处理器中异常的处理
处理器执行程序的过程中,在流水线的很多阶段都有可能发生异常(exception),但是由于存在流水线和乱序执行等原因,在时间点上先发生的异常未必在程序中也是靠前的;
- 如图所示的流水线中,第一条指令在流水线的执行阶段(Execute)发生了Page Fault类型的异常,而第二条指令在流水线的解码阶段(Decode)就发现了未定义指令的异常,从时间上来看,肯定是发生在t1时刻的那个异常更早一些,但是放在程序中来看,它应该在Page Fault 这个异常之后才进行处理。
- 因此,需要一种方法来记录所有指令的异常,然后按照指令在程序中的原始顺序对所有的异常进行处理,能够胜任这个任务的,就是重排序缓存(ROB)
 在 ROB 中按照程序中指定的顺序(in-order)记录着流水线中所有的指令(确切地说,是记录了重命名阶段之后的所有指令);
在 ROB 中按照程序中指定的顺序(in-order)记录着流水线中所有的指令(确切地说,是记录了重命名阶段之后的所有指令);- 为了能够按照正常的顺序处理异常,一条指令的异常要被处理,必须保证在它之前的所有指令的异常都已经被处理完成了
- 最容易实现这个任务的时间点就是在一条指令将要退休(retire)的时候,此时这条指令之前的所有指令都已经顺利地离开了流水线,因此这些指令的异常也肯定被处理完毕。
- 如果发现本周期要退休的指令被记录了异常,那么这条指令就不能够退休,而是需要对这个异常进行处理,如图所示。
现代的处理器,都支持精确的异常,能够极大地简化软件的工作;
精确的异常:指处理器能够知道哪条指令发生了异常,并且这条发生异常的指令之后的所有指令都不允许改变处理器的状态,就好像这些指令从来没有发生过一样,这样在对这个异常处理完后,可以精确地进行返回,返回的地方可能有两种情况,可以返回到发生异常的指令本身、重新执行这条指令,也可以不重新执行这条发生异常的指令,而是返回到它的下一条指令开始执行。
- 例如当一条访问存储器的指令发生TLB缺失的异常时,处理器将其处理完毕,并从对应的异常处理程序中返回的时候,会重新执行这条产生异常的指令,此时肯定就不会发生TLB 缺失了。
- 而对于产生系统调用的指令引起的异常,例如 MIPS 中的 SYSCALL 指令,则只需要返回到下一条指令就可以了,如果返回到这条指令本身,则又会产生异常,这样就形成了死循环。
在超标量处理器中,为了支持精确的异常,当发现要退休的指令存在异常时,在跳转到对应的异常处理程序之前,需要将流水线中这条产生异常的指令后面的所有指令都抹去,并将它们对处理器状态的修改进行恢复,就好像这些指令从来没有发生过一样,如下图所示。
 当一条指令要从 ROB中退休之时,如果发现它在之前记录过异常的发生,此时ROB中所有的指令其实都不允许退休而改变处理器的状态
当一条指令要从 ROB中退休之时,如果发现它在之前记录过异常的发生,此时ROB中所有的指令其实都不允许退休而改变处理器的状态- 也就是说,此时流水线中的所有指令都是没有用的,可以将整个流水线中的指令都抹掉,并对处理器的状态进行恢复
- 即需要清空流水线,并进行状态恢复。
- 通过这些操作之后,此时处理器的状态已经没有这些错误指令的影响,因此可以跳转到对应的异常处理程序的入口地址,开始取新的指令来执行。
这种 Recovery at Retire的异常处理方法还有一个好处,那就是很多指令的异常并非是真的需要被处理,如果这些指令处在分支预测失败(mis-prediction)的路径上,它们都会从流水线中被抹掉,因此它们的异常其实都是无效的。只有当一条指令变为流水线中最旧的指令,也就是马上要退休的时候,才可以保证这条指令不处于错误的路径上,此时它的异常才是真正有效的。
另一种方式:WALK的方式
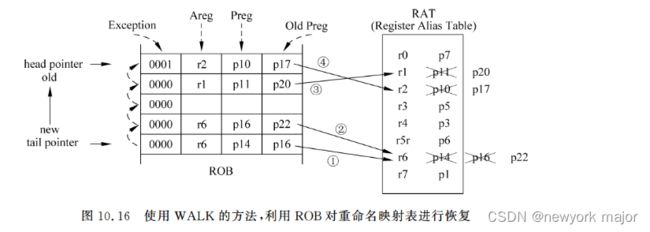
- 这种方法也是基于重排序缓存(ROB)来进行的。
- 前面说过,当一条指令被重命名之后,这条指令对应的旧映射关系也会保存到ROB中
- 这样一条指令在退休的时候,如果发现了异常,则从ROB 中最新写入的指令开始(即从图 10.16 中 tail pointer 指向的指令开始),逐个将每条指令对应的旧的映射关系写到重命名映射表中,这样就可以将这个表格进行状态恢复了
- 这个方法就是前文提到过的WALK,图10.16表示了使用ROB对重命名映射表进行恢复的过程。
- 对于一个 4-way 的超标量处理器来说,重命名映射表(RAT)有四个写端口,因此在使用图 10.16 所示的方法对RAT进行恢复的时候,每周期也可以从ROB中取出四条指令对RAT进行修复,这样可以最大限度地利用RAT的写端口,加快恢复的时间。
在使用统一的PRF进行寄存器重命名的方式中,和RAT相关的内容还有两个表格
- 一个表格用来存储哪些物理寄存器是空闲状态的,称为Free Register Pool;
- Free Register Pool跟踪当前未使用的physical register,并用于将新的physical register分配给通过Rename stage的指令。Free List通过a-bit vector实现,可以使用优先级解码器来查找第一个空闲寄存器。
- 另外一个表格用来存储每个物理寄存器的值是否已经被计算出来,称为Busy Table。
- Busy Table跟踪每个physical register的就绪状态,如果所有物理操作数就绪,指令就可以发出(issued)
- 这两个表格都是配合 RAT进行工作的,当异常发生的时候,这两个部件也需要进行恢复,不过它们的恢复有着自身的特点。
free register pool的恢复
- 对于 Free Register Pool 来说,每当对一条指令进行重命名时,就会从这个表格中读取一个空闲的物理寄存器的编号,和指令的目的寄存器产生映射关系,然后这个表格的读指针会指向下一个地方
- 但是在这个表格中,刚刚被读取的内容并不会消失,也不会被那些退休(retire)的指令所释放的物理寄存器所覆盖,所以对于这个表格的状态恢复,只需要恢复它的读指针就可以了。
- 刚刚讲过,可以利用ROB中存储的旧映射关系对RAT进行恢复(WALK的方式),每当ROB中读取一条指令对RAT进行恢复时(这条指令必须存在目的寄存器),就将Free Register Pool 的读指针也变化一格,这样 ROB 中的所有指令对 RAT 的恢复完成时,这个表格也恢复完成了。
busy table的恢复
- 对于用来表示 PRF 中每个物理寄存器是否已经被计算出来的 Busy Table,由于指令只要运算完成了,就可以在流水线的写回(Write Back)阶段将结果写到对应的物理寄存器中(即目的寄存器),而不需要等到这条指令退休,
- 所以当一条指令到达ROB的顶部而变为流水线中最旧的指令,并被发现存在异常的时候,这条指令后面的很多指令都已经将其结果写到了PRF中,也就是将Busy Table中对应的状态进行了修改。
- 所以在进行状态恢复的时候,需要将这个表格也进行恢复
- 这个过程也是很简单的,在从ROB中读取指令进行状态恢复时,每读取一条指令(WALK的方式),就将这条指令的目的寄存器(此时以物理寄存器的形式存在)在 Busy Table中对应的内容置为无效
- 这样即使这条指令将结果已经写到 PRF 中,也可以将其变成无效了,后续的指令不会使用到错误的值。
在采用统一的PRF进行重命名的架构中,在处理异常的时候,利用ROB进行状态恢复是比较合适的。相反,如果使用Recovery at Retire方式对处理器的状态进行恢复,虽然可以使用提交阶段architecture RAT对重命名阶段的speculative RAT进行恢复,但是对Free Register Pool和Busy Table的状态恢复就没有那么直接了,有可能需要使用architecture RAT中记录的物理寄存器,逐个地对这两个表格进行修复,这样所需要的时间不会很短,使处理器对异常(exception)的响应时间变长,降低了执行效率。
因此,对于异常(exception)发生时的处理器来说,如果采用ROB进行重命名的架构,使用Recovery atRetire方法是合适的,而对于采用统一的PRF进行重命名的架构,则需要使用本节介绍的WALK 的方法。