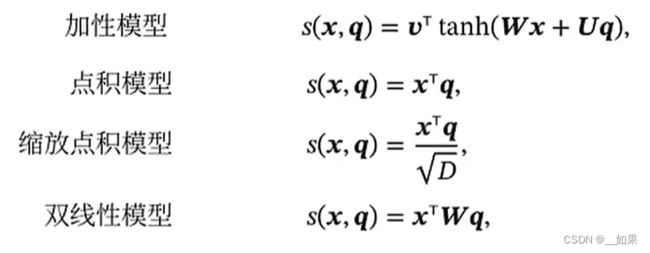
加性模型:把x和q拼到一起送入一个隐藏层
Q:为什么点积模型需要缩放?
A:点积模型的输出是要过softmax的,若x与q的维度比较高,通常意味着点积比较大,会导致softmax的分布更不均衡,从而带来softmax的梯度问题,梯度可能过小,这样不利于我们使用梯度法优化
双线性模型:允许x和q的维度不一样,且可以避免不同的x与q但是内积相同的情况。因为我们希望一个东西在查询和被查询的时候相似度是不一样的,这时候就可以选择双线性模型
硬注意力机制
不是以概率的方式给每个输入的信息都分配一定的权重,而是一个离散的决策,要么1要么0
因为是离散的,所以没有梯度,不能通过梯度法优化,通常和强化学习结合,把它看作是一个连续的决策过程
键值对注意力机制
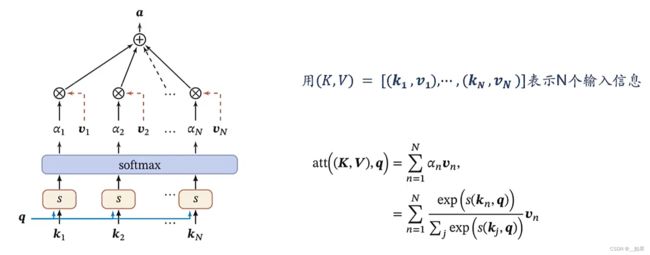
在软注意力中,我们用x进行相似度计算,又用x进行注意力加权。其实可以把这两部分进行一个区分,把每个输入信息拆成两份,用k和q作相似度计算,再用v进行注意力加权
好处:相似度计算时用一种机制,注意力加权时可以使用另一种机制,更加灵活,模型能力更强
多头注意力

一个注意力可以认为是用一个查询去输入信息里面选一个信息
多头注意力就是用多个查询来并行地从输入信息里面选多种信息,希望每个注意力关注输入信息的不同部分,这样我们可以选出更全面的信息
结构化注意力
我们现在的注意力是分布在1~n上面的多项分布,也就是α1+...+αn = 1
但我们可以把注意力分布换成n个01分布
同时,每个位置上的01分布又会受其他位置上的分布影响
但是这种注意力分布相对来说比较复杂,很难去计算联合概率,所以这种方法用得也少
指针网络
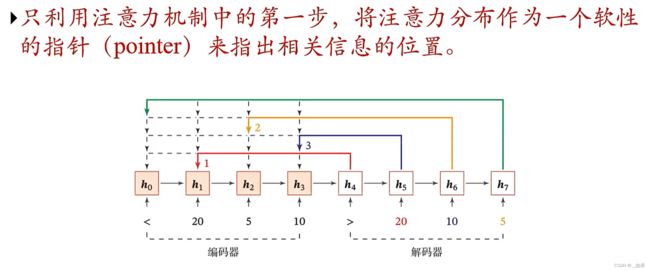
用来指出我们的候选信息中有哪些是和任务查询向量q有关的,不需要第二步的将信息抽取出来做加权汇总,这里的pointer是一个概率
例如之前阅读理解的例子,我们只需要指针把答案所在位置指出来就行了,不需要把答案进行加权汇总得到它的向量表示
图中是用注意力机制给数组排序的例子,<表示输入数组的开始,>表示现在开始排序,我们输入一个20,5,10的数组,希望得到一个降序排序的数组。它不适合我们语言模型中的那种预测,因为数组是会变的,下次可能输入40,60,10它就无法排序正确了
首先我们用>的hidden state作为查询q去和h0~h3(候选信息)进行相似度计算,找到相似度最高的h1并指向它。h4指向的h1对应的候选信息作为输入,计算hidden state后作为查询q找到h3。以此类推。最终我们就得到了hidden state指向的下标,也就是1,3,2,从而知道了原数组应该如何排序正确
注意力机制的应用
文本分类
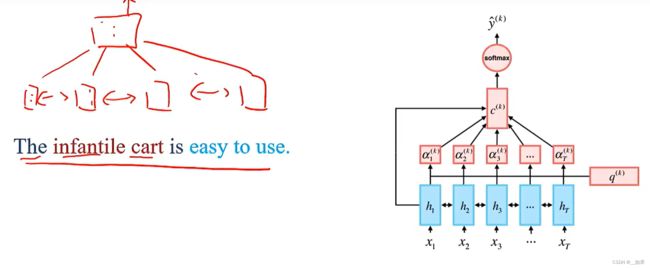
对RNN来说,文本分类是将每个词embedding之后计算hidden state,最后一个hidden state就代表了整句话的语义
对双向RNN来说,文本分类是将每个词embedding之后双向计算hidden state,然后做一个加权平均得到一个代表整个句子的语义信息的向量
但如果我们的分类目标不同,例如我们想判断这句话是在讲电器还是讲木制品等等,我们应该更加关注infantile cart;我们想判断这句话的情感,我们应该更加关注easy to use。但RNN想要做到这些只能去训练一些专门的网络,并不高效
而我们使用注意力机制,只需要添加一个查询向量q,就可以时一个RNN同时满足多种不同需求。其中RNN是通用的,不需要学习与任务相关的领域知识,而查询向量q是一个可学习的向量,去匹配不同的任务

对同一段文字用不同的q做情感分类,上面的q为Books,注意力关注的结果为一些与书相关负面的情绪lack,而下面的q为DVD,注意力关注的结果为一些与DVD相关的正面的情绪quite beautiful
层次注意力模型
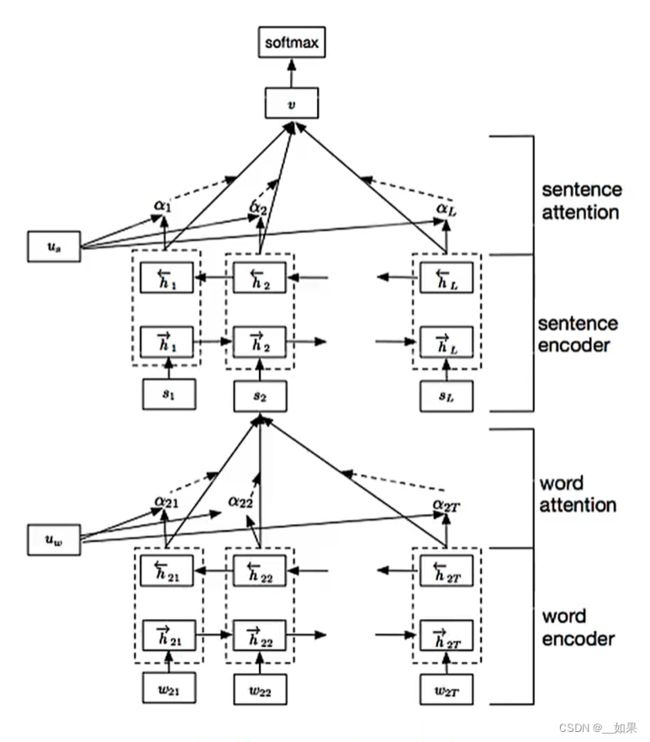
一篇文章由很多的句子组成,一个句子由很多的单词组成,这是一个天生的层次化结构,因此我们可以把注意力也做成一个层次化的结构
将单词embedding之后经过一个双向LSTM得到hidden state,再利用一个句子级别的注意力向量对每个词注意力打分,再加权汇总得到句子的表示。把得到的句子表示再丢进一个双向LSTM得到hidden state后再利用一个句子级别的注意力向量对每个句子打分,加权汇总得到文章的表示。其中两个句子级别的注意力向量都是可学习的
机器翻译

用RNN做机器翻译的问题在于s难以表示句子中所有的信息,且RNN具有长程依赖问题
用注意力机制改善的方法是,保留encoder的每个hidden state作为候选信息,查询向量q就是我们decoder中上一步的hidden state,decoder中每一个hidden state的计算是通过上一步的输出+上一步的hidden state+上一步hidden state与候选信息得出的attention一起计算得到的。因此这里的q不再是可学习的了
另一个好处是由于attention的存在,计算decoder输出的loss时使用梯度下降,可以直接从输出到hidden state到encoder,缩短了计算路径,避免了梯度消失的问题
看图说话
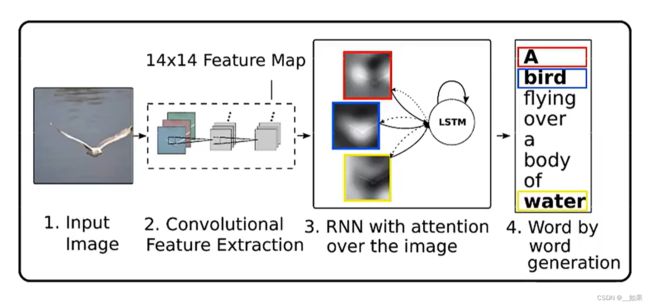
用attention去feature map中选一些与生成词最相关的attention map出来(越亮的地方注意力分数越高),比如我们生成A的时候,看红色框中的注意力放在左右两个翅膀上;生成bird的时候注意力放在鸟上;生成water的时候注意力放在周边的环境上
阅读理解

x1~xn是我们的上下文内容,q1~qj是我们的问题
首先要实现词对词的双向注意力,query中的每个词都去context中把相关的信息选过来,然后context中的每个词也去query中把相关信息选过来,最终把所有信息堆加到context上,经过两个双向LSTM,预测答案开始在哪里,结束在哪里
自注意力模型
不需要外部的查询向量q
引言
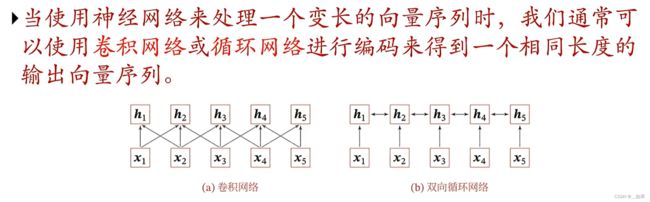
这两种网络都能解决变长序列的问题,但它们都只能建模输入信息的局部依赖关系
如果我们想构建长的非局部依赖关系呢?
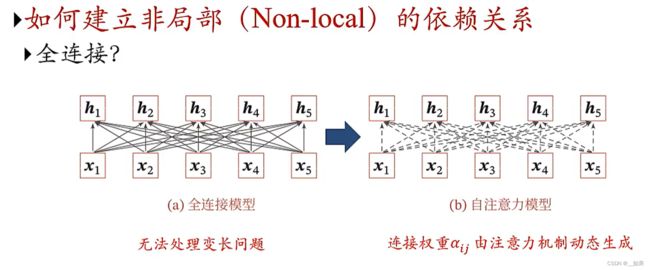
全连接的每个hidden state都是由所有的输入计算得到的,但是其无法处理变长问题,且全连接的hidden state计算只与位置相关,与内容无关,比如此时我换成x2~x6,连接的权重是一样的,可是通常内容的相关会影响结果,x1与x2组合和x2与x6组合得到的内容是不一样的,这也导致全连接不擅长建模数据的语义关系
我们希望能把全连接静态的权重矩阵用动态的权重矩阵来代替,于是就有了自注意力模型
自注意力模型示例
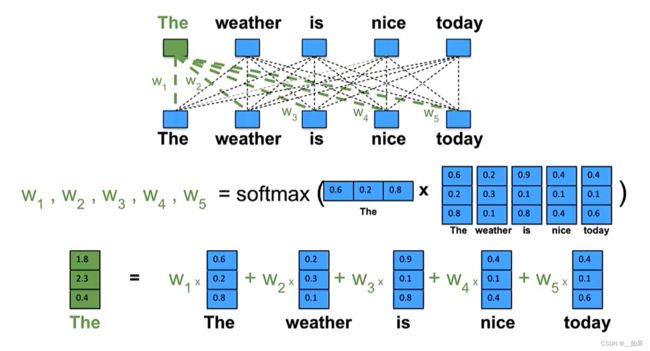
我们以一句自然语言的建模为例,我们希望每个单词都能与其他单词有长的非局部依赖关系,也就是希望得到这五个单词与其中某个单词组合时(The The、The weather、The is...)的权重
计算The时,我们用The作为查询向量q,去和这个句子中每个词计算相似度的得分,过一个softmax得到对应的权重w1~w5,也就是注意力分布,接着用注意力分布对每个词进行语义组合,就得到了The的上下文表示
矩阵表示
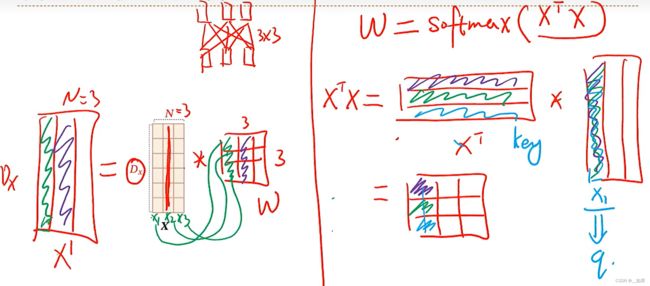
Dx是每个词向量的维度,N是词向量的个数,也就是有几个词
通过自注意力机制得到每个词之间的上下文关系的矩阵表示,是由原矩阵*X的转置乘X得到的。这里的X的转置乘X就是我们的动态权重矩阵W,X的转置中每一行代表了每个词,也就是key,而X中的每一列代表的是query。因此求解W的过程就是注意力机制中的第一步——计算相似度,原矩阵*W是注意力机制中的第二步——注意力分布加权汇总

这个式子就是自注意力机制的矩阵表示
QKV模式
在自注意力模型中,X既是key、value,又是query。因此我们可以把X拆成这三部分

好处:引入三个参数化矩阵WqWkWv,使自注意力矩阵可学习,原来的注意力矩阵是X.T*X,不可学习
多头自注意力模型
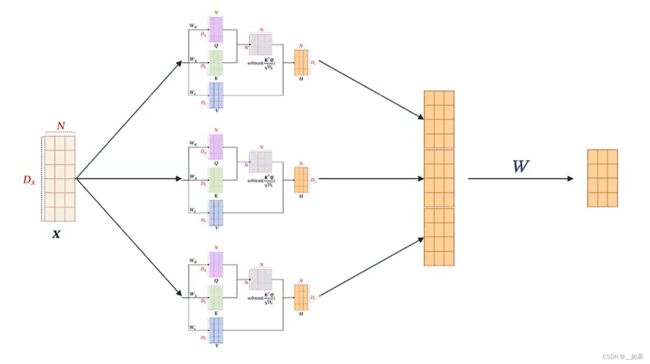
把X投到多个QKV模式上,每个模式中的参数化矩阵WqWkWv都不一样,可以在不同的空间上建模它们的上下文关系
然后把每个head的输出拼起来经过一个W使其维度变回DX
和卷积网络里的通道十分像,在不同的channel上计算不同的特征;这里是在不同的head上计算不同的语义组合
Transformer

如果我们只通过自注意力机制来搭建网络,这是不远远不够的
位置编码
自注意力机制的动态权重矩阵其实只和内容有关,也就是x1、x2、x3的加权汇总与x2、x1、x3的加权汇总是一样的,而在序列中位置信息也是一种很重要的信息
若自注意力模型与CNN、RNN结合,那么位置信息一定程度上可以由CNN、RNN提供,但只有自注意力模型的时候,就需要引入位置信息,就有了位置编码
把每个输入序列的位置编码成一个向量,然后将这个向量和我们的x直接加起来,这样我们得到的新的x既有内容又有位置表示
层归一化
使模型更深
直连边
残差连接,x+z,z是经过自注意力计算的x
逐位的FFN
每一个词向量都经过一个FFN层,FFN层是先升维再降维的前馈层,功能类似于1x1卷积
与传统序列比较
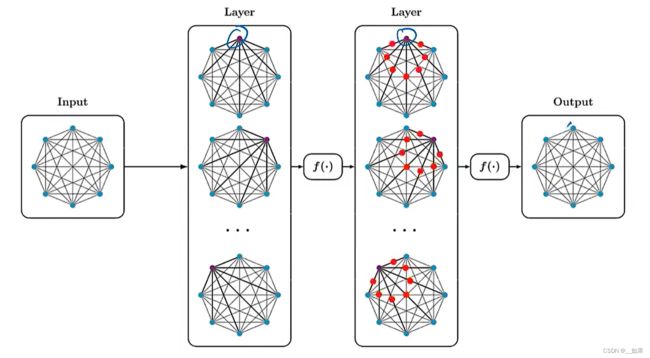
最大的区别是传统序列需要一步步交互
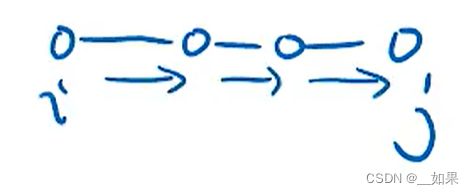
而Transformer一步就可以
复杂度分析
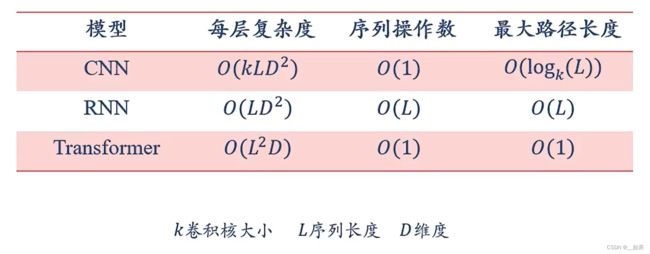
由图可以看出,Transformer最大的问题是无法处理太长的信息
网络结构
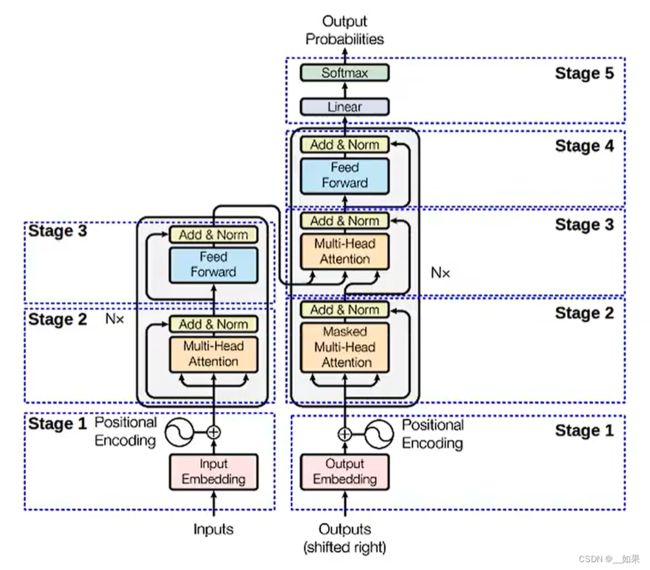
因为Transformer的提出就是用来做机器翻译的,所以在这里分为encoder和decoder两部分
左边的encoder部分在上面已经详细分析过了
右边的是decoder部分
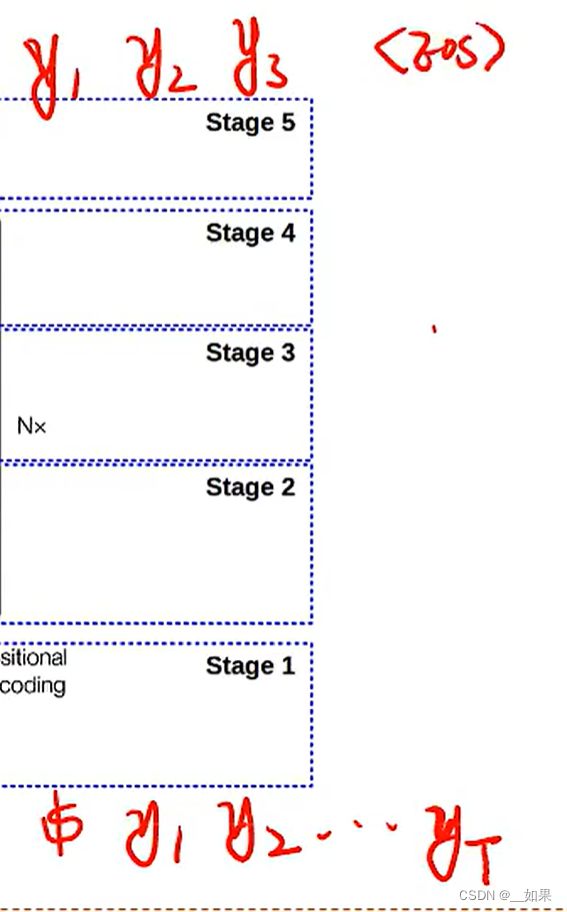
Teacher forcing
输入的outputs括号中的shifted right意思是将encoder中的inputs右移1位,原因是遵循Teacher forcing原则,也就是输入时要确保之前的输入是正确的,也就是输入y3时要确保$、y1、y2是正确的,所以只需要把encoder中的inputs右移1位就行了
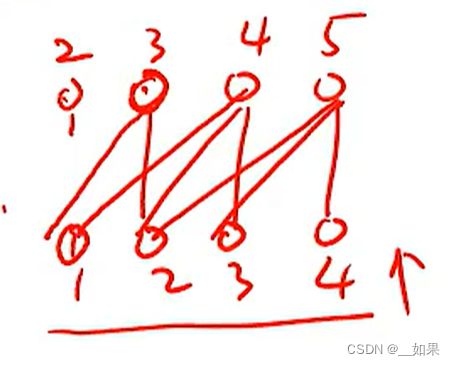
Masked
我们只允许输出的信息往前看,而不能往后看,因为往后看就会漏答案,也就是在预测3时看见了3、4、5...这样是不对的。所以我们将后面的信息做掩码遮住
注意事项
Transformer训练数据量越大,它的效果就越好,它的层数也可以变得更深
因为Transformer实在太复杂,如果直接把Transformer用在小数据集上,它的过拟合是十分严重的,因此我们往往需要调用预训练模型
参考文献推荐
左边讲解了Transformer的原理以及它的各种变体
右边讲解了自然语言处理中的预训练模型,怎样通过设计一个预训练任务来训练一个更好的Transformer,并且更好地运用到下游任务
外部记忆

人的记忆是按内容寻找的,我们想回想起某件事情通常只能靠某些相似的事件触发

人的记忆容量其实很小,因此当人遇到需要记忆的事情时,通常需要把这件事用笔或其他方式记录下来,需要的时候再去查看
神经网络的外部记忆也是如此,把需要记忆的内容存起来,需要的时候再去读,这样可以给神经网络增加记忆容量
记忆网络
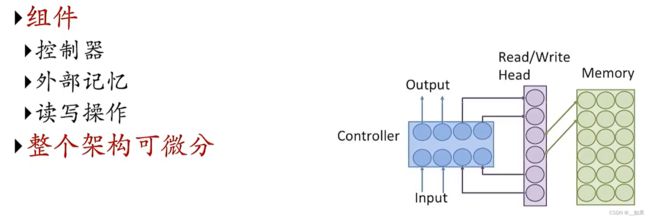
记忆增强网络
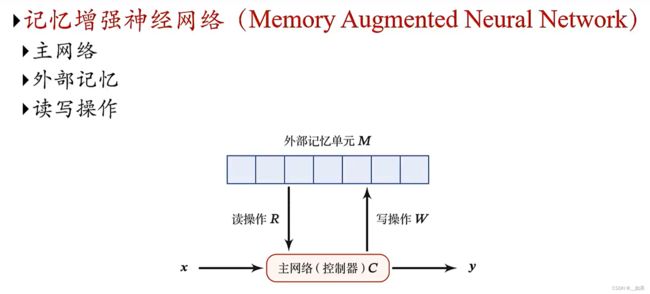
最重要的部分便是外部记忆单元的设置,下面将介绍两种设置方法
神经图灵机
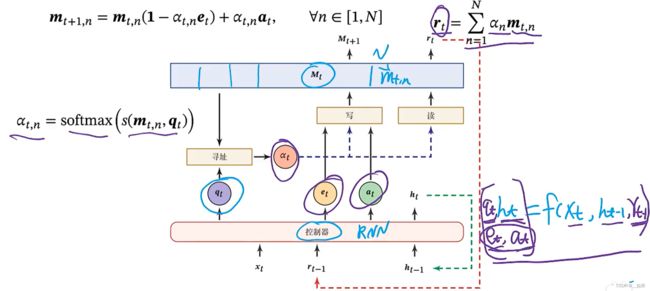
qt,et,at的产生可以是RNN输出一个更高维的向量然后进行分割得到
et是需要删掉多少记忆,at是需要记住多少记忆
输入由xt、ht-1、rt三个部分组成
可读写与只读
可读写的网络的表现的方差比较大,所以训练起来是比只读的网络要难的
结构化外部记忆
矩阵
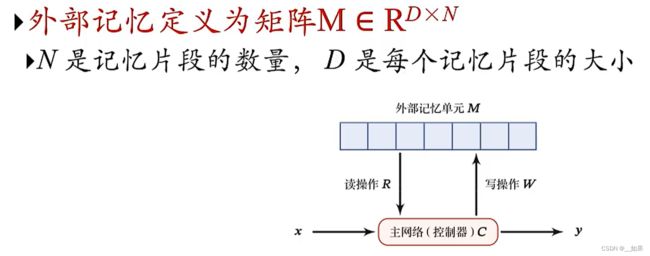
如何进行读写操作呢?
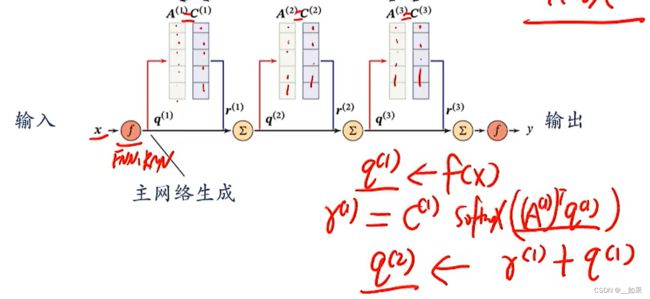
读写之前先要做寻址操作,而外部记忆的寻址是通过注意力机制来执行的
在主网络中产生一个查询向量q,q去记忆单元里面匹配,找出需要读的记忆单元
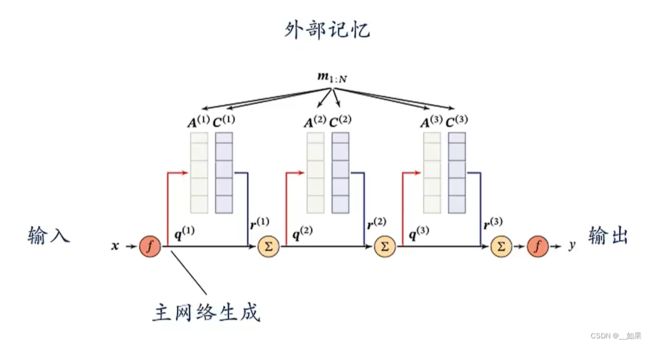
拿之前的阅读理解为例,可以把整个story当作外部记忆,m是阅读理解中的每个单词,在这里的外部记忆是只读的,不可写
外部记忆的取值是非常灵活的,你可以直接把每个单词做embedding作外部记忆,也可以把整篇文字embedding作外部记忆,还可以做完embedding之后再过一个RNN等等,不同形式的外部记忆可能带来的效果是不同的
基于神经动力学的联想记忆

大部分机器学习都属于异联想
神经网络如何联想

Hopfield网络
初始化每个神经元的状态,每个神经元接收其他神经元(不包括自己)的信息用来更新自己的状态
和循环神经网络很像,但是Hopfield只在初始化时接收外部信息,后续更新都是内部更新
离散型Hopfield更新过程
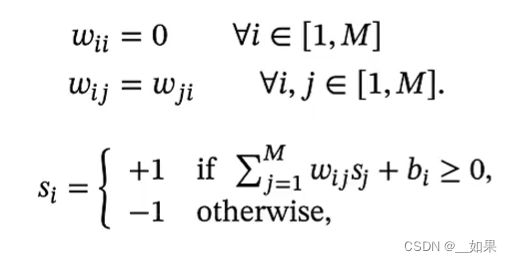
神经元之间的连接是有对称性的,si表示第i个神经元的状态
能量函数

Hopfield网络能实现的前提是s能够收敛于某个值,但是我们怎么确保s一定能收敛呢?
E = -1/2×边的权重×两端点的状态 + bisi,其中1/2是因为神经元的连接是对称的
若Et恒大于等于Et+1,则可收敛
检索过程

不同的状态对应了不同的能量,且这条曲线是非凸的
由于能量只能减少,所以一个状态只能落在一个吸引点,因此吸引点可以看作是记忆的储存点
存储过程

当xi与xj(si与sj)同时为1或-1时,wij会更大,和人脑的运作方式一样
结构记忆与联想记忆比较

但联想记忆的存储容量小,每1000个神经元只能存储138组向量