IEEE Transactions on Image Processing文献跟踪11月
IEEE Transactions on Image Processing文献跟踪
2021年11月 • 40卷 • 第11期
可视化分析:
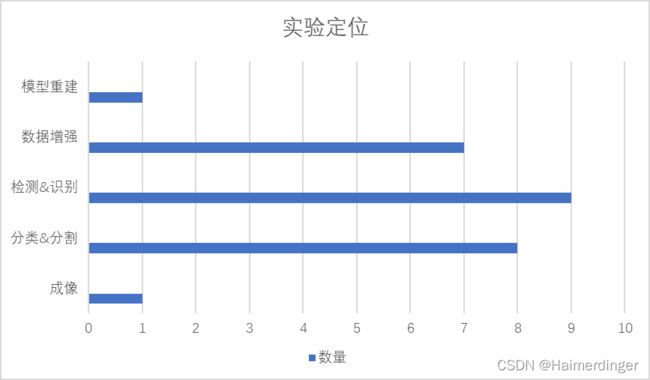
实验定位:
成像:
| 文献名/代码开源/推荐 |
关键词 |
数据集 |
对象 |
实验环境 |
实验方法 |
亮点 |
| Real-Time Computation of 3D Wireframes in Computer-Generated Holography(1)否 |
计算机生成全息(CGH)算法 理论分析 |
无 |
无 |
软件 |
本文提出了一种有效计算三维线段全息图的技术。我们解析地表达了这些解,并设计了一种适用于大规模并行计算体系结构的高效可计算近似。 |
全息视频显示器上验证 |
分类或分割:
| 文献名/代码开源/推荐 |
关键词 |
数据集 |
对象 |
实验环境 |
实验方法 |
亮点 |
| Semi-Supervised Dual Relation Learning for Multi-Label Classification(1)否 |
多标签分类 半监督学习 |
Corel5K ESP Game IAPRTC-12 SUN CUB AWA |
具有多个标签的图片 |
软件 |
提出了一种用于多标签分类的半监督双关系学习(SDRL)框架。SDRL在训练阶段使用少量的标记样本以及大规模的未标记样本。它甚至从未标记的样本中联合探索实例间特征级关系和实例内标签级关系。在我们的模型中,部署了一个双分类器结构来获得域不变表示。进一步比较来自分类器的预测结果,并将最有信心的预测提取为伪标签。设计了一个可训练的标签关系张量,用于显式地探索两两潜在标签关系并细化预测标签。SDRL能够有效地探索特征标签关系以及标签关系知识,而无需任何额外的语义知识。 |
一种双分类器域自适应机制 一种基于双分类器结构的主动伪标签分配策略 一种基于标签关系张量的多标签关系学习结构 |
| Joint Feature Disentanglement and Hallucination for Few-Shot Image Classification(1)否 |
少镜头学习 |
CUB FLO mini-ImageNet和 CIFAR-100 |
\ |
软件 |
本文提出了特征分离和幻觉网络(FDH-Net),它为FSL目的联合执行特征分离和幻觉。更具体地说,我们的FDH网络能够将输入的视觉数据分解为特定于类别和特定于外观的特征。在数据恢复和分类约束下,利用从基本类别中提取的外观信息,可以实现对新类别图像特征的幻觉。 |
提出了一种新的基于解纠缠的数据幻觉方法来解决少数镜头学习 |
| Deep Unsupervised Active Learning via Matrix Sketching(2)是 |
无监督学习 矩阵绘制 |
Mice Protein Expression UCF11 Musk Epileptic Seizure Recognition Swarm Behaviour Mediamill |
\ |
软件 |
提出了一种新的深度无监督主动学习方法,用于分类任务,该方法受矩阵绘制思想的启发,称为ALMS。具体而言,ALMS利用深度自动编码器将数据嵌入潜在空间,然后用小尺寸草图描述所有嵌入数据,以总结数据的主要特征。与以前重建整个数据矩阵以选择代表性样本的方法不同,ALMS旨在选择代表性样本子集以很好地逼近草图,这样可以保留数据的主要信息,同时显著减少网络参数的数量。这使得我们的算法减轻了模型过度拟合的问题,并且易于处理大型数据集。实际上,草图提供了一种自我监督信号,用于指导模型的学习。 |
通过对真/假样本进行分类来构造一个辅助的自监督任务 |
| Spatially Adaptive Feature Refinement for Efficient Inference(2)否 |
CNN |
ImageNet |
\ |
软件 |
本文中,我们提出了一种新的空间自适应特征细化(SAR)方法来减少CNN多余的计算。它通过自适应地融合来自两个分支的信息来执行有效的推理:一个分支以较低的空间分辨率对输入特征进行标准卷积,另一个分支以原始分辨率选择性地细化一组区域。这两个分支在特征学习中相互补充,并且它们都比标准卷积产生的计算量小得多。SAR是一种灵活的方法,可以方便地插入现有CNN中,以建立具有减少空间冗余的模型。 |
适用于分类分割检测 |
| Adversarial Domain Adaptation With Prototype-Based Normalized Output Conditioner(2)是 |
无监督学习 |
Office-Home VisDA2017 Office31 ImageCLEF-DA |
\ |
软件 |
本文通过设计简单紧凑的条件域对抗训练方法来解决这一难题。回顾了简单的连接调节策略,其中特征与输出预测连接,作为鉴别器的输入。我们发现级联策略受到弱条件强度的影响。我们进一步证明,扩大级联预测的范数可以有效地激发条件域对齐。因此,我们通过对输出预测进行归一化,使其具有相同的特征范数,并将导出的方法称为归一化输出调节器(名词),从而改进了级联调节。然而,以域对齐的原始输出预测为条件,Non会遭受目标域的不准确预测。 |
提供了一种强领域对抗性的代词训练方法 |
| 3D Interactive Segmentation With Semi-Implicit Representation and Active Learning(3)否 |
三维分割 医学图像 |
CTA BraTS2015 MRI |
血管 脑肿瘤 3D核磁共振 |
软件 |
提出了一种新的半隐式表示方法,即非均匀隐式B样条曲面(NU-IBS),该方法根据几何复杂度自适应地分布参数混合的面片。然后,引入两级级联分类器进行有效的前景和背景描绘,其中训练简单的朴素贝叶斯模型进行快速背景消除,然后使用更强的伪3D卷积神经网络(CNN)多尺度分类器精确识别前景对象。采用了一种局部交互式自适应分割方案,通过利用用户干预迭代获得的信息来提高分割精度。分割结果是通过根据划定区域的概率解释对NU-IBS进行变形获得的,这也对各个分段施加了同质性约束。 |
不再依赖于训练数据 |
| Examinee-Examiner Network: Weakly Supervised Accurate Coronary Lumen Segmentation Using Centerline Constraint(2)是 |
弱监督 被检查者-检查者网络(EE-Net) |
Cardiac CCTA Data ASOCA Data |
冠状动脉CT血管造影 |
软件 |
本文通过结合管腔的语义特征和从中心线获得的连续拓扑的几何约束,提出了EE网络来解决狭窄导致的分割断裂问题。然后,针对网络对中心线不敏感的问题,提出了一种中心线高斯掩模模块。随后,提出了一种弱监督学习策略,即被检查者-检查者学习,通过使用我们的EE网络以定制的先验条件引导和约束分割,来处理流明标签较少的弱监督情况。最后,提出了一种通用的网络层Drop-Output层,该层通过丢弃分割良好的区域和动态加权类来适应类的不平衡性。 |
一种新的弱监督模型 |
| RLStereo: Real-Time Stereo Matching Based on Reinforcement Learning(2)否 |
立体匹配算法 编码解码结构网络 |
Scene Flow KITTI 2015 Middlebury |
\ |
软件 |
本文提出了一种新的实时立体匹配方法RLStereo,该方法基于强化学习,摒弃了穷举搜索的代价量或常规方法。经过训练的RLStereo只需迭代执行几个操作,即可搜索每对立体图像的视差值。 |
先监督学习、后强化学习 |
检测或识别:
| 文献名/代码开源/推荐 |
关键词 |
数据集 |
对象 |
实验环境 |
实验方法 |
亮点 |
| Parallel Residual Bi-Fusion Feature Pyramid Network for Accurate Single-Shot Object Detection(3)否 |
特征金字塔 |
UAVDT17 MS COCO |
车辆 草地 |
软件 |
本文提出了一种并行残差双融合特征金字塔网络(PRB-FPN),用于快速准确的单镜头目标检测。提出了一种新的并行FP结构,该结构具有双向(自上而下和自下而上)融合和相关改进,以保留高质量的特征以实现精确定位。1)具有自底向上融合模块(BFM)的并行Biffusion FP结构,可同时检测大小目标,具有高精度;2) 拼接与重组(CORE)模块为特征融合提供了一条自底向上的路径,从而形成了双向融合FP,可以从底层特征图中恢复丢失的信息;3) 核心特征被进一步净化,以保留更丰富的上下文信息。这种自上而下和自下而上的核心净化过程只需几次迭代即可完成;4) 将剩余设计添加到CORE中,将产生一个新的Re CORE模块,该模块可方便地进行训练,并可与各种较深或较轻的主干进行集成。 |
提出PRB-FPN避免由于主干网络层数过深以及池移位导致无法精确定位的问题。 同时可以检测大小目标。 |
| Depth Privileged Scene Recognition via Dual Attention Hallucination(2)否 |
注意力 场景识别 |
SUN RGB-D NYU Depth V2 |
家居图片 |
软件 |
本文中,我们关注深度特权设置,其中深度信息仅在训练期间可用,而在测试期间不可用。考虑到从RGB和深度图像获得的信息是互补的,而注意是信息性的和可转移的,我们的想法是使用RGB输入来产生深度注意的幻觉。我们在调制的可变形卷积层上建立了我们的模型,并产生了双重注意:事后重要性权重和可训练的空间变换。 |
可以在测试中使用训练中的深度信息 |
| Dynamic Selective Network for RGB-D Salient Object Detection(1)否 |
RGB-D显著性检测 目标检测 |
公共RGB-D数据集 |
\ |
软件 |
本文提出了一种新的RGB-D显著性模型,即动态选择网络(DSNet),通过充分利用两种模式之间的互补性,在RGB-D图像中执行显著性目标检测(SOD)。首先部署一个跨模态全局上下文模块(CGCM)来获取高层语义信息,该信息可用于粗略定位显著对象。设计了一个动态选择模块(DSM)来动态挖掘RGB图像和深度图之间的跨模态互补信息,并通过执行基于选通和基于池的选择来进一步优化多层次和多尺度信息此外,我们还进行了边界细化,以获得具有清晰边界细节的高质量显著图。 |
自动选择和融合跨模态特征 自主优化跨层次和多尺度混合特征。 |
| DS-UI: Dual-Supervised Mixture of Gaussian Mixture Models for Uncertainty Inference in Image Recognition(1)是 |
图像识别不确定性 双监督 |
CIFAR-10/-100 SVHN TIM |
\ |
软件 |
提出了一种双监督不确定性推理(DS-UI)框架,用于改进基于DNN的图像识别中基于贝叶斯估计的UI。在DS-UI中,我们将DNN的分类器(即最后一个完全连接(FC)层)与高斯混合模型(MoGMM)的混合相结合,以获得MoGMM FC层。与DNN的现有UI方法(仅计算DNN输出分布的平均值或模式)不同,建议的MoGMM FC层充当分类器输入特征的概率解释器,以直接计算DS-UI的概率。 |
同时考虑了来自其他类的负样本,以减少类内距离,同时扩大类间边距, |
| It GAN Do Better: GAN-Based Detection of Objects on Images With Varying Quality(2)否 |
GAN网络 |
PASCAL VOC2007 |
\ |
软件 |
在本文提出了一种新的生成框架,该框架使用生成对抗网络(GAN)生成特征,为低质量图像上的目标检测提供鲁棒性。提出的基于GAN的目标检测(GAN-DO)框架不局限于任何特定的体系结构,可以推广到几种基于深度神经网络(DNN)的体系结构。由此产生的深度神经网络保持与所选基线模型相同的精确结构,而不会增加模型参数的复杂性或推理速度。 |
对抗网络是由两个神经网络构成的 |
| Rethinking Motion Representation: Residual Frames With 3D ConvNets(2)否 |
视频图像处理 3D卷积网络 |
UCF101 HMDB51 |
视频 |
软件 |
提出了一种廉价而有效的方法来提取视频中的运动特征,利用剩余帧作为3D网络的输入数据。通过使用剩余的RGB帧替换传统的堆叠RGB帧 |
可以获得比某些甚至使用附加光流的方法更好的性能 |
| Learning Human-Object Interaction via Interactive Semantic Reasoning(1)否 |
人-物交互(HOI) |
V-COCO HICO-DET |
人-物图片 |
软件 |
首先提出了一种新的基于语义的交互式推理块,该推理块有效地利用了视觉目标之间隐含的交互语义。设计了一个HOI推断结构,用于在场景范围和实例范围内解析视觉目标之间的成对交互语义。此外,我们提出了一种基于人体部位和物体位置的空间引导模型,作为几何引导,动态增强视觉特征学习 |
完全可微、端到端可训练的HOI检测框架 |
| Video Text Tracking With a Spatio-Temporal Complementary Model(1)是 |
视频文本跟踪 |
ICDAR 2013 Video Text ICDAR 2015 Video Text Minetto |
视频 |
软件 |
本文提出了一种新的时空互补文本跟踪模型。我们利用暹罗互补模块充分利用文本实例在时间维度上的连续性特征,有效地减少了文本实例的漏检,从而保证了每个文本轨迹的完整性。我们进一步通过文本相似性学习网络将文本实例的语义线索和视觉线索集成到一个统一的表示中,在存在外观相似的文本实例时提供了较高的辨别能力,从而避免了它们之间的错误关联。 |
利用连续帧之间的相关性来查找丢失的文本 |
| Multi-Hierarchical Category Supervision for Weakly-Supervised Temporal Action Localization(1)否 |
弱监督 动作定位 |
THUMOS14 ActivityNet1.2 ActivityNet1.3 |
视频 |
软件 |
本文引入了一种新的监督方法,称为多层次类别监督(MHCS),以发现更多的子行为,而不仅仅是区分性行为。具体来说,共享相似子动作的动作类别将通过层次聚类构造为超类。因此,使用新生成的超级类进行训练将鼓励模型更多地关注公共子动作,而忽略使用原始类进行训练。 |
提出的MHC是模型不可知和非侵入性的,可以直接应用于现有方法而不改变其结构 |
数据增强:
| 文献名/代码开源/推荐 |
研究部位 |
数据集 |
对象 |
实验环境 |
实验方法 |
亮点 |
| Non-Homogeneous Haze Removal via Artificial Scene Prior and Bidimensional Graph Reasoning(1)是 |
去噪(雾霾) |
RESIDE DCPDN-data Foggy Cityscapes-DBF NH-HAZE DHQ |
雾霾天气的图片 |
软件 |
本文提出了一种基于人工场景先验和二维图推理的非齐次烟雾去除网络(NHRN)。首先,我们采用gamma校正迭代地模拟不同曝光条件下的人工多次拍摄,其雾度不同,丰富了底层场景的先验知识。其次,除了利用局部邻接关系外,我们还构建了一个二维图推理模块,对特征地图的空间和通道维度进行非局部过滤,该模块对特征地图的长期依赖性进行建模,并在保存完好的节点和被烟雾污染的节点之间传播自然场景先验信息。 |
没有遵循基于双变量估计的大气散射模型,而是将薄雾的低能见度视为不适当的曝光,并尝试通过联合人工多曝光融合和非局部滤波进行校正 |
| Memorize, Associate and Match: Embedding Enhancement via Fine-Grained Alignment for Image-Text Retrieval(1)否 |
图像文本检索嵌入增强 |
Flickr30K |
文本图片相对应 |
软件 |
本文,我们提出了一种新的基于记忆的图像文本检索嵌入增强方法(MEMBER),该方法引入了全局内存库,以实现嵌入学习范式中的细粒度对齐和融合。具体来说,我们使用存储在文本(resp.,image)内存库中的相关文本(resp.,image)特征来丰富图像(resp.,text)特征。这样,我们的模型不仅实现了两种模式之间的相互嵌入增强,而且保持了检索效率。 |
从一个新的角度研究了图像文本检索,即通过细粒度对齐和融合来增强嵌入 |
| Image Comes Dancing With Collaborative Parsing-Flow Video Synthesis(1)是 |
图像视频合成 |
iPER (视频数据集) |
视频 |
软件 |
提出的CPF-Net集成了结构化的人类解析和外观流程来指导真实前景的合成,真实前景通过时空融合模块合并到背景中。CPF网络将问题分解为人类解析序列生成、前景序列生成和最终视频生成三个阶段。人体解析生成阶段捕获目标的姿势和身体结构。外观流有利于在合成帧中保留细节。人体解析和外观流的集成有效地指导了具有真实外观的视频帧的生成。 |
证明了人体解析图和外观流的集成可以大大提高最终视频的视觉质量 |
| Multi-Scale Single Image Dehazing Using Laplacian and Gaussian Pyramids(3)否 |
拉普拉斯金字塔 高斯金字塔 多尺度 去雾 |
自建(部分自采,部分从其他数据集中挑选) |
模糊图片 |
软件 |
本文提出了一种暗直接衰减先验(DDAP)来解决目标辐射和雾度之间的模糊性这一问题,提出了一种新的haze线平均法来减少DDAP引起的形态伪影,该方法使得具有较小半径的加权引导图像滤波器能够进一步减少形态伪影,同时保留图像中的精细结构。针对天空区域的噪声放大问题,本文提出一种多尺度去雾算法,采用拉普拉斯金字塔和高斯金字塔将模糊图像分解为不同的层次,并采用不同的去雾和降噪方法恢复不同层次的场景辐射。折叠生成的棱锥体以恢复无雾图像。 |
算法参数量小、它有被计算资源有限的移动设备采用的潜力。 |
| Stroke-Based Scene Text Erasing Using Synthetic Data for Training(5)否 |
场景文本擦除技术 文本检测和图像修复 编解码结构 Resblock |
SCUT-Syn ICDAR2013 SCUT-EnsText |
\ |
软件 |
提出了包含笔划掩码预测模块和背景修复模块的网络,该模块可以从裁剪的文本图像中提取相对较小的笔划,以保持更多的背景内容,从而获得更好的修复结果。该模型可以使用边界框部分擦除场景图像中的文本实例,或者使用现有的场景文本检测器自动擦除场景文本。 |
两个工作:先分割,后去除 |
| Burst Photography for Learning to Enhance Extremely Dark Images(2)否 |
极低光照条件下拍摄图像增强 |
SID |
极暗图片 |
软件 |
本文利用突发摄影来提高性能,并从极暗的原始图像中获得更清晰、更准确的RGB图像。我们提出的框架的主干是一种从粗到精的新型网络体系结构,它可以逐步生成高质量的输出。粗糙网络预测低分辨率、去噪的原始图像,然后将其馈送到精细网络以恢复精细比例细节和真实纹理。为了进一步降低噪声水平和提高颜色精度,我们将该网络扩展到一种置换不变结构,使其以突发的弱光图像作为输入,并在特征级合并来自多个图像的信息。 |
基于学习的方法克服传统的增强技术无法应用极暗图片 |
| Image Noise Reduction Based on a Fixed Wavelet Frame and CNNs Applied to CT(3)否 |
CT图像降噪 CNN |
Cancer Imaging Archive(50张) |
头部CT |
软件 |
本文首先简化了过完备小波变化(OHWT)的计算,可以很容易地再现。其次,我们通过进一步结合传统小波收缩方法的知识来更新收缩阶段的结构。最后,通过与RED和FBPConvNet CNN的比较,我们广泛地测试了它的性能和泛化性。 |
综合了多种降噪方法 |
定位:
| 文献名/代码开源/推荐 |
研究部位 |
数据集 |
对象 |
实验环境 |
实验方法 |
亮点 |
模型重建:
| 文献名/代码开源/推荐 |
关键词 |
数据集 |
对象 |
实验环境 |
实验方法 |
亮点 |
| Texture Memory-Augmented Deep Patch-Based Image Inpainting(1)是 |
图像修复 |
Places、 CelebA HQ Street View(公开) |
扣掉一部分的图片 |
软件 |
结合基于补丁的方法和深度网络的方法的优点,本文提出了一种新的深度修复框架,其中纹理生成由从未遮罩区域提取的面片样本的纹理记忆来指导。引入了斑块分布损失,以鼓励高质量的斑块合成 |
允许使用深度修复网络端到端地训练纹理记忆检索。 |
预测:
| 文献名/代码开源/推荐 |
研究部位 |
数据集 |
对象 |
实验环境 |
实验方法 |
亮点 |