comfyUI + animateDiff video2video AI视频生成工作流介绍及实例
原文:comfyUI + animateDiff video2video AI视频生成工作流介绍及实例 - 知乎
目录
收起
前言
准备工作环境
comfyUI相关及介绍
comfyUI安装
生成第一个视频
进一步生成更多视频
注意事项
保存为不同的格式
视频宽高设置
种子值设置
提示词与负向提示词
节点变换提示词
controlnet权重控制
总结
参考
前言
最近一段时间,使用stable diffusion + animateDiff生成视频非常热门,但普通用户想要在自己电脑上成功生成一段视频并不容易。本文将介绍如何加载comfyUI + animateDiff的工作流,并生成相关的视频。在本文中,主要有以下几个部分:
- 设置视频工作环境
- 生成第一个视频
- 进一步生成更多视频
- 注意事项介绍
准备工作环境
comfyUI相关及介绍
comfyUI是一个节点式和流式的灵活的自定义工作流的AI画图软件。使用comfyUI可以方便地进行文生图、图生图、图放大、inpaint 修图、加载controlnet控制图生成等等,同时也可以加载如本文下面提供的工作流来生成视频。 相较于其他AI绘图软件,在视频生成时,comfyUI有更高的效率和更好的效果,因此,视频生成使用comfyUI是一个不错选择。
comfyUI安装
具体可参考comfyUI 页面介绍,安装python环境后一步步安装相关依赖,最终完成comfyUI的安装。相关过程需要对python语言及pip安装有一定的了解。具体安装步骤本文不再详细介绍,如有需要您可以自行搜索解决。如果您的电脑上安装好了comfyUI,那么可以进入下一步加载工作流及视频,开始生成。
如果您是普通用户,不想自己一步步的安装python环境及相关软件,那么您可以从tensorbee 官网下载安装tensorbee, 也可直接点击 下载链接 进行下载。tensorbee安装好后,在tensorbee 中点击下载它的 AnimateComfy, tensorbee将会为您配置好comfyUI的工作环境,和本文的使用的工作流,您只需要点击生成,即可生成第一个视频。
生成第一个视频
第一个待生成视频的原始视频为:

00:02
我们的目标是让AI学习该视频中的手势动作,生成一个新的视频。
为此,我们需要使用以下工作流

comfyUI animatediff vid2vid工作流
注意:如果您是tensorbee用户,只需要点击右侧的 Queue Prompt开始生成即可。可跳过这一节的加载工作流等内容。
您可以下载以下图片,然后使用comfyUI右侧的load按钮加载该图片,加载上面的工作流。

含工作流的图片
加载成功后。使用右侧的manager安装工作流对应缺失的节点并多次重启,使工作流能正常加载。
非tensorbee的用户,请自行下载工作流中相关的模型:
aniverse 模型
animatediff 1.5模型
lcm_sd1.5_lora: latent-consistency/lcm-lora-sdv1-5 放到loras目录
将以上模型及lora放到comfyUI对应的目录,即可开始生成第一个视频。
工作流中其他controlnet相关的模型,comfyUI应该可以自行下载。
在3070ti的机器上,大约3分钟后,就能够完成生成。生成的视频如下:

00:02
进一步生成更多视频
由于该工作流使用了最新的清华出品的Latent Consistency Models技术,采样环节只需六步即可生成对应的视频,同样两秒左右的视频,使用20步采样,在3070ti的机器上,原来需要8分钟,使用了LCM lora后仅需要3分钟,如果重复生成,则需要的时间更短。因此,使用该工作流,可以尝试制作长视频。
由于视频加载器目前设置帧数最大1200,如果每秒12帧,则最长可生成100秒的视频,博主使用以下88秒的视频进行测试。

01:24
最终生成以下视频:

01:28
在3070ti的机器上,用时1小时,相对于其他的方式。生成视频的速度还是相当快的。
注意事项
保存为不同的格式
在video combine组件的格式设置区,可修改视频的输出格式,当前默认为mp4,您可以修改为gif、webp等便于您分享。
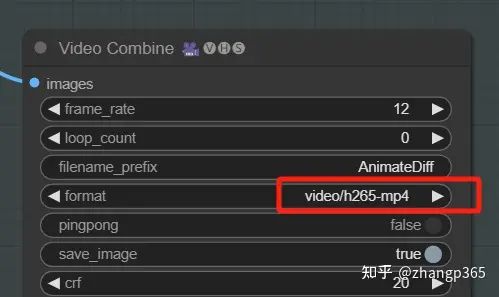
视频格式修改
视频宽高设置
在左上角的输入区,您需要按原始视频的比例设置视频的宽度和高度。注意,最好其中的一个数值保持为512,改变另一个数值,使生成的视频与原始视频的比例一致。

宽高设置
种子值设置
目前工作流的种子值设置为固定,如果您需要多次尝试更好的效果,可将种子值为为随机。
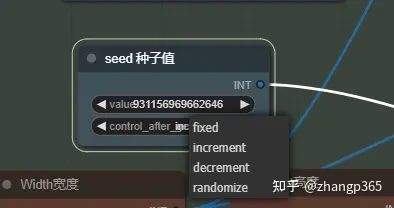
种子值设置
提示词与负向提示词
您可以提示词区调整提示词及负向提示词,注意提示词最后最好加上一个逗号,以便与下面的节点变换提示词控制更好的组合。

提示词设置
节点变换提示词
在此输入框中,可设置开始帧数及对应的场景。比如下面的分别设置了0和16帧时开始使用不同的场景。

节点变换控制
注意,上面的输入框中必须使用英文的引号、冒号及逗号。同时,最重要的是,最后一行不能有逗号,其他的行必须要有逗号。
controlnet权重控制
当前工作流中,controlnet的权限设置为0.5,该值最好设置在0.3~0.6之间,不要太大,否则会影响视频的生成效果。

总结
此工作流主要的流程是提取原始视频的人体关节图,以控制AI生成视频中对应的动作。视频中的其他内容由提示词控制生成。
因此,您如果旁通上面的controlNet节点,该工作流就自然变成一个文生视频的工作流。
参考
How does AnimateDiff Prompt Travel work?
latent-consistency-model