计算机视觉中的细节问题(五)
参考 计算机视觉中的细节问题(五) - 云+社区 - 腾讯云
目录
(1)、训练集与测试集的标准定义
(2)anchor_scales、anchor_ratios、anchor_strides的含义?
(3)、残差网络ResNet的原理
(4)、Batch Normalization(批归一化)
(5)、Bottleneck的含义
(6)、Dropout
(7)、RPN的原理
(8)、Fast R-CNN的多任务损失:
(9)、目标检测中的Bounding Box回归模型(不是Fc7上的特征,而是conv5的特征):
(10)、RoI池化层的原理
(1)、训练集与测试集的标准定义
从数据中学得模型的过程称为“学习”(learning)或“训练”(training),这个过程通过执行某个机器学习算法来完成。训练过程中使用的数据称为“训练数据”(training data),其中每个样本称为一个“训练样本”(training sample),训练样本组成的集合称为“训练集”(training dataset)。学得模型对应了关于数据的某种潜在的规律,因此亦称“假设”(hypothesis);这种潜在规律自身,则称为“真相”或“真实”(groun truth),学习过程就是为了找出或逼近真相。
(2)anchor_scales、anchor_ratios、anchor_strides的含义?
anchor_scales=[8]
anchor_ratios=[0.5, 1.0, 2.0]
anchor_strides=[4, 8, 16, 32, 64]anchor_strides一般使用在FPN中,至于为什么有五个anchor_stride,是因为FPN要为rpn再下采样一次,所以相当于有五个层的FPN网络。anchor_ratio主要决定anchor的形状, 然后设定一个初始大小anchor_scale生成base_anchor, base_anchor*anchor_strides 生成各个feature_map上使用的anchor。
参考代码为:
mmdetection/mmdet/models/anchor_heads/anchor_head.py
mmdetection/mmdet/core/anchor/anchor_generator.py
(3)、残差网络ResNet的原理
残差网络在原始的网络上加上跳跃连接,左边为朴素网络,可以拟合出任意目标映射H(x),右边为Residual网络,可以拟合出目标映射F(x),H(x)=F(x)+x,F(x)是残差映射,相对于identity来说。当H(x)最优映射接近identity时,很容易捕捉到小的扰动。右边这种结构称为残差网络的残差块,用此模型堆叠能保证模型深度更深,同时收敛快,梯度消失能更好的解决
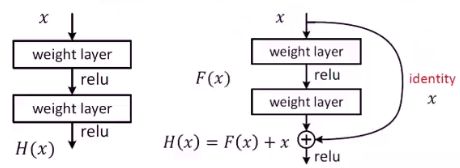
在进行梯度下降优化的时候,需要对x求偏导
因此在此小模块上导数永远大于1,梯度消失是因为导数接近于零无法继续传播,如果每层梯度都大于1,乘积一定大于1。因此这么操作后F(x)只拟合出残差函数,这样即使F(x)的导数很小时,强制让网络去拟合小的梯度扰动,网络很轻松的就能拟合,具体的残差块如下图

全是3x3的卷积核,卷积步长2取代池化,使用Batch Normalization,取消max pooling、全练级、Dropout,整个网络为


残差网络想要更深需要根据Bottleneck优化残差映射网络,原始网络为
原始:
优化:

左边为原始残差网络,256个通道,优化加了两个1x1的卷积,把输入从256先降到64,再将维数升到256输出,用此方法降低计算量和参数量。最终提升网络的深度,下表为不同残差网络的配置:

(4)、Batch Normalization(批归一化)
BN是GoogleNet的Inception V2中提出的一个方法。解决Internal Covariate Shift问题(内部Neuron的数据发生变化,神经元输出数据发生偏移),使每一层的输出都规范化到N(0,1)来白化特征图,能允许较高的学习率,取代部分Dropout,是决定GAN能不能训练成功的决定性因素。


在batch范围内,对每个特征通道分别进行归一化,对所有图片,所有像素点。在训练的时候数据集太大,没有办法把所有数据一次性的提取进来就算loss,根据设备取32或64个,batch越大越好。一次进去的32个数据就是一个batch,batch之间的数据要做归一化,假设batch的尺寸是32,一次送32张图片,图片送入之后每个卷积层的输出都对应着32张图片,加入某一个卷积层有k个输出通道,输出k个特征,batch在k个通道上有32个batch,假设每一个图片对应MxM的特征尺寸,对这32个特征图算出平均值和标准差,对算出来的这层做归一化,归一化就是减去均值除以标准差。
如果均值是 标准差是
标准差是 ,计算归一化的公式为
,计算归一化的公式为

强制归一化会抹杀有些数据特性,包括尺度也是,代表尺度,例如会将数据变为零。这时候必须配对使用scale和shift,scale和shift也要学习出来,这组参数需要学习:
其中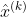 是输出的特征图,
是输出的特征图, 和是需要学习的参数分别代表尺度变化和偏移,假设卷积层输出是k个通道,做BN的时候需要做k次,每个通道上还对应这一组和,k指的是通道数,也就是说一个BN层会对应k组尺度和偏移参数,ReLU的作用是将卷积层的输出压成非线性,BN层一般用在卷积和ReLU层之间。
和是需要学习的参数分别代表尺度变化和偏移,假设卷积层输出是k个通道,做BN的时候需要做k次,每个通道上还对应这一组和,k指的是通道数,也就是说一个BN层会对应k组尺度和偏移参数,ReLU的作用是将卷积层的输出压成非线性,BN层一般用在卷积和ReLU层之间。
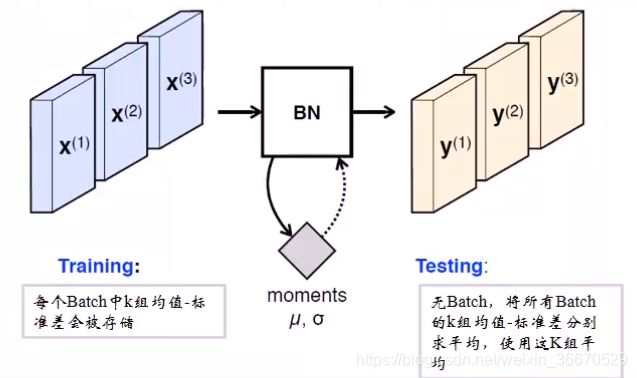
因为BN层是基于minibatch做计算的,训练的时候用minibatch的数据,测试的时候没有minibatch。训练的时候是实时计算,训练的时候,每个batch中k组均值-标准差会被存储,例如有10000组数据batch是100,1000个数据全部训练一遍称为epoch,也就是说训练1个epoch会有100个batch。测试的时候,无batch,将所有batch的k组均值-标准差分别求平均,使用这k组平均。
(5)、Bottleneck的含义
三层瓶颈结构为1X1,3X3和1X1卷积层。其中两个1X1卷积用来减少并增加(复原)维度。3X3卷积层可以看作一个更小的输入输出维度的瓶颈。下图右侧为瓶颈——Bottleneck架构设计,实际上描述的很形象,但是为什么要这么设计呢?

(6)、Dropout
Dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如图1所示。

(7)、RPN的原理
Faster R-CNN的区域建议生成算法Selective Search是一个独立的计算模块,Faster R-CNN中提出了Region Proposal Network,使得输出特征也使用Alexnet第五个卷积层的输出特征来决定,将区域建议生成算法直接集成到网络中,如下图所示,

因此Faster R-CNN = Fast R-CNN + RPN,解决了SS算法带来的计算时间瓶颈,进一步得共享了卷积层计算。RPN基于Attention注意机制,引导Fast R-CNN关注特定区域。因为SS算法输出2000个区域,RPN输出的区域建议比较少,约300个,但是质量比较高。
RPN网络是一个全卷积网络,网络有两层是一个3x3的卷积,256个输出通道,第二层是两个分支,都是1x1的卷积,一个分支输出通道是4k(k是anchor的数量)输出的是矩形框Anchor的补偿(r,c,w,h)。另一个通道输出是分类值,这个分类是二分类(object score, non-object score),如下图所示

RPN的损失函数为:
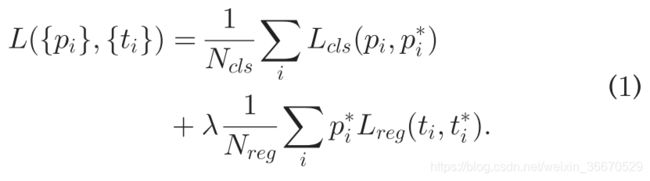
PRN有两个分支,两个分支各带来两个损失函数项,PRN需要单独训练,训练的设置和Fast R-CNN的分类和回归类似。
(8)、Fast R-CNN的多任务损失:
损失函数有两项,一项负责分类,一项负责定位:

分类器的损失为:
每个分类对应一个概率,每个RoI的概率分布为,guound truth的概率为u。比如,在训练过程中softmax有20个分类,softmax输出了21个预测概率值,最后一个为背景类,训练时用指示函数来指示。如果ground truth代表猫排在第一个,因此u=0,因此计算加到loss function里面。
Bounding box回归使用L1平滑方程,方程的表达式为。

(9)、目标检测中的Bounding Box回归模型(不是Fc7上的特征,而是conv5的特征):

训练分类器完成后,接下来要完成Bounding Box回归,来做SS区域的精化。目的是提升Bounding Box的定位性能,每一个分类对应一个Bounding Box回归模型,将旧的(x,y,w,h)映射成更精确的(x,y,w,h),另外的输入是Bounding Box对,P是SS算法提出旧的位置信息,G是ground truth,就是要输出的,是卷积层的输入,是要学习的,乘以特征进行特征的组织和变维,表示x,y,w,h个需要学习一个参数,x,y是直角坐标下的比例关系,w,h是极坐标下的比例关系,最终要计算出变化,或者说是一个校准量,而不是原本的输出结果,在训练阶段需要训练好4个w。
在测试阶段,首先用学习好的第五卷积层特征乘以学习好的参数,然后进行各自的校正,x,y是直角坐标下的校正,计算出的偏量乘以旧的,再加上旧的,极坐标要用指数计算再乘以旧的。
(10)、RoI池化层的原理

左侧是SPP池化,图片为第五个卷积层的输出上面黑的图片是单通道的特征图片,绿框是SS算法给出的物体区域,SPP池化用4x4、2x2、1x1的网格做划分后做最大池化并重组,形成一个1x21的特征,而RoI池化只用最上面的4x4来进行最大池化,形成一个1x16。