Pytorch项目,肺癌检测项目之一
项目目的:输入人体躯干的三维CT扫描作为输入数据,如果存在肿瘤,希望输出疑似恶性肿瘤的位置。
项目背景:发现处于早期的肺癌对病人生存率有巨大影响,但很难大规模进行。审查CT数据的工作必须由训练有素的专家进行,需要对细节进行细致的关注,当然,绝大部分情况下医生看的片子都没有癌症。
CT的数据叫做:DICOM数据。CT扫描的每一个体素都对应一个数值,这个数值描述的是内部物质的平均质量密度。CT扫描的数据还允许我们通过隐藏我们不感兴趣的部分进行立体查看。
体素数据与CT值
对于一块体素数据,它不是一个立方体,而是1.125mm*1.125mm*2.5mm的一个立方体,如果按照立方体来对数据进行绘制的时候,人会看起来更胖一些,所以如果要按照真实的样貌进行展示还需要加入一个变换比例。CT值是测定人体某一局部或器官密度大小的一种计量单位,通常称为亨氏单位(HU),空气为 -1000 (0g/cm3),致密骨为 +1000(2-3g/cm3)。实际上CT值是CT图像中各组织与X线衰减系数相当的对应值。
观察数据
(1)CT数据是立体3D数据
(2)数据存在重复和错误
(3)数据的标注包括一份某个区域的结节是否为肿瘤以及某个肿瘤是否恶性的标准
理解业务
(1)拿到CT先逐行逐个查看图像
(2)找到其中存在异常的位置,然后用笔把这个位置圈出来留待分析
(3)对所有圈出来的位置进行仔细的研究,根据它的各种特性,比如光泽,形状,大小,位置等信息来决策是否真的是一个肿瘤
(4)做更多的检查,结合经验判断这个肿瘤是否是恶行肿瘤
(5)帮助病人指定治疗方案
解决方案
原始数据---》数据处理---》切割图象---》候选分组---》候选分类---》恶行判断
数据清洗、数据 在全像素空间中寻 对有问题的点位进行分组,加载、数据转换 找有问题的像素 确定一个结节的范围 ,对有结节的图像进行分类,确定是否是肿瘤,对判定为肿瘤的图像进一步分类判断是否为恶行肿瘤
解决方案描述
(1)加载原始数据,把它转化为PyTorch可以处理的数据,也就是我们的tensor数据
(2)使用PyTorch进行数据分割,把存在异常的点位确定出来
(3)把已经确定有问题的区域进行发呢组,这一块不太需要构建一个模型来处理,所以单独拿出来作为一个步骤
(4)构建模型对候选结节分类,区分出它是否是真的肿瘤
(5)对分类结果进行分析,然后根据影像判断肿瘤是良性的还是恶性的。
查看数据
一个CT数据实际上包含两个文件,‘.mhd’文件包含了元数据头部信息,‘.raw’则是存储的三维CT原始数据。前面的文件名称为它的uid,符合DICOM数据命名法。
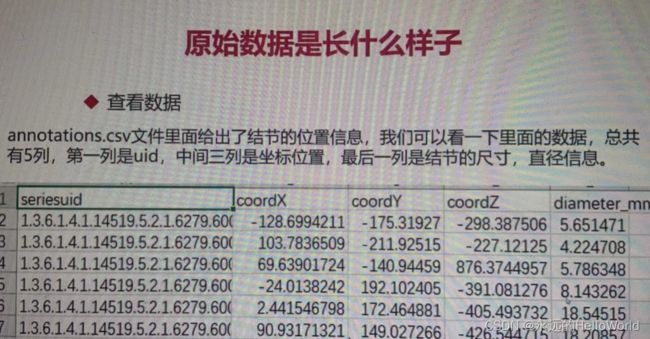
annotations.csv文件里面给出了结节的位置信息,里面的数据共有5列,第一列是uid,中间三列是坐标位置,最后一列是结节的尺寸,直径信息。
查看数据
candidates.csv是对影响中小圆点的标注,数据也是五列,有区别的是最后一列,candidates.csv的最后一列标明了这个小圆点是否是结节。其中candidates.csv文件中包含了551063条数据,如果我们对分类标签统计一下,可以发现总共有1351条被标注是结节。这个时候数据的问题就来了,在annotation.csv文件里只给出了 1187条结节的信息。

数据比对

这几条数据,比对下,看是否是一个位置,对数据预处理
代码处理
CandidateInfoTuple = namedtuple(
'CandidateInfoTuple',
'isNodule_bool,diameter_mm,series_uid,center_xyz',
)
#放缓存里
@functools.lru_cache(1)
def getCandidateInfoList(requireOnDisk_bool=True):
mhd_list=glob.glob('/lujing/subset*/*.mhd')
persentOnDisk_set={os.path.split(p)[-1][:-4] for p in mhd_list}