机器学习:手撕 cross-entropy 损失函数
本文首次发表于知乎,欢迎关注作者。
1. 前言
cross-entropy loss function 是在机器学习中比较常见的一种损失函数。在不同的深度学习框架中,均有相关的实现。但实现的细节有很多区别。本文尝试理解下 cross-entropy 的原理,以及关于它的一些常见问题。
本文将尝试解释以下内容:
-
如何计算 corss-entropy
-
用 cross-entropy 优化一个分类 model 的动机
-
cross-entropy 与 KL divergence 的区别和关系
-
cross-entropy 与 log loss 的区别和关系
2. cross-entropy 的概念
2.1 事件的信息量和编码事件信息量 bits 数量的理解
在介绍 cross-entropy 之前,先说说一个事件的信息量和编码一个事件 bit 位长度的含义。在信息论中,概率越小的事件,具备的信息量越大;概率越大的事件,具备的信息量越小。如事件 k 发生的概率为 , 那么事件 k 的信息量定义如下:
, 那么事件 k 的信息量定义如下:

为了更直观的理解一个事件的概率和信息量的关系,我们举一个简单的例子:
例1: 比如在一个地区,明天“下雨”和“晴天”的概率各位 0.5,“下雨”和“晴天”的信息量为:

在没看天气预报前,我们不确定明天是“下雨”还是“晴天”。假如天气预报告诉我们明天“下雨”或者“晴天”,那么这个消息为我们带来1 bit 的信息量。
例2 :同理比如这个地区,明天“下雨”概率为 0.75, 明天“晴天”概率为 0.25, “下雨”的信息量为:

“晴天”的信息量为:

当天气预报告诉我们明天“下雨”,为我们带来 0.41 的信息量;若明天“晴天”,则为我们带来 2 bits 的信息量。
当 log 的底数为 2 时,![]() 的单位为 bits;当 log 的底数为 e 时,
的单位为 bits;当 log 的底数为 e 时,![]() 的单位为 nats;为了叙述方便,在没特殊说明的情况下,我们默认 log 的底数为 2。因为信息量
的单位为 nats;为了叙述方便,在没特殊说明的情况下,我们默认 log 的底数为 2。因为信息量![]() 的单位是 bits, 这代表编码传输事件 k 的信息量需要的最少 bits 的数量。在实际的信息传输中,编码一个事件的 bits 位数量可能大于这个事件的信息量,多出的 bits 位为冗余或者错误,不具备更多的信息。
的单位是 bits, 这代表编码传输事件 k 的信息量需要的最少 bits 的数量。在实际的信息传输中,编码一个事件的 bits 位数量可能大于这个事件的信息量,多出的 bits 位为冗余或者错误,不具备更多的信息。
2.2 entropy 的理解
对于一个离散的概率分布来说,每个事件 k 的信息量,都会对应一个 bits 位的数量,entropy 则是概率分布中所有事件的 bits 位数量的期望 (均值),也代表着个事件中的平均信息量。即:entropy 是编码一个概率分布时,用到的 bits 位数量的期望 (均值)。有偏分布的 entropy 要小于均匀分布的 entropy。对于一个概率分布 p,entropy 的概念如下:

比如在例 1 中,听天气预报可以获取的平均信息量:
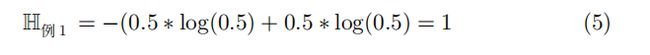
比如在例 2 中,听天气预报可以获取的平均信息量为:
![]()
2.3 cross-entropy 的理解
如果事件 k 对应 2 个不同的概率分布 p 和 q,cross-entropy H(p, q) 的定义如下:
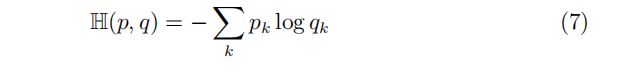
为了更好的理解 cross-entropy 的定义,先定义一个随机变量 ![]() :
:
从概率分布 p 中,采样一个事件 (数据) k, 然后按照概率分布 q 编码事件 k 的信息量,需要的 bit 位长度为 ![]() 。
。
cross-entrpy 则是随机变量 ![]() 的相对于分布 p 的期望,即用分布 q 编码从分布 p 中的采样数据的信息量时的 bits 数量期望。entropy 和 cross-entropy 从定义上看起来很像, 将 entropy 的
的相对于分布 p 的期望,即用分布 q 编码从分布 p 中的采样数据的信息量时的 bits 数量期望。entropy 和 cross-entropy 从定义上看起来很像, 将 entropy 的 ![]() 替换为
替换为 ![]() 便得到 cross-entropy,且容易推导出下面的等式:
便得到 cross-entropy,且容易推导出下面的等式:

类比 H(p) 表示分布 p 提供的平均信息量,也是 p 分布包含的所有事件编码的平均 bits 数量。同理 H(q, p)表示用分布 p 编码从分布 q 的采样数据时,需要的平均 bits 数量。很明显 cross-entropy 不对称,即 H(p, q)!= H(q, p) 。
为了进一步理解 cross-entropy 的概念,我们继续举一个关于编码天气预报的例子:
例3:一个地区的天气有8种类型,如表 1 所示, 天气类型的分布为 p。天气预报将每种天气编码成 3bits 数据进行传输,根据信息量定义,可以通过编码的 bits 位数,推算出对应的编码分布 q。

根据 entropy 的定义:

根据 corss-entropy 的定义:

entropy 表示我们能从天气预报中,平均每天获取 3 个 bits 的信息量。cross-entropy 表示这个编码方式的传输系统,平均每天传输 3bits 的数据。此时传输编码 bits 数与信息量恰好相等,即 H(p) = H(p, q),传输系统编码效率较高,没有冗余 bits 位。但假如是在沙漠地区,天气类型的概率分布 p 发生变化,但编码方式没变,即编码分布 q 没变,如表 2 所示:

对应的 entropy 为 (平均每天获取信息量):

对应的 cross-entropy 为 (传输系统平均每天的传输 bits 位) :

这时候,发现传输系统平均每天传输的 bits 数要大于从天气预报中获得的 bits 数,这时传输系统有冗余,多出来的 bits 数就是冗余 bits 数。
如果我们更换传输系统的编码方式,编码分布也会相应的跟随变化,如表 3 所示:
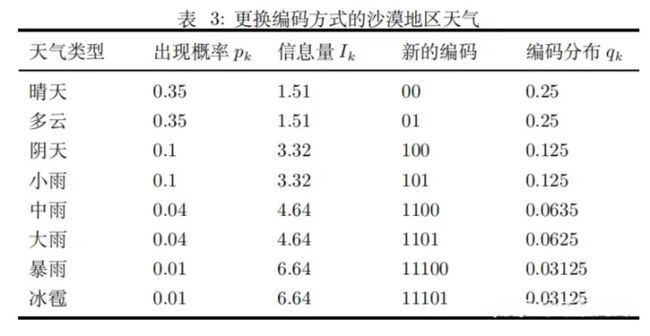
对应的 entropy 没变 (平均每天获取信息量) :
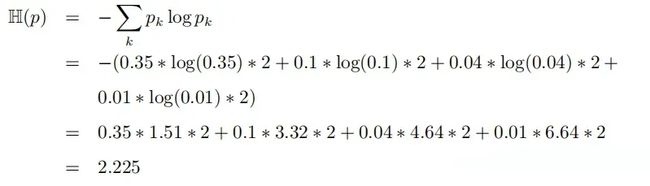
对应的 cross-entropy 为 (传输系统平均每天的传输 bits 位) :

改变天气预报的编码方式后,传输系统平均每天的传输 bits 数量相对与修改前减少,与 entropy 更接近了。冗余的 bits 位数量更少了,传输系统的效率也更高了。
通过例 3 我们可能隐约感觉到,如果编码方式设计的更精巧些,传输系统平均每天的传输 bits 数,会进一步下降,直到 H(p, q) = 2.225 与分布的 p 的熵相等。自然引出一个猜想:∀q ,H(p, q) ≥ H(p)。这个猜想是正确,H(p, q) 和 H(p) 的差是 KL(p||q), 这个我们放到下一节证明。
3. cross-entropy 与 KL 散度
cross-entropy 不是 KL 散度,但 cross-entropy 与 KL 散度有着密切的关系。如果事件 k 对应 2 个不同的概率分布 p 和 q,则 KL 散度 KL(p||q) 的定义如下:

我们对 KL 散度做进一步的推导:
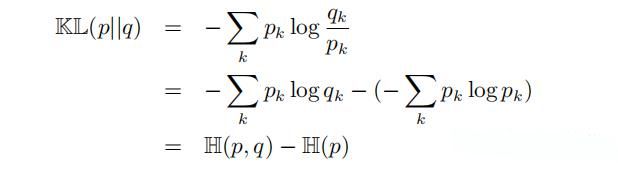
即 cross-entropy 与 entropy 的差为 KL 散度。同理为了更好的理解 KL 散度,我们先定义一个随机变量 ∆ ![]() :
:
*从概率分布 p 中,采样一个事件 (数据)k, 用概率分布 q 编码事件 k 的信息量比用概率分布 p 编码事件的信息量额外多需要的 bits 位长度为 ∆ ![]() = -(
= -( ![]() -
- ![]() ) *
) *
所以 KL(p||q) 可以理解为:随机变量 ∆kbit 相对与分布 p 的期望,即用分布 q 编码从分布 p 中采样数据的信息量时,相对于用分布 p 编码从分布 p 中采样数据的信息量时, 额外需要的 bits 位的期望。KL(p||q) 衡量了分布 p 和 q 之间的差异,因此,KL 散度也叫 Relative Entropy(相对熵)。同 cross-entropy 一样,KL 散度也不是对称的,即 KL(p||q) != KL(q||p)。 KL 散度另外一个关键的定理:

证明。 为了证明这个定理,我们需要使用 Jenson's inequality。对于任意的凸函数,我们有:

其中 ![]() ≥ 0 且
≥ 0 且 ![]() = 1,即期望的函数小于等于函数的期望,如图所示。
= 1,即期望的函数小于等于函数的期望,如图所示。
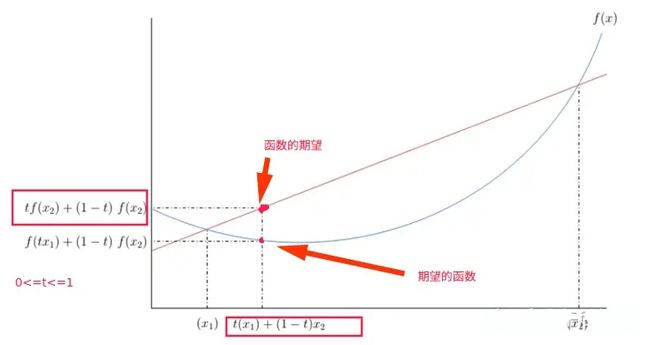
让我们开始证明这个定理,以下证明参考《Machine Learning A Probabilistic Perspective 》p58。
设集合 A = {x : p(x) > 0}:
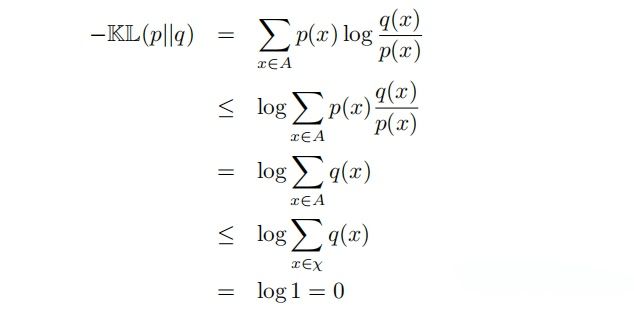
因为函数 log 为凹函数,所以正是 Jenson’s inequality 的反向表达:*期望的函数大约等于函数的期望*, 得到第一行到第二行的变换;因为 p(x) > 0, 所以第二行的分子分母中的 p(x) 可以直接点约掉,得到第三行;因为集合 A 表示分布 p 的所有 x 的集合,集合 χ 表示 q 分布所有 x 的集合,当且仅当集合 A = χ 时,第四行的等号成立;对于集合 χ 中,所有元素的 q(x) 之和为 1, 便得到第五行的等式。所以这也间接的验证我们在上一章提出的猜想:∀q , H(p, q) ≥ H(p)。这为 cross-entropy 和 KL 散度作为损失函数提供保证。
将 cross-entropy 和 KL 散度的关系和区别总结如下:


通过前面的讨论,我们可以感觉到,当 cross-entropy 和 KL 散度作为分类模型的损失函数时,从模型初始的损失值,到模型最优时的损失值,这两种损失函数的减少量是相同的,所以从这个角度讲,cross-entropy 与 KL 散度的作用是相同的。
4. cross-entropy 优化分类模型
cross-entropy 作为损失函数常常被用来优化分类模型。采用 cross-entropy 作为损失函数往往会比 sum-of-square 作为损失函数收敛速度更快,同时泛化性更好。
只有 2 个类别的分类任务,是 binary classification problems, 超过 2 个类别则是 multi-class classification。在 K-分类问题中,对于每一条样本数据,它的 label 一般被编码为 one-hot 向量,它可以看做一个离散的概率分布,共 K 个类别,真实类别概率为 1,其余类别概率为 0。分类模型最后一层如果是 softmax, 分类模型也输出一个离散概率分布,表示样本数据属于各个类别的概率。对于单条样本数据,我们希望分类模型输出的概率分0布与数据的真实 label 分布越接近越好。可以看到 cross-entropy 可以很自然的计算这两个分布的距离。因此 cross-entropy 可以作为分类模型的损失函数。
如果我们把样本数据的 label 分布用 p 表示,将模型给出的样本的预测概率分布用 q 表示。对于一条样本则 cross-entropy 可以通过下式计算:

遍历维度 K 中的每个元素 k。其中样本数据的 label 分布 p,它的 entropy 为 0, 即 H(p) = 0。在前面的叙述中,我们知道:
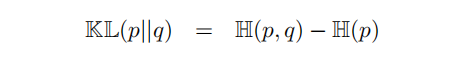
可以得到 KL(p||q) = H(p, q),所以 * 对于 multi-class classification 问题,当分类模型的输出层为 softmax 时, 损失函数为 cross-entropy 与 KL 散度是等价的,效果相同。* 为了更好的理解我们举一个例子:
例 4:我有一个数据样本,它的 label 经过 one-hot 编码后 p =[0, 1, 0, 0, 0, 0], 分类模型经过 softmax 后输出概率分布 q = [0.1, 0.5, 0.1, 0.1, 0.1, 0.1],则此时 cross-entropy 和 KL 散度分别为:
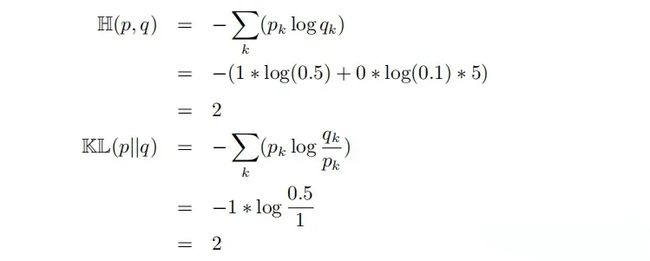
我们可以看到,在这种情况下 cross-entropy 和 KL 散度的值相等。当模型通过多次迭代后,性能有所改善,对于同一个样本,输出概率分布 q = [0.05, 0.8, 0.05, 0.05, 0.05, 0.05],此时 cross-entropy 和 KL 散度分别为:

当模型预测的分布 q 与 label 分布 p 接近时,cross-entropy 和 KL 散度均会减少。
总结上述内容:对于 label 用 one-hot 编码的多分类问题。因为 one-hot 的 entropy 为 0,所以此时损失函数 cross-entropy 与 KL 散度等价。
5. cross-entropy 与 log loss 的关系
这里 log loss 是指 NLLLoss(negative log likelihood loss)。cross-entropy 与 log loss 是不同的,但他们作为多分类模型的损失函数时,计算的量是相互等价的,即 cross-entropy 与 log loss 可以互换。很多在概率框架下的模型,采用 MLE( maximum likelihood estimation) 的方法进行优化。这种方法是找到一组最优的模型参数,使观测到的数据出现的概率最大。在实际使用中,likelihood 容易产生下溢,所以对 likelihood 取了 log 。而且在一般的使用中,大家习惯最小化一个优化目标,于是加了负号,由最大化优化目标变为最小化优化目标。经过这些变换之后便得到 NLLLoss, 对于一个二值分类问题具体的表达式:

其中 ![]() =1 为示性函数。可以看到在分类问题下,cross-entropy 与 NLLLoss 是等价的。在 multi-class classification 中,这个关系也成立。因为多分类模型中,只有真实 label 为1, 其余 label 为 0,cross-entropy 会退化为 log loss:
=1 为示性函数。可以看到在分类问题下,cross-entropy 与 NLLLoss 是等价的。在 multi-class classification 中,这个关系也成立。因为多分类模型中,只有真实 label 为1, 其余 label 为 0,cross-entropy 会退化为 log loss:

其中 N 为样本个数,K 为类别总数。对于多分类问题,因为 cross-entropy 退化为 log loss, 所以在 pytorch 中,我们可以看到 nn.CrossEntropyLoss 和 nn.NLLLoss 的实现很像。
6. 结语
本文主要目的是为了理解认识 cross-entropy 作为损失函数的性质和含义。作者能力有限,可能存在很多地方,叙述不清或者不准确。欢迎留言讨论。
参考文献
[1] Jason Brownlee: A Gentle Introduction to Cross-Entropy for MachineLearning,
A Gentle Introduction to Cross-Entropy for Machine Learning - Machine Learning Masterymachine-learning/
[2] Aurélien Géron: A Short Introduction to Entropy, Cross-Entropy and KL-Divergence,
https://www.youtube.com/watch?v=ErfnhcEV1O8
[3] Murphy: Machine Learning A Probabilistic Perspective
团队介绍
「三翼鸟数字化技术平台-智慧设计团队」依托实体建模技术与人工智能技术打造面向家电的智能设计平台,为海尔特色的成套家电和智慧场景提供可视可触的虚拟现实体验。智慧设计团队提供全链路设计,涵盖概念化设计、深化设计、智能仿真、快速报价、模拟施工、快速出图、交易交付、设备检修等关键环节,为全屋家电设计提供一站式解决方案。