使用labelImg制作数据集并用于YOLOV5模型训练
LabelImg是图形图像注释工具。它是用Python编写的,并将Qt用于其图形界面。
目前LabelImg支持YOLO和PascalVOC2种格式,前者标签文件后缀是.txt件,而后者标签文件后缀是.xml件。YOLOv5算法所支持的数据格式为YOLO。图片和保存标签的文件名是对应的,只是扩展名不同(例如:00001.txt和00001.jpg)。标签保存在对应的labels文件夹下,与images中的图片文件名一一对应。
在这里补充下两个常用的制作标签数据集的工具labelImg和labelme的区别
labelimg是一种矩形标注工具,常用于目标识别和目标检测,其标记数据输出为.xml和.txt
labelme是一种多边形标注工具,可以准确的将轮廓标注出来,常用于分割,其标记输出格式为json
总之:labelImg和labelme都是训练数据集时,用于给数据集打标签的软件,但一个是矩形框,一个是可以标记不规则边缘,用于CV的不同领域。
本文主要使用labelImg制作自己的数据集并用于YOLOV5模型训练,给出YOLOV5下载地址:GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite
1、labelImg的下载即安装:
方法一:labelImg的安装——Win10
Win10可以直接下载简易版exe文件,下载地址:https://github.com/tzutalin/labelImg/releases,选择windows_v1.8.1.zip,下载并解压,直接双击exe文件点开即用,下载后,发个快捷方式到桌面就可了
方法二:labelImg工具原github下载地址
mirrors / tzutalin / labelimg · GitCode
方法三:如何你安装了Anaconda环境,那么在Anaconda Prompt输入命令(作者就是这样的):
pip install labelImg
等待下载完毕后再接着输入命令以下命令启动:
labelImg
启动后labelImg的界面:

2、使用labelImg制作自己的数据集
先给出最终我们需要制作的yolo格式的数据集,如下:

其中,images是存放图片的位置,labels是存放图片对应的标签,而yolo的标签是某个图片的类别及boundingbox的坐标及大小。labels文件夹下的标签就是需要使用labelImg生成,最后的buffaloLion.yaml是训练yolov5时的数据集配置文件,需要我们先创建,后面会说如何配置。
2.1切换至YOLO模式

2.2 打开数据集文件夹以及labels文件夹
点击Open dir选择我们训练图片所在的文件夹images,选择之后会弹窗让你选择labels所在的文件夹。labels文件夹需要自己建立,名字随意,目的是用来存储图片标注后的信息。如果第二个弹窗没有弹出或者选错了,可以点击change save dir进行修改。以下是本文案例样式。

执行上面两步的结果如下:

2.3 建立类名

2.4 开始标记

常用快捷键:w,a,d
w—创建一个检测box,就是方框
a—前一张图片
d—下一张图片
Ctrl + s——保存结果,先前View中勾选了Auto Save mode后,只需框选,然后下一张,就能自动保存
框选错误可以通过EditRectBox来删除,选中错误框后,按delete
标记完成后,labelImg生成的标签放在labels文件夹下:

生成的标签文件格式:class x_center y_center width height 。每行表示一个目标对象,每行中的第一个数表示目标类别,计数从0开始,比如这里的0代表的橘子。后面的4个值代表目标真实框中心点(x,y)和真实框的宽、高信息。生成的标签文件的内容如下:
打开某个标签txt文件:

class.txt是标签的所有类别名称:
后面的图片及生成的标签类似上述操作,最终会在labels文件夹下生成所有images文件下图片对应的标签。
3、编辑数据集配置文件***.yaml
buffaloLion.yaml(名称自己取),是一个yolov5模型进行训练时加载的数据集配置文件,比如:yolov5模型从官网下载下来时,有coco.yaml文件等,如下:

因此,我们需要根据这些配置文件的信息,换成自己的数据集的配置文件,这样在使用yolo模型训练时它才会知道如何加载我们自己的数据集。
自行创建一个yaml文件,文件的内容如下:
#path为自己数据集的文件夹名称,要根据的数据集放置自己项目路径下的哪个位置进行更改 path: ./mydata #train是训练时加载的图片或者标签的路径 train: images/train #val是验证时加载的图片或者标签的路径 val: images/train #test是测试时加载的图片或者标签的路径 test: images/test # 类别数 nc: 2 # 类别名称 names: ['buffalo','lion']
其中需要自己修改的内容为:
train与val后的地址,地址均指向训练图集的文件夹。以及names后的内容,nc类别数。
提示:train与val文件夹下的图片和标签需要自己进行划分哦。记得图片和标签要对应上。
注意 label不用配置:train.py在训练过程中,会将路径中的images替换为 labels来寻找labels数据
至此训练模型的数据就准备好了。
4、 编辑models模型配置xxx.yaml文件
在yolov5项目下进入models/目录,可以看到有四个模型配置的yaml文件:

表示训练时,你选中的yolov5的模型结构,这里根据自己的需求选择其中一个的模型,并将模型的配置文件yaml进行修改。
这些Model的yaml文件中都是模型网络相关配置参数,例如nc下面的depth_multiple是指网络的深度,width_multiple是网络的宽度, anchors是锚标(标出物体的方框),backbone既骨干网络。
我在这里选择了yolov5s.yaml文件进行复制一份,并修改了里面模型的nc(类别参数)为2(这里要和你提前训练时设定的类别数一直),以下为我自己编辑的模型配置文件部分截图:

并将文件重命名,自行将他放在一个位置处,我这为了方便,直接放在之前制作的数据集下的目录里,如下:
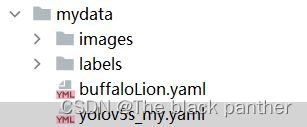
后面进行训练的时候,就需要记住这些你制作的配置文件的位置。
5、开始训练
前期的数据集自己制作好后,并自行划分训练集、验证集,以及创建了数据集配置文件和模型配置文件后,就可以在项目路径里的终端下执行下面的命令,开始训练了:
python train.py --data mydata/buffaloLion.yaml --weights yolov5s.pt --epoch 50 --batch-size 32 --cfg mydata/yolov5s_my.yaml
这里需要注意的是,终端的路径要执行到train.py文件的目录下,后面的几个参数,如 --data就是自己数据集的配置文件,--weights是你自己是否需要预训练模型(可以提前下载好),--epoch 50是迭代的次数, --cfg为模型的配置文件,
训练过程:
这里再补充下train.py文件里的常用参数及解释:
weights:权重文件路径,如果是’'则重头训练参数,如果不为空则做迁移学习,权重文件的模型需与cfg参数中的模型对应
epochs:指的就是训练过程中整个数据集将被迭代多少次
batch-size:每次梯度更新的批量数,指一次看完多少张图片才进行权重更新
config-thres: 模型目标检测的置信度阈值
cfg:存储模型结构的配置文件
data:存储训练、测试数据的文件
img-size:输入图片的宽高
rect:进行矩形训练
resume:恢复最近保存的模型开始训练
nosave:仅保存最终checkpoint
notest:仅测试最后的epoch
evolve:进化超参数
cache-images:缓存图像以加快训练速度
name: 重命名results.txt to results_name.txt
device:cuda device, i.e. 0 or 0,1,2,3 or cpu
adam:使用adam优化
multi-scale:多尺度训练,img-size +/- 50%
single-cls:单类别的训练集
6、训练结果查看
通过最后log可以看到训练好的模型的权重保存在了runs/train/exp(次数)/weights/last.pt和best.pt
其中还包括了PR Curve 曲线、Confusion matric (混淆矩阵)、results.png/txt 等训练过程数据,如下:

7、训练过程中的可视化:
我们可以在模型训练过程时,查看模型权重、损失、精确度、网络结构等的可视化,这里需要使用tensorboard工具进行可视化(需要提前安装)
在项目根路径执行:tensorboard --logdir runs\train

并浏览器打开http://localhost:6006/

8. 测试训练后的模型:
同样使用detect.py,weights使用新训练后的best.pt,测试图片可以拍一个新照片,或者找一个之前没有用到的图片,执行以下命令:
python detect.py --weights runs/train/exp/weights/best.pt --source data/test/Tc400_137.jpg
注意,上面的一些参数要换成自己的,如测试图片的路径,权重的路径等
最后,到run文件夹下查看测试结果。
以上就是使用labelImg工具自己制作数据集,并用于yolov5来训练模型的操作步骤。只是演示,谈不上训练模型的精度和效果,如要要基于某个任务,使用yolo模型进行改进,那么还需要更多的研究工作,如数据集的大小、数据增强、网络结构的调整、超参数的设置等。