Intel自顶向下微架构分析方法
现代 CPU 使用流水线(pipelining)以及硬件多线程、乱序执行和指令级并行等技术来尽可能有效地利用资源。尽管如此,某些程序包含的代码和算法还是会破坏流水线的完美执行。例如,我们在程序中常见的链表类型,获取下一个表项中的内容时,会导致间接寻址,从而破坏了硬件预取的效果。这种情况下,当前的流水线将会被清空,而且只会进行取指操作,不会有其他的指令会被执行。使用链表可能是程序的最佳解决方案,但不一定是最有效率的方法。在软件层面还有许许多多的对底层CPU流水产生影响的例子。自顶向下的微架构分析方法旨在当你需要选择算法或数据结构时,提供一些的理论参考依据。
CPU流水线架构
Intel将流水线中的处理分为前端(front-end)和后端(back-end)两部分
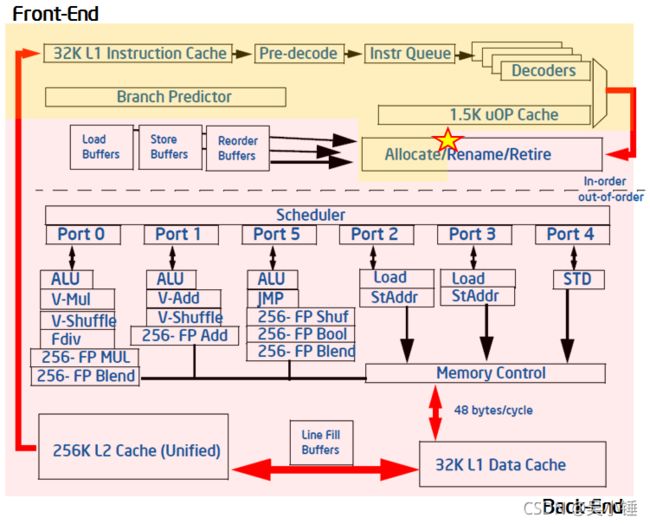
前端(front-end)
前端的主要部件如下:
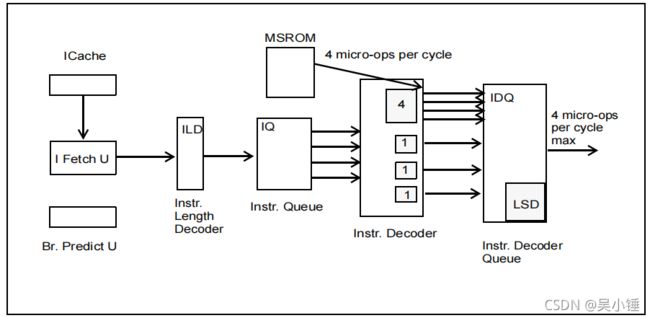
指令获取单元(IFU)每个周期可以从I-cache中提取16字节的指令并推送至指令长度解码组件(ILD),解码后将指令保存到指令队列(IQ)当中。
指令解码器(Instr Decoder)每周期可以从IQ中获取4个指令。指令解码器有3个简单指令解码单元,每个单元每周期可以解码1个简单指令。还有一个复杂指令解码单元,每个周期可以解码一个简单指令或者复杂指令。每条指令可以解码为1个或数个微操作(uops),并存储到指令解码队列(IDQ)当中。如果是由超过4个微操作构成的复杂指令,则是从MSROM中获取的,而不是从I-Cache中。
前端的基本组成部件及功能总结如下:
| 组件 |
功能 |
性能挑战 |
| 分支预测单元 (Branch Prediction Unit) |
* 通过预测各种分支类型:条件(conditional)、间接(indirect)、直接(direct)、调用(call)和返回(return),帮助指令预取单元获取最有可能执行的指令。每种类型由特定的硬件来完成。 |
* 减少代码分支或者分支代码的总量,来提高推测执行单元的效率。 |
| 指令提取单元 (Instruction Fetch Unit) |
* 预取最有可能执行的指令 * 缓存频繁使用的指令 * 预解码和缓冲指令,维持固定带宽的指令流。 |
* 不同长度的指令会致使解码的带宽得不到充分利用 * cache line未对齐的目标会增加额外的传输带宽 |
| 指令队列和解码单元 (Instruction Queue and Decode Unit) |
* 最多可解码 4 条指令,或开启了Macro-Fusion功能的 5 条指令 * 用于高效处理进入和退出的堆栈跟踪算法 * 实现Macro-Fusion功能,提供更高的性能和效率 * 指令队列还用作循环缓存,使某些循环处理能够以更高的带宽和效率执行 |
* 指令前缀增加了解码的复杂度。 * 长度变化的前缀 (LCP) 会导致前端产生空闲气泡。 |
Pipeline Slot
Intel微架构的流水线前端每个周期可以分配4个微操作(uops),同时后端每个周期可以退休4个微操作。这里引入一个pipeline slot的概念,一个pipeline slot就代表了处理一个微操作所需要的全部硬件资源。假设对于每个cpu核,在每个时钟周期上,都有4个pipeline slot可以使用。cpu中使用专门设计的 PMU 事件来测量这些pipeline slot的利用情况。pipeline slot的状态在分配点(图一中用星号标记)处获取,即微操作离开前端到后端的时间点。
在任何一个周期,一个pipeline slot可以是空载的或者是填充了微操作的。如果一个pipeline slot在一个时钟周期是空载的,那么可以称之为流水线停顿。下一步就要分析是前端还是后端的原因导致了停顿。
一般来说,如果停顿是由于前端无法用微操作来填充pipeline slot,那么当前的pipeline slot可以归类为前端屏障(front-end bound),意味着性能受到了一些前端的瓶颈限制。如果前端准备好了一个微操作,但是由于后端没有准备好处理它而无法交付给后端,那么这个pipeline slot将被归类为后端屏障(back-end bound)。后端停顿通常是由后端耗尽某些资源(例如加载缓冲区)引起的。如果前端和后端都停顿了,也将pipeline slot归为后端屏障。这是因为,在这种情况下,修复前端中的停顿很可能无助于提升应用程序的性能。由于后端是阻塞瓶颈,需要先将其移除,然后才能分析前端问题所产生的影响。
如果流水线没有停止,那么pipeline slot将在分配点被微操作填充。在这种情况下,如何对pipeline slot进行分类取决于微操作是否能成功退休(retiring)。如果确实退休了,那么将pipeline slot归类为退休类型。如果没有,可能是前端的分支预测错误或者是一些自修改代码导致的流水线刷新引起的,都将其归类为错误推测(bad speculation)类型。这四种分类组成了自顶向下分析方法的最上层特征。为了评估一个应用程序,每个pipeline slot都被归类为以下四类之一:
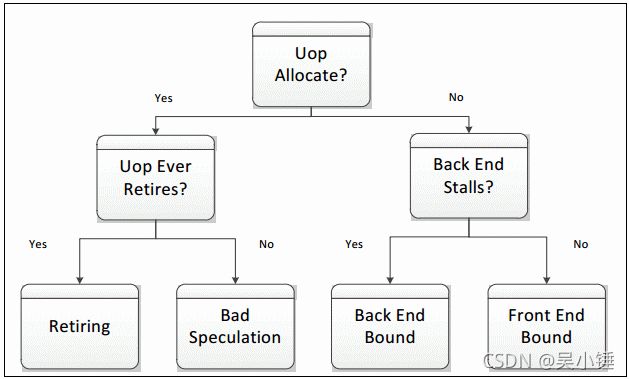
将pipeline slot归为这4类非常有用。尽管基于PMU事件的度量已经存在多年,但在此特征之前,还没有哪种方法可以确定哪些潜在的性能问题影响最大。当性能指标被放入到这个框架时,你可以看到哪些问题需要首先解决。从Intel的Sandy Bridge架构开始,就可以将pipeline slot归类为这4类。
基于时钟(clockticks)的性能表示 VS 基于pipeline slot的性能表示
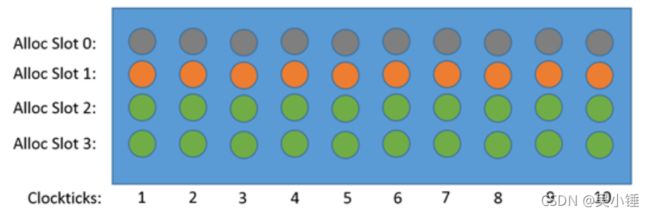
Intel VTune Profiler 提供基于clockticks和基于pipeline slot的事件采集方法。如上图所示,每个时钟周期都有2个slot是无用操作,用pipeline slot表示的话,当前cpu的有效利用率为50%。如果用clockticks描述的话,每个周期的停顿指标就是100%。在每个周期引起停顿的原因可能有多种,如果用clockticks来表示的话,某些指标可能会有所重复。因此,用clockticks测量的精度会低于pipeline slot,但是在识别性能的主要瓶颈时,这个指标还是有用的。
Intel Vtune Profiler中的微架构探索方法
Intel VTune Profiler中的Microarchitecture Exploration分析类型用于收集自顶向下特征中定义的事件,并将这4种pipeline slot类型作为最顶层的性能指标。
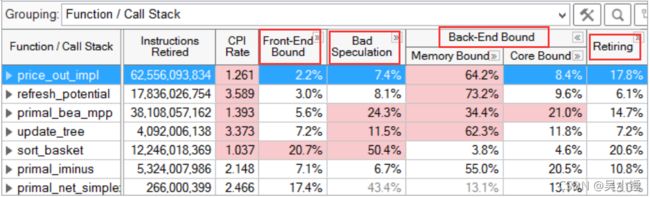
采用Microarchitecture Exploration抓取的结果示例如上图所示,整个应用程序的每个类别pipeline slot的占比可以清晰展示。对于每个函数,都能显示每个类别中pipeline slot的占比。
例如, price_out_impl有 2.2% 的pipeline slot属于前端屏障,7.4% 的错误推测,72.6%的后端屏障,后端屏障由分为64.2% 的内存屏障(memory bound)和8.4% 的核心受限(core bound),以及 17.8% 的退休。每种类别都可以展开以查看更详细指标。
微架构调优方法
在进行性能调优时,需要重点关注应用程序的顶级热点。热点是占用 CPU 时间最多的函数。 优化这些热点函数将会提升整个应用程序的性能。VTune提供两种热点分析方法,用户采样模式(user-mode sampling)和硬件事件采样模式(hardware event-based sampling)。在采样结果视图中,函数或模块的热点是以时钟滴答(clockticks)来计算的。
从微架构优化的角度来看,通常应该最先执行系统级别的调优,然后是程序算法级别的调优,然后才是代码架构和微架构的调优。这个过程也称为是自顶向下程序调优方法。
微架构调优方法:
- 选择一个热点函数(一个在应用程序总时钟中占很大比例的函数)。
- 使用自上而下的方法评估该热点的效率。
- 如果效率低下,则深入分析主要瓶颈的类别,并使用下一级指标来确定原因。
- 优化问题。
- 重复分析,直到所有重要的热点都被评估。
在VTune中,如果在热点中的度量值超过了预定义的阈值,则会在窗口中突出显示。如果一个函数消耗超过了程序总cpuclocks的5%,则将其归为热点。确定pipeline slot是否是瓶颈取决于工作负载,Intel给出了一些通用程序中pipeline slot的合理占比。
| 类别 |
客户端/桌面应用程序 |
服务器/数据库/分布式应用程序 |
高性能计算 (HPC) 应用程序 |
| 退休 |
20-50% |
10-30% |
30-70% |
| 后端屏障 |
20-40% |
20-60% |
20-40% |
| 前端屏障 |
5-10% |
10-25% |
5-10% |
| 错误推测 |
5-10% |
5-10% |
1-5% |
这些阈值是基于英特尔实验所得。如果某个热点在某个类别上比例大于指示的范围,则进行调优可能会有用。如果多个类别都处于合理范围,则应花时间调查比例最高的类别。在正常范围内较低的值表示当前函数或模块并不存在性能问题,那就不需要花时间优化未被识别为瓶颈的类别, 因为这样做可能对性能提升无益。