【腾讯云HAI域探秘】使用Checkpoint 模型开发仿“羊了个羊”游戏
文章目录
-
- 前言
- 什么是HAI?
- HAI 特点有哪些?
-
- 即插即用,轻松上手
- 横向对比 , 青出于蓝
- 应用场景
- 开启HAI新篇章
-
- 申请高性能应用服务 HAI
- 创建实例
-
- 配置选择
- 实例介绍
- 模型介绍
- 上传`DreamShaper`和`MeinaMix`模型
- 模型对比
- 点击Gradio WebUl 查看模型是否生效
- 模型对比
- 获取游戏所需的UI图
- 游戏开发
-
- 效果展示
- 核心代码展示
- 代码解析
- 开发完成
- 总结
前言
2022年可谓是AIGC(AI Generated Content)元年,上半年有文生图大模型DALL-E2和Stable Diffusion,下半年有OpenAI的文本对话大模型ChatGPT问世,这让冷却的AI又沸腾起来了,因为AIGC能让更多的人真真切切感受到AI的力量。这篇文章将介绍如和借助腾讯云HAI构建文生图模型Stable Diffusion(简称SD),Stable Diffusion不仅是一个完全开源的模型(代码,数据,模型全部开源),而且是它的参数量只有1B左右,大部分人可以在普通的显卡上进行推理甚至精调模型。毫不夸张的说,Stable Diffusion的出现和开源对AIGC的火热和发展是有巨大推动作用的,因为它让更多的人能快地上手AI作画。
通过本篇文章你将会收获以下知识内容:
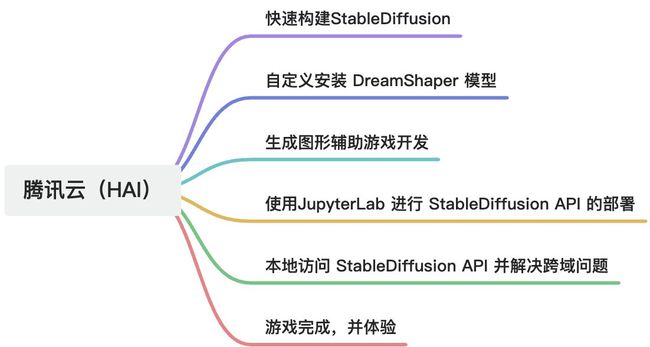
什么是HAI?
**腾讯云高性能应用服务(Hyper Application inventor,HAI),是一款面向 Al、科学计算的 GPU 应用服务产品,**为开发者量身打造的澎湃算力平台。无需复杂配置,便可享受即开即用的GPU云服务体验。在 HAl中,根据应用智能匹配并推选出最适合的GPU算力资源,以确保您在数据科学、LLM、Al 作画等高性能应用中获得最佳性价比。此外,HAL的一键部署特性让您可以在短短几分钟内构建如 StableDifusion,ChatGLM等热门模型的应用环境。而对于 AI 研究者,我们的直观图形界面大大降低了调试的复杂度,支持 jupyterlab、webui等多种连接方式,助您轻松探索与创新。
HAI 特点有哪些?
即插即用,轻松上手
基于腾讯云GPU云服务器底层算力,提供即插即用的高性能云服务。
| 新品优势 | |
|---|---|
| 智能选型 | 根据应用匹配推选GPU算力资源,实现最高性价比。同时,打通必备云服务组件,大幅简化云服务配置流程。 |
| 一键部署 | 分钟级自动构建LLM、AI作画等应用环境。提供多种预装模型环境,包含如StableDiffusion、ChatGLM等热门模型。 |
| 可视化界面 | 提供开发者友好的图形界面,支持jupyterlab、webui等多种算力连接方式,AI研究调试超低门槛 |
横向对比 , 青出于蓝
大幅降低GPU云服务器使用门槛,多角度优化产品使用体验,开箱即用
| 产品对比 | |
|---|---|
| GPU 云服务器 | 高性能应用服务 HAI |
| 机型选择难 | 机型自匹配 |
| 环境部署难 | 开箱即用 |
| 资源配置难 | 集成必要资源 |
| 命令行界面 | 可视化界面 |
| 模型甄别难 | 主流模型 |
| 需要了解GPU型号,自行选择合适机型,有不匹配风险 | 基于AI应用,自动匹配合适套餐 |
| 需要自行部署驱动、CUDA、Python、Notebook等环境依赖 | 分钟级快速启动,直接交付可用应用环境 |
| 需要额外购买合适的云硬盘、带宽或流量 | 打包GPU、云硬盘、带宽及网络,一键启动 |
| 需要具备一定运维知识,登录服务器内部进行操作 | 提供webui等可视化连接方式,一键进入服务,可视化配置 |
| 各类模型版本繁多,难以挑选 | 筛选最新版本的主流模型,适配套餐机型 |
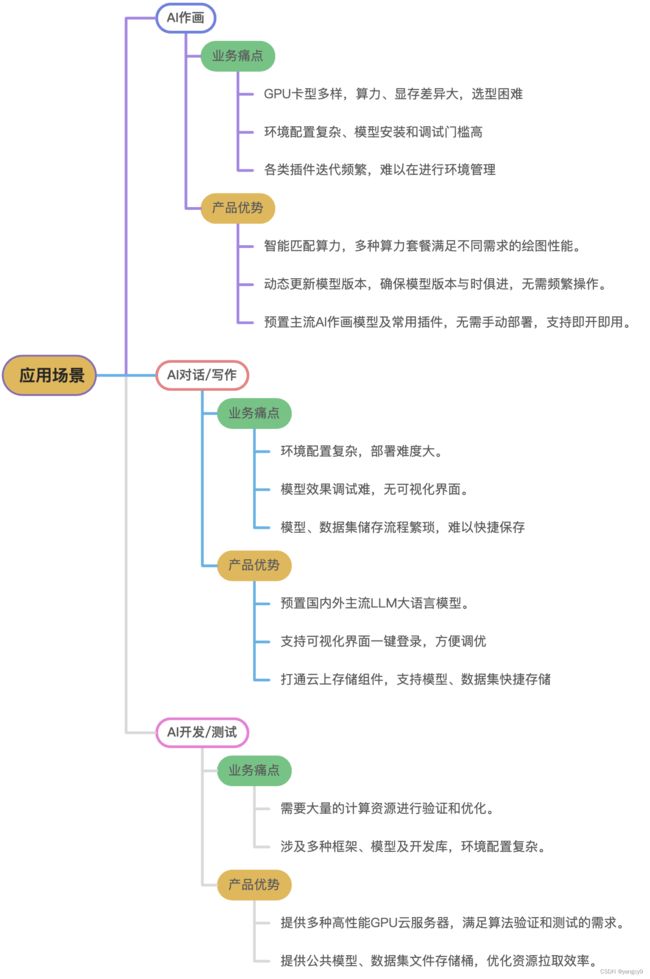
应用场景
多种高性能应用部署场景,轻松拿捏
开启HAI新篇章
接下来就让我们一步一步的创建 StableDifusion ,并基于StableDifusion API 来辅助完成我们的
动物大联盟的游戏吧!!!!
申请高性能应用服务 HAI
点击链接 , 访问高性能应用服务 HAI 的资格申请页面, 并点击 申请资格 按钮, 填写信息并提交, 等待审核通过即可哦!
资格审核通过后,点击前往体验HAI 就可以开始你的AI 之旅啦~~~~
创建实例
点击新建 按钮 , 进入 高性能应用服务 HAI
配置选择
| 名称 | 选择内容 |
|---|---|
| 选择应用 | AI模型 =》 Stable Diffusion |
| 地域 | 广州 |
| 算力方案 | 基础型 |
| 实例名称 | autoModel(这里自定义或者不填均可) |
| 网络 | 每台实例免费提供500GB流量包,默认5Mbps带宽,每月刷新 |
| 协议 | 勾选协议 |
详细如下图所示
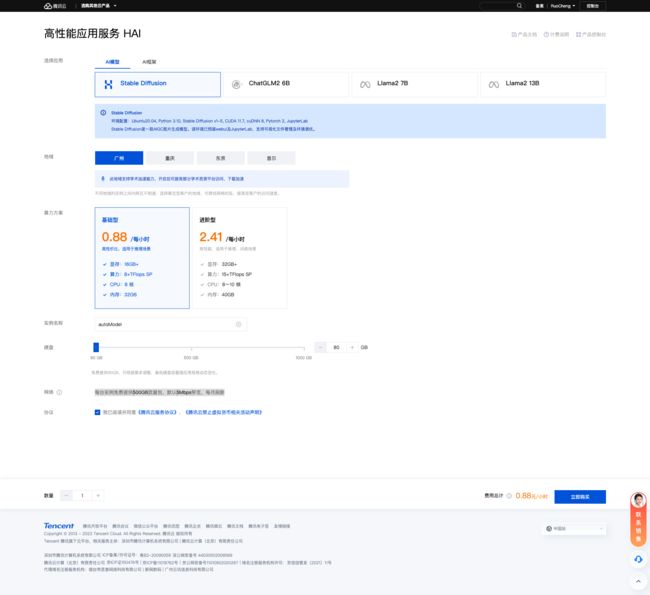
配置完成后点击
立即选购即可
实例介绍
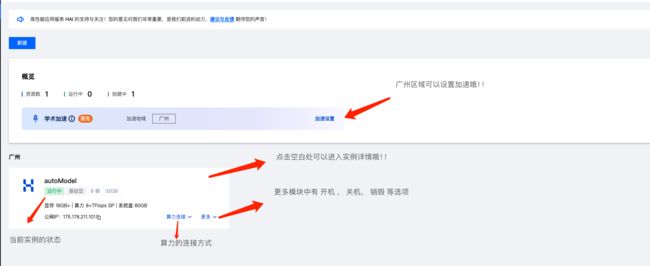
模型介绍
大模型/底模型-属于基础模型也叫预调模型, Stable Diffusion必须搭配基础模型才能使用。不同的基础模型,其画风和擅长的领域会有侧重。
本次实例我们采用的是 Checkpoint模型下的 DreamShaper
模型说明:DreamShaper模型可以 胜任多种风格(写实、原画、2.5D 等),能生成很棒的人像和风景图。
效果如下:

当然还有很多其他的模型, 可以下载使用
模型下载地址: 点击按钮去下载
上传DreamShaper和MeinaMix模型
点击算力连接 选择
JupyterLab
将我们准备好的模型 放在如下目录中 [root/stable-diffusion-webui/models/Stable-diffusion]
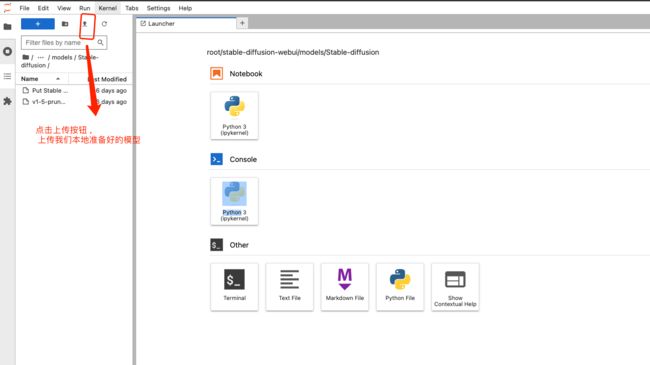
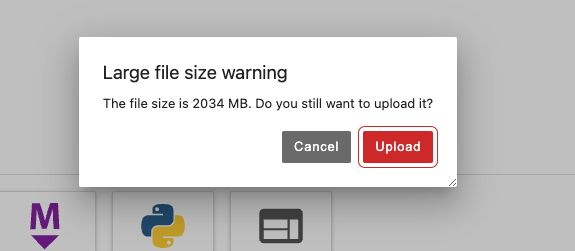
如下图所示 , 点击
Upload即可, 等待上传完成大约需要20min 左右
模型对比
DreamShaper |
MeinaMix |
|---|---|
| 胜任多种风格(写实、原画、2.5D 等),能生成很棒的人像和风景图。 | 高质量二次元、人物模型 |
点击Gradio WebUl 查看模型是否生效
如下图所示 选择
Gradio WebUl

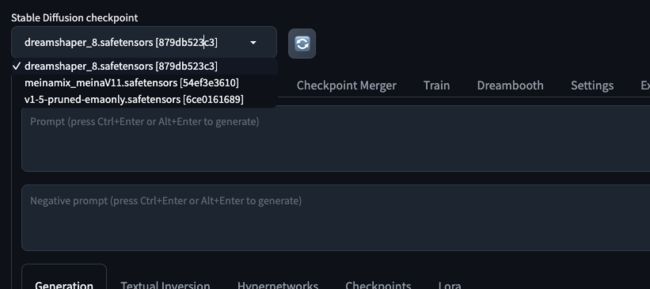
进入到WebUI 之后 检查模型是否可以正常加载 ,
如下图所示 我们自己的模型可以成功的加载进来了, 我们选择该模型即可
模型对比
我们用相同的提示词来看下不同模型,所绘制的图片的区别, 以便于我们接下来的游戏开发
提示词如下:
Naruto con un rasengan en una mano en el estilo de tattoo ,new school, anime
| v1-5-pruned-emaonly.safetensors | dreamshaper_8.safetensors | MeinaMix |
|---|---|---|
 |
 |
 |
通过对比我们发现dreamshaper模型生成的图可能会更好一些, 接下来我们就使用该模型来绘制我们所需的素材
获取游戏所需的UI图
接下来我们通过微调来获取所需的游戏UI 图
| 提示词 | 图片 |
|---|---|
| Cartoon character a white cat with a silver coat and sparkling blue eyes, the coat is sprinkled with glitter dust, a magic tail of sequins, full - length, Ghibli_ Studio meets Disney Style | |
| very cute for a cute puppy, digital art, highly detailed, rim light, exquisite lighting, clear focus, very coherent, details visible, soft lighting, character design, concept, atmospheric, fluffy, vibrant colors, trending on artstation, foggy, sun flare,light teal, Photorealistic |  |
| Generate a cute Sheep OF THE FARM illustration, resolution, cartoon-sticker style with clear lines on a pure white background suitable for a children’s coloring book. |  |
| cartoon single 3d elephant is talking very fast and lip syncing and shaking neck |  |
| cute monkey for a toddler’s, big cute eyes, pixar style, simple outline and shapes, coloring page black and white, flat vector, white background, clean line art, simple, only lines |  |
| Create a cute baby sparrow with cute eyes, looking in front of the camera and smiling in 3d |  |
| cartoon mouse in sitting position and happily laughing |  |
| Adorable little blue creature, big head, white tummy, round tummy, cute, orange fins, in the water, on a beach, smiling, digital painting |  |
| A cute baby pheonix, blue and yellow, 8k, anime, transparent background |  |
游戏开发
效果展示
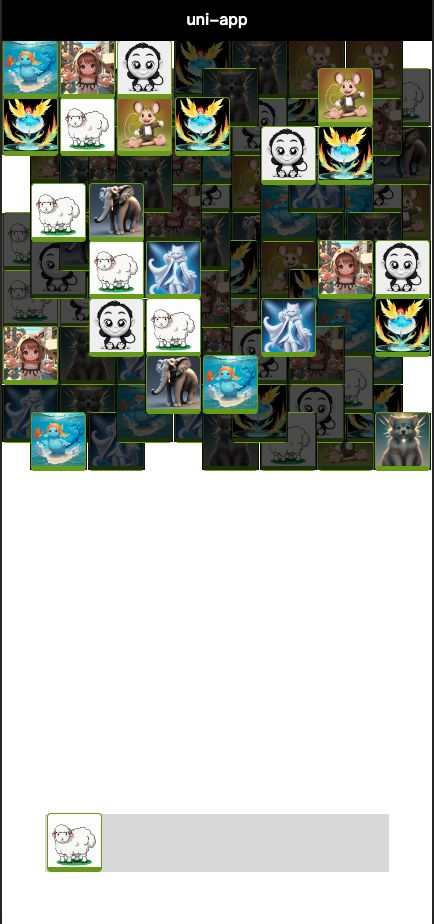 |
 |
|---|---|
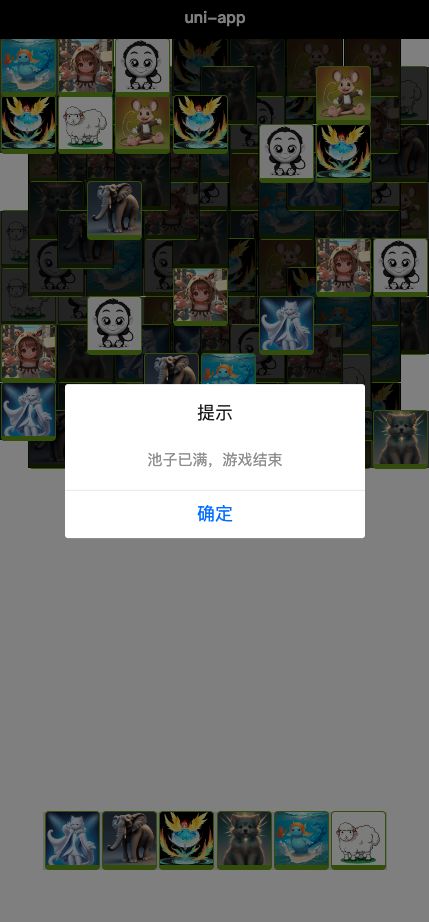 |
 |
核心代码展示
布局展示
核心代码
init() {
this.moveData = [];
const cellHtml = [];
//整理
let renderData = Array.from(new Array(this.oneGroupCount * this.group))
.map((v) => {
return this.simpleData.map((v) => ({ ...v }));
})
.flat()
.sort((v) => Math.random() - 0.5); //加上flat是为了把二维的拉成一维的 //最后用随机数打乱一下
//第一步画表格
//先绘制 最上面一层 然后 从顶层到底层绘制 进行行和列的 数据循环
for (let ly = this.layerCount - 1; ly >= 0; ly--) {
for (let i = 0; i < this.rows; i++) {
for (let j = 0; j < this.cols; j++) {
let pyStep = (ly + 1) % 2 === 0 ? this.size / 2 : 0; //给偏移量和不给偏移量 实现错开的效果
//进行 图层的渲染 id 是必要的 这个定义了 第几层ly 第几行 i 第几列j 可以判断这个卡片有没有被盖住
//最终 我们会以绝对定位的方式 进行 布局
//整个随机数
let item = Math.random() > 0.7 && renderData.pop(); //取完随机数 然后用pop 随用 随删 直到没有为止
item &&
cellHtml.push({
ly: ly,
i: i,
j: j,
left: this.size * j + pyStep,
top: this.size * i + pyStep,
id: "m" + ly + "-" + i + "-" + j,
name: item.name,
src: item.src,
isMove: false,
});
}
}
}
this.cellHtml = cellHtml.reverse();
console.log(this.cellHtml.length);
this.checkDisabled();
},
checkDisabled() {
this.cellHtml.forEach((v, index) => {
const arr = v.id
.substring(1)
.split("-")
.map((v) => Number(v));
const isPy = (arr[0] + 1) % 2 === 0;
for (let i = arr[0] + 1; i <= this.layerCount - 1; i++) {
const isPyB = (i + 1) % 2 === 0;
if (isPy === isPyB) {
let el = this.cellHtml.find((item) => {
return item.id === "m" + i + "-" + arr[1] + "-" + arr[2];
});
if (el) {
v.disabled = true;
break;
}
} else if (isPy && !isPyB) {
[
`${i}-${arr[1]}-${arr[2]}`,
`${i}-${arr[1]}-${arr[2] + 1}`,
`${i}-${arr[1] + 1}-${arr[2]}`,
`${i}-${arr[1] + 1}-${arr[2] + 1}`,
].every((k) => {
let el = this.cellHtml.find((item) => {
return item.id === "m" + k;
});
return !el;
});
if (
![
`${i}-${arr[1]}-${arr[2]}`,
`${i}-${arr[1]}-${arr[2] + 1}`,
`${i}-${arr[1] + 1}-${arr[2]}`,
`${i}-${arr[1] + 1}-${arr[2] + 1}`,
].every((k) => {
let el = this.cellHtml.find((item) => {
return item.id === "m" + k;
});
return !el;
})
) {
v.disabled = true;
break;
} else {
v.disabled = false;
}
} else if (!isPy && isPyB) {
if (
![
`${i}-${arr[1]}-${arr[2]}`,
`${i}-${arr[1]}-${arr[2] - 1}`,
`${i}-${arr[1] - 1}-${arr[2]}`,
`${i}-${arr[1] - 1}-${arr[2] - 1}`,
].every((k) => {
let el = this.cellHtml.find((item) => {
return item.id === "m" + k;
});
return !el;
})
) {
v.disabled = true;
break;
} else {
v.disabled = false;
}
}
}
});
},
代码解析
init()函数:
this.moveData = [];:初始化一个空数组moveData,用于存储移动的数据。const cellHtml = [];:创建一个空数组cellHtml,用于存储卡片的HTML元素。- 整理渲染数据:使用
Array.from(new Array(this.oneGroupCount * this.group))创建一个长度为oneGroupCount * group的数组,并对每个元素进行处理。
.map((v) => { return this.simpleData.map((v) => ({ ...v })); }):将simpleData数组中的每个对象进行浅拷贝,并将整个数组复制oneGroupCount * group次。.flat():将二维数组转换为一维数组。.sort((v) => Math.random() - 0.5):使用sort()方法对数组进行随机排序。
- 绘制表格布局:
- 使用两层循环,外层循环根据图层数量从最上面一层开始,内层循环遍历行和列。
- 计算偏移量
pyStep,并根据当前坐标和偏移量计算出卡片的位置信息。 - 在随机数中取出元素,如果存在则将其添加到
cellHtml数组中。
- 反转并赋值:将
cellHtml数组进行反转并赋值给this.cellHtml,然后调用checkDisabled()函数进行禁用状态的检查。
checkDisabled()函数:
- 遍历
cellHtml数组,对于每个卡片,根据其ID解析出图层、行和列的索引。 - 对于奇数图层:查找下一图层中与当前卡片位置相同的元素,如果找到了,则将当前卡片的
disabled属性设置为true,并跳出内层循环。 - 对于偶数图层:同时检查四个相邻位置的卡片是否存在。通过构建四个相邻位置的ID字符串,并通过
every()方法判断这四个位置是否都不存在卡片,如果存在卡片则将当前卡片的disabled属性设置为true,并跳出内层循环。
完成禁用状态的检查后,每个卡片的disabled属性都会被设置为相应的值。
整体上来看的话很难,其实一点也不简单哦!!
完整代码已上传Coding 喽!!
开发完成
完成开发之后 记得回到HAI 中 销毁或者关机实例哦!
总结
通过从创建到实际完成项目的流程来进行探讨,
HAI 还是可以满足我们大部分需求的, 我们可以上传自己想要的模型来绘制不同风格的图片,同时在开发的过程中你不会感觉到它很难 , 可以说是非常的丝滑, 这一点大大的节省了开发者的学习成本, 点赞
但是在开发过程中其实也存在一些小问题, 比如 如果我想使用自己上传的模型来对接API 应该如何操作呢 ?
这一块是否可以封装出来,然后用户可以通过自定义配置来进行接口的对接,
其次对于prompt 提示词的微调其实也是一个很费时间的过程, 当然目前这里大部分都需要开发者自己去进行微调, 我在想是否可以通过某种方式来节省这个时间呢, 比如说 用户可以输入关键词, 然后给出关键词所组合的Prompt 然后用户通过这点来进行微调可能会更好些 。