大型语言模型,MirrorBERT — 将模型转换为通用词汇和句子编码器
大型语言模型,MirrorBERT — 将模型转换为通用词汇和句子编码器

一、介绍
BERT 模型在现代 NLP 应用中发挥着基础作用,这已不是什么秘密。尽管它们在下游任务上表现出色,但大多数模型在没有微调的情况下在特定问题上并不是那么完美。从原始预训练模型中嵌入构建通常会导致指标与最先进的结果相去甚远。同时,微调是一个繁重的过程,通常需要至少数千个带注释的数据样本才能使模型更好地理解领域数据。在某些情况下,当我们无法简单地收集已经注释的数据或者它的价格很高时,这方面就会出现问题。
MirrorBERT 旨在克服上述问题。 MirrorBERT 不是标准的微调算法,而是依靠自我监督,在没有任何外部知识的情况下智能地增强初始数据。这种方法使 MirrorBERT 在语义相似性问题上表现出相当的性能。此外,通过使用其创新的对比学习技术,MirrorBERT 可以转换预训练模型,例如 BERT 或 RoBERTa 在不到一分钟的时间内进入通用词汇编码器!
在官方 MirrorBERT 论文的帮助下,我们将深入研究其关键细节,以了解其底层工作原理。所获得的知识将是通用的,因为所讨论的技术也可以用于处理相似任务的其他 NLP 模型。
二、MirrorBERT方法 与 BERT方法
简单来说,MirrorBERT 与 BERT 模型相同,只是在学习过程中引入了几个步骤。让我们逐一讨论一下。
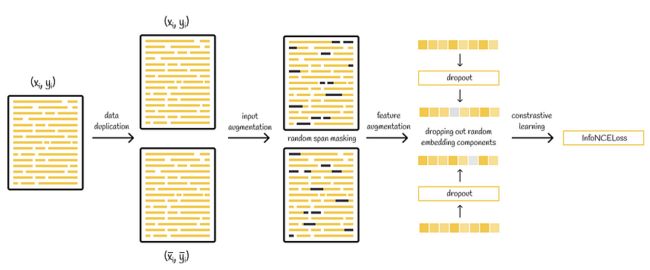
MirrorBERT学习流程
2.1.自我复制
顾名思义,MirrorBERT 只是复制初始数据。
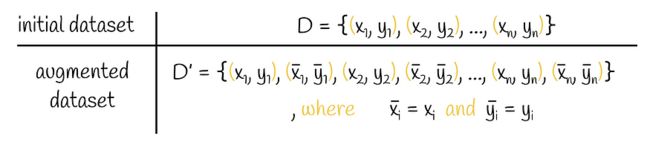
自我复制
然后,使用这些重复的数据进一步构造相同字符串的两种不同的嵌入表示。
2.2. 数据增强
该论文的作者提出了两种稍微修改数据集文本的直观技术。据他们称,在绝大多数情况下,这些文本损坏并不会改变其含义。
2.3.输入增强
给定一对字符串 (xᵢ, x̄ᵢ),算法会随机选择其中一个并应用随机跨度掩码,该掩码由随机的用 [MASK] 标记替换文本中固定长度的子字符串 k。
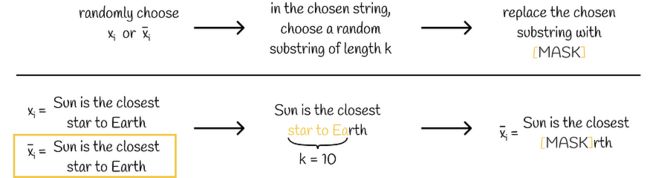
通过随机跨度掩蔽增强输入
2.4.特征增强
随机跨度掩码在句子/短语级别上运行。为了使模型也能够很好地处理单词级任务,需要另一种增强机制来处理较短的文本片段。特征增强通过使用 dropout 来解决这个问题。
退出过程是指关闭给定百分比p某个网络层中的神经元。这可以看作相当于将网络中相应的神经元归零。
该论文的作者建议使用 dropout 进行数据增强。当一对字符串 (xᵢ, x̄ᵢ) 传递到具有 dropout 层的网络时,如果在每次前向传递中 dropout 层始终禁用不同的神经元,则它们的输出表示会略有不同。
使用 dropout 进行功能增强的一个重要方面是,dropout 层已经包含在 BERT / RoBERTa 架构中,这意味着不需要额外的实现!
虽然随机范围掩蔽仅应用于数据集中的每个第二个对象,但 dropout 应用于所有对象。
2.5.对比学习
对比学习是一种机器学习技术,它通过学习数据表示来学习数据表示,使相似的对象在嵌入空间中彼此靠近,而不相似的对象彼此远离。
对比学习实现的方法之一是使用对比损失函数。为 MirrorBERT 选择的是 InfoNCELoss。让我们了解它是如何工作的。
信息NCE损失
乍一看,InfoNCELoss 的公式可能看起来很吓人,所以让我们逐步逐步了解它。
- 两个向量之间的余弦相似度衡量它们彼此对齐的程度,取值范围为 -1 到 1,值越大表示相似度越高。
![]()
两个向量之间的余弦相似度
2.为了更好地理解接下来的步骤,有必要注意InfoNCELoss使用softmax变换,温度参数T控制输出softmax分布的平滑度。这就是为什么相似度除以 T。
有关 softmax 温度的更多信息,请参阅本文对其进行更详细的解释。
![]()
余弦相似度除以温度
3. 与标准 softmax 公式一样,预测(相似度)随后转换为指数形式。

余弦相似度的指数
4。在普通的 softmax 公式中,分子包含类别概率的指数,而分母是所有分布概率的指数和。在与 InfoNCELoss 类似的情况下,公式类似地遵循以下逻辑:
- 分子包含两个稍作修改的相同字符串 (xᵢ, x̄ᵢ) 的指数相似度,可以将其视为正例。< /span>
- 分母由 xᵢ 与所有其他数据集字符串 xⱼ 之间的指数相似度之和组成,可以将其视为一组所有反例 .
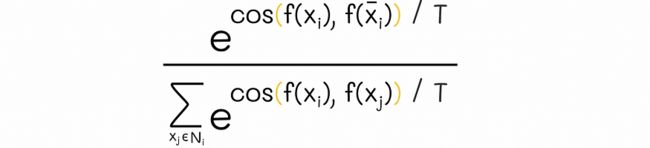
余弦相似度的 Softmax 公式。 Nᵢ 表示除 xᵢ 和 x̄ᵢ 之外的所有数据集字符串。
5. 在理想情况下,我们希望相同字符串 (xᵢ, x̄ᵢ) 之间的相似度较高,而 xᵢ 与其他字符串 xⱼ 的相似度较低。如果为真,则上式中的分子将增加,而分母将减少,使整个表达式变大。
损失函数的作用相反:在理想情况下,它们取较小的值,而在更糟糕的情况下,它们会严重惩罚模型。为了使上面的公式符合这个损失原则,让我们在整个表达式之前添加负对数。

softmax 相似度的负对数。该表达式可以被视为单个字符串 xᵢ 的损失值。
6. 上一步中的表达式已经对应于单个字符串 xᵢ 的损失值。由于数据集由许多字符串组成,因此我们需要考虑所有这些字符串。为此,让我们总结所有字符串的表达式。

信息NCE损失
得到的公式正是InfoNCELoss!
InfoNCELoss 尝试将相似的对象彼此靠近分组,同时将嵌入空间中不相似的对象推开。
SBERT 中使用的三元组损失SBERT是对比学习损失的另一个示例。
三、培训资源
关于 MirrorBERT 的一个令人惊讶的事实是它不需要大量数据进行微调。此外,这些数据不必是外部的,因为整个训练过程是自我监督的。
研究人员报告说,为了微调词汇表示,他们只使用每种语言中 10k 个最常见的单词。对于句子级任务,使用 10k 个句子。
3.1 培训详情
MirrorBERT 训练的详细信息如下:
- 在句子级任务中温度设置为T = 0.04,并设置为T = 0.2 在单词级任务中。
- 在随机跨度掩码中,k 设置为 5。
- 丢弃设置为p = 0.1。
- 使用 AdamW 优化器,学习率为2e-5。
- 批量大小设置为 200(或重复的 400)。
- 词汇模型训练 2 个 epoch,句子级模型训练单个 epoch。
- 创建 [CLS] 令牌表示,而不是所有输出令牌表示的均值池。
单个 MirrorBERT 训练周期仅需 10-20 秒。
3.2 评价
作者通过应用镜像微调来评估一组基准的指标。结果报告了三种类型的任务:词汇、句子级和跨语言。在每个模型中,MirrorBERT 都表现出了与其他类似 BERT 的微调模型相当的性能。
结果还表明,10k 到 20k 训练样本之间的范围对于微调来说是最佳的。随着训练样本的增多,模型的性能逐渐下降。
四、结论
镜像微调实际上就像一个魔咒:镜像框架无需使用繁重的微调过程,只需更少的时间,无需使用外部数据,在语义相似性方面与 BERT、SBERT 或 RoBERTa 等其他微调模型相当任务。
因此,MirrorBERT 可以将类似 BERT 的预训练模型转换为高效捕获语言知识的通用编码器。
