【机器学习】KNN算法对鸢尾花进行分类
目录
一、KNN算法的理解:
1.算法概述
KNN算法的主要步骤:
二、KNN算法实现鸢尾花分类
1. 鸢尾花数据集介绍
2.获取数据集
3. 数据集可视化
4.统计型转置
5.数据直方图
6.散点图
三、KNN总结
四、实验总结
1.实验过程中遇到的问题
2.实验总结
一、KNN算法的理解:
1.算法概述
K最近邻(K-Nearest Neighbors,KNN)算法是一种常用的分类和回归算法。对于分类问题,KNN算法的基本思想是找出离待预测样本最近的K个训练样本,然后根据这K个样本的标签,通过投票或加权投票的方式来确定待预测样本的类别。
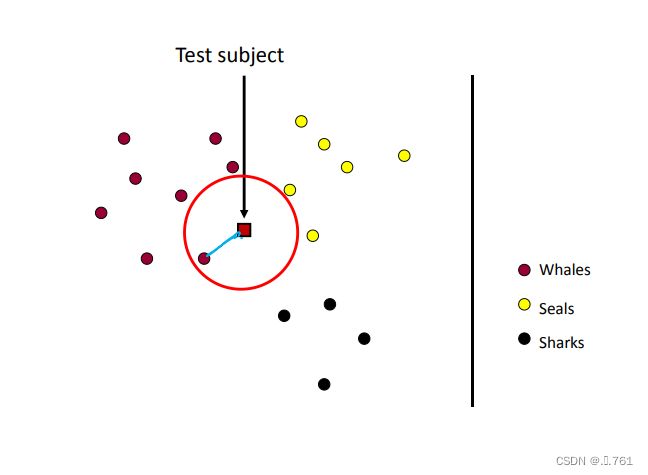
KNN算法的主要步骤:
- 加载训练数据集。
- 对训练数据进行特征归一化处理,确保每个特征在相同的尺度上。
- 提取待预测样本的特征。
- 计算待预测样本与训练样本之间的距离,常用的距离度量方法有欧氏距离、曼哈顿距离等。
- 根据距离的大小,选取离待预测样本最近的K个训练样本。
-
输出预测结果:将预测结果返回作为模型的输出。
二、KNN算法实现鸢尾花分类
KNN算法是一种常用的分类算法,它的主要思想是根据样本间的距离来进行分类。本次使用KNN算法对鸢尾花数据集进行分类。
1. 鸢尾花数据集介绍
iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set。iris包含150个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征和样本的类别信息,所以iris数据集是一个150行5列的二维表。
通俗地说,iris数据集是用来给花做分类的数据集,每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征(前4列),我们需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾、变色鸢尾还是维吉尼亚鸢尾(这三个名词都是花的品种)。
- sepal_Length:萼片长度(厘米)
- sepal_Width:萼片宽度(厘米)
- petal_Length:花瓣长度(厘米)
- petal_Width:花瓣宽度(厘米)
2.获取数据集
(1)调用load_iris函数来加载数据集
from sklearn.datasets import load_iris
# 加载鸢尾花数据集
iris_dataset = load_iris()

(2)数据集返回值介绍
返回值类型是bunch--是一个字典类型
返回值的属性:
data:特征数据数组
target:标签(目标)数组
DESCR:数据描述
feature_name:特征名称
target_name:标签(目标值)名称
(3)数据集划分

# x是特征值,y是目标值
x_train,x_test,y_train,y_test = train_test_split(iris_dataset.data,iris_dataset.target)
print("训练集的特征值是:\n",x_train)
print("测试集的目标值是:\n",x_test)
print("训练集的特征值是:\n",y_train)
print("测试集的目标值是:\n",y_test)
print("训练集的特征值是:\n",y_train.shape)
print("测试集的目标值是:\n",y_test.shape)

(4)实例化一个转换器
transfer = StandardScaler()
# 调用fit_transform 方法
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
(5)模型训练
# 实例化一个估计器
estimator = KNeighborsClassifier(n_neighbors=5)
# 模型训练
estimator.fit(x_train,y_train)
# 模型评估
# 输出预测值
y_pre = estimator.predict(x_test)
print("预测值是:\n",y_pre)
print("预测值与真实值对比:\n",y_pre == y_test)
# 输出准确率
ret = estimator.score(x_test,y_test)
print("准确率是:\n",ret)

3. 数据集可视化
数据类型转换,把数据用DATaFrame存储
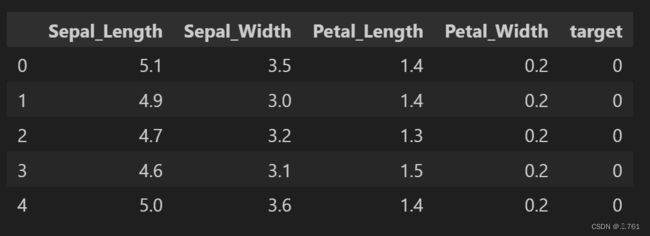
iris_data = pd.DataFrame(data=iris_dataset.data,columns=['Sepal_Length','Sepal_Width','Petal_Length','Petal_Width'])
iris_data["target"] = iris_dataset.target
iris_data.shape
iris_data.head()
# print(iris_data)

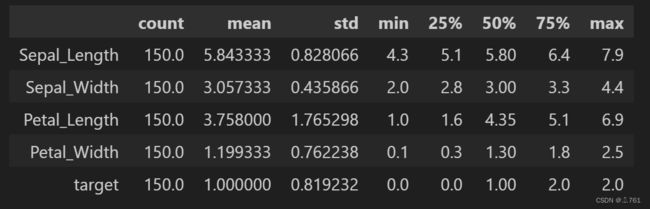
4.统计型转置
iris_data.describe().T
5.数据直方图
之前已经使用过describe()计算出四个属性所对应的四分位数, 最大值以及最小值等统计量。这些均是以表格的形式展示。
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = pd.read_csv(url, names=names)
dataset.hist() #数据直方图histograms

6.散点图
dataset.plot(x='sepal-length', y='sepal-width', kind='scatter')
自定义iris_plot函数,用于绘制鸢尾花数据集中指定两个特征的散点图。它使用了seaborn库和matplotlib库来进行绘图。

hue:目标值是什么,设置hue="target"

fit_reg是否进行线性拟合。将fit_reg属性设置为False。

def iris_plot(data,col1,col2):
sns.lmplot(x = col1,y = col2,data = data,hue="target",fit_reg=False)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title("鸢尾花数据展示")
plt.xlabel(col1)
plt.ylabel(col2)
plt.show()
iris_plot(iris_data,"Sepal_Length","Petal_Width")

三、KNN总结
KNN算法优点:
- 简单易理解:KNN算法非常直观和简单,易于理解和实现。
- 无需训练阶段:KNN是一种懒惰(lazy)学习方法,不需要显式地训练模型。它将所有训练样本都存储在内存中,并在预测阶段根据新样本的特征与已有样本的相似性进行预测。
- 适用于多分类问题:KNN算法可以处理多分类问题,根据投票法或加权投票法来确定预测结果。
- 对异常值不敏感:KNN算法对异常值不敏感,这是因为KNN是基于实例的方法,不受训练数据分布的影响。
KNN算法缺点:
- 高计算复杂度:KNN算法在预测时需要计算新样本与全部训练样本的距离,随着样本数量增加,计算复杂度会显著增大。
- 需要大量内存:KNN算法需要存储训练样本的特征向量,占用较大的内存空间。
- 对特征缩放敏感:KNN算法是基于距离的,对特征的尺度敏感。如果特征具有不同的尺度范围,则应进行特征缩放,以避免某些特征对距离计算的影响过大。
- 需要确定K值:KNN算法需要确定K值,即选择多少个邻居参与预测。选择不恰当的K值可能导致预测错误。
四、实验总结
1.实验过程中遇到的问题
(1)在运行代码时,出现如下问题:

解决过程:在终端将Pillow删除,重新下载。
(2)缺少seaborn库,在终端下载。seaborn库是一个基于matplotlib的Python数据可视化库。提供了一个高级界面,用于绘制信息丰富的统计图形。

2.实验总结
本次使用KNN算法对鸢尾花数据集进行了分类,实现了自动划分训练集和测试集、训练KNN模型、预测和计算准确率、可视化结果。KNN算法简单易懂,容易实现,但是当数据集较大时,计算距离的时间复杂度较高,需要选择合适的K值和距离计算方法来提高分类效果。