对话诊断(X)2021Neurocomputing-Heterogeneous graph reasoning for knowledge-grounded medical DS

作者:梁晓丹组
论文链接:论文链接
代码链接:无
Abstract:
除了任务对话系统面临的常见困难外,医学对话由于其巨大的应用潜力而受到越来越多的关注,同时对使用医学领域的知识和逻辑进行推理带来了更多的挑战。现有的工作采用神经语言模型嵌入对话,忽略了显式逻辑推理,导致可解释和泛化能力较差。因此,为统一关系对话上下文理解和实体相关推理,本文提出了一个可解释的异构图推理(Heterogeneous Graph Reasoning, HGR)模型。HGR根据相应的话语对实体上下文进行编码,并通过注意图传播将基础医学知识与实体上下文融合后,推导出下一步的回答。为了推进未来对专家敏感的任务型对话系统的研究,本文首先发布了一个包括16种胃肠道疾病的大规模的医学对话顾问基准(MDG-C),用于评估顾问能力,以及一个用于测量模型诊断能力的含6种疾病的医学对话诊断基准(MDG-D)(未公开?)。
Introduction:
基于大量数据训练的端到端神经对话系统已被广泛应用于各种任务中,如电影推荐、餐厅预订、在线购物等。在这些应用中,医疗领域的对话系统由于其促进诊断程序和降低患者信息收集成本方面展现出的巨大潜力,引起了越来越多的关注。使用知识图谱建模不同症状及疾病间的相关性已经被证明可以提升医学对话过程中症状推断及疾病诊断的性能。图1展示了医学对话场景中的对话实例。在开始时患者对自己存在的健康问题进行了叙述,而后医生通过不断询问获得患者更多的信息。最终,医生根据收集的信息及临床经验(用潜在的医学知识图谱表示)做出诊断。

最近,大量基于知识的对话语料库被发布,以推动通过整合知识来生成信息响应的研究。与基础的应用相比,医学对话由于需要明确的询问逻辑以产生最终正确的诊断,所以通过实体构建更加全面的更具解释性的推理存在更大的挑战。如图1,胃溃疡以及食管炎两个疾病间存在很多共同的症状,如食欲不振、肚子疼。为进行鉴别诊断,医生在第四次询问时查询了“胸痛”这个症状,该症状至于食管炎有关,并通过患者的回答排除了相应疾病。
同时,以往基于知识的对话系统的研究大多使用一个单一的神经编码器或者预训练的语言模型进行对话嵌入[14-18],忽略了每个实体在图推理过程中不同上下文表示的建模。然而,实体上下文对于正确的诊断是十分重要的因为它一般都包含明确症状的多种属性,比如持久度、频率、严重程度。在这些属性中微小的不同通常会导致完全不同的推理路径。例如,图1中,胃溃疡和食管炎都会导致肚子疼这个症状,但如果这个症状的条件是“按压肚子”,那患者患胃溃疡的概率就会大。
为解决以上问题(询问逻辑和上下文融合?),本文提出融合两种源信息的异构图推理模型,两种源信息分别指从对话历史中得到的对话上下文以及从知识图谱中得到的实体关系。考虑到信息类型的异构问题,HGR使用三个图层作为三个不同的推理阶段。在第一个阶段,HGR通过对话转移信息。在学习实体上下文的第二个阶段,对话信息被聚合到相应的实体中。在第三个阶段,HGR通过预先定义的知识图谱进行从显性症状到隐性症状的全面推理。最终,在图推理结果的指导下,使用文案解码器生成知识相关响应。
由于现存的数据集如MZ、DXY不能支持医疗对话生成的训练,本文收集了两个胃肠道疾病的数据集:MDG-C、MDG-D。MDG-C数据集想要评估模型顾问的能力,包含16种疾病,14000轮对话。同时为了提高诊断的可信度,MDG-D包含6种相似的疾病。
本文提出有三点贡献:
- 提出了一种新的异构图推理(HGR)模型,以统一对话上下文理解和实体相关推理。基于HGR模型,建立了一个完全端到端面向任务的医疗对话系统。
- 构建两个数据集MDG-C和MDG-D,分别作为新的全科顾问和疾病诊断的基于知识的医学对话基准。
- 在MDG-C和MDG-D数据集上的客观结果和主观的人类评价都显示了本文模型的优越性,它优于广泛使用的生成模型和最先进的基于知识的对话系统。
Related works
Knowledge-grounded conversation
最近,人们对整合外部知识来提高神经对话生成的质量越来越感兴趣。一些方法利用非结构化文档作为知识来源,如维基百科文章[12]和个人信息[10]。Memory network[19]对与历史实体相关的自由形式文本进行编码,产生信息更丰富的响应。此外,Lian等人[20]对知识的先验和后验分布进行了建模,以促进知识选择,Kim等人[21]利用序列潜在变量模型对其进行了扩展。
此外,其他方法还侧重于合并结构化知识图[14,18]。Zhou等人[15]利用历史实体和常识图中的相关实体来帮助在下一个响应中对实体进行推理。Tuan等人[16]设计了一种多跳推理方法来选择图中的相对路径和实体。Zhang等人的[17]通过在处理后的概念网上应用图形注意机制来建模人类对话中的概念流。与以往的工作不同,HGR通过异构图建立了对话和知识实体之间的关系,有助于对对话历史和相关实体选择的逻辑推理。
Dialogue system for medical diagnosis
近年来对医学对话的自然语言理解研究广泛,如症状提取[22]、实体推理[8,7]和槽填充[23]。强化学习框架在对话系统中的采用,[24–26]激发了医学领域的对话管理策略学习。Wei等人迈出了使用强化学习(DQN)解决医疗对话中自动诊断得第一步。此外,Xu等人[9]提高了医疗对话决策的合理性,并将外部概率症状纳入了强化学习框架的关系。Liao等人[6]以分级的方式分配不同的工人进行症状获取和疾病诊断。然而,这些强化学习方法仅仅从包含症状存在的表格数据中学习。此外,响应的产生也被以往的工作所忽视,在实际应用中造成了巨大的差距。与这些方法相比,本文在构建端到端得生成式医疗对话系统研究中向前迈出了一步。
Proposed model
给定包含M个对话 D = { U 1 , U 2 , . . . , U M } D=\{U_1,U_2,...,U_M\} D={U1,U2,...,UM}的对话历史,对话系统需要返回含一系列单词得回复。在本文任务设置中,对话由用户开启,之后医生和患者交互对话。模型需要产生每次对话交互时医生的回复 ( U 2 , U 4 , . . . ) (U_2,U_4,...) (U2,U4,...)。如图2所示,本文所提模型由三个重要部分组成,包括一个分层对话编码器,一个异质图推理模型,一个基于图指导的回复生成器。

Hierarchical dialogue encoder
本文使用分层循环编码器编码对话历史信息,该编码器由两个不同的循环神经网络(RNN)构成。具体的,第一个RNN将每个对话 U i U_i Ui映射到一个对话向量 h i u h_i^u hiu,这是在会话最后一个单词被处理后得到的隐藏状态。之后得到的一系列编码后的会话向量 { h 1 u , h 2 u , . . . , h M u } \{h_1^u,h_2^u,...,h_M^u\} {h1u,h2u,...,hMu}需要经过另一个上下文循环神经网络。第二个人RNN的最终隐藏状态代表了会话历史的概要信息,由 h d i a l h_{dial} hdial表示。
Heterogeneous graph reasoning
异构图结构在文本分类[28]和视觉推理[29]等任务中得到了广泛的应用,但如何在对话系统中的应用尚未得到研究。本文构建了一个将对话上下文理解和医学知识推理融合的异构图推理网络。异构图由 G = ( V , ε ) \mathcal{G}=(\mathcal{V},\mathcal{\varepsilon}) G=(V,ε)表示。
节点 HG通过引入两种类型的节点来考虑医学对话中各种信息类型的异质性。节点集 V \mathcal{V} V由实体节点 E = { e 1 , . . . , e N } E=\{e_1,...,e_N\} E={e1,...,eN}和对话节点 U = { u 1 , . . . , u M } U=\{u_1,...,u_M\} U={u1,...,uM}组成, V = E ∪ U \mathcal{V}=E∪U V=E∪U。实体节点由数据集中标准的疾病和症状组成,每个实体节点 e i e_i ei的特征向量由一个可学习的实体嵌入模型初始化,对话节点 u i u_i ui由关联的对话向量 h i u h_i^u hiu进行初始化。
边 HG根据连接节点的不同将边 ε \mathcal{\varepsilon} ε分为三种类型:会话节点-会话节点、会话节点-实体节点、实体节点-实体节点。首先,第 i i i个会话节点 u i u_i ui与其前 k k k个会话节点相连以实现节点间信息的转移。其次,每个会话实体 u i u_i ui与通过在对话中的字符串匹配提取的实体节点相连接。对于每个实体,需要维护一个由医学专家提供的同义表达式列表。第三,根据从[30]获得的医学知识图作为外部知识源,如果两个实体相关联,则两个实体节点之间的边是连接的。 为处理知识图谱的稀疏性问题,本文将语料库中共现次数大于某一阈值的实体进行相连。 \colorbox{pink}{为处理知识图谱的稀疏性问题,本文将语料库中共现次数大于某一阈值的实体进行相连。} 为处理知识图谱的稀疏性问题,本文将语料库中共现次数大于某一阈值的实体进行相连。三种类型的边分别用 ε 1 \varepsilon_1 ε1、 ε 2 \varepsilon_2 ε2、 ε 3 \varepsilon_3 ε3表示。
层 直观地说,异构图中不同类型的边在信息转换中具有不同的用途。如图2所示,本文提出的异构图包括三层。图中第 l l l层只包含边 ε l \varepsilon_l εl集合中的边,因此一层只关注一种类型的信息转移。在第一层中,每个话语与前 k k k个话语相连,通过从上下文中收集更多的症状属性来增强实体相关的表示。然后,通过收集相关话语节点的信息,在第二层激活对话历史中出现的这些实体。在第三层中,被激活的实体节点将信息扩散到其他相关节点,从而将信息从显式实体传递到相对隐式实体,用于症状探索和疾病诊断。
如图2所示,会话节点 u 1 u_1 u1与 u 2 u_2 u2、 u 3 u_3 u3相连,可以获得腹痛症状的更多属性,如“一个多月了”。然后第二层可以从三个对应的话语节点 u 1 u_1 u1与 u 2 u_2 u2、 u 3 u_3 u3中收集实体节点“腹痛”的上下文信息,并扩散到其他相关实体,如第三层的“食管炎”。
传播 本文的图传播方法改编自图注意力神经网络(GAT)[31]。然而传统的GAT并不能促进各种信息类型的异质性。为解决这个问题,HGR采用一种动态的方法在不同层中切换边来传播图。(??)。具体的,用 h i ( l ) h_i^{(l)} hi(l)表示第 i i i个节点的隐藏表示并且 N i ( l ) \mathcal{N_i^{(l)}} Ni(l)为节点在第 l l l层的相邻节点的集合。 h i ( 0 ) h_i^{(0)} hi(0)表示第 i i i个节点的初始特征向量, h i ( l ) h_i^{(l)} hi(l)通过以下公式进行更新:(第一层的实体节点不是会话节点如何表示?)
h i ( l ) = σ ( ∑ j ∈ N i ( l ) α i j W l h j ( l − 1 ) ) α i j = S o f t m a x j ∈ N i ( l ) ( a i j ) a i j = σ ′ ( v l T [ W l h i ( l − 1 ) ∣ ∣ W l h j ( l − 1 ) ] ) h_i^{(l)}=\sigma(\sum_{j\in \mathcal{N_i^{(l)}}}\alpha_{ij}W_lh_j^{(l-1)}) \\ \quad\\ \alpha_{ij}=Softmax_{j\in \mathcal{N_i^{(l)}}}(a_{ij}) \\ \quad\\ a_{ij}=\sigma^\prime(\mathcal{v}_l^T[W_lh_i^{(l-1)}||W_lh_j^{(l-1)}]) hi(l)=σ(j∈Ni(l)∑αijWlhj(l−1))αij=Softmaxj∈Ni(l)(aij)aij=σ′(vlT[Wlhi(l−1)∣∣Wlhj(l−1)])
其中 v l ∈ R 2 h \mathcal{v}_l\in \mathbb{R}^{2h} vl∈R2h, W l ∈ R h × h W_l\in \mathbb{R}^{h \times h} Wl∈Rh×h是第 l l l层可学习的参数。 σ \sigma σ及 σ ′ \sigma^\prime σ′表示非线性激活函数, ∣ ∣ || ∣∣为连接操作。 α i j \alpha_{ij} αij为注意权重,表示节点 j j j的特征对节点 i i i的影响。
预测 本文将实体预测作为一个辅助任务,以促进图的学习。HGR通过对每个实体节点进行二进制分类来预测下一个医生的话语中的实体。每个节点的最终状态输入到sigmoid函数中,以预测每个实体的发生概率。实体预测的损失函数定义为所有实体上的交叉熵误差,由 L e \mathcal{L}_e Le表示。
Graph guided response generation
生成模型通过传播的图信息生成词序列。解码器架构改编自指针生成器网络[32],而主要的区别在于本文将注意机制应用于图实体上,而不是源tokens。令 x t x_t xt作为解码器RNN的输入, s t s_t st为第 t t t步的隐藏状态,由对话编码器的最后一个状态 h d i a l h_{dial} hdial进行初始化。解码器状态 s t s_t st用于构建图实体节点最后状态 h i e h_i^e hie的巴达瑙注意力:
a i = v T t a n h ( w 1 T [ s t ∣ ∣ h i e ] + b 1 ) α i = S o f t m a x 1 ≤ i ≤ N ( a i ) h t g = ∑ i α i h i e a^i=v^Ttanh(w_1^T[s_t||h_i^e]+b_1) \\ \quad\\ \alpha^i = Softmax_{1 \leq i \leq N}(a^i) \\ \quad\\ h_t^g=\sum_i \alpha^i h_i^e ai=vTtanh(w1T[st∣∣hie]+b1)αi=Softmax1≤i≤N(ai)htg=i∑αihie
其中 v v v、 w 1 w_1 w1、 b 1 b_1 b1是参数。 α i \alpha_i αi是实体 e i e_i ei的注意力权重, h t g h_t^g htg表示图信息的聚合。
如图2右半部分所示,生成第 t t t个词的概率分布由 P E P_E PE和 P N P_N PN组成。 P E P_E PE是注意力分布的一个扩展,实体 e i e_i ei的生成概率为用注意力权重 α i \alpha_i αi来表示,非实体概率为0。 P N P_N PN为解码器RNN生成的词汇分布。最终预测的概率分布 P V P_V PV计算如下:
p g = σ ( w 2 T [ x t ∣ ∣ s t ∣ ∣ h t g ] + b 2 ) P V = ( 1 − p g ) ⋅ P E + p g ⋅ P N p_g=\sigma (w_2^T[x_t||s_t||h_t^g]+b_2) \\ \quad\\ P_V=(1-p_g)\cdot P_E + p_g \cdot P_N pg=σ(w2T[xt∣∣st∣∣htg]+b2)PV=(1−pg)⋅PE+pg⋅PN
其中 w 2 w_2 w2、 b 2 b_2 b2为参数, σ \sigma σ为sigmoid函数。生成概率 p g ∈ [ 0 , 1 ] p_g\in[0,1] pg∈[0,1]为一个门变量,用来指示词是否正常的词汇生成还是通过图中节点得到。
生成的Loss是整个序列与目标序列 { w t ∗ } ( 1 ≤ t ≤ T ) \{w_t^*\}(1\leq t \leq T) {wt∗}(1≤t≤T)的平均负的对数似然:
L g = 1 T ∑ t = 1 T l o g P ( w t ∗ ) \mathcal{L}_g=\frac{1}{T}\sum_{t=1}^{T}logP(w_t^*) Lg=T1t=1∑TlogP(wt∗)
为平衡实体预测loss L e \mathcal{L}_e Le和生成loss L g \mathcal{L}_g Lg,使用超参数 β \beta β:
L = L g + β L e \mathcal{L}=\mathcal{L}_g+\beta\mathcal{L}_e L=Lg+βLe
Dataset
本文提到了两个新的数据集MDG-C、MDG-D。
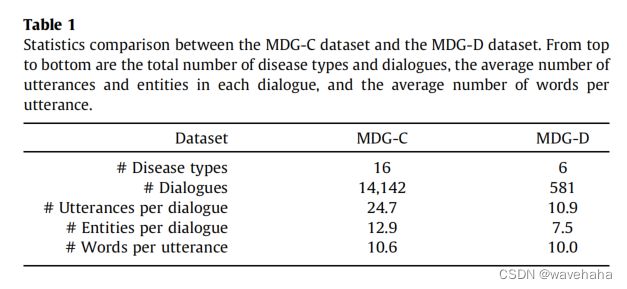
MDG-C数据集是为一般医疗顾问场景构建的。源会话语料库来自两个中国在线健康中心的消化内科的对话数据,患者可以提交关于他们的胃肠道健康问题的帖子,然后与医生沟通获得医生的建议及初步诊断。医疗知识图谱来源于CMeKG1.0 [30],由16种胃肠道疾病、62种症状和336条关系边组成。本文使用医学专家提供的模板和手工制作的规则从收集的语料库中检测图中实体。其中没有足够的回合数和提取的实体的对话将被忽略,那些包含个人信息、图像或音频的对话也将被过滤。最后获得了14,142个对话样本,并将其按7:1:2的比例近似分割,以获得训练、验证和测试集。
为了进一步设置一个令人信服的面向任务的对话基准,以便从给定的背景下进行疾病诊断,引入了另一个名为MDG-D的数据集。在咨询专家后,选择了6种难以区分的相对胃肠道疾病作为诊断目标。
Experiments
Experimental setup
-
Seq2Seq是一个经典的基于注意力的序列到序列模型,使用普通的RNN编码器和解码器。
-
HRED [27]扩展了Seq2Seq中的传统编码器,以一种分层的方式堆叠两个RNN:一个在单词级别,另一个在话语级别。
-
Ptr-Gen [32]通过一个混合指针生成器网络增强了基于注意的标准Seq2Seq模型,以方便从源文本中复制单词。
为了验证HGR模型中的知识表示和推理的效率,模型与几种最先进的基于知识的对话系统进行对比。为了确保每个解决方案都能充分利用医学领域的知识,本文通过预定义的模板将包含相关症状和疾病的知识图转换为一组知识三联体或句子。对比模型如下:
- Seq2Seq-know and HRED-know[18],两者都在前面提到的Seq2Seq和HRED基线中引入了一个键值内存模块。利用编码器产生的上下文向量作为查询向量,并将解码过程中的值向量的加权和与初始状态进行连接。
- NKD [14]利用一个由多个多层感知器组成的神经知识扩散模块,将相对实体合并到对话生成中。
- **PostKS **[20]利用知识之上的先验分布和后验分布来选择最合适的生成知识。
衡量标准 句子平滑水平的BLUE-1和BLUE-4用作衡量uni-gram和four-gram词汇相似程度。(??)Entity-P/R/F1计算生成响应中的预测实体和Gloden实体之间的precision/recall/F1 score,以衡量利用医学领域知识的正确性。在MDG-D数据集中,通过Diagnosis-P/R/F1对所有对话生成的预测疾病进行评估,进一步评估每个模型的诊断能力。
配置 所有基线在两个数据集上共享相同的配置设置。使用pkuseg [35]工具包进行医学领域中文分词。RNN编码器和解码器使用单层LSTM [36]。所有实验均在AllenNLP平台[37]上实现。
Results

如表3所示,如果去掉第一个图层,两个数据集的BLEU分数显著下降,说明会话节点之间的信息共享过程能够增强上下文信息。没有第二层的图,模型直接将话语节点的隐藏状态复制到相应的实体节点,由于实体节点无法有选择性地从对话中聚合话语信息,所以所有的指标都显著减少了。在没有第三层的情况下,由于无法利用实体之间的关系,HGR的诊断能力会受到很大的影响。
Human evaluation

Case study

Seq2Seq在没有使用知识的情况下,连续三次重复两个常见的实体“恶心”和“呕吐”。Seq2Seq-know和NKD可以在最后一轮质疑适当的症状并进行疾病诊断,但症状检查和疾病诊断会存在错误。

图4展示了一个测试用例(左)和异构图第三层的图(右)的注意权重。可以看出,正确的实体“胃炎”与对话史中存在的五个实体有关。在这些实体中,“内部气体”(0.216)和“胃痛”(0.167)比“胃酸反流”(0.058)和“胃灼热”(0.058)贡献更高的注意力权重,这与前两个实体对“胃炎”的诊断更重要的事实相匹配。注意权重和实体重要性之间的一致性表明了HGR模型的可解释性。
Conclusion
本文提出了一个异构图推理模型(HGR),该模型可以充分融合上下文信息和领域知识以更好地进行医学对话过程中的实体推理。本文收集了两个新的数据集作为医学对话和诊断的新的基准。通过对比证明了HGR模型的优越性能。
作为结合知识图推理和医学对话系统的初步尝试,本文只研究了与胃肠道疾病相关的对话。一旦收集到知识图和一定数量的高质量对话,HGR模型可以很容易地适应于其他疾病。同时,HGR模型也有潜力扩展到一般的临床场景和其他类似的应用。
参考文献:
K.-F. Tang, H.-C. Kao, C.-N. Chou, E.Y. Chang, Inquire and diagnose: Neural symptom checking ensemble using deep reinforcement learning, in: Proceedings of NIPS Workshop on Deep Reinforcement Learning, 2016…
Z. Wei, Q. Liu, B. Peng, H. Tou, T. Chen, X. Huang, K.-F. Wong, X. Dai, Task oriented dialogue system for automatic diagnosis, in: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, 2018, pp.
K. Liao, Q. Liu, Z. Wei, B. Peng, Q. Chen, W. Sun, X. Huang, Task-oriented dialogue system for automatic disease diagnosis via hierarchical reinforcement learning, CoRR abs/2004.14254. arXiv:2004.14254…
(待看)N. Du, M. Wang, L. Tran, G. Lee, I. Shafran, Learning to infer entities, properties and their relations from clinical conversations, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP IJCNLP), 2019, pp. 4979–4990.201–207.
(待看)X. Lin, X. He, Q. Chen, H. Tou, Z. Wei, T. Chen, Enhancing dialogue symptom diagnosis with global attention and symptom graph, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019, pp. 5033–5042.
L. Xu, Q. Zhou, K. Gong, X. Liang, J. Tang, L. Lin, End-to-end knowledge-routed relational dialogue system for automatic diagnosis, in: Proceedings of the Thirty-Third AAAI Conference on Artifificial Intelligence, 2019.
(待看)S. Zhang, E. Dinan, J. Urbanek, A. Szlam, D. Kiela, J. Weston, Personalizing dialogue agents: I have a dog, do you have pets too?, in: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, 2018, pp 2204–2213.
(待看)N. Moghe, S. Arora, S. Banerjee, M.M. Khapra, Towards exploiting background knowledge for building conversation systems, in: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, 2018, pp. 2322–2332.
(待看)E. Dinan, S. Roller, K. Shuster, A. Fan, M. Auli, J. Weston, Wizard of wikipedia: knowledge-powered conversational agents, in: 7th International Conference on Learning Representations, ICLR, 2019.
(待看)W. Wu, Z. Guo, X. Zhou, H. Wu, X. Zhang, R. Lian, H. Wang, Proactive human machine conversation with explicit conversation goal, in: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 3794–3804.
…