大数据从入门到精通(超详细版)之Hive的分区表,带你理解Hive当中的高阶玩法!!!
前言
嗨,各位小伙伴,恭喜大家学习到这里,不知道关于大数据前面的知识遗忘程度怎么样了,又或者是对大数据后面的知识是否感兴趣,本文是《大数据从入门到精通(超详细版)》的一部分,小伙伴们如果对此感谢兴趣的话,推荐大家按照大数据学习路径开始学习哦。
以下就是完整的学习路径哦。
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
大数据从入门到精通文章体系!!!!!!!!!!!!!!
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
推荐大家认真学习哦!!!
前面我们学习了Hive的DDL和DML操作,接下来我们应该学习Hive的DQL(查询数据),但在这之前,我们先学习Hive的分区表概念,也是Hive当中最为重要的部分之一,大家认真学习吧!

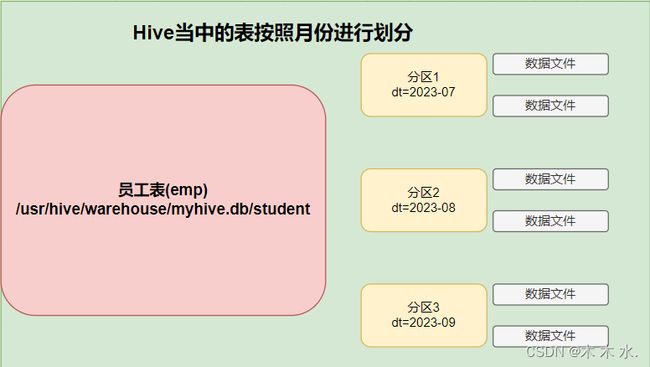
分区表
分区表的概念
我们先介绍一下什么是分区表?
在Hive中,分区表(Partitioned table)是一种 数据组织和管理方式。
它将数据按照一个或多个列的值进行逻辑上的分区。每个分区都被存储在独立的目录或文件中,从而使得数据可以更加高效地被查询和处理。
其实与HDFS的分块文件存储很相似,HDFS也是将大文件划分为多个块进行存储。
总体来说,仍然是大数据的分而治之思想,将一个大的任务或者文件划分成小的文件和任务,分散进行存储计算,从而提高当个服务器的效率,减少单个服务器的压力。
比如说,一个很大的表,存储的数据量非常大,我们可以使用分区表对其进行管理,提升后续操作的效率。
需要注意,每一个分区都是一个单独的文件夹,在物理上是严格隔离的。
创建分区表语法
语法:
create table table_name(...) partitioned by (分区列 列类型,......) row format delimited fields terminated by '';
关键字:
partitioned by:这个关键字就可以指定通过哪一列进行分区操作。
单分区表操作
首先创建员工表:
##创建一个按照月份划分的单分区员工表
create table myhive.emp
(
id string,
job string,
salary int
) partitioned by (month string) row format delimited fields terminated by '\t';
查看hdfs当中的文件夹:
hdfs dfs -ls -r /user/hive/warehouse/myhive.db
##查看表当中是否存在数据
hdfs dfs -ls -r /user/hive/warehouse/myhive.db/emp

可以看到HDFS当中的文件夹已经创建成功了,当时目前文件夹当中还没有数据。
接下来我们向emp表当中加载数据。
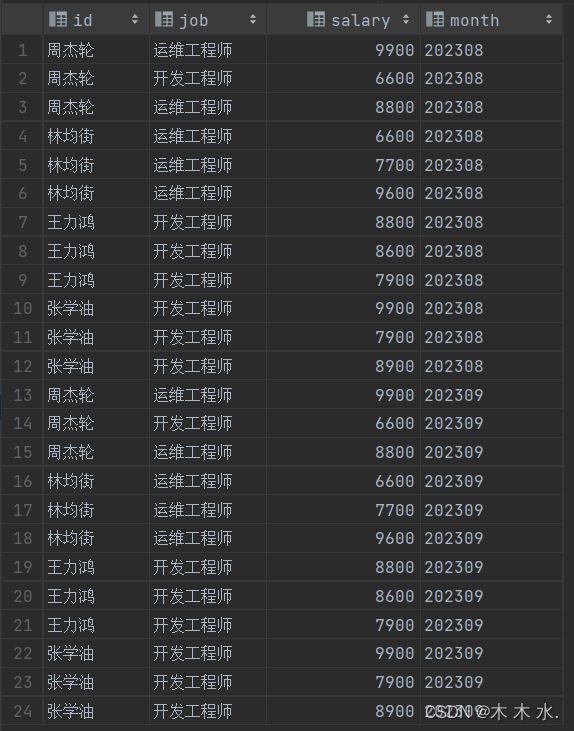
我们先准备数据,可以看到,数据当中并没有出现分区字段,因为分区字段是执行load命令才进行指定的:

接下来我们加载数据到分区表当中,注意此时要使用分区字段了。
load data local inpath '/export/test/empinfo.txt' into table myhive.emp partition (month='202309');
执行完毕后,我们发现数据已经正确的加载进表当中了,并且额外带上了一个列month

要注意:
我们这个emp表,前三个列id,job,salary数据来源于load的文件,month分区列数据来源于插入时指定的月份。
接下来我们插入另外一个月份的数据
load data local inpath '/export/test/empinfo.txt' into table myhive.emp partition (month='202308');
插入成功后,可以看到数据都已经分好区了。
再次查看HDFS文件夹当中是否存在两个分区:
hdfs dfs -ls -r /user/hive/warehouse/myhive.db/emp
可以看到,HDFS文件夹当中已经出现了两个文件了,并且是按照月份分区的文件夹。

多分区表操作
以上我们介绍了实际操作了单分区表,接下来我们进行操作多分区表。
创建一个多分区表,分区的层次分别为年,月,日
create table myhive.emp1
(
id string,
job string,
salary int
) partitioned by (year string,month string,day string) row format delimited fields terminated by '\t';
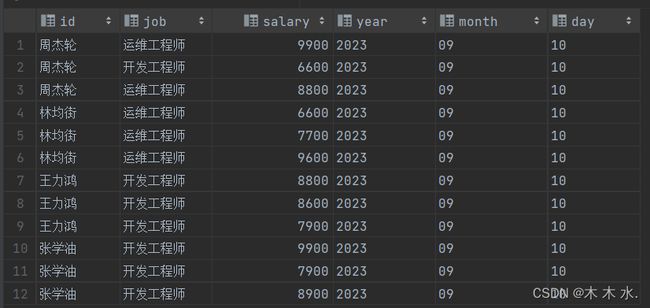
按照分区列插入数据
load data local inpath '/export/test/empinfo.txt' into table myhive.emp1 partition (year='2023',month = '09',day='10');
执行成功后,我们看一下结果,发现已经按照year,month,day分区了
接下来我们再进入HDFS当中查看文件夹的目录层级
##查看年级分区
hdfs dfs -ls -r /user/hive/warehouse/myhive.db/emp1/year=2023
##查看月级分区
hdfs dfs -ls -r /user/hive/warehouse/myhive.db/emp1/year=2023/month=09
##查看日级分区
hdfs dfs -ls -r /user/hive/warehouse/myhive.db/emp1/year=2023/month=09/day=10

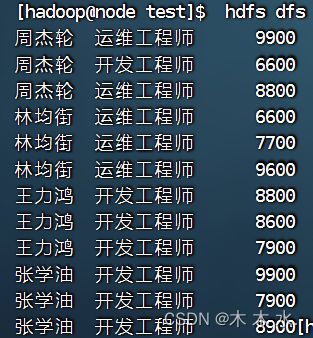
再查看文件内容
hdfs dfs -cat /user/hive/warehouse/myhive.db/emp1/year=2023/month=09/day=10/empinfo.txt
总结
在Hive中,分区表(Partitioned table)是一种数据组织和管理方式,它将数据按照一个或多个列的值进行逻辑上的分区。每个分区都被存储在独立的目录或文件中,从而使得数据可以更加高效地被查询和处理。
使用分区表可以带来以下好处:
- 数据组织结构清晰:通过按照特定列的值对数据进行分区,可以将数据组织成更加灵活和易于理解的结构。例如,可以按照日期、国家、地区等进行分区,使得数据在逻辑上具有更清晰的层次性。
- 提高查询性能:由于数据被分散存储在不同的目录或文件中,当查询时只需扫描特定的分区,而不需要扫描整张表,从而大大提高了查询性能。特别是在数据量巨大且按照分区列进行筛选查询时,分区表的性能优势尤为明显。
- 灵活的数据过滤和检索:使用分区表可以轻松地对特定分区进行数据过滤和检索。例如,仅查询某个时间范围内的数据或特定地区的数据,可以直接指定相应的分区条件,而无需扫描整个表。
- 更高效的数据加载和维护:对于大规模数据的加载和更新操作,分区表可以提供更高效的数据加载和维护方式。只需关注特定分区的数据,避免了对整个表的操作,大大减少了数据的移动和复制成本。
使用Hive创建分区表时,需要在CREATE TABLE语句中通过PARTITIONED BY子句指定分区列,然后在插入数据时,可以使用INSERT INTO ... PARTITION子句将数据插入到指定的分区中。同时,对分区表进行查询时,也可以通过WHERE子句指定特定的分区条件来实现数据过滤和检索。
结尾
恭喜小伙伴完成本篇文章的学习,相信文章的内容您已经掌握得十分清楚了,如果您对大数据的知识十分好奇,请接下来跟着学习路径完成大数据的学习哦,相信你会做到的~~~
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
大数据从入门到精通文章体系!!!!!!!!!!!!!!