JAVA面试题分享一百八十七:Hystrix的理解?
目录
一、Hystrix 是什么?
二、Hystrix 的设计原则是什么?
三、Hystrix 更加细节的设计原则?
四、Hystrix 要解决的问题是什么?
五、Hystrix 是如何实现它的目标?
六、Hystrix原理
七、断路器开关的条件与工作原理
九、Hystirx 两种最基础的容错模式
十、Hystrix分布式系统的经验总结
一、Hystrix 是什么?
Netflix 美国流媒体巨头、世界最大的收费视频网站; 几年前整个网站经常出故障,可用性不太高,他们 api 团队为了提升高可用性,开发了一个框架 Hystrix。
Hystrix 提供了高可用相关的各种各样的功能,确保在 Hystrix 的保护下,整个系统可以长期处于 高可用的状态,如 99.99%;
最理想的状态下,软件故障不应该导致整个系统的崩溃,服务器硬件故障可用通过服务的冗余来保证, 唯一有可能导致系统彻底崩溃,就是类似于机房停电,自然灾害等状况
不可用和产生的一些故障或者 bug 的区别:
不可用:是完全不可用,整个系统完全崩溃
部分故障或 bug:只是一小部分服务出问题
在分布式系统中,每个服务都可能会调用很多其他服务,被调用的那些服务就是依赖服务,有的时候某些依赖服务出现故障也是很正常的。
Hystrix 可以让我们在分布式系统中对服务间的调用进行控制,加入一些调用延迟或者依赖故障的容错机制。 Hystrix 通过将依赖服务进行资源隔离,进而阻止某个依赖服务出现故障的时候,这种故障在整个系统所有的依赖服务调用中进行蔓延, 同时 Hystrix 还提供故障时的 fallback 降级机制
总而言之,Hystrix 通过这些方法帮助我们提升分布式系统的可用性和稳定性
上面一段文字用下图示意

二、Hystrix 的设计原则是什么?
hystrix 为了实现高可用性的架构,设计 hystrix 的时候,一些设计原则是什么?
-
对依赖服务调用时出现的调用延迟和调用失败进行控制和容错保护
-
在复杂的分布式系统中,阻止某一个依赖服务的故障在整个系统中蔓延
服务 A - 服务 B -> 服务 C,服务 C 故障了,服务 B 也故障了,服务 A 故障了,整套分布式系统全部故障,整体宕机
-
提供 fail-fast(快速失败)和快速恢复的支持
-
提供 fallback 优雅降级的支持
-
支持近实时的监控、报警以及运维操作
关键词总结:
- 调用延迟 + 失败,提供容错
- 阻止故障蔓延
- 快速失败 + 快速恢复
- 降级
- 监控 + 报警 + 运维
这里不是完全描述了 hystrix 的功能,简单来说是按照这些原则来设计 hystrix ,提供整个分布式系统的高可用的架构
三、Hystrix 更加细节的设计原则?
-
阻止任何一个依赖服务耗尽所有的资源,比如 tomcat 中的所有线程资源
-
避免请求排队和积压,采用限流和 fail fast 来控制故障
-
提供 fallback 降级机制来应对故障
-
使用资源隔离技术,隔离技术是为了实现第一条的功能
比如 bulkhead(舱壁隔离技术),swimlane(泳道技术),circuit breaker(短路技术), 来限制任何一个依赖服务的故障的影响
-
通过近实时的统计/监控/报警功能,来提高故障发现的速度
-
通过近实时的属性和配置热修改功能,来提高故障处理和恢复的速度
-
保护依赖服务调用的所有故障情况,而不仅仅只是网络故障情况
调用这个依赖服务的时候,client 调用包有 bug、阻塞,等等
依赖服务的各种各样的 调用的故障,都可以处理
四、Hystrix 要解决的问题是什么?
在复杂的分布式系统架构中,每个服务都有很多的依赖服务,而每个依赖服务都可能会故障, 如果服务没有和自己的依赖服务进行隔离,那么可能某一个依赖服务的故障就会拖垮当前这个服务
举例来说:某个服务有 30 个依赖服务,每个依赖服务的可用性非常高,已经达到了 99.99% 的高可用性
那么该服务的可用性就是 99.99% - (100% - 99.99% * 30 = 0.3%)= 99.69%, 意味着 3% 的请求可能会失败,因为 3% 的时间内系统可能出现了故障不可用了
对于 1 亿次访问来说,3% 的请求失败也就意味着 300万 次请求会失败,也意味着每个月有 2个 小时的时间系统是不可用的, 在真实生产环境中,可能更加糟糕
上面的描述想表达的意思是:即使你每个依赖服务都是 99.99% 高可用性,但是一旦你有几十个依赖服务, 还是会导致你每个月都有几个小时是不可用的
下面画图分析说,当某一个依赖服务出现了调用延迟或者调用失败时,为什么会拖垮当前这个服务? 以及在分布式系统中,故障是如何快速蔓延的?

简而言之:
- 假设只有系统承受并发能力是 100 个线程,
- C 出问题的时候,耗时增加,将导致当前进入的 40 个线程得不到释放
- 后续大量的请求涌进来,也是先调用 c,然后又在这里了
- 最后 100 个线程都被卡在 c 了,资源耗尽,导致整个服务不能提供服务
- 那么其他依赖的服务也会出现上述问题,导致整个系统全盘崩溃
当时这个只能是在 高并发高流量的场景下会出现这种情况,其实我工作中也遇到过一次真实的案例, quartz 默认线程只有 25 个,当时定时任务接近 150 个左右,平时每个定时任务触发时间基本上上分散的, 而且基本上在 10 分钟左右会结束任务,当我们调用其他第三方服务时,没有加超时功能, 第三方服务可能出问题了,导致我们的请求被卡主,进而导致任务线程不能结束,最后整个任务调度系统完全崩溃, 完全不能提供服务。
这个场景在我所工作生涯中可能是记忆最深的一次了,因为当时在线上,根据日志打印完全看不出来问题, 就像系统假死一样,后来通过 jconsole 查看线程挂起情况,发现所有线程调用第三方服务后都被卡主了。 才顺藤摸瓜找到 quartz 的默认线程只有 25 个。最后加大了线程,也只是治标不治本,长时间运行还是会出问题
五、Hystrix 是如何实现它的目标?
-
通过 HystrixCommand 或者 HystrixObservableCommand 来封装对外部依赖的访问请求 d 这个访问请求一般会运行在独立的线程中,资源隔离
-
对于超出我们设定阈值的服务调用,直接进行超时,不允许其耗费过长时间阻塞住。
这个超时时间默认是 99.5% 的访问时间,但是一般我们可以自己设置一下
-
为每一个依赖服务维护一个独立的线程池,或者是 semaphore(信号量),当线程池已满时,直接拒绝对这个服务的调用
-
对依赖服务的调用的成功次数、失败次数、拒绝次数、超时次数,进行统计
-
如果对一个依赖服务的调用失败次数超过了一定的阈值,自动进行熔断
在一定时间内对该服务的调用直接降级,一段时间后再自动尝试恢复
-
当一个服务调用出现失败、被拒绝、超时、短路(熔断)等异常情况时,自动调用 fallback 降级机制
-
对属性和配置的修改提供近实时的支持
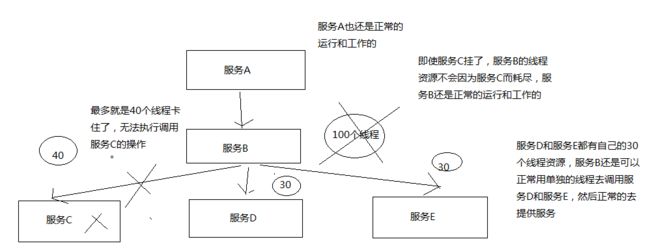
疑问:上图只是站在全局角度来看的?并非自己所想,当一个依赖故障的时候,怎么搞也拿不到正确数据了?关注点关注错了?意思是说,及时这个一个小功能点不能用了,但是该系统其它的功能点能正常使用。并且不会因为这个故障导致整个系统崩溃?
六、Hystrix原理

如图,这样一来调用都用线程去调用,的确能起到资源隔离的效果
创建 command,执行这个 command,配置这个 command 对应的 group 和线程池,以及线程池/信号量的容量和大小
我们要去讲解一下,你开始执行这个 command,调用了这个 command 的 execute() 方法以后, hystrix 内部的底层的执行流程和步骤以及原理是什么呢? 在讲解这个流程的过程中,我们会带出来 hystrix 其他的一些核心以及重要的功能
画图分析整个 8 大步骤的流程,然后再对每个步骤进行细致的讲解;


汉化语句:
- available in cache? 是否有缓存?
- circuit breaker open? 断路器是否打开?
- Semaphore / Thread pool rejected? 信号量/线程池被拒绝?
- execution fails? 执行失败?
- fallback successful? fallback 是否执行成?
- no;failed or not implemented 没有;失败或没有实现
- report metrics 报告治标
- calculate circuit health 断路器健康检查计算
下面来逐一讲解每个步骤的原理
1. 构建一个 HystrixCommand 或者 HystrixObservableCommand
一个 HystrixCommand 或一个 HystrixObservableCommand 对象,代表了对某个依赖服务发起的一次请求或者调用, 构造的时候,可以在构造函数中传入任何需要的配置参数
- HystrixCommand:主要用于仅仅会返回一个结果的调用
- HystrixObservableCommand:主要用于可能会返回多条结果的调用
2. 调用 command 的执行方法
执行 Command 就可以发起一次对依赖服务的调用, 要执行 Command,需要在 4 个方法中选择其中的一个:execute()、queue()、observe()、toObservable()
其中 execute() 和 queue() 仅仅对 HystrixCommand 适用
-
execute()调用后直接 block 住,属于同步调用,直到依赖服务返回单条结果,或者抛出异常
-
queue()返回一个 Future,属于异步调用,后面可以通过 Future 获取单条结果
-
observe()订阅一个 Observable 对象,Observable 代表的是依赖服务返回的结果,获取到一个那个代表结果的 Observable 对象的拷贝对象
-
toObservable()返回一个 Observable 对象,如果我们订阅这个对象,就会执行 command 并且获取返回结果
| 返回值 | command |
|---|---|
| K | value = command.execute(); |
Future |
fValue = command.queue(); |
Observable |
ohValue = command.observe(); |
Observable |
ocValue = command.toObservable(); |
注意,上面 4 种结果都依赖 toObservable();这句话怎么理解?
拿 execute 来举例,可以看到源码中的确是使用了 toObservable() 来调用的结果
com.netflix.hystrix.HystrixCommand#execute
public R execute() {
try {
return queue().get();
} catch (Exception e) {
throw Exceptions.sneakyThrow(decomposeException(e));
}
}
com.netflix.hystrix.HystrixCommand#queue
public Future queue() {
/*
* The Future returned by Observable.toBlocking().toFuture() does not implement the
* interruption of the execution thread when the "mayInterrupt" flag of Future.cancel(boolean) is set to true;
* thus, to comply with the contract of Future, we must wrap around it.
*/
final Future delegate = toObservable().toBlocking().toFuture();
} 3. 检查是否开启缓存
从这一步开始,进入我们的底层的运行原理啦,了解 hysrix 的一些更加高级的功能和特性
如果这个 command 开启了请求缓存(request cache),而且这个调用的结果在缓存中存在,那么直接从缓存中返回结果
4. 检查是否开启了短路器
检查这个 command 对应的依赖服务是否开启了短路器,如果断路器被打开了,那么 hystrix 就不会执行这个 command, 而是直接去执行 fallback 降级机制
5. 检查线程池/队列/ semaphore 是否已经满了
如果 command 对应的线程池/队列/ semaphore 已经满了,那么也不会执行 command,而是直接去调用 fallback 降级机制
6. 执行 command
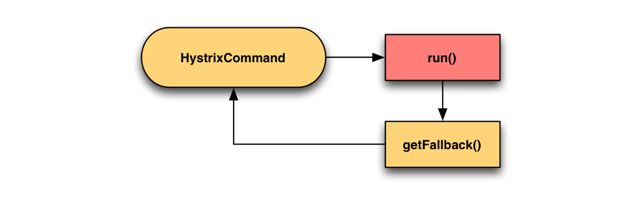
调用 HystrixObservableCommand.construct() 或 HystrixCommand.run() 来实际执行这个 command
- HystrixCommand.run() 是返回一个单条结果,或者抛出一个异常
- HystrixObservableCommand.construct() 是返回一个 Observable 对象,可以获取多条结果
如果执行超过了 timeout 时长的话,那么 command 所在的线程就会抛出一个 TimeoutException, 如果 timeout 了,也会去执行 fallback 降级机制,而且就不会管 run() 或 construct() 返回的值了
这里要注意的一点是,我们是不可能终止掉一个调用严重延迟的依赖服务的线程的,只能说给你抛出来一个 TimeoutException, 但是还是可能会因为严重延迟的调用线程占满整个线程池的
对于上面一段话,本人知识储备不能很好的理解这一段话, hystrix 抛出了一个超时异常,但是对应的线程可能被卡住回不来? 这里的细节有点懵逼
如果没有 timeout 的话,那么就会拿到一些调用依赖服务获取到的结果,然后 hystrix 会做一些 logging 记录和 metric 统计
7. 短路健康检查
Hystrix 会将每一个依赖服务的调用成功、失败、拒绝、超时、等事件,都会发送给 circuit breaker 断路器, 短路器就会对调用成功/失败/拒绝/超时等事件的次数进行统计
短路器会根据这些统计次数来决定是否要进行短路,如果打开了短路器,那么在一段时间内就会直接短路, 然后如果在之后第一次检查发现调用成功了,就关闭断路器
8. 调用 fallback 降级机制
在以下几种情况中,hystrix 会调用 fallback 降级机制:
- run() 或 construct() 抛出一个异常
- 短路器打开
- 线程池/队列/ semaphore 满了
- command 执行超时了
即使在降级中,一定要进行网络调用,也应该将那个调用放在一个 HystrixCommand 中,进行隔离
- 在 HystrixCommand 中,实现 getFallback() 方法,可以提供降级机制
- 在 HystirxObservableCommand 中,实现一个 resumeWithFallback() 方法,返回一个 Observable 对象,可以提供降级结果
如果 fallback 返回了结果,那么 hystrix 就会返回这个结果
- 对于 HystrixCommand,会返回一个 Observable 对象,其中会发返回对应的结果
- 对于 HystrixObservableCommand,会返回一个原始的 Observable 对象
如果没有实现 fallback,或者是 fallback 抛出了异常,Hystrix 会返回一个 Observable,但是不会返回任何数据
不同的 command 执行方式,其 fallback 为空或者异常时的返回结果不同
- 对于execute():直接抛出异常,获取一个 Future.get(),然后拿到单个结果
- 对于queue():返回一个 Future,调用 get() 时抛出异常
- 对于observe():返回一个 Observable 对象,但是调用 subscribe() 方法订阅它时,立即抛出调用者的 onError 方法
- 对于toObservable():返回一个 Observable 对象,但是调用 subscribe() 方法订阅它时,立即抛出调用者的 onError 方法
七、断路器开关的条件与工作原理
断路器的打开是多方度量的结果,受以下几方面影响
-
断路器上的流量达到某个阀值
HystrixCommandProperties.circuitBreakerRequestVolumeThreshold()所有的调用都会经过断路器,它才能统计经过的流量
-
统计到异常占比达到某个阀值
HystrixCommandProperties.circuitBreakerErrorThresholdPercentage() -
断路器从关闭(closed)状态到打开(open)状态
-
经过一段时间
HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds()后 -
下一个请求如果通过(这个时候是半开状态(half-open)),断路器则关闭; 如果下一个请求失败,那么断路器将变成 open 状态,继续等待该配置时间后,再次尝试半开状态;
它的流程图大体是这样,10 秒是一个时间窗口

比如:10 秒内请求流量需要达到 10(默认值是 20 ) 个,并且异常占比 50%,也就是有 5 个请求 异常了,那么断路器就会开启。当开启 3 秒后,会允许一个请求通过,如果成功,则关闭断路器
九、Hystirx 两种最基础的容错模式
下面几节是 HystrixCommand 和 HystrixObservableCommand 的常见用法和使用模式。
fail-fast
没有 fallback 降级逻辑,报错的话,异常可以被捕获到
fail-silent
有 fallback 降级逻辑;如果执行报错了,会走 fallback 降级,返回 fallback 的值给你
metrics.rollingStats.numBuckets
该属性设置每个滑动窗口被拆分成多少个 bucket,而且滑动窗口对这个参数必须可以整除,同样不允许热修改
默认值是 10,也就是说,每秒钟是一个 bucket
随着时间的滚动,比如又过了一秒钟,那么最久的一秒钟的 bucket 就会被丢弃,然后新的一秒的 bucket 会被创建
HystrixCommandProperties.Setter()
.withMetricsRollingStatisticalWindowBuckets(int value)
metrics.rollingPercentile.enabled
控制是否追踪请求耗时,以及通过百分比方式来统计,默认是 true
HystrixCommandProperties.Setter()
.withMetricsRollingPercentileEnabled(boolean value)
metrics.rollingPercentile.timeInMilliseconds
设置 rolling window 被持久化保存的时间,这样才能计算一些请求耗时的百分比,默认是 60000 = 60s,不允许热修改
相当于是一个大的 rolling window,专门用于计算请求执行耗时的百分比
HystrixCommandProperties.Setter()
.withMetricsRollingPercentileWindowInMilliseconds(int value)
metrics.rollingPercentile.numBuckets
设置 rolling percentile window 被拆分成的 bucket 数量,上面那个参数除以这个参数必须能够整除,不允许热修改
默认值是 6,也就是每 10s 被拆分成一个 bucket
HystrixCommandProperties.Setter()
.withMetricsRollingPercentileWindowBuckets(int value)
metrics.rollingPercentile.bucketSize
设置每个 bucket 的请求执行次数被保存的最大数量,如果在一个 bucket 内,执行次数超过了这个值,那么就会重新覆盖从 bucket 的开始再写
举例来说,如果 bucket size 设置为 100,而且每个 bucket 代表一个 10 秒钟的窗口, 但是在这个 bucket 内发生了 500 次请求执行,那么这个 bucket 内仅仅会保留 100 次执行
如果调大这个参数,就会提升需要耗费的内存,来存储相关的统计值,不允许热修改
默认值是 100
HystrixCommandProperties.Setter()
.withMetricsRollingPercentileBucketSize(int value)
metrics.healthSnapshot.intervalInMilliseconds
控制成功和失败的百分比计算,与影响短路器之间的等待时间,默认值是 500 毫秒
HystrixCommandProperties.Setter()
.withMetricsHealthSnapshotIntervalInMilliseconds(int value)
TIP
一般来说这些配置使用默认即可
十、Hystrix分布式系统的经验总结
如果发现了严重的依赖调用延时,先不用急着去修改配置,如果一个 command 被限流了,可能本来就应该限流
在 netflix 早期的时候,经常会有人在发现短路器因为访问延时发生的时候,去热修改一些配置遏制,比如线程池大小、队列大小、超时时长等等,给更多的资源,但是这其实是不对的
如果我们之前对系统进行了良好的配置,然后现在在高峰期,系统在进行线程池 reject、超时、短路、那么此时我们应该集中精力去看底层根本的原因,而不是调整配置
为什么在高峰期,一个 10 个线程的线程池,搞不定这些流量呢?代码写的太烂了?
千万不要急于给你的依赖调用过多的资源,比如线程池大小、队列大小、超时时长、信号量容量等等,因为这可能导致我们自己对自己的系统进行 DDOS 攻击(疯狂的大量的访问你的机器,最后给打垮)
举例来说,想象一下,我们现在有 100 台服务器组成的集群,每台机器有 10个 线程大小的线程池去访问一个服务,那么我们对那个服务就有 1000个 线程资源去访问了
在正常情况下,可能只会用到其中 200~300个 线程去访问那个后端服务,但是如果在高峰期出现了访问延时,可能导致 1000 个线程全部被调用去访问那个后端服务,如果我们调整到每台服务器 20 个线程呢?
如果因为你的代码等问题导致访问延时,即使有 20个 线程可能还是会导致线程池资源被占满,此时就有 2000个 线程去访问后端服务,可能对后端服务就是一场灾难
这就是断路器的作用了,如果我们把后端服务打死了,或者产生了大量的压力,有大量的 timeout 和 reject,那么就自动短路,一段时间后,等流量洪峰过去了,再重启访问
简单来说,让系统自己去限流、短路、超时、以及 reject,直到系统重新变得正常了
最后总结:就是不要随便乱改资源配置,不要随便乱增加线程池大小,等待队列大小,异常情况是正常的。