《PySpark大数据分析实战》-04.了解Spark
博主简介
- 作者简介:大家好,我是wux_labs。
热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。
通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP)、TiDB数据库认证SQL开发专家(PCSD)认证。
通过了微软Azure开发人员、Azure数据工程师、Azure解决方案架构师专家认证。
对大数据技术栈Hadoop、Hive、Spark、Kafka等有深入研究,对Databricks的使用有丰富的经验。- 个人主页:wux_labs,如果您对我还算满意,请关注一下吧~
- 个人社区:数据科学社区,如果您是数据科学爱好者,一起来交流吧~
- 请支持我:欢迎大家 点赞+收藏⭐️+吐槽,您的支持是我持续创作的动力~
《PySpark大数据分析实战》-04.了解Spark
- 《PySpark大数据分析实战》-04.了解Spark
-
- 前言
- 了解Spark
-
- Spark是什么
- Spark的发展历程
- Spark的特点
- Spark的生态系统
- Spark的部署模式
- Spark的运行架构
- 结束语
《PySpark大数据分析实战》-04.了解Spark
前言
大家好!今天为大家分享的是《PySpark大数据分析实战》第1章第4节的内容:了解Spark。
图书在:当当、京东、机械工业出版社以及各大书店有售!
了解Spark
在Hadoop 1.x版本的时候采用的是MRv1版本的MapReduce编程模型,包括3个部分:运行时环境(JobTracker和TaskTracker)、编程模型(MapReduce)、数据处理引擎(MapTask和ReduceTask)。但是MRv1存在以下不足:
1)可扩展性差。在运行时,JobTracker既负责资源管理,又负责任务调度,当集群繁忙时JobTracker很容易成为瓶颈,最终导致它的可扩展性问题。
2)可用性差。采用了单节点的Master,没有备用Master及选举操作,这就存在单点故障的问题,一旦Master出现故障,整个集群将不可用。
3)资源利用率低。TaskTracker使用slot来划分节点上的CPU、内存等资源,并将空闲的slot分配给Task使用,一个Task只有在获得slot后才有机会进行运行。但是一些Task并不能充分利用获得的slot,导致slot有空闲,而其他Task又无法使用这些空闲资源。
Apache为了解决MRv1中的缺陷,对Hadoop进行了升级改造及重构,就有了MRv2。MRv2重构了MRv1中的运行时环境,将原来的JobTracker拆分成了:集群资源调度平台(ResourceManager)、节点资源管理者(NodeManager)、任务管理者(ApplicationMaster),这就是后来Hadoop中的YARN。除了运行时环境,编程模型和数据处理引擎变成了可插拔的,可以用其他框架模型来替换,比如Spark。
Spark是什么
官方网站表明Spark是一个用于大规模数据(Large-scala Data)分析的统一引擎(Unified Engine),Unified engine for large-scale data analytics。Apache Spark™是一个多语言引擎,用于在单节点机器或集群上执行数据工程、数据科学和机器学习,Apache Spark™ is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters。如图所示。

Spark最早源于由加州大学柏克莱分校的Matei Zaharia等人发表的一篇论文Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing。Spark借鉴了MapReduce的思想,保留了分布式并行计算的优点并改进了其明显的缺陷,对MapReduce做了大量的优化,例如减少磁盘I/O、增加并行度、避免重新计算、内存计算及灵活的内存管理策略等。Spark提出了一种弹性分布式数据集(Resilient Distributed Datasets,RDD)的概念,RDD是一种分布式内存数据抽象,使得程序员能够在大规模集群中做内存运算,并且有一定的容错方式,而这也是整个Spark的核心数据结构,Spark整个平台都围绕着RDD进行。中间数据存储在内存中提高了运行速度,并且Spark提供丰富的操作数据的API,提高了开发速度。
Spark是如何处理数据的?Spark会将HDFS上文件的每个数据块读取为RDD的一个分区(Partition),每个分区会启动一个计算任务(Task),以实现大规模数据集的并行计算,过程如图所示。
Spark是一款分布式内存计算的统一分析引擎,其特点就是对任意类型的数据进行自定义计算,可以计算结构化、半结构化、非结构化等各种类型的数据结构。Spark的适用面比较广,所以被称为统一的分析引擎,他同时支持使用Python、Java、Scala、R以及SQL语言去开发应用程序处理数据。
Spark的发展历程
Spark在2009年作为加州大学伯克利分校AMPLab(Algorithms Machines and People Lab)的一个研究项目而问世。Spark的目标是打造一个全新的针对快速迭代处理(如机器学习和交互式数据分析)进行过优化的框架,与此同时保留Hadoop MapReduce的可扩展性和容错能力。2010年6月发表了第一篇论文Spark: Cluster Computing with Working Sets,并且通过BSD许可协议正式对外开源发布Spark。2013年6月,Spark在Apache Software Foundation (ASF)进入孵化状态,并于2014年2月被确定作为Apache顶级项目之一。Spark的主要发展历程:
- 2009年,Spark由加州大学伯克利分校AMPLab实验室的研究人员开发出来。最初,它是为了解决Hadoop的内存不足和磁盘IO等问题而开发的。
- 2010年,Spark第一篇论文发布,Spark通过BSD许可协议正式对外开源发布。
- 2012年,Spark 0.6版本发布。
- 2014年,Spark 1.0版本发布,成为Apache顶级项目,包括Spark Core、Spark SQL、Spark Streaming和MLlib等。
- 2015年,Spark 1.3版本发布,引入了DataFrame和SparkR等新特性。
- 2016年,Spark 2.0版本发布,引入了Datasets和SparkSession等新特性。
- 2017年,Spark 2.2版本发布,引入了Structured Streaming流处理。
- 2018年,Spark 2.4版本发布,成为全球最大的开源项目。
- 2019年,Spark 3.0版本发布,支持Python 3和Scala 2.12。
- 2020年,Spark 3.1版本发布,引入了Delta Lake,提供了事务性的数据湖功能,并支持ACID事务和版本控制。
- 2022年,Spark 3.3版本发布,获得SIGMOD系统奖。
- 2023年,Spark 3.4版本发布。
Spark的特点
Spark具有运行速度快、易用性好、通用性强和随处运行等特点:
1)速度快。由于Apache Spark支持内存计算,并且通过有向无环图(DAG)执行引擎支持无环数据流,所以官方宣称其在内存中的运算速度要比Hadoop的MapReduce快100倍,在硬盘中要快10倍。Spark处理数据与MapReduce处理数据相比,有两个不同点: 其一,Spark处理数据时,可以将中间处理结果数据存储到内存中;其二,Spark提供了非常丰富的算子(API),可以做到复杂任务在一个Spark程序中完成。
2)易用性好。Spark的版本已经更新到3.4.0(截止日期2023.04.13),支持了包括 Java、Scala、Python、R和SQL语言在内的多种语言。为了兼容Spark 2.x企业级应用场景,Spark仍然持续更新Spark 2.x版本。
3)通用性强。在Spark核心基础上,Spark还提供了包括Spark SQL、Spark Streaming、MLlib 及GraphX在内的多个工具库,可以在一个应用中无缝地使用这些工具库。
4)随处运行。Spark支持多种运行方式,包括在YARN和Mesos上,也支持独立集群运行模式,同时也可以运行在云Kubernetes(Spark 2.3开始支持)和云环境上。
5)批处理/流数据。使用您的首选语言(Python、SQL、Scala、Java或R)以批处理和实时流的方式统一数据处理。
6)SQL分析。执行快速、分布式的ANSI SQL查询,用于仪表板和即席报告。运行速度比大多数数据仓库都快。
7)大规模数据科学。对PB级数据执行探索性数据分析(EDA),而无需采用缩减采样。
8)机器学习。在笔记本电脑上训练机器学习算法,并使用相同的代码扩展到数千台计算机的容错群集。
Spark的生态系统
Spark有一套自己的生态体系,以Spark为核心(Spark Core),并提供了支持SQL语句操作的Spark SQL模块、支持流式计算的Spark Streaming模块、支持机器学习的MLlib模块、支持图计算的GraphX模块。在资源调度方面,Spark支持自身独立集群的资源调度、YARN及Mesos等资源调度框架。Spark的体系架构如图所示。
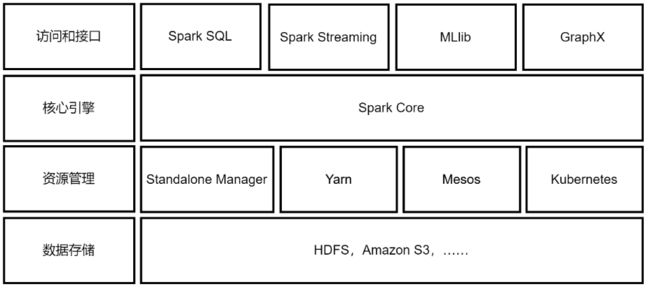
1)Spark Core。包含Spark的基本功能,包含任务调度、内存管理、容错机制等,内部采用RDD数据抽象,并提供了很多API来创建和操作这些RDD。为其他组件提供底层的服务。
2)Spark SQL。用来操作结构化数据的核心组件,通过Spark SQL可以直接查询Hive、 HBase等多种外部数据源中的数据。Spark SQL能够统一处理关系表,在处理结构化数据时,开发人员无须编写MapReduce程序,直接使用SQL命令就能完成更复杂的数据查询操作。
3)Spark Streaming。Spark提供的流式计算框架,支持高吞吐量、可容错处理的实时流式数据处理,其核心原理是将流式数据分解成一系列微小的批处理作业,每个微小的批处理作业都可以使用Spark Core进行快速处理。Spark Streaming支持多种数据来源,如文件、Socket、Kafka、Kinesis等。
4)MLlib。Spark提供的关于机器学习功能的算法程序库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能,开发人员只需了解一定的机器学习算法知识就能进行机器学习方面的开发,降低了学习成本。
5)GraphX。Spark提供的分布式图处理框架,拥有图计算和图挖掘算法的API接口以及丰富的功能和运算符,极大地方便了对分布式图的处理需求,能在海量数据上运行复杂的图算法。
Spark的部署模式
Spark提供多种部署模式,包括:
1)本地模式(单机模式)。本地模式就是以一个独立的进程,通过其内部的多个线程来模拟整个Spark运行时环境。本地模式不适合用于生产环境,仅用于本地程序开发、代码验证等。
2)独立集群模式(集群模式)。Spark中的各个角色以独立进程的形式存在,并组成Spark集群环境,这种模式下Spark自己独立管理集群的资源。
3)Spark on YARN模式(集群模式)。Spark中的各个角色运行在YARN的容器内部,并组成Spark集群环境,这种模式下Spark不再管理集群的资源,而是交给YARN进行集群资源管理。
4)Kubernetes模式(容器集群)。Spark中的各个角色运行在Kubernetes的容器内部,并组成Spark集群环境。
5)云服务模式(运行在云平台上)。Spark的商业版本Databricks就运行在谷歌、微软、亚马逊云服务提供商的云平台上。
Spark的运行架构
从物理部署层面上看,如果是独立集群模式部署的集群,则Spark主要包含两种类型的节点,Master节点和Worker节点。Master节点负责管理集群资源,分配Application到Worker节点,维护Worker节点、Driver和Application的状态。Worker节点负责具体的任务运行。如果是运行在YARN环境下,则不需要Master节点和Worker节点。
从程序运行层面上看,Spark主要有Driver和Executor。Driver充当单个Spark任务运行过程中的管理者,Executor充当单个Spark任务运行过程中的执行者。
Spark中的4类角色组成了Spark的整个运行时(Runtime)环境。这些角色与YARN中的各个角色有类似的地方。在集群资源管理层面:整个集群的管理者,在YARN中是ResourceManager,在Spark中是Master;单个节点的管理者,在YARN中是NodeManager,在Spark中是Worker。在任务执行层面:单个任务的管理者,在YARN中是ApplicationMaster,在Spark中是Driver;单个任务的执行者,在YARN中是Task,在Spark中是Executor。Spark官方提供的运行结构如图所示。
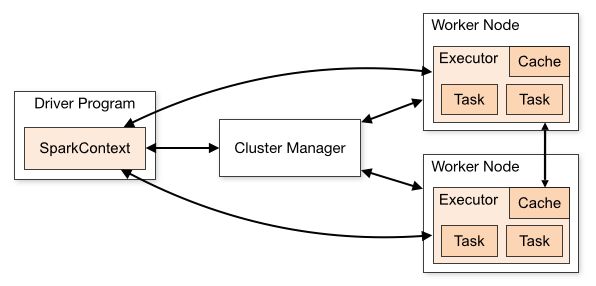
在Spark的运行结构中涉及到一些关键概念:
1)Master Node。集群中的主节点,负责集群的资源管理。
2)Worker Node。可以在集群中运行应用程序代码的任何节点。
3)Application。基于Spark构建的用户应用程序。由集群上Driver Program和Executor执行。
4)Driver Program。运行应用程序的main()函数,并创建SparkContext的过程。
5)Executor。为Worker节点上的应用程序启动的进程,用于运行任务并将数据保存在内存中或跨磁盘存储。每个Application都分配有自己的Executor。
6)Cluster Manager。用于获取、管理集群上的资源,如果是独立集群模式部署的集群则是Standalone Manager,否则就是外部服务,例如Mesos、YARN、Kubernetes。
7)Job。Spark的数据抽象是RDD,RDD提供了很多算子(API),这些算子被划分为两种类型Transformation和Action算子。Transformation算子只构建程序的执行计划,但并不会执行;Action算子的作用是触发Spark程序的真正执行。为了响应Action算子,当程序中遇到一个Action算子时,Spark会提交一个Job,用来真正执行前面的一系列操作。通常一个Application会包含多个Job,Job之间按串行方式依次执行。
8)Stage。每个Job会根据Shuffle依赖划分为更小的任务集,称为Stage(阶段),Stage之间具有依赖关系及执行的先后顺序,比如MapReduce中的map stage和reduce stage。
9)Task。Stage再细分就是Task,Task是发送给一个Executor的最细执行单元,RDD的每个Partition都会启一个Task,因此每个Stage中Task的数量就是当前Stage的并行度。
结束语
好了,感谢大家的关注,今天就分享到这里了,更多详细内容,请阅读原书或持续关注专栏。