从零构建属于自己的GPT系列5:模型部署1(文本生成函数解读、模型本地化部署、文本生成文本网页展示、代码逐行解读)
Hugging Face 实战系列 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在PyCharm中进行
本篇文章配套的代码资源已经上传
从零构建属于自己的GPT系列1:数据预处理
从零构建属于自己的GPT系列2:模型训练1
从零构建属于自己的GPT系列3:模型训练2
从零构建属于自己的GPT系列4:模型训练3
从零构建属于自己的GPT系列5:模型部署1
从零构建属于自己的GPT系列6:模型部署2
1 前端环境安装
安装:
pip install streamlit
测试:
streamlit hello
安装完成后,测试后打印的信息
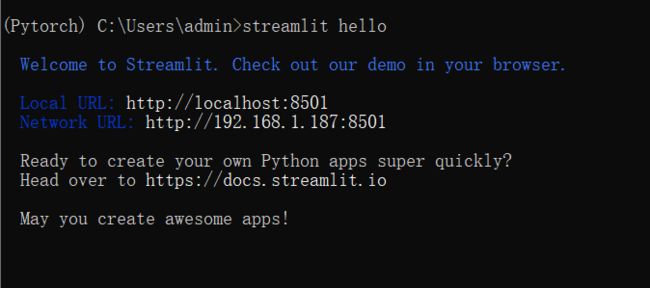
(Pytorch) C:\Users\admin>streamlit hello
Welcome to Streamlit. Check out our demo in your browser.
Local URL: http://localhost:8501 Network URL:
http://192.168.1.187:8501
Ready to create your own Python apps super quickly? Head over to
https://docs.streamlit.io
May you create awesome apps!
接着会自动的弹出一个页面
2 模型加载函数
这个函数把模型加载进来,并且设置成推理模式
def get_model(device, model_path):
tokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model")
eod_id = tokenizer.convert_tokens_to_ids("" ) # 文档结束符
sep_id = tokenizer.sep_token_id
unk_id = tokenizer.unk_token_id
model = GPT2LMHeadModel.from_pretrained(model_path)
model.to(device)
model.eval()
return tokenizer, model, eod_id, sep_id, unk_id
- 模型加载函数,加载设备cuda,已经训练好的模型的路径
- 加载tokenizer 文件
- 结束特殊字符
- 分隔特殊字符
- 未知词特殊字符
- 加载模型
- 模型进入GPU
- 开启推理模式
- 返回参数
device_ids = 0
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICE"] = str(device_ids)
device = torch.device("cuda" if torch.cuda.is_available() and int(device_ids) >= 0 else "cpu")
tokenizer, model, eod_id, sep_id, unk_id = get_model(device, "model/zuowen_epoch40")
- 指定第一个显卡
- 设置确保 CUDA 设备的编号与 PCI 位置相匹配,使得 CUDA 设备的编号更加一致且可预测
- 通过设置为 str(device_ids)(在这个案例中为 ‘0’),指定了进程只能看到并使用编号为 0 的 GPU
- 有GPU用GPU作为加载设备,否则用CPU
- 调用get_model函数,加载模型
3 文本生成函数
对于给定的上文,生成下一个单词
def generate_next_token(input_ids,args):
input_ids = input_ids[:, -200:]
outputs = model(input_ids=input_ids)
logits = outputs.logits
next_token_logits = logits[0, -1, :]
next_token_logits = next_token_logits / args.temperature
next_token_logits[unk_id] = -float('Inf')
filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=args.top_k, top_p=args.top_p)
next_token_id = torch.multinomial(F.softmax(filtered_logits, dim=-1), num_samples=1)
return next_token_id
- 对输入进行一个截断操作,相当于对输入长度进行了限制
- 通过模型得到预测,得到输出,预测的一个词一个词进行预测的
- 得到预测的结果值
- next_token_logits表示最后一个token的hidden_state对应的prediction_scores,也就是模型要预测的下一个token的概率
- 温度表示让结果生成具有多样性
- 设置预测的结果不可以未知字(词)的Token,防止出现异常的东西
- 通过top_k_top_p_filtering()函数对预测结果进行筛选
- 通过预测值转换为概率,得到实际的Token ID
- 返回结果
每次都是通过这种方式预测出下一个词是什么
4 多文本生成函数
到这里就不止是预测下一个词了,要不断的预测
def predict_one_sample(model, tokenizer, device, args, title, context):
title_ids = tokenizer.encode(title, add_special_tokens=False)
context_ids = tokenizer.encode(context, add_special_tokens=False)
input_ids = title_ids + [sep_id] + context_ids
cur_len = len(input_ids)
last_token_id = input_ids[-1]
input_ids = torch.tensor([input_ids], dtype=torch.long, device=device)
while True:
next_token_id = generate_next_token(input_ids,args)
input_ids = torch.cat((input_ids, next_token_id.unsqueeze(0)), dim=1)
cur_len += 1
word = tokenizer.convert_ids_to_tokens(next_token_id.item())
if cur_len >= args.generate_max_len and last_token_id == 8 and next_token_id == 3:
break
if cur_len >= args.generate_max_len and word in [".", "。", "!", "!", "?", "?", ",", ","]:
break
if next_token_id == eod_id:
break
result = tokenizer.decode(input_ids.squeeze(0))
content = result.split("" )[1] # 生成的最终内容
return content
- 预测一个样本的函数
- 从用户获得输入标题转化为Token ID
- 从用户获得输入正文转化为Token ID
- 标题和正文连接到一起
- 获取输入长度
- 获取已经生成的内容的最后一个元素
- 把输入数据转化为Tensor
- while循环
- 通过生成函数生成下一个词的token id
- 把新生成的token id加到原本的数据中(原本有5个词,预测出第6个词,将第6个词和原来的5个词进行拼接)
- 输入长度增加1
- 将一个 token ID 转换回其对应的文本 token
- 如果超过最大长度并且生成换行符
- 停止生成
- 如果超过最大长度并且生成标点符号
- 停止生成
- 如果生成了结束符
- 停止生成
- 将Token ID转化为文本
- 将生成的文本按照分隔符进行分割
- 返回生成的内容
从零构建属于自己的GPT系列1:数据预处理
从零构建属于自己的GPT系列2:模型训练1
从零构建属于自己的GPT系列3:模型训练2
从零构建属于自己的GPT系列4:模型训练3
从零构建属于自己的GPT系列5:模型部署1
从零构建属于自己的GPT系列6:模型部署2