黑马程序员Javaweb重点笔记(二) (2023年版)
文章目录
- 前言
- Mybatis入门介绍
- JDBC介绍
- lombok技术
- Mybatis基础操作
- Mybatis动态SQL
前言
我个人有一个学习习惯就是把学过的内容整理出来一份重点笔记,笔记往往只会包括我认为比较重要的部分或者容易忘记的部分,以便于我快速复习,如果有错误欢迎大家批评指正。
另外:本篇笔记大部分参考了JavaWeb这个专栏的文章,相当于是这个专栏的压缩版,特此鸣谢作者「_Matthew」
版权声明:本文为CSDN博主「_Matthew」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_46225503/article/details/130778031
Mybatis入门介绍
Mybatis是一款优秀的持久层框架,简化了JDBC的开发
使用Maven来构建项目,需要将下面的依赖代码配置于pom.xml文件中:
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
下面是一个简单的查询案例:
1、引入Mybatis相关依赖,配置
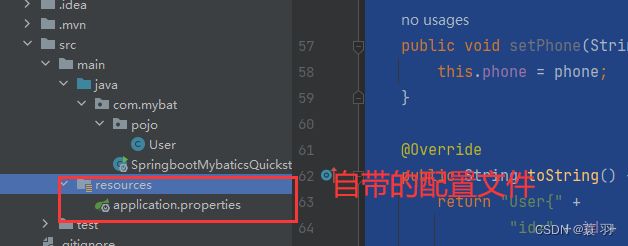
#驱动类名称
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#数据库连接的ur1
spring.datasource.url=jdbc:mysql://localhost:3306/mybatis
#连接数据库的用户名
spring.datasource.username=root
#连接数据库的密码
spring.datasource.password=**********
2、在UserMapper这个接口中定义方法
@Mapper//在运行的时候,会自动生成该接口的实现类对象(代理对象),并且讲该对象交给IOC容器管理
public interface UserMapper {
@Select("select * from user")//想要实现其他的功能也类似,比如@Delete等等
//查询全部的信息
public List<User> list();
}
3、在测试类中调用接口中的方法
@SpringBootTest
class SpringbootMybaticsQuickstartApplicationTests {
@Autowired//自动注入对象
private UserMapper userMapper;
@Test
public void testListUser(){
//调用userMapper中的list方法
List<User> userList = userMapper.list();
userList.stream().forEach(user -> {
System.out.println(user);
});
}
}
4、执行测试就能完成查询用户的功能
JDBC介绍
这一部分现在基本都被其他的框架给封装好了,所以大部分时候不需要个人具体操作,但是属于传统的基础知识,根据个人情况决定是否需要深入了解
JDBC:(Java DataBase Connectivity),就是使用Java语言操作关系型数据库的一套API
数据库连接池:
数据库连接池负责分配、管理数据库连接。如果没有数据库连接池,人员想要访问数据库就要创建一个新的数据库连接对象,执行完毕之后要关闭连接对象,这样会浪费很多的时间,因此有了数据库连接池,如下图所示:

常见的数据库连接池产品有:C3P0,DBCP,Druid,Hikari(Springboot默认)
Druid(德鲁伊):是阿里巴巴开源的数据库连接池,功能强大,实际开发中使用比较多
lombok技术
简单来讲就是你加一个注解就可以免去很多比较臃肿的定义,比如在实体类上加一个@Data就可以不需要定义get(),set(),toString()方法
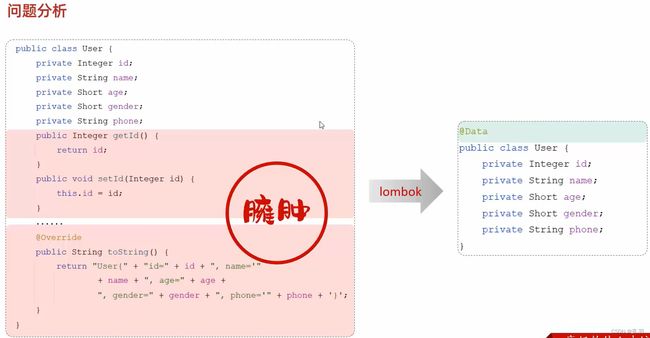
下面是几个常用的注解:
@Data 生成代码功能( @Getter + @Setter + @ToString +@EqualsAndHashCode)
@NoArgsConstructor 为实体类生成无参的构造器方法
@AllArgsConstructor 为实体类生成除了static修饰的字段之外带有各参数的构造器方法。
使用的前提也是需要在pom文件中加入lombok的依赖
Mybatis基础操作
Mybatis基础操作就是利用Mybatis实现数据库表的增删改查
这个部分有一些具体的操作流程,需要一些截图和实体类才能比较清晰,可以看下面这篇文章的对应部分跳转链接
Mybatis动态SQL
什么是动态SQL?
在页面原型中,列表上方的条件是动态的,是可以不传递的,也可以只传递其中的1个标签或者2个标签或者全部
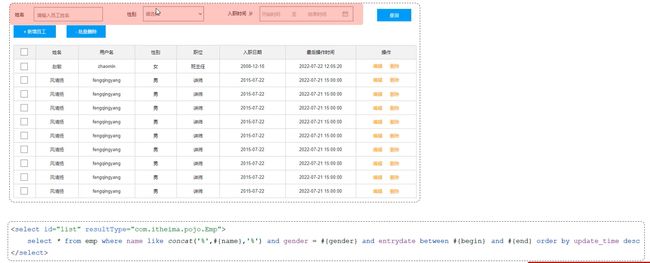
主要就是把原始SQL中一些地方换成标签的形式,比如where等
示例:把SQL语句改造为动态SQL方式
- 原有SQL语句
<select id="list" resultType="com.itheima.pojo.Emp">
select * from emp
where name like concat('%',#{name},'%')
and gender = #{gender}
and entrydate between #{begin} and #{end}
order by update_time desc
</select>
- 改造为动态SQL之后
<select id="list" resultType="com.itheima.pojo.Emp">
select * from emp
<where>
<!-- if做为where标签的子元素 -->
<if test="name != null">
and name like concat('%',#{name},'%')
</if>
<if test="gender != null">
and gender = #{gender}
</if>
<if test="begin != null and end != null">
and entrydate between #{begin} and #{end}
</if>
</where>
order by update_time desc
</select>
小结:
用于判断条件是否成立,如果条件为true,则拼接SQL
形式:...
where元素只会在子元素有内容的情况下才插入where子句,而且会自动去除子句开头的AND或OR
动态地在行首插入SET关键字,并删除额外的逗号。(用在update语句中)
下面是使用案例:
<foreach collection="集合名称"
item="集合遍历出来的元素/项"
separator="每一次遍历使用的分隔符"
open="遍历开始前拼接的片段"
close="遍历结束后拼接的片段">
</foreach>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.mapper.EmpMapper">
<!--删除操作-->
<delete id="deleteByIds">
delete from emp where id in
<foreach collection="ids" item="id" separator="," open="(" close=")">
#{id}
</foreach>
</delete>
</mapper>
sql&include
存在的问题:
在xml映射文件中配置的SQL,有时会存在很多重复的片段,此时就会存在很多冗余的代码,比如下面加深颜色的两行:

可以利用
<sql id="commonSelect">
select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp
</sql>
<select id="list" resultType="com.itheima.pojo.Emp">
<include refid="commonSelect"/>//这个地方就是抽取出去的部分
<where>
<if test="name != null">
name like concat('%',#{name},'%')
</if>
<if test="gender != null">
and gender = #{gender}
</if>
<if test="begin != null and end != null">
and entrydate between #{begin} and #{end}
</if>
</where>
order by update_time desc
</select>