爬虫项目实战:利用基于selenium框架的爬虫模板爬取豆瓣电影Top250
- Hi, I’m @货又星
- I’m interested in …
- I’m currently learning …
- I’m looking to collaborate on …
- How to reach me …
- README 目录(持续更新中) 各种错误处理、爬虫实战及模板、百度智能云人脸识别、计算机视觉深度学习CNN图像识别与分类、PaddlePaddle自然语言处理知识图谱、GitHub、运维…
- WeChat:1297767084
- GitHub:https://github.com/cxlhyx
文章目录
- 概要
- 整体架构流程
- 技术细节
-
- *Step 2: 解析网页并提取目标数据*
- *Step 3: 存储数据到本地或其他持久化存储服务器中*
- *Step 4: 控制流程,调用上述函数完成数据抓取任务*
- 结果
- 源码
概要
利用基于selenium框架的爬虫模板进行项目实战
博主之前发了一篇爬虫:解决动态刷新、基于selenium框架的爬虫、解决登录以及验证码问题(含爬虫模板),介绍了爬虫如何解决动态刷新、基于selenium框架的爬虫、如何解决登录以及验证吗问题,以及分享了爬虫的源码:爬虫模板、基于selenium框架的爬虫模板(包含登录与验证码问题)、爬虫项目实战:爬虫模板爬取单位净值 (动态更新网址)。
还利用了爬虫模板来进行简单的入门项目:爬取豆瓣图书Top250。爬虫项目实战:利用爬虫模板爬取豆瓣图书Top250
今天我们利用基于selenium框架的爬虫模板进行另外一个简单的入门项目:爬取豆瓣电影Top250。流程基本上是一样的,但使用selenium框架我们可以解决某些看得到源码,使用request库却爬取不到的情况。
整体架构流程
整体架构流程基于selenium框架的爬虫模板
由于豆瓣电影没有使用太强的反爬机制,html源码利用F12打开开发人员工具看得到也爬得到,所以直接使用简单的爬虫模板也是可以的。但这了我们使用基于selenium框架的爬虫模板,模板请在概要或者源码的链接里自取。
技术细节
其实这里要做的与使用爬虫模板爬取豆瓣图书Top250是一样的,大家可以对比一下。
爬虫项目实战:利用爬虫模板爬取豆瓣图书Top250
需要做的修改:
- Step 2: 解析网页并提取目标数据
- Step 3: 存储数据到本地或其他持久化存储服务器中
- Step 4: 控制流程,调用上述函数完成数据抓取任务
Step 2: 解析网页并提取目标数据
对爬取到的html源码进行解析,需要我们对html语言有一定的了解,可以简单了解一下HTML 教程- (HTML5 标准),同时还需要对BeautifulSoup有了解,可以参考python爬虫之Beautifulsoup模块用法详解。
这里我们主要爬取电影的名称、人物时间地点类型、评分、简介。我们打开一个网页豆瓣电影 Top 250,F12打开开发人员工具,查看对应的html源码。
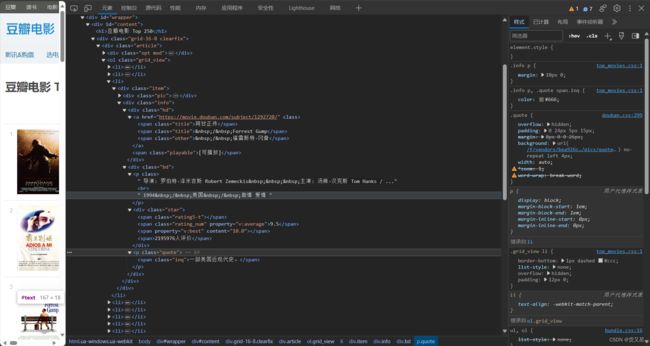
可以看到:
- 名称:有三种,中文名,外文名,别名。各自在一个span标签内,所以我们向上找它们的父标签,是一个链接标签a,不太方便查找,继续向上找,可以查找class为hd的div标签,然后在这个标签里去找class为title或other的span标签。注意到在外文名、别名前有
/,爬取后会变成\xa0/\xa0,所以需要将他们去掉。
data_list = []
data_list.append([[j.text.replace("\xa0/\xa0", "") for j in i.find_all('span', ['title', 'other'])]
for i in soup.find_all('div', 'hd')]) # 电影名
- 人物时间地点类型:在class为空的p标签里,所以只能向上找class为bd的div标签,然后再在这个标签里去找p标签。一样需要对爬取下来的字符串进行处理,包括
\ 、\n、空格等等
。
wwww = []
for i in soup.find_all('div', 'bd'):
tmp = []
for j in i.find('p', _class=''):
text = j.text.replace("\xa0\xa0\xa0", '\\')
text = text.replace("\xa0", "")
text = text.replace("\n", "")
text = text.replace(" ", "")
if text != "" and text != '豆瓣':
tmp.append(text)
if len(tmp) != 0:
wwww.append(tmp)
data_list.append(wwww) # who when where what
- 评分:由于评分所在的标签span,既有属性class=“rating_num”,又有property=“v:average”,所以很明显可以直接查找。
data_list.append([i.text for i in soup.find_all('span', {'class': "rating_num", 'property': "v:average"})]) # 评分
- 简介:在一个p标签里面,但它所在的span标签有class为inq,可以直接查找。不过比起其它三个,某些书没有这一项,所以有可能会对应不上,于是对于没有的,我们把它设为空。因此,我们也没办法直接查找span标签了,所以我们通过它的祖先标签div,class值为info间接搜索它,找到的直接添加在数据列表,没有就加空字符串。
About = []
for i in soup.find_all('div', 'info'):
if i.find('span', 'inq'):
About.append(i.find('span', 'inq').text)
else:
About.append(" ")
data_list.append(About) # 简介
Step 3: 存储数据到本地或其他持久化存储服务器中
在step2中,我们将爬取到250部电影的名字、人物时间地点类型、评分、简介分别存在一个列表当中,一共4个列表,再把它们放在一个大列表中。这一步要做的是就是把他们存储在txt或者其它文件当中,还是比较简单的,主要就是文件的读取而已。
与爬取图书稍有不同,电影名字可能有中文名,外文名,别名,也有可能只有中文名和别名,这里需要区分一下。还有就是人物时间地点类型,会分成两部分爬取,即人物、时间地点类型。评分与简介是一样的。
with open("豆瓣电影Top250.txt", 'a', encoding='utf-8') as file:
for i in range(25):
if len(result_list[0][i]) == 2:
file.write("Chinese name: " + result_list[0][i][0] + '\n')
file.write("Other name: " + result_list[0][i][1] + '\n')
elif len(result_list[0][i]) == 3:
file.write("Chinese name: " + result_list[0][i][0] + '\n')
file.write("Foreign name: " + result_list[0][i][1] + '\n')
file.write("Other name: " + result_list[0][i][2] + '\n')
file.write("Who: " + result_list[1][i][0] + '\n')
file.write("When/Where/What: " + result_list[1][i][1] + '\n')
file.write("Score: " + result_list[2][i] + '\n')
file.write("About: " + result_list[3][i] + '\n')
file.write('=' * 50 + '\n')
Step 4: 控制流程,调用上述函数完成数据抓取任务
与基于selenium框架的爬虫模板相比,这一步只需稍微修改,原因是豆瓣的每一页只有25部电影,而我们要爬取的是Top250的。那么如何解决呢,观察榜单的链接可以发现榜单的每一页的链接都只是在 https://movie.douban.com/top250?start= 的后面加上0、25…而已,所以简单遍历一下就可以了。
与爬取豆瓣图书Top250相比则在于需要打开关闭浏览器。
driver = webdriver.Firefox() # 打开火狐浏览器
spider = MySpider()
url = "https://movie.douban.com/top250?start="
for page in trange(0, 250, 25):
target_url = url + str(page)
html_content = spider.get_html_content(target_url)
if html_content:
result_list = spider.parse_html(html_content)
spider.store_data(result_list)
else:
print("网页访问失败")
driver.close() # 关闭浏览器
结果
部分结果如图

源码
基于selenium框架的爬虫模板请看爬虫:解决动态刷新、基于selenium框架的爬虫、解决登录以及验证码问题(含爬虫模板)
from selenium import webdriver # 打开网页爬取源码
from bs4 import BeautifulSoup # 解析源码
from tqdm import trange
class MySpider():
def __init__(self):
pass
# Step 1: 访问网页并获取响应内容
def get_html_content(self, url):
try:
driver.get(url)
driver.set_page_load_timeout(10) # 设置超时限制10s
html_content = driver.page_source # 网页内容
return html_content # 返回网页内容
except Exception as e:
print(f"网页请求异常:{e}")
return None
# Step 2: 解析网页并提取目标数据
def parse_html(self, html_content):
soup = BeautifulSoup(html_content, 'html.parser') # 解析 html 数据
# TODO:根据需求编写解析代码,并将结果保存到合适的数据结构中
data_list = []
data_list.append([[j.text.replace("\xa0/\xa0", "") for j in i.find_all('span', ['title', 'other'])]
for i in soup.find_all('div', 'hd')]) # 电影名
wwww = []
for i in soup.find_all('div', 'bd'):
tmp = []
for j in i.find('p', _class=''):
text = j.text.replace("\xa0\xa0\xa0", '\\')
text = text.replace("\xa0", "")
text = text.replace("\n", "")
text = text.replace(" ", "")
if text != "" and text != '豆瓣':
tmp.append(text)
if len(tmp) != 0:
wwww.append(tmp)
data_list.append(wwww) # who when where what
data_list.append([i.text for i in soup.find_all('span', {'class': "rating_num", 'property': "v:average"})]) # 评分
About = []
for i in soup.find_all('div', 'info'):
if i.find('span', 'inq'):
About.append(i.find('span', 'inq').text)
else:
About.append(" ")
data_list.append(About) # 简介
return data_list
# Step 3: 存储数据到本地或其他持久化存储服务器中
def store_data(self, result_list):
# TODO:编写存储代码,将数据结果保存到本地或其他服务器中
with open("豆瓣电影Top250.txt", 'a', encoding='utf-8') as file:
for i in range(25):
if len(result_list[0][i]) == 2:
file.write("Chinese name: " + result_list[0][i][0] + '\n')
file.write("Other name: " + result_list[0][i][1] + '\n')
elif len(result_list[0][i]) == 3:
file.write("Chinese name: " + result_list[0][i][0] + '\n')
file.write("Foreign name: " + result_list[0][i][1] + '\n')
file.write("Other name: " + result_list[0][i][2] + '\n')
file.write("Who: " + result_list[1][i][0] + '\n')
file.write("When/Where/What: " + result_list[1][i][1] + '\n')
file.write("Score: " + result_list[2][i] + '\n')
file.write("About: " + result_list[3][i] + '\n')
file.write('=' * 50 + '\n')
# Step 4: 控制流程,调用上述函数完成数据抓取任务
if __name__ == '__main__':
driver = webdriver.Firefox() # 打开火狐浏览器
spider = MySpider()
url = "https://movie.douban.com/top250?start="
for page in trange(0, 250, 25):
target_url = url + str(page)
html_content = spider.get_html_content(target_url)
if html_content:
result_list = spider.parse_html(html_content)
spider.store_data(result_list)
else:
print("网页访问失败")
driver.close() # 关闭浏览器