大数据—Hadoop(四)_ HDFS_03、客户端API
文章目录
- 1、客户端环境准备
-
- 1.1 idea
- 1.2 window依赖
- 2、HDFS的API案例实操
-
- 2.1 HDFS文件上传(测试参数优先级)
-
- 2.1.1 客户端代码常用套路
- 2.1.2 普通版
- 2.1.3 优化后
- 2.1.4 上传文件,修改@Test
- 2.1.5 补充:API参数优先级(由低到高)
-
- 2.1.5.1 hdfs-default.xml(最低)
- 2.1.5.2 hdfs-site.xml
- 2.1.5.3 代码中的配置(最高)
- 2.2 HDFS文件下载
- 2.3 HDFS删除文件和目录
- 2.4 HDFS文件更名和移动
- 2.5 HDFS文件详情查看
- 2.6 HDFS文件和文件夹判断
1、客户端环境准备
1.1 idea
导入依赖
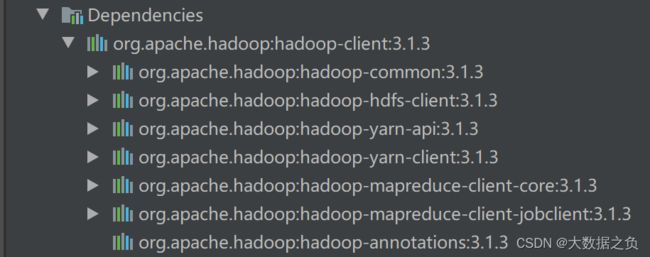
1、hadoop-client 客户端
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.3version>
dependency>
a、导入Hadoop客户端依赖 3.1.3 (和服务器依赖一致)
b、相当于导入一个本地模式的Hadoop,子依赖含有hdfs、yarn、mr等
2、junit 单元测试
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
3、slf4j-log4j 打印日志
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.30version>
dependency>
在Resource(一般放置静态文件,如:图片、音频和视频)中加入配置文件,修改slf4j日志级别为INFO
- INFO:INFO以及上
- INFO和 ERROR
- ERROR:ERROR以及上
- ERROR
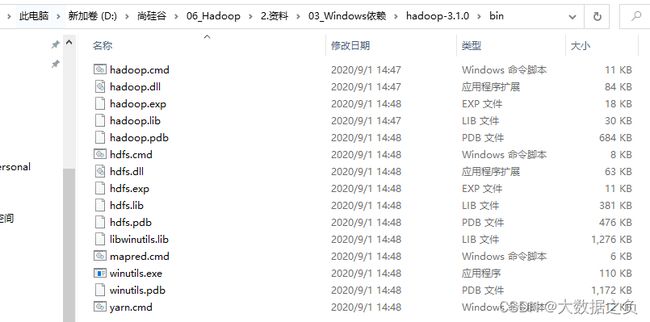
1.2 window依赖
- 配置HADOOP_HOME环境变量
- idea中的依赖的jar包需要使用这些window依赖
2、HDFS的API案例实操
2.1 HDFS文件上传(测试参数优先级)
2.1.1 客户端代码常用套路
- 获取客户端对象 操作谁就得先拿到该对象
- 执行相关的操作命令
- 关闭资源
应用:hdfs zk
2.1.2 普通版
/**
* 在hdfs上创建文件夹
*/
@Test
public void testMkdir() throws URISyntaxException, IOException, InterruptedException {
// 1、客户端和 namenode 打交道,所以要拿到 namenode 所在节点:hadoop102 的URI
// 2、namenode 的内部通讯端口为8020
URI uri = new URI("hdfs://hadoop102:8020");
// 创建配置文件
Configuration configuration = new Configuration();
// 得到了一个客户端对象
// hdfs的 owner 是atguigu
FileSystem fs = FileSystem.get(uri, configuration, "atguigu");
fs.mkdirs(new Path("/xiyou/huaguoshan"));
// 关闭资源
fs.close();
}
- 使用注解@Test进行单元测试
- NameNode服务端口号:8020
NameNode外部端口号:9870 - owner
- 需要对 创建对象 和 关闭资源 做优化
2.1.3 优化后
private FileSystem fs;
@Before
public void init() throws IOException, InterruptedException, URISyntaxException {
// 1、客户端和 namenode 打交道,所以要拿到 namenode 所在节点:hadoop102 的URI
URI uri = new URI("hdfs://hadoop102:8020");
// 创建配置文件
Configuration configuration = new Configuration();
// 得到了一个客户端对象
// hdfs的owner是atguigu
fs = FileSystem.get(uri, configuration, "atguigu");
}
@After
public void close() throws IOException {
// 关闭资源
fs.close();
}
/**
* 在hdfs上创建文件夹
*/
@Test
public void testMkdir() throws URISyntaxException, IOException, InterruptedException {
fs.mkdirs(new Path("/xiyou/huaguoshan1"));
}
- before是在test之前执行的代码
- after是在test之后执行的代码
- 将 fs 提升为全局的变量
2.1.4 上传文件,修改@Test
@Test
public void testPut() throws IOException {
// 参数1:是否删除原数据 2:是否允许覆盖 3:原数据路径 4:目标地址路径
fs.copyFromLocalFile(false,false,new Path("D:\\input\\sunwukong.txt") , new Path("hdfs://hadoop102/xiyou/huaguoshan"));
}
2.1.5 补充:API参数优先级(由低到高)
2.1.5.1 hdfs-default.xml(最低)
<property>
<name>dfs.replicationname>
<value>3value>
<description>Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
description>
property>
上传文件默认副本数是3
2.1.5.2 hdfs-site.xml
在idea中的resources文件夹下添加hdfs-site.xml文件
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>
设置副本数是1
2.1.5.3 代码中的配置(最高)
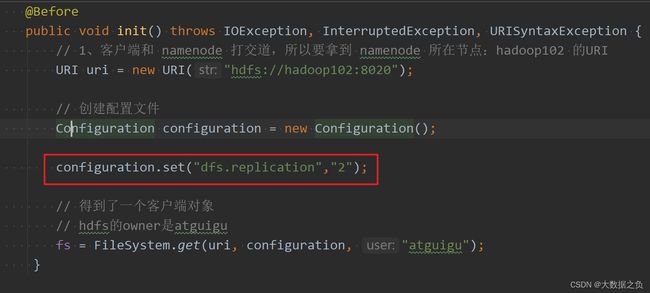
设置副本数是2
优先级最高
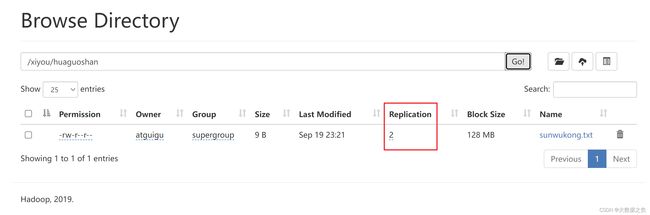
2.2 HDFS文件下载
@Test
public void testGet() throws IOException {
// 参数1:是否删除原数据 2:HDFS路径 3:目标地址路径Window 4:是否使用校验文件,对比传输时有无中途丢失数据
fs.copyToLocalFile(false,new Path("hdfs://hadoop102/xiyou/huaguoshan") , new Path("D:\\input\\sunwukong1.txt"),true);
}

除了下载的文件之外,还有一个crc校验文件
2.3 HDFS删除文件和目录
@Test
public void testDel() throws IOException {
// 参数1:要删除的路径 2:是否递归删除 如果只是一个文件,true和false都一样 ; 如果是非空目录,true
fs.delete(new Path("hdfs://hadoop102/sanguo") ,true);
}
2.4 HDFS文件更名和移动
@Test
public void testMv() throws IOException {
// 参数1:原文件路径 2:目标文件路径
// 1、修改文件名
fs.rename(new Path("hdfs://hadoop102/jinguo/weiguo.txt") ,new Path("hdfs://hadoop102/jinguo/wg.txt"));
// 2、更名或者移动
fs.rename(new Path("hdfs://hadoop102/jinguo/wg.txt") ,new Path("hdfs://hadoop102/output/weiguo.txt"));
// 3、目录更名
fs.rename(new Path("hdfs://hadoop102/output") ,new Path("hdfs://hadoop102/input"));
}
2.5 HDFS文件详情查看
@Test
public void testFileDetail() throws IOException {
// 得到所有文件信息的迭代器
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/jinguo"), true);
// 遍历文件
while (listFiles.hasNext()){
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("==="+fileStatus.getPath()+"===");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getPath().getName());
System.out.println(fileStatus.getBlockSize());
}
}
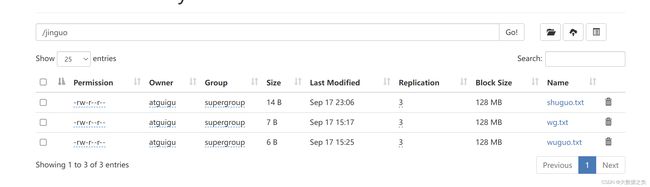
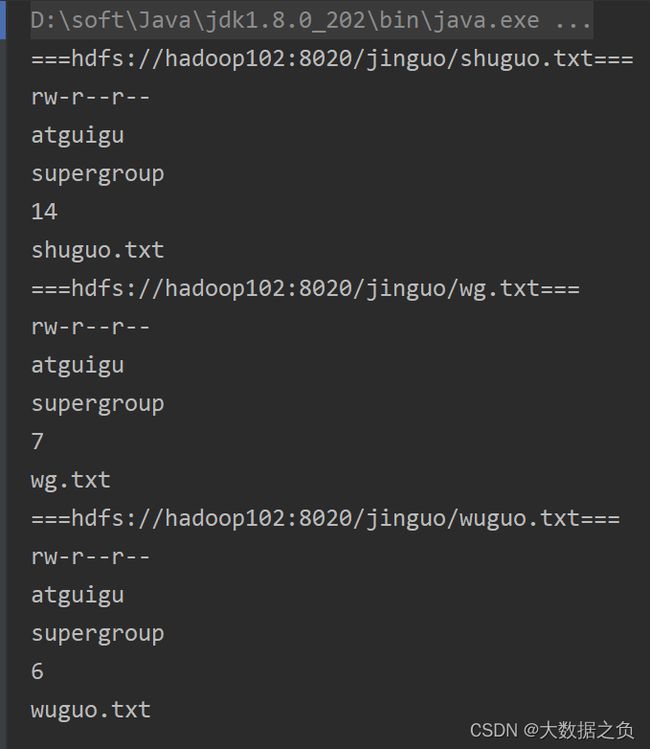
2.6 HDFS文件和文件夹判断
@Test
public void testFile() throws IOException {
// 得到所有文件信息的数组
FileStatus[] listStatus = fs.listStatus(new Path("/jinguo"));
// 遍历文件
for (FileStatus status : listStatus) {
if (status.isFile()){
System.out.println("文件:" + status.getPath().getName());
}else {
System.out.println("文件夹:" + status.getPath().getName());
}
}
}
