【强化学习】Deep Q Learning
Deep Q Learning
在前两篇文章中,我们发现RL模型的目标是基于观察空间 (observations) 和最大化奖励和 (maximumize sum rewards) 的。
如果我们能够拟合出一个函数 (function) 来解决上述问题,那就可以避免存储一个 (在Double Q-Learning中甚至是两个) 巨大的Q_table。
Tabular -> Function
- Continous Observation: 函数能够让我们处理连续的观察空间,而表只能处理离散的。
- Saving the space: 不用存储
len(state) * len(action)大小的Q_table
在早期人们试过使用核函数或者线性函数等各种方法去拟合这个function,但后来深度神经网络出现后人们纷纷开始研究如何用DNN来拟合。
然而以上的拟合方式不免存在一个问题,我们期望得到一个DNN,使得DNN(state)->Q-value。
可是强化学习中,最好的Q-value在开始时是不知道的 (这也是强化学习和机器学习不一样的地方:我们不知道能否训练到一个Q值,直到有人把它训练出来),这就导致我们在训练过程中没有目标函数。
Natural Deep Q Learning
所有的第一步必须从高维的感官输入中获得对环境的有效表示
深度Q网络(DQN)是一种将深度学习和Q学习相结合的强化学习方法。DQN由DeepMind于2015年提出,并在玩Atari视频游戏方面取得了显著的成功。DQN的核心原理是使用深度神经网络来近似Q函数,即在给定状态下采取某一动作的预期累积奖励。
DQN的关键创新
-
使用神经网络近似Q函数:
- 传统的Q学习使用表格(Q表)来存储每个状态-动作对的Q值。当状态空间很大或连续时,这变得不切实际。
- DQN通过使用深度神经网络来近似Q函数,克服了这一限制。网络输入是状态,输出是该状态下所有可能动作的Q值。
-
经验回放:
-
DQN引入了经验回放机制,即将代理的经验(状态、动作、奖励、新状态)存储在回放缓冲区中。

-
训练时,从这个缓冲区中随机抽取小批量经验进行学习。这增加了数据的多样性,减少了样本之间的相关性,从而稳定了训练。
-
-
目标网络:
- DQN使用两个结构相同但参数不同的网络:一个是在线网络 (dqn_model),用于当前Q值的估计;另一个是目标网络 (target_model),用于计算目标Q值。
- 目标网络的参数定期从在线网络复制过来,但不是每个训练步骤都更新。这减少了学习过程中的震荡,提高了稳定性。

训练过程
- 在每个时间步,代理根据当前的Q值(通常结合探索策略,如ε-贪婪)选择一个动作,接收环境的反馈(新状态和奖励),并将这个转换存储在经验回放缓冲区中。
- 训练神经网络时,从缓冲区中随机抽取一批经验,然后使用贝尔曼方程计算目标Q值和预测Q值,通过最小化这两者之间的差异来更新网络参数。
DQN解决月球着陆问题
导入环境
import time
from collections import defaultdict
import gymnasium as gym
import numpy as np
import random
from matplotlib import pyplot as plt, animation
from IPython.display import display, clear_output
env = gym.make("LunarLander-v2", continuous=False, render_mode='rgb_array')
定义经验池
class ExperienceBuffer:
def __init__(self, size=0):
self.states = []
self.actions = []
self.rewards = []
self.states_next = []
self.actions_next = []
self.size = 0
def clear(self):
self.__init__()
def append(self, s, a, r, s_n, a_n):
self.states.append(s)
self.actions.append(a)
self.rewards.append(r)
self.states_next.append(s_n)
self.actions_next.append(a_n)
self.size += 1
def batch(self, batch_size=128):
indices = np.random.choice(self.size, size=batch_size, replace=True)
return (
np.array(self.states)[indices],
np.array(self.actions)[indices],
np.array(self.rewards)[indices],
np.array(self.states_next)[indices],
np.array(self.actions_next)[indices],
)
import torch
from torch import nn
from torch.nn.functional import relu
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
定义DQN
class DQN(nn.Module):
def __init__(self, state_size, action_size):
super().__init__()
self.state_size = state_size
self.action_size = action_size
self.hidden_size = 32
self.linear_1 = nn.Linear(self.state_size, self.hidden_size)
self.linear_2 = nn.Linear(self.hidden_size, self.action_size)
nn.init.uniform_(self.linear_1.weight, a=-0.1, b=0.1)
nn.init.uniform_(self.linear_2.weight, a=-0.1, b=0.1)
def forward(self, state):
if not isinstance(state, torch.Tensor):
state = torch.tensor([state], dtype=torch.float)
state = state.to(device)
return self.linear_2(relu(self.linear_1(state)))
定义policy
def policy(model, state, eval=False):
eps = 0.1
if not eval and random.random() < eps:
return random.randint(0, model.action_size - 1)
else:
q_values = model(torch.tensor([state], dtype=torch.float))
action = torch.multinomial(F.softmax(q_values), num_samples=1)
return int(action[0])
collect
dqn_model = DQN(state_size=8, action_size=4).to(device)
target_model = DQN(state_size=8, action_size=4).to(device)
from tqdm.notebook import tqdm
# 学习率
alpha = 0.9
# 折扣因子
gamma = 0.95
# 训练次数
episode = 1000
experience_buffer = ExperienceBuffer()
eval_iter = 100
eval_num = 100
# collect
def collect():
for e in tqdm(range(episode)):
state, info = env.reset()
action = policy(dqn_model, state)
sum_reward = 0
while True:
state_next, reward, terminated, truncated, info_next = env.step(action)
action_next= policy(dqn_model, state_next)
sum_reward += reward
experience_buffer.append(
state, action, reward, state_next, action_next
)
if terminated or truncated:
break
state = state_next
info = info_next
action = action_next
learning
## learning
from torch.optim import Adam
loss_fn = nn.MSELoss()
optimizer = Adam(lr=1e-5, params=dqn_model.parameters())
losses = []
target_fix_period = 5
epoch = 3
def train():
for e in range(epoch):
batch_size = 128
for i in range(experience_buffer.size // batch_size):
s, a, r, s_n, a_n = experience_buffer.batch(batch_size)
s = torch.tensor(s, dtype=torch.float).to(device)
s_n = torch.tensor(s_n, dtype=torch.float).to(device)
r = torch.tensor(r, dtype=torch.float).to(device)
a = torch.tensor(a, dtype=torch.long).to(device)
a_n = torch.tensor(a_n, dtype=torch.long).to(device)
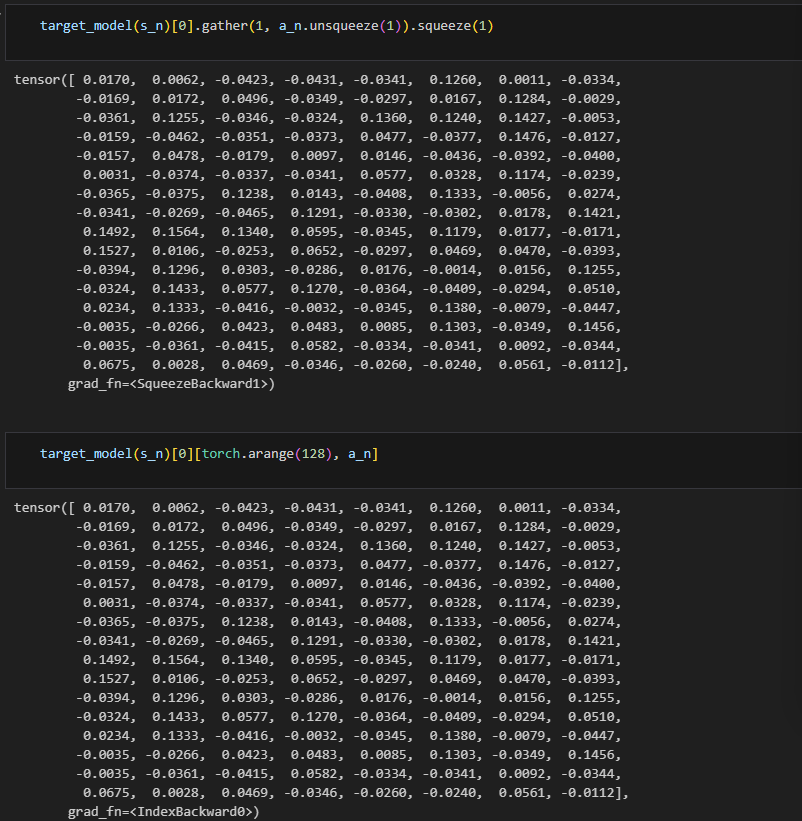
y = r + target_model(s_n).gather(1, a_n.unsqueeze(1)).squeeze(1)
y_hat = dqn_model(s).gather(1, a.unsqueeze(1)).squeeze(1)
loss = loss_fn(y, y_hat)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 500 == 0:
print(f'i == {i}, loss = {loss} ')
if i % target_fix_period == 0:
target_model.load_state_dict(dqn_model.state_dict())
a_n:动作
s_n:状态
将状态
s_n作为输入,target_model的输出是针对每个可能动作的 Q 值;如果s_n包含多个状态(比如一个批量),输出将是一个批量的 Q 值


训练
for i in range(10):
print(f'collect/train: {i}')
experience_buffer.clear()
collect()
train()
结果
task_num = 10
frames = []
for _ in range(10):
state, _ = env.reset()
while True:
action = policy(dqn_model, state, eval=True)
state_next, reward, terminated, truncated, info_next = env.step(action)
frames.append(env.render())
if terminated or truncated:
break