C语言学习NO.8-操作符(二)二进制相关的操作符,原码、反码、补码是什么,左移右移操作符、按位与,按位或,按位异或,按位取反
一、操作符的分类
操作符的分类
- 算术操作符: + 、- 、* 、/ 、%
- 移位操作符: << >>
- 位操作符: & | ^ `
- 赋值操作符: = 、+= 、 -= 、 *= 、 /= 、%= 、<<= 、>>= 、&= 、|= 、^=
- 单⽬操作符: !、++、–、&、*、+、-、~ 、sizeof、(类型)
- 关系操作符: > 、>= 、< 、<= 、 == 、 !=
- 逻辑操作符: && 、||
- 条件操作符: ? :
- 逗号表达式: ,
- 下标引用: [ ]
- 函数调用: ( )
- 结构成员访问: . 、->
在C语言学习NO.2中操作符中已经讲过算术操作符、赋值操作符、逻辑操作符、条件操作符和部分的单目操作符。
也在NO.2操作符中介绍了整型常量的不同进制关系,今天来更详细地介绍操作符中和⼆进制有关系的操作符。
二、⼆进制和进制转换
| 0,1 | 0-7 | 0-9 | 0-9,a-f |
|---|---|---|---|
| 二进制 | 八进制 | 十进制 | 十六进制 |
详细见C语言学习NO.2-操作符的整形常量的不同进制关系。
三、原码、反码、补码
整数的2进制表示方法有三种,即原码、反码和补码
2进制序列中,有符号整数的三种表示方法均有**符号位(最左侧数字)和数值位(除符号位剩余位)**两部分。
- 符号位都是用0表示“正”,用1表示“负”。
- 正整数的原、反、补码都相同:
- 直接将数值按照正负数的形式翻译成⼆进制得到的就是原码;
- 正整数的原、反、补码相同。
- 负整数的三种表达方式各不相同:
- 原码:直接将数值按照正负数的形式翻译成⼆进制得到的就是原码。;
- 反码:将原码的符号位不变,其他位依次按位取反就可以得到反码;
- 补码:反码+1就得到补码。;
- 反码得到原码也是可以使用:取反,+1的操作。
对于整形来说:数据存放内存中其实存放的是补码。
为什么呢? 在计算机系统中,数值一律用补码来表示和存储。原因在于使用补码可以将符号位和数值域统一处理;同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
四、移位操作符
<<左移操作符
>>右移操作符
注:移位操作符的操作数只能是整数。
(一)左移操作符
移位规则:左边抛弃、右边补0.
当num为正数时:
#include
int main()
{
int num = 10;
int n = num<<1;
printf("n = %d\n",n);
printf("num = %d\n",num);
return 0;
}

现在让我们来看看一下n值是怎么求得的。
由于<<是移动二进制位的符号,我们首先把整型的num转化为二进制。
int拥有四个字节,每个字节有8个比特位,转换为二进制后为:
1010 →→→ 是二进制为的10。1*2^3 +0+1*2^1+0 = 10;
int有32个比特位,所以转换二进制后应为:
00000000 00000000 00000000 00001010;
<<是指二进制位向左移动一位,右侧补上一位。
则
同理,当num为负数时:
#include
int main()
{
int num = -10;
int n = num<<1;
printf("n = %d\n",n);
printf("num = %d\n",num);
return 0;
}
补码转换到原码,两种方法:
- 补码 减一 到反码, 反码 取反 到 原码(符号位不变)。
- 补码 取反 加一 得到 原码。(符号位不变)

(二)右移操作符
移位规则:右移运算分两种:
- 逻辑右移:左边用0填充,右边丢弃;
- 算术右移:左边用原值符号位填充,右边丢弃;
- 采用哪种右移取决于编译器设置。
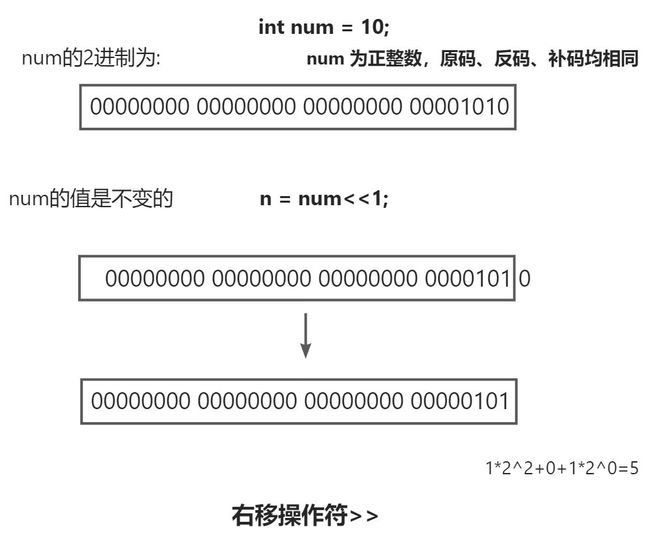
当num为正整数时:
#include
int main()
{
int num = 10;
int n = num>>1;
printf("n= %d\n", n);
printf("num= %d\n", num);
return 0;
}

当num为负整数:
#include
int main()
{
int num = -10;
int n = num>>1;
printf("n= %d\n", n);
printf("num= %d\n", num);
return 0;
}


(三)总结
- 数据存放内存存放的是补码;
- 左移操作符、右移操作符操作移动的是数据存放的补码;
- 打印出来的值是原码。
五、位操作符:&、|、^、~
&: //按位与 双目操作符 a&b
//两个数的二进制位只有对应的二进制位都为1,才为1.否则为0
|: //按位或 双目操作符 a|b
//两个数的二进制位只有对应的二进制位都为0,才为0.否则为1
^: //按位异或 双目操作符 a^b
//两个数的二进制位对应的二进制位:相同为0,相异为1
~: //按位取反 单目操作符 ~a
//整数的二进制位全部取反
注:他们的操作数都必须是整数
#include
int main()
{
int num1 = -3;//内存中是补码,打印出的是原码
int num2 = 5;
//-3:10000000 00000000 00000000 00000011 原码
// 11111111 11111111 11111111 11111101 补码
// 5:00000000 00000000 00000000 00000101 原码 正整数相同
// 00000000 00000000 00000000 00000101 补码
//先操作看补码,后打印出的值看原码
printf("%d\n", num1 & num2);
//只有对应的二进制位都为一,才为1,否则为0
//00000000 00000000 00000000 00000101 → 补码 符号位为正
//00000000 00000000 00000000 00000101 → 原码 5
printf("%d\n", num1 | num2);
//两个数的二进制位只有对应的二进制位都为0,才为0.否则为1
//11111111 11111111 11111111 11111101 → 补码 符号位为负
//10000000 00000000 00000000 00000011 → 原码-3
printf("%d\n", num1 ^ num2);
//两个数的二进制位对应的二进制位:相同为0,相异为1
//11111111 11111111 11111111 11111000 → 补码 符号位为负
//10000000 00000000 00000000 00001000 → 原码 +8
printf("%d\n", ~0);
//整数的二进制位全部取反
//11111111 11111111 11111111 11111111 → 补码 符号位为负
//10000000 00000000 00000000 00000001 → 原码-1
return 0;
}

(一)^ 按位异或交换两个数的小技巧:
a^a = 0;
0^a = a;
**不能创建临时变量(第三个变量),实现两个数的交换。 **
#include
//不能创建临时变量(第三个变量),实现两个数的交换。
int main()
{
int a = 10;
int b = 20;
a = a^b;//
b = a^b;
//b = a^b = a^b^b = 0^a = a
a = a^b;
// a = a^b = a^b^a = b^0 =b
printf("a = %d b = %d\n", a, b);
return 0;
}
(二)练习
练习1:整数在内存中1的个数
编写代码实现:求一个整数存储在内存中的⼆进制中1的个数。
为了方便多组测试添加的while(scanf(“%d”,&num) != EOF)可删去。
#include
//求一个整数存储在内存中的⼆进制中1的个数。
int main()
{
int num = 10;
while(scanf("%d",&num) != EOF)//为了方便多次测试不同数值
{
int i = 0;
int count = 0;
for (i = 1; i <= 32; i++) { //32个比特位
if (1 == ((num >> i) & 1))
//num是不会因为>>改变num的值的,所以每向右移 i 位,
//让最右侧的值 & 1,来判断是否为1,为1 则进入if语句,count++
count++;
}//该语句要循环32次,知道num的32个比特位都移动至最右侧
printf("%d\n", count);
}
return 0;
}
#include
//求一个整数存储在内存中的⼆进制中1的个数。
int main()
{
int num = 10;
while(scanf("%d",&num) != EOF)//为了方便多次测试不同数值
{
int i = 0;
int count = 0;
for (i = 1; i <= 32; i++)
{
count += num & 1;
num = num >> 1;//同上一代码原理一致,当num最右侧值和1相同时,
//num & 1是1,否则为0,以此count进行计数的功能,
//每次循环num的值都会变化,因此是 num >> 1,而不是num >> i
//同样需要循环32次进行判断
}
printf("%d\n", count);
}
return 0;
}
#include
int main()
{
int num = -1;
int i = 0;
int count = 0;//计数
for(i=0; i<32; i++)//循环32次
{
if( num & (1 << i) )//上列是num 右移,现在思维转换,将1 的二进制左移进行判断
count++; //计数
} //原理一致
printf("⼆进制中1的个数 = %d\n",count);
return 0; }
上列方法都必须循环32次的,思考是否可以优化:
#include
int main()
{
int num = -1;
int count = 0;//计数
while(num)//非0为真,0为假
{
count++;
num = num&(num-1);//按位与
//&按位与: 对应的二进制位都为1,才为1,否则为0
//&运算符可以用来检查一个数的二进制表示中是否包含1
//通过将原数与1进行位与运算,并将结果加到计数器上,可以计算出二进制中1的个数。
}
printf("⼆进制中1的个数 = %d\n",count);
return 0;
}
练习2:⼆进制位置0或者置1
编写代码将13⼆进制序列的第5位修改为1,然后再改回0
//13的2进制序列: 00000000000000000000000000001101
//将第5位置为1后:00000000000000000000000000011101
//将第5位再置为0:00000000000000000000000000001101
#include
//编写代码将13⼆进制序列的第5位修改为1,然后再改回0
int main()
{
int a = 13;
//13的2进制序列: 00000000000000000000000000001101
a = a | (1<<4);
printf("a = %d\n", a);
//1左移4个二进制位00000000 00000000 00000000 00000001
//00000000 00000000 00000000 00010000 → 第5位变为1
//‘|’按位或 :两个数对应的二进制位都为0才为0,否则为1
//a修改为00000000 00000000 00000000 00011101 → 16+8+4+1=29
a = a & ~(1<<4);
printf("a = %d\n", a);
//~按位取反
//11111111 11111111 11111111 11101111
//& 按位与 : 对应的二进制位都为1才为1,否则为0
//00000000 00000000 00000000 00011101 修改第五位的a的2进制序列
//00000000 00000000 00000000 00001101 第五位改回为0 → 13
return 0;
}

六、下标访问[]、函数调用()
(一)[ ] 下标引用操作符
操作数:一个数组名 + 一个索引值
int arr[10];//创建数组
arr[9] = 10;//实用下标引用操作符。
[]的两个操作数是arr和9。
(二)函数调用操作符
接受一个或者多个操作数:第一个操作数是函数名,剩余的操作数就是传递给函数的参数。
#include
void test1()
{
printf("hehe\n");
}
void test2(const char *str)
{
printf("%s\n", str);
}
int main()
{
test1(); //这⾥的()就是作为函数调用操作符。
test2("hello bit."); //这⾥的()就是函数调用操作符。
return 0;
}
七、结构成员访问操作符
(一)结构体
C语言已经提供了内置类型,如:char、short、int、long、float、double等,但是只有这些内置类型还是不够的。
假设我想描述学生,描述一本书,这是单一的内置类型是不行的。描述一个学生需要 名字、年龄、学号、身高、体重等;描述一本书需要 作者、出版社、定价等。C语言为了解决这个问题,增加了结构体这种自定义的数据类型,让程序员可以自己创造适合的类型。
结构是一些值的集合,这些值称为成员变量。
结构的每个成员可以是不同类型的变量,如: 标量、数组、指针,甚至是其他结构体。
结构的声明:
struct tag
{
member-list;
}variable-list;
描述一个学生:
struct Stu
{
char name[20]; //名字
int age; //年龄 1234
char sex[5]; //性别
char id[20]; //学号
}; //分号不能丢
结构体变量的定义和初始化
//代码1:变量的定义
struct Point
{
int x;
int y;
}p1; //声明类型的同时定义变量p1
struct Point p2; //定义结构体变量p2
//代码2:初始化。
struct Point p3 = {10, 20};
struct Stu //类型声明
{
char name[15]; //名字
int age; //年龄
};
struct Stu s1 = {"zhangsan", 20};//初始化
struct Stu s2 = {.age=20, .name="lisi"}; //指定顺序初始化
//代码3
struct Node
{
int data;
struct Point p;
struct Node* next;
}n1 = {10, {4,5}, NULL}; //结构体嵌套初始化
struct Node n2 = {20, {5, 6}, NULL}; //结构体嵌套初始化
(二)结构成员访问操作符
结构体成员的直接访问
结构体成员的直接访问是通过点操作符(.)访问的。点操作符接受两个操作数。如下所示:
#include
struct Point
{
int x;
int y;
}p = {1,2};
int main()
{
printf("x: %d y: %d\n", p.x, p.y);
return 0;
}
//使用⽅式:结构体变量.成员名
// p.x, p.y
结构体成员的间接访问
有时候我们得到的不是一个结构体变量,而是得到了一个指向结构体的指针。如下所示:
#include
struct Point
{
int x;
int y;
};
int main()
{
struct Point p = {3, 4};
struct Point *ptr = &p;
ptr->x = 10;
ptr->y = 20;
printf("x = %d y = %d\n", ptr->x, ptr->y);
return 0;
}
//使用⽅式:结构体指针->成员名
// ptr->x, ptr->y
综合举例:
#include
#include
struct Stu
{
char name[15]; //名字
int age; //年龄
};
void print_stu(struct Stu s)
{
printf("%s %d\n", s.name, s.age);
}
void set_stu(struct Stu* ps)
{
strcpy(ps->name, "李四");
ps->age = 28;
}
int main()
{
struct Stu s = { "张三", 20 };
print_stu(s);
set_stu(&s);
print_stu(s);
return 0;
}
八、表达式求值
(一)整型提升 (隐式类型转换)
C语言中整型算术运算总是至少以缺省整型类型的精度来进行的。
为了获得这个精度,表达式中的字符和短整型操作数在使用之前被转换为普通整型,这种转换称为整型提升。
整型提升的意义:
表达式的整型运算要在CPU的相应运算器件内执行,CPU内整型运算器(ALU)的操作数的字节长度一般就是int的字节长度,同时也是CPU的通用寄存器的长度。
因此,即使两个char类型的相加,在CPU执行时实际上也要先转换为CPU内整型操作数的标准长度。
通用CPU(general-purpose CPU)是难以直接实现两个8比特字节直接相加运算(虽然机器指令中 可能有这种字节相加指令)。所以,表达式中各种长度可能⼩于int长度的整型值,都必须先转换为 int或unsigned int,然后才能送⼊CPU去执行运算。
//实例1
char a,b,c;
...
a = b + c;
b和c的值被提升为普通整型,然后再执执行加法运算。
加法运算完成之后,结果将被截断,然后再存储于a中。
如何进行整体提升呢?
- 有符号整数提升是按照变量的数据类型的符号位来提升的
- 无符号整数提升,高位补0
//负数的整形提升
char c1 = -1;
//变量c1的⼆进制位(补码)中只有8个⽐特位:1111111
//因为 char 为有符号的 char
//所以整形提升的时候,⾼位补充符号位,即为1
//提升之后的结果是:
// 11111111111111111111111111111111
//正数的整形提升
char c2 = 1;
//变量c2的⼆进制位(补码)中只有8个⽐特位:00000001
//因为 char 为有符号的 char
//所以整形提升的时候,⾼位补充符号位,即为0
//提升之后的结果是:
// 00000000000000000000000000000001
//⽆符号整形提升,⾼位补0
(二)算术转换
如果某个操作符的各个操作数属于不同的类型,那么除非其中一个操作数的转换为另一个操作数的类型,否则操作就无法进行。下面的层次体系称为寻常算术转换。
long double
double
float
unsigned long int
long int
unsigned int
int
如果某个操作数的类型在上面这个列表中排名靠后,那么首先要转换为另外一个操作数的类型后执行运算。
小的数据类型转换成大的数据类型。再执行运算。