4--贝叶斯 聚类算法
本周学习内容:
- 学习贝叶斯网相关知识
- 学习集成学习部分内容
- 学习聚类任务及其相关算法
1 贝叶斯网
半朴素贝叶斯中规定每一个特征可以依赖于另外一个特征,贝叶斯网络在半朴素贝叶斯的基础上更进一步,认为每个特征都可以依赖于另外多个特征。贝叶斯网络实际上是一个有向无环图,图中包含贝叶斯网络的结构和参数,带有方向的边从父特征出发,指向子特征,代表子特征依赖于父特征。
贝叶斯网中三个变量之间的典型依赖关系如图1所示:

图1 贝叶斯网中的典型依赖关系
对于同父结构,当知道 x1 的信息时,x3 和 x4 独立。对于 V 型结构,当子特征取值未知时,父特征互相独立,在上图中,即当 x4 未知时,x1 和 x2 独立。对于顺序结构,在知道x的信息的情况下,y和z独立。
对于贝叶斯网络,同样也是要让模型自行学习到最优结构,所以构建了一个评分函数来为每一种结构打分,当评分最小时就是最优的模型。评分函数如图2所示,第一项考虑的是整个贝叶斯网络中用于编码参数的编码位的多少,第二项是贝叶斯网络的对数似然。

图2 贝叶斯评分函数
最小化评分函数时,编码位数量越少越好。这样在预测时不需要进行大量的计算,并且简单的模型避免了过拟合,泛化性能更好。在贝叶斯网络中,对数似然的大小直接取决于贝叶斯网络的结构。为了最小化评分函数,只需对网络结构进行搜索得到最优贝叶斯网络。但该方法是一个NP难问题,一般通过贪心法和限定网络结构来求近似解。
贝叶斯网络训练好后,可以通过已知变量观测值来推测待查询变量。当网络的结点较多,连接较为稠密时,要根据联合概率分布精确推断后验概率是 NP 难问题。因此需要借助近似推断,通过降低精度要求,在有限的时间内求得近似解,一般使用吉布斯采样来完成。
1.2实现拉普拉斯修正的朴素贝叶斯分类器
主要函数probability2 (dataset,classlable,test_data,p,l abelCount)的代码如图3所示:
def probability2(dataset,classlable,test_data,p,labelCount):#计算每个属性的条件概率
'''
:param dataset:测试数据
:param classlable:类的信息 用来作条件概率的分母
:param test_data:测试信息
:param p : 基于训练集的先验概率
:param labelCount:特征字典
:return: 各属性的条件概率
'''
p1 = {}
all_p = {}
for value in classlable:#一类一类的计算条件概率
print("当前类别:",value)
all_p[value] = 1
j = 0
temp_data = [[0] * 6] * classlable[value]
for i in range(len(dataset)):#得到当前类别的所有数据
if dataset[i,-1] == value:
temp_data[j] = dataset[i]#将训练数据按类进行划分 方便后续在该数据上计算分子
print("temp_data[j]:", temp_data[j])
j += 1
temp_data = np.array(temp_data)
print("当前类别的数据:",temp_data)
j = 0
for feather in test_data:#取测试数据里的每一个特征值 查找该类上有该特征的个数
print("当前特征为:", feather)
a = list(temp_data[:, j]).count(feather)#分子
print("分子为:",a)
p1[feather] = (a+1)/(len(temp_data)+labelCount[j])#加入拉普拉斯平滑处理
j += 1
all_p[value] = all_p[value]*p1[feather]#连乘操作
all_p[value] = p[value]*all_p[value]#公式 乘上每个类的P(c)
print("当前类别的可能性:",all_p[value])
fina_dict = sorted(all_p.items(), key=lambda x: x[1])#进行排序 选择最后一个也就是可能性最大的类别来进行输出
print("预测结果为:",fina_dict[-1][0])
print("可能性为:",fina_dict[-1][1])图3 probability2函数
该分类器以西瓜数据集2.0为训练集,并对['青绿', '蜷缩','浊响', '清晰','凹陷', '硬滑','0.697','0.460']该数据进行测试,得到结果如图4所示:
图4 预测结果
3 集成学习
结合一组个体学习器的结果,可以获得比单一学习器优越的泛化性。一般分为两大类,一类是个体学习器间存在强依赖关系,需要串行生成的序列化方法,比如Adaboost。另一类是个体学习器间不存在强依赖可以同时生成的并行化方法,如Bagging和随机森林。
3.1 Adaboost
该算法在首先根据训练集的大小初始化样本权值(一般是其满足均匀分布),在后续操作中来改变迭代后样本的权值。被错误分类的样本权值会增大,反之权值相应减小,即被错分的训练样本集将获得一个更高的权重。这就使得在下一轮训练中更注重于上一轮分类错误的样本,一直重复直到达到规定的迭代次数。
在以下数据集上运行AdaBoost算法,其中1表示好瓜,0表示坏瓜

在不同规模的集成学习器上的决策边界如图5所示,基学习器选择深度为1的决策树,其中名为Tree的决策边界是决策树的分类边界。可以看出集成学习器生成的决策边界比单一学习器生成的决策边界表现效果更好。
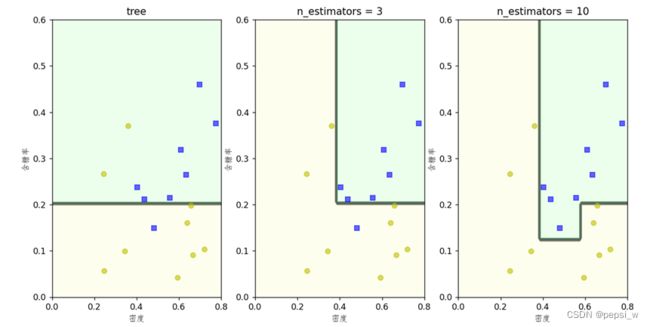
图5 在西瓜数据集上运行AdaBoost算法的决策边界
3.2 Bagging
bagging是投票式算法,首先使用Bootstrap(自助采样法,即对样例抽取是有放回的)产生不同的训练数据集,然后再分别基于这些训练数据集得到多个基础分类器,最后通过对基础分类器的分类结果进行组合得到一个相对更优的预测模型。
该算法输入为样本集D={(x1,y1),(x2,y2),,,,(xm,ym)},弱分类器迭代次数为T,输出为强分类器f(x)。对于t=1,2,,,T,对训练集进行第t次随机采样,共采样m次,得到包含了m个样本的采样集Dt,用采样机Dt训练第t个弱学习器Gt(x)。如果是分类算法预测,则T个弱学习器投出最多票数的类别为最终类别,如是回归算法预测,T个弱学习器得到的结果进行算术平均后的值作为最终输出。
选择随机生成的数据集,并使用train_test_split模块来划分测试集和训练集。具体代码如下:

这里Bagging选择决策树作为基学习器,并设置500个基学习器来对数据进行处理。作为对比,也画出了单一决策树在同一数据上生成的决策平面,如图6所示。可以看出决策树存在过拟合的情况,而集成学习器过拟合风险就相应小一些。
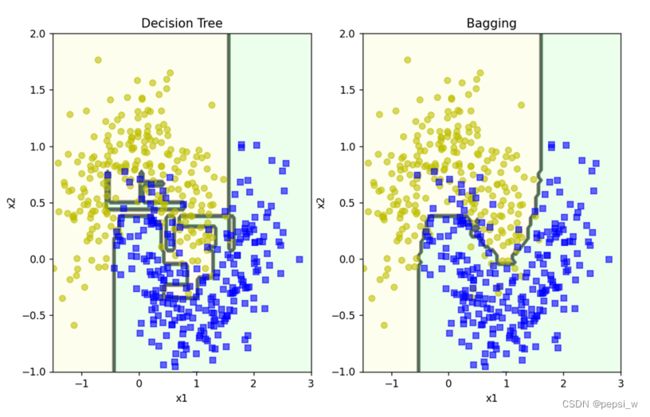
图6 决策树与Bagging集成学习器在数据集上得到的决策平面
3.3 随机森林
由多个决策树组成,每个决策树并不相同。在构建决策树时,从训练数据中有放回的随机选取一部分样本(依旧使用自助采样法),并且不会使用数据的全部特征,而是随机选取部分特征进行训练。得到的每棵决策树使用的样本和特征都不相同,训练出的结果也不相同。因为开始训练前,无法知道哪部分数据存在异常样本,也无法知道哪些特征最能决定分类结果,随机过程降低了两个影响因素对于分类结果的影响。
4 聚类
4.1 聚类任务
聚类( clustering )是一种典型的“无监督学习”,是把物理对象或抽象对象的集合分组为由彼此类似的对象组成的多个类的分析过程。即按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。使得聚类后同一类的数据尽可能聚集到一起,不同类的数据尽量分离。一般用于寻找数据内在的分布结构或作为分类任务的前去过程。
4.2 K均值算法
该算法步骤如下:
1、在数据集里随机选K个点(对数据进行K个类别的聚类),当作每个类别的中心点。
2、通过距离度量,把数据集里的所有点根据距离远近分配给这K个中心点(即数据分给最近的一个中心点),组成一个类别,即获得K个类别。
3、在获得的K个类别里进行均值计算,算出新的中心点(该中心点使相应聚类里的所有点到这个点的距离和最小),把得到的中心点替换各个类别的K点值。
4、判断新获得的一组K值是否和上一次的一组K值相同,如果不同则跳到第2步,如果相同则完成了聚类过程。K均值算法的伪代码如图7所示:
图7 k均值算法
以书中西瓜数据集4.0为数据集,假定这里聚类簇数k=3,使用K均值算法来对其进行划分。主函数代码如下:
if __name__=='__main__':
data, lables = dataset()
sample = {}
#list = random.sample(range(0,len(data)),3)#随机选择三个整数 用来当作初始均值向量 这里为了看是否正确 复习书上的例子
list = [5,11,23]
for i in range(3):
sample[i] = data[list[i]]#将随机选择的数据 用来当作初始均值向量
print("sample",sample)
flag = 0
while flag != 3 :#直到所有均值向量不再更新时 退出循环
print("这是循环!")
flag = 0
sorted_data = sort_data(data,sample)#先对当前所有数据根据向量均值进行分簇
plot(sorted_data,sample)#每一轮划分好后 可视化展示
for i in range(len(sample)):#一类一类的进行更新均值
new_mean = updata_mean(np.array(sorted_data[i]),sample[i])
if ((new_mean==sample[i]).all()):#当前均值保持不变 标志位+1
flag += 1
else:#当前均值更新为新的均值
sample[i] = new_mean
for k in range(len(sorted_data)):#查看每一簇有多少数据
print(len(sorted_data[k]))
各轮运行结果如图8所示(当改变初始均值向量时最终聚类结果也会相应改变,即初始均值向量的选取对最终聚类结果有影响):
图8 k均值算法各轮迭代后的结果
下周计划:
- 学习其他几种聚类算法,如学习向量量化算法、高斯混合聚类等。
- 学习降维与度量学习部分的内容。
附:
朴素贝叶斯分类器(可以处理连续值)
import math
from math import log
import numpy as np
#实现了连续值的处理
def creatDataSet():
dataset = [
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460, '是'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.774, 0.376, '是'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.634, 0.264, '是'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.608, 0.318, '是'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.556, 0.215, '是'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.403, 0.237, '是'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', 0.481, 0.149, '是'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', 0.437, 0.211, '是'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', 0.666, 0.091, '否'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', 0.243, 0.267, '否'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', 0.245, 0.057, '否'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', 0.343, 0.099, '否'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', 0.639, 0.161, '否'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', 0.657, 0.198, '否'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.360, 0.370, '否'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', 0.593, 0.042, '否'],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', 0.719, 0.103, '否'],
]
dataset = np.array(dataset)
labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感','密度','含糖率']
flag =[True,True,True,True,True,True,False,False]
labelCount1 = {}
labelCount ={}
for i in range(len(labels)):#获取每个特征属性的可能取值 形成特征字典
labelCount1[labels[i]] = list(set(dataset[:,i]))
labelCount[i] = len(labelCount1[labels[i]])
#print("lableCount: ", labelCount)
return dataset, labels, labelCount,flag
def bayes(test):
#先计算类先验概率
return 0
def probability1(dataset):#先计算类先验概率 并按类对数据进行划分
classlable = {}
for vote in dataset[:,-1]:
if vote not in classlable.keys():
classlable[vote] = 0
classlable[vote] += 1
p = {}
for value in classlable:
p[value] = (classlable[value]+1)/(len(dataset)+len(classlable)) #计算每一类的先验概率 加入拉普拉斯修正
return p,classlable
def probability2(dataset,classlable,test_data,p,labelCount,flag):#计算每个属性的条件概率
'''
:param dataset:测试数据
:param classlable:类的信息 用来作条件概率的分母
:param test_data:测试信息
:param p : 基于训练集的先验概率
:param labelCount:特征字典
:return: 各属性的条件概率
'''
p1 = {}
all_p = {}
for value in classlable:#一类一类的计算条件概率
print("当前类别:",value)
all_p[value] = 1
j = 0
temp_data = [[0] * (len(dataset[0])-1)] * classlable[value]
for i in range(len(dataset)):#得到当前类别的所有数据
if dataset[i,-1] == value:
temp_data[j] = dataset[i]#将训练数据按类进行划分 方便后续在该数据上计算分子
j += 1
temp_data = np.array(temp_data)
#print("当前类别的数据:",temp_data)
j = 0
for feather in test_data:#取测试数据里的每一个特征值 查找该类上有该特征的个数
#print(feather)
if flag[j]:#判断为字符型
#print("当前特征为:", feather)
a = list(temp_data[:, j]).count(feather)#分子
#print("分子为:",a)
#p1[feather] = (a) / (len(temp_data))
p1[feather] = (a+1)/(len(temp_data)+labelCount[j])#加入拉普拉斯平滑处理
#print(p1[feather])
j += 1
all_p[value] = all_p[value]*p1[feather]#连乘操作
else:#当前为连续值
#print("当前为连续值")
#print("当前特征为:", feather)
a = list(temp_data[:, j]).count(feather) # 分子
#print("分子为:", a)
int_list = [float(x) for x in temp_data[:,j]]#因为存放在temp_data中的是字符串形式 这里是改为float类型
#print('int_list', int_list)
var =np.std(int_list, ddof=1)# 求方差
#print("方差:",var)
mean = np.mean(int_list) # 求均值
#print("均值:",mean)
p1[feather] = (1/(pow(2*math.pi,1/2)*var))*math.exp(-pow((float(feather)-mean),2)/(2*pow(var,2)))
#print(p1[feather])
j += 1
all_p[value] = all_p[value] * p1[feather] # 连乘操作
all_p[value] = p[value]*all_p[value]#公式 乘上每个类的P(c)
print("当前类别的可能性:",all_p[value])
fina_dict = sorted(all_p.items(), key=lambda x: x[1])#进行排序 选择最后一个也就是可能性最大的类别来进行输出
print("预测结果为:",fina_dict[-1][0])
print("可能性为:",fina_dict[-1][1])
if __name__ == '__main__':
dataset, labels, labelCount,flag = creatDataSet()
test_data = ['青绿', '蜷缩','浊响', '清晰','凹陷', '硬滑','0.697','0.460']
p,classlable= probability1(dataset)
#print(p)
probability2(dataset,classlable,test_data,p,labelCount,flag)
AdaBoost
import numpy as np
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from graphviz import Digraph
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
def DataSet():
dataset = [
[0.697,0.460,1],
[0.774,0.376,1],
[0.634,0.264,1],
[0.608,0.318,1],
[0.556,0.215,1],
[0.403,0.237,1],
[0.481,0.149,1],
[0.437,0.211,1],
[0.666,0.091,0],
[0.243,0.267,0],
[0.245,0.057,0],
[0.343,0.099,0],
[0.639,0.161,0],
[0.657,0.198,0],
[0.360,0.370,0],
[0.593,0.042,0],
[0.719,0.103,0]
]
dataset = np.array(dataset)
lables = ['密度','含糖率']
return dataset,lables
from matplotlib.colors import ListedColormap
def plot_decision_boundary(clf,X,y,lables,axes=[0,0.8,0,0.6],alpha = 0.5,contour = True):
x1s = np.linspace(axes[0],axes[1],100)
x2s = np.linspace(axes[2],axes[3],100)
x1,x2 = np.meshgrid(x1s,x2s)
X_new = np.c_[x1.ravel(),x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
print(type(clf.predict(X_new)))
print(y_pred)
plt.contourf(x1,x2,y_pred,cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0']),alpha = 0.2)
if contour:
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1,x2,y_pred,cmap = custom_cmap2,alpha = 0.8)
plt.plot(X[:, 0][y == 0], X[:, 1][y == 0], 'yo', alpha=0.6)
plt.plot(X[:, 0][y == 1], X[:, 1][y == 1], 'bs', alpha=0.6)
plt.axis(axes)
plt.xlabel(lables[0],fontname = "Fangsong")
plt.ylabel(lables[1],fontname = "Fangsong")
if __name__ == '__main__':
dataset, lables = DataSet()
X_train = np.delete(dataset, -1, axis=1)
y_train = dataset[:,-1]
tree_clf = DecisionTreeClassifier(max_depth=1)
tree_clf.fit(X_train,y_train)
ada1_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1),
n_estimators = 3,
learning_rate= 0.5,
random_state = 42
)
ada2_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1),
n_estimators=10,
learning_rate=0.5,
random_state=42
)
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(10, 6))
plt.sca(axes[0])
ada1_clf.fit(X_train, y_train) # 第一个图片
plot_decision_boundary(tree_clf, X_train, y_train, lables)
plt.title("tree")
plt.sca(axes[1])
ada1_clf.fit(X_train,y_train)# 第一个图片
plot_decision_boundary(ada1_clf, X_train, y_train, lables)
plt.title("n_estimators = 3")
plt.sca(axes[2]) # 第2个图片
ada2_clf.fit(X_train, y_train)
plot_decision_boundary(ada2_clf,X_train,y_train,lables)
plt.title("n_estimators = 10")
plt.show()
基学习器为决策树的bagging
import numpy as np
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
#得到数据 进行展示
X,y = make_moons(n_samples = 500 , noise = 0.3, random_state= 42)
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=42)
bag_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,#500个基学习器
max_samples = 100,#最大样本数量
bootstrap= True,#是否有放回的抽样
n_jobs= -1,#-1表示全部的cpu来进行计算
random_state= 42 #随机数种子
)
bag_clf.fit(X_train,y_train)
y1_pred = bag_clf.predict(X_test)
print("Bagging:",accuracy_score(y_test,y1_pred))
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train,y_train)
y2_pred = tree_clf.predict(X_test)
print("Decision Tree:",accuracy_score(y_test,y2_pred))
from matplotlib.colors import ListedColormap
def plot_decision_boundary(clf,X,y,axes=[-1.5,3,-1,2],alpha = 0.5,contour = True):
x1s = np.linspace(axes[0],axes[1],100)
x2s = np.linspace(axes[2],axes[3],100)
x1,x2 = np.meshgrid(x1s,x2s)
X_new = np.c_[x1.ravel(),x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
plt.contourf(x1,x2,y_pred,cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0']),alpha = 0.2)
if contour:
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1,x2,y_pred,cmap = custom_cmap2,alpha = 0.8)
plt.plot(X[:, 0][y == 0], X[:, 1][y == 0], 'yo', alpha=0.6)
plt.plot(X[:, 0][y == 1], X[:, 1][y == 1], 'bs', alpha=0.6)
plt.axis(axes)
plt.xlabel('x1')
plt.ylabel('x2')
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(10,6))#设定nn排列方式,这里设置的是22,nrows行,ncols列,figsize设定窗口大小,使用的时候可以按照需求设定图片排版格式
plt.sca(axes[0])#第一个图片
plot_decision_boundary(tree_clf,X,y)
plt.title("Decision Tree")
plt.sca(axes[1])#第二个图片
plot_decision_boundary(bag_clf,X,y)
plt.title("Bagging")
plt.show()
K-means
import random
import math
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
def dataset():
data = [
[0.697, 0.460],[0.774, 0.376],[0.634, 0.264],[0.608, 0.318],[0.556, 0.215],[0.403, 0.237],
[0.481, 0.149],[0.437, 0.211],[0.666, 0.091],[0.243, 0.267],[0.245, 0.057],[0.343, 0.099],
[0.639, 0.161],[0.657, 0.198],[0.360, 0.370],[0.593, 0.042],[0.719, 0.103],[0.359, 0.188],
[0.339, 0.241],[0.282, 0.257],[0.748, 0.232],[0.714, 0.346],[0.483, 0.312],[0.478, 0.437],
[0.525, 0.369],[0.751, 0.489],[0.532, 0.472],[0.473, 0.376],[0.725, 0.445],[0.446, 0.459]
]
data = np.array(data)
lables = ['密度','含糖率']
return data,lables
def distance(data1,data2):
'''
计算两个样本点之间的距离 使用欧氏距离
:param data1: 样本点1
:param data2: 样本点2
:return: 距离
'''
sum = 0
for x in range(len(data1)):
sum += pow(abs(data1[x]-data2[x]),2)
dist = pow(sum,1/2)
return dist
def sort_data(data,sample):
'''
对数据进行分类
:param data: 所有样本数据
:param sample: 均值向量
:return: 当前簇的划分
'''
sorted_data = {}
for i in data:
min = float("inf")#最小值设为无穷大
for k in range(len(sample)):#分为3类 就是要计算到这三类的距离
dist1 = distance(i,sample[k])
if dist1 < min:
min = dist1
min_k = k
sorted_data.setdefault(min_k,[]).append(i)
print("sorted_data",sorted_data)
return sorted_data
def updata_mean(group,old_mean):
'''
用来更新均值向量
:param group: 每一簇的所有数据
:param old_mean: 原来的均值
:return: 新的均值
'''
new_mean = []
for i in range(len(old_mean)):#遍历每一维
sum = 0
for data in group[:,i]:
#print("group[i]:",group[i])
sum += data
new_mean.append(sum/len(group))
return np.array(new_mean)
def plot(data,sample,axes=[0,0.9,0,0.8]):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# matplotlib画图中中文显示会有问题,需要这两行设置默认字体
custom_cmap2 = ListedColormap(['#7d7d58', '#4c4c7f', '#507d50'])
for i in range(len(data)):
#print(np.array(data[i]))
a = np.array(data[i])
plt.scatter(np.array(data[i])[:,0],np.array(data[i])[:,1],cmap = custom_cmap2, alpha=0.4, label=i)
plt.scatter(sample[i][0], sample[i][1], marker='+', color='black', alpha=0.6)
plt.axis(axes)
plt.legend()
plt.xlabel('密度')
plt.ylabel('含糖率')
plt.show()
if __name__=='__main__':
data, lables = dataset()
sample = {}
#list = random.sample(range(0,len(data)),3)#随机选择三个整数 用来当作初始均值向量 这里为了看是否正确 复习书上的例子
list = [5,11,23]
for i in range(3):
sample[i] = data[list[i]]#将随机选择的数据 用来当作初始均值向量
print("sample",sample)
flag = 0
while flag != 3 :#直到所有均值向量不再更新时 退出循环
print("这是循环!")
flag = 0
sorted_data = sort_data(data,sample)#先对当前所有数据根据向量均值进行分簇
plot(sorted_data,sample)#每一轮划分好后 可视化展示
for i in range(len(sample)):#一类一类的进行更新均值
new_mean = updata_mean(np.array(sorted_data[i]),sample[i])
if ((new_mean==sample[i]).all()):#当前均值保持不变 标志位+1
flag += 1
else:#当前均值更新为新的均值
sample[i] = new_mean
for k in range(len(sorted_data)):#查看每一簇有多少数据
print(len(sorted_data[k]))