深度估计之旅 — AICrowd单目深度感知

训练图像示例与真实标签
最近,我参加了AICrowd单目深度感知比赛,这是我机器学习之旅中的一个值得自豪的里程碑。我获得了第四名,并获得了“最创意解决方案奖”。在这篇文章中,我将详细介绍挑战、我的方法以及所学到的经验。我还开源了代码和模型权重,可以在这里访问 - SAUDD2023。
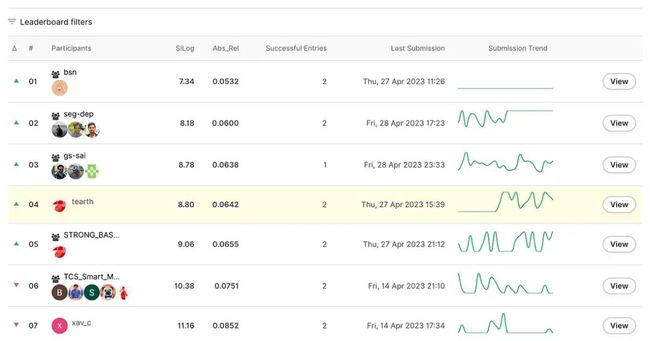
最终排行榜
挑战
比赛围绕两个关键任务展开 - 语义分割和单目深度感知。这两个任务在模型架构方面相似,但在足够不同的地方需要特别注意。由于时间限制和我对当前计算机视觉状态的陌生,我决定专注于深度估计。
简而言之,深度估计涉及测量相机与场景中物体之间的距离。对于无人机而言,这是一项关键的感知任务。使用两个立体相机可以通过立体视觉方法完成这项任务。然而,挑战在于开发一个能够利用单个相机和单个图像的信息来预测每个像素深度的模型。
数据集
数据集包括由我们无人机上的一个下视相机在特定时间戳捕获的一系列飞行帧。这些图像是在特殊的数据收集操作期间收集的,而不是在客户交付操作期间。

提供了图片文件夹的说明性截图,其中每个文件名分为两部分:飞行ID(彩色方块)和图片时间戳
数据集包括412个飞行,共计2056帧(每个飞行近似五帧,不同的地面以上高度),所有帧的完整语义分割注释以及深度估计。组织者将数据集分为训练、验证和测试(公共/私有)集。尽管没有明确说明这种划分背后的逻辑,但可能使用了飞行ID进行划分。
这些数据集包括鸟瞰图灰度图像,拍摄距离地面以上5米至25米之间(AGL)。用于语义分割任务的注释是在19个不同类别中全标记的图像。用于单目深度估计任务的注释是使用几何立体深度算法计算的。
深度注释包含相对深度图,这意味着单凭这些图就无法确定绝对深度值(即以米为单位)。它们被编码为uint16图像,但必须转换为表示深度的浮点值。无效值表示为零。

这是一个单个飞行的示例。顶行显示输入图像,底行呈现相应的目标
评估指标
比赛评价指标是论文“从单个图像中预测深度图的多尺度深度网络”(第3.2节)提出的标度不变错误。作者观察到仅仅识别场景的平均尺度就占总RMSE错误的相当大一部分。他们引入了SI错误,该错误考虑了场景的全局尺度。该指标对场景中点之间的关系非常敏感,而不考虑绝对全局尺度。
对于比赛,该指标对每张图片进行单独计算,然后使用均值进行聚合。

我在训练模型时实现了这个逻辑。
def si_log(prediction, target):
bs = prediction.shape[0]
prediction = torch.reshape(prediction, (bs, -1))
target = torch.reshape(target, (bs, -1))
mask = target > 0 # 0=missing target
num_vals = mask.sum(dim=1)
log_diff = torch.zeros_like(prediction)
log_diff[mask] = torch.log(prediction[mask]) - torch.log(target[mask])
si_log_unscaled = torch.sum(log_diff**2, dim=1) / num_vals - (torch.sum(log_diff, dim=1)**2) / (num_vals**2)
si_log_score = torch.sqrt(si_log_unscaled) * 100
si_log_score = torch.mean(si_log_score)
return si_log_score验证策略
在机器学习竞赛中,有效的验证对于可靠地估计模型性能而不进行正式提交是至关重要的。就像在现实世界的机器学习应用中一样,训练-验证拆分的设计理想情况下应该模仿训练-测试拆分(由竞赛组织者或在现实世界的情况下由进程的性质设置)。
在这个比赛中,每个飞行由五张不同时间戳的图像表示。我的初始策略是通过确保来自同一飞行的不同时间戳不同时出现在训练集和验证集中,防止任何泄漏。为此,我使用了基于飞行ID的KFold拆分,将所有飞行ID分为五个折叠。这确保了特定飞行ID的图像只出现在训练集或验证集中,而不会同时出现在两者中。
然而,这种方法并没有产生令人满意的结果,导致评分被高估。这种差异背后的确切原因并不是完全清楚的,这促使我重新评估我的验证策略。
我决定采用由竞赛组织者提供的用于微调模型超参数并评估其性能的训练/验证拆分。KFold拆分策略被保留,但被重新用于训练五个不同的模型,目的是稍后混合它们的输出。这种双管齐下的方法使我能够在可靠性能估计和最终模型的稳健性之间取得平衡。
图像预处理
预处理阶段涉及将图像加载到内存并将其调整大小为62 * patch_size乘以37 * patch_size的尺寸,其中DinoV2的patch大小为14。选择62和37这两个数字是为了保持图像的原始纵横比(2200/1550接近62/37)。调整大小使用cv2.resize函数进行,对图像使用cv2.INTER_CUBIC,对深度掩膜使用cv2.INTER_NEAREST。
调整大小后,使用预先计算的均值和标准差值对图像进行标准化。这些值是针对数据集中的每个图像计算的,然后进行平均。
鉴于输入图像是单通道的,而DinoV2使用三个通道,我将相同的图像复制三次,以模仿三个通道。对于训练数据,我加入了一些基本的增强,而验证图像则保持原样。
self.aug_transform = A.Compose(
[
A.OneOf(
[
A.HorizontalFlip(),
A.VerticalFlip(),
],
p=1.0,
),
],
p=0.5,
)然后,处理过的图像通过模型。输出被调整回处理图像的尺寸,使用torch.nn.functional.interpolate函数进行插值处理后,通过比较调整大小的深度掩膜与插值过程的输出来计算损失。
在推断期间,插值是从模型输出到图像的原始大小进行的。
使用裁剪图像与调整大小图像进行训练
在这个比赛中,输入图像的尺寸约为2200*1500。鉴于这种高分辨率,直接将完整图像馈送到网络中是不可行的,尤其是对于具有二次内存复杂性的视觉变换器骨干。例如,在完整图像上进行一次前向传递消耗了超过40GB的内存。
我研究的大多数深度估计论文都建议使用图像的裁剪段进行模型训练,另一种方法是调整整个图像的大小。我的初始策略是在图像的裁剪段上训练模型,然后使用CPU对完整图像执行推断,或者使用测试时间增强(TTA)。TTA的一种方法是使用滑动窗口在图像的不同裁剪段上生成预测,最终预测是所有单个预测的平均值。

测试时间增强(TTA)涉及创建原始图像的修改版本,并使用模型对其进行处理。然后,将得到的预测汇总为单个通常更准确的预测。
在这个比赛中,使用裁剪图像进行训练似乎有两个潜在的优势:
由于所有图像的大小不相同,裁剪将有助于保持原始纵横比,避免由调整大小引起的扭曲。
使用裁剪图像进行训练有助于更容易进行数据增强,可能减少过拟合。
然而,与期望相反,在这个比赛中使用裁剪图像并没有产生令人满意的结果。我的分析表明,这可能是由于在裁剪时丢失了有价值的上下文信息。例如,考虑一幅带有汽车和树的图像(图像A)。当这个图像被调整大小(图像B)时,模型仍然保留了树的可见性,这对于汽车的深度估计可能是至关重要的。然而,如果树被裁剪掉(图像C),这个有价值的上下文线索就丢失了,可能会对模型的性能产生负面影响。

模型架构
我的最终解决方案结合了两个预训练模型,然后在我的数据集上进行了微调。我使用DinoV2模型作为骨干,并使用MIM模型的头部(舍弃了MIM的SwinBaseV2骨干)。以下考虑因素启发了这种方法:
MIM架构对我表现良好。在比赛期间,DinoV2论文发布了以及其权重。鉴于作者声称具有最先进性能,我决定将其纳入我的流程。
虽然DinoV2的作者确实测试了他们的模型进行深度估计任务,但他们只发布了骨干的权重,而没有发布任务本身的权重。他们建议使用深度估计工具包(https://github.com/facebookresearch/dinov2/issues/46),但我在安装过程中遇到了库版本不一致的问题。此外,该工具包缺乏预训练权重,我认为从头开始训练头部并不是最有效的方法。
因此,我选择了合并两个模型的最佳部分。我使用了包含300M参数的DinoV2大型模型作为骨干,以及MIM Base头部,其中包括一个额外的解码器块并且消除了线性放大层。
我还尝试过DinoV2 G模型(1100M参数)和MIM的不同版本(large/base)。嵌入大小为:
DinoV2输出大小:
大(L) - 1024
大(G) - 1536
MIM(SwinBaseV2)头部输入大小:
基础 - 1024
大 - 1536
我测试了各种组合(L+Base,L+Large等)。如果嵌入大小不匹配,我包含了一个1x1卷积来调整Dino输出的大小。最好的结果是使用Dino大型和MIM基础模型获得的。

举例说明,以下是训练预测的示例:左图是输入,中间图表示深度目标,右图显示模型的预测。预测中的显著方块伪影是由于ViT中的补丁造成的
冻结骨干,微调头部
在数据集相对较小的情况下,微调骨干可能不会有益,因为它可能导致过拟合。因此,在微调过程中通常会冻结骨干,仅微调或从头开始训练头部。
如果骨干被冻结,其输出将保持不变。骨干占据模型总参数的相当大的部分。例如,我使用的DinoV2骨干的参数在300到1100百万之间,而简单的卷积头部的参数在1到10百万之间。
因此,我们可以为数据集中的每个图像缓存骨干的输出,然后使用这个输出而不是通过骨干传递特征。以下是说明这个想法的简化伪代码:
backbone_model = ...
head_model = ...
# prepare cache - consumes a lot of RAM or disk space
cache = {}
for i, picture in enumerate(dataset):
features = backbone_model(picture)
cache[i] = features
# run model training - much faster
dataloader = DataLoader(dataset)
for batch in dataloader:
x, y_true = batch
y_hat = head_model(x)
loss = clc_loss(y_true, y_hat)
[...]
# run inference
input_pic = ...
features = backbone_model(input_pic)
answer = head_model(features)在我的实验中,我将DinoV2的特征存储在磁盘上,大约占用了100GB的磁盘空间。然而,训练过程加速了大约五倍,使得这种方法变得值得一试。
不幸的是,与骨干未冻结的管道相比,模型的性能较差。因此,我决定不将这种方法纳入我的最终解决方案。
优化器:SGD、Adam、AdamW、Adan和Lion
考虑到微调的任务,我最初假设随机梯度下降(SGD)会产生最佳性能。在比赛期间,我尝试了几种优化器,包括:
SGD — 考虑到手头的任务,我认为纯SGD对微调是一个理想的选择。
Adam — 一个经得住考验的选择,Adam是优化的可靠工作马。
AdamW — 考虑到数据集的有限大小和增强的温和强度,我认为一些额外的正则化可能是有益的。
Lion和Adan — 我还想测试这些现代优化器。
根据我的实验,Adan表现出最佳性能。AdamW和Adan紧随其后。Lion和SGD,不幸的是,在这个特定任务中没有产生良好的结果。
一个担忧是在训练的初始阶段,当Adam的矩估计还没有估计出来时,“步骤”可能过大,这可能对模型的性能产生负面影响。为了在训练过程中促进稳定性,我加入了一个简短的预热:在训练的前200个步骤中,学习率从0线性增加到0.00004。
累积批次
为了训练我的模型,我使用了一个带有40GB内存的A100 GPU。根据模型和分辨率,GPU可以处理1到6个图像的批次。这导致了两个显着的挑战:
小批量大小(1-2)导致学习不稳定。
不同的批次大小(例如,1对比6)导致不可比较的结果。较小的批次意味着每个时期的更新更多,使得时期末的损失成为不可靠的度量。
为了解决这些问题,我转而使用梯度累积。我将有效批次大小设置为12,这是一个相当保守的数字,但在我的情况下证明是有效的。
BS = 4
NUM_ACCUMULATION_STEPS = 12 % BS
loss = criterion(prediction, target)
loss = loss / NUM_ACCUMULATION_STEPS
loss.backward()
if n_steps % NUM_ACCUMULATION_STEPS == 0:
optimizer.step()
optimizer.zero_grad()大梯度
在整个比赛中,我遇到了模型无法有效收敛的情况。我怀疑这个问题可能归因于梯度过大的问题。大梯度意味着可能朝错误的方向迈出较大的步伐。
为了进一步调查,我开发了一个函数来检查每个层中梯度的分布。然而,由于其性能较慢,我只在初始训练运行的每个第n个时期执行了这个检查,为了效率目的,稍后禁用了它。
def plot_gradients(model, output_folder):
gradients = {}
for name, param in model.named_parameters():
if param.grad is not None:
if name not in gradients:
gradients[name] = []
gradients[name] = param.grad.cpu().detach().numpy()
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# Plot and save gradient distribution for each layer
for name, grad in gradients.items():
plt.hist(np.reshape(grad, [-1]))
plt.title(f"{name} Gradient Distribution")
plt.xlabel("Gradient Bins")
plt.ylabel("Frequency")
plt.savefig(os.path.join(output_folder, f"{name}.png"))
plt.clf()当分析网络的最后几层的梯度时,问题显现出来。这些层显示出显著大的梯度,对模型的收敛产生了不利影响。一个具体的例子是输出层的梯度,其中幅度明显较大。
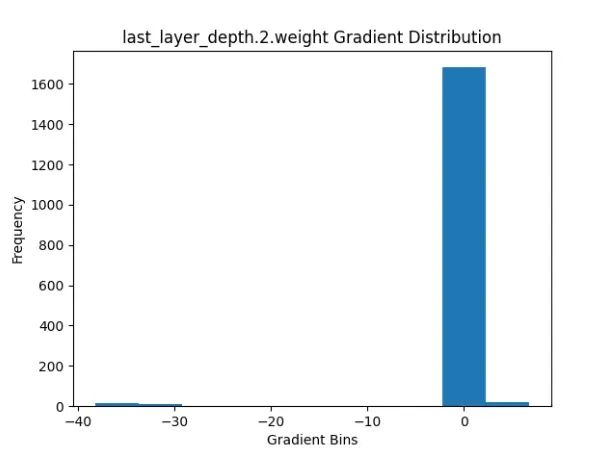
我通过应用一种称为梯度裁剪的技术来解决这个问题。通过实施梯度裁剪,我限制了梯度的幅度,以防止其超过某个阈值。这种方法有助于缓解网络最后几层中梯度过大的问题,并有助于改善收敛性能。
clip_grad_max_norm = 3
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip_grad_max_norm)
optimizer.step()
optimizer.zero_grad()· END ·
HAPPY LIFE
 本文仅供学习交流使用,如有侵权请联系作者删除
本文仅供学习交流使用,如有侵权请联系作者删除