Linux学习系列(六):linux系统上C程序的编译、运行及调试
目录
- 引言
- 一.文件编译及运行
-
- 1.编译过程
- 2.gcc分布编译
- 3.gcc一步编译
- 4.一步运行
- 5.make 和makefile
- 二.gdb调试
-
-
- 1.调试步骤:
- 2.调试命令:
-
- 1.l 行号
- 2.b/break
- 3.info b/break
- 4.运行代码
- 5.p 变量
- 6.结束调试
- 7.调试命令(全)
-
引言
本文介绍了Linux操作系统中关于C程序的编译,通过介绍编译过程、gcc命令、分步编译、一步编译和makefile自动化编译,详细介绍了编译的原理过程及命令。再介绍了在Linux操作系统下,应如何执行C程序,以及如何把可执行文件转化成命令。最后介绍了应如何像VS一样去逐步调试程序,并介绍了相应的命令。最后所做出的总结,希望能有所帮助.
一.文件编译及运行
1.编译过程

-
预编译阶段 :
a) 删除所有的“#define”,并且展开所有的宏定义;
b) 处理所有的条件预编译指令,“#if”、“#ifdef”、“#endif”等;
c) 处理“#include”预编译指令,将被包含的文件插入到该预编译指令的位置;
d) 删除所有的注释;
e) 添加行号和文件名标识,以便于编译器产生调试用的符号信息及编译时产生编译错 误和警告时显示行号;
f) 保留所有的#pragma 编译器指令,因为编译器需要使用它们。 -
编译阶段 :
词法分析、语法分析、语义分析,代码优化,汇总符号。
-
汇编阶段
将汇编指令翻译成二进制格式,生成各个 section,生成符号表。
-
链接阶段
a) 合并各个 section,调整 section 的起始位移和段大小,合并符号表,进行符号解析, 给符号分配虚拟地址
b) 符号重定位
2.gcc分布编译
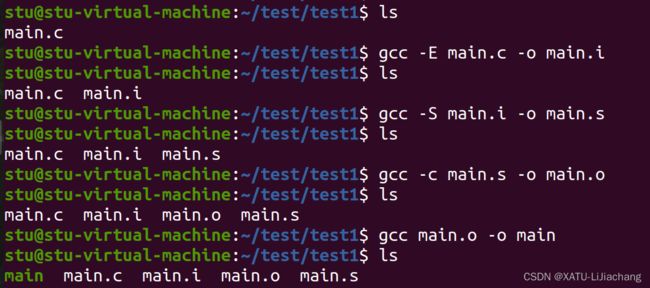
- (1) 预编译:gcc -E main.c -o main.i 生成.i文件
- (2) 编译:gcc -S main.i -o main.s 生成.s文件
- (3) 汇编:gcc -c main.s -o main.o 生成.o文件
- (4) 链接:gcc main.o -o main 生成可执行文件
注:在linux上最后生成的可执行文件main.exe变为main,无后缀
注:原有的文件都没被删除,只是生成了新的文件
3.gcc一步编译
- gcc -o main main.c :生成可执行文件main,依托main.c,也可依托多个文件
- gcc -o main main.c mul.c add.c :生成可执行文件依托多个文件

4.一步运行
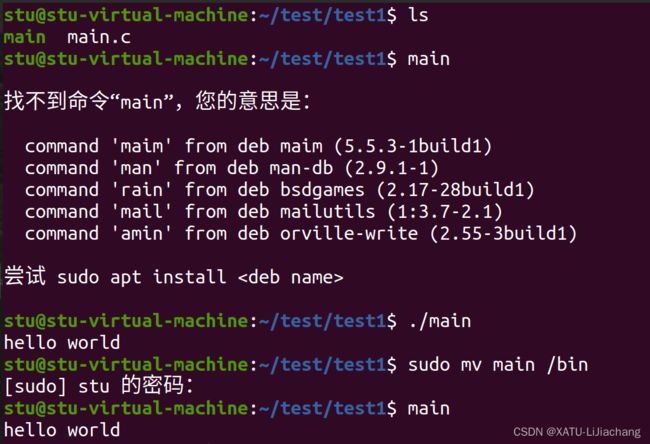
- ./main(路径文件名) 若单独使用main(文件名)则被认为是命令。从而无法运行
若想要让main发挥和ls、pwd同等作用,则可以把main文件放到/bin/路径下(存放的是命令)
5.make 和makefile
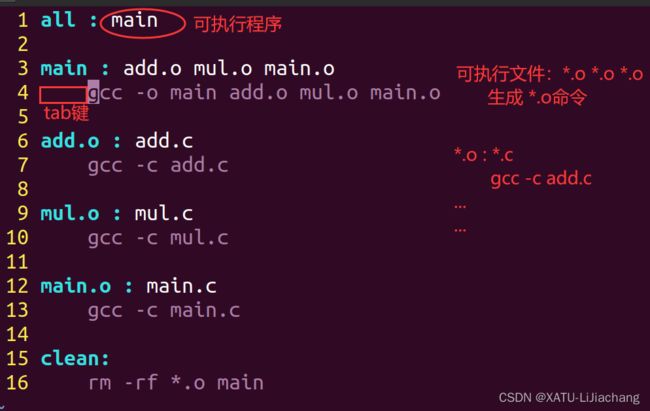
管理工程 实现自动化编译 (和 vs 比较)示例:
对 main.c add.c max.c 三个文件进行编译(注意: gcc 前面必须是 table 键缩进,或者在上一行末尾敲换行,自动缩进到table键位上)
注:文件名必须是makefile

makefile文件
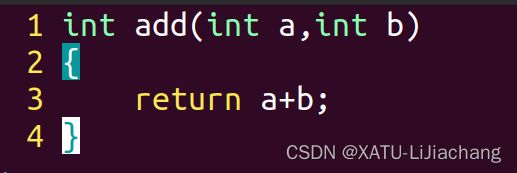
extern 关键字,链接其他文件
也可#include"add.c"

add.c
mul.c

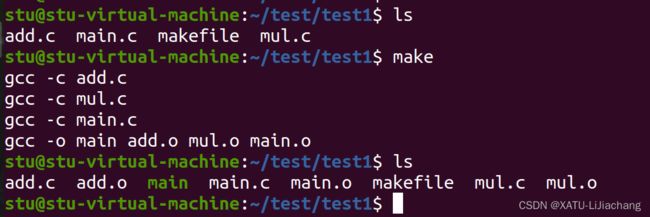
- 终端执行make命令
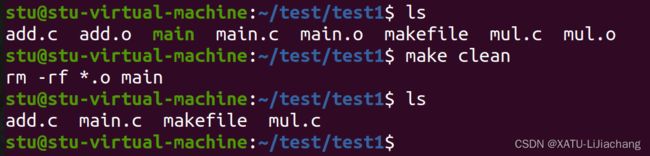
- 执行make clean命令
二.gdb调试

- gcc -o main main.c -g :生成包含调试信息的中间文件,相当于增加了可以调试的功能,原文件功能不变
1.调试步骤:
-
- gcc -o main main.c -g 切换debug
-
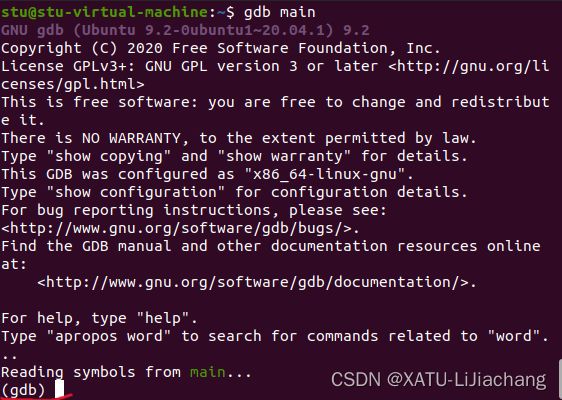
- gdb main 启动调试
-
- (gdb)出现 启动调试成功 ,可以输入命令

- 但此处代码还没运行,需下命令让其运行
2.调试命令:
1.l 行号
-
l 行号 :查看当前行号前后共10行代码
-
l :第一次使用默认查看第一行开始的10行代码,第二次使用则显示接下来的后续代码(包含上次的 l 行号)



2.b/break
- b/break 行号 :下断点

3.info b/break
- info b/break :查看断点信息

4.运行代码
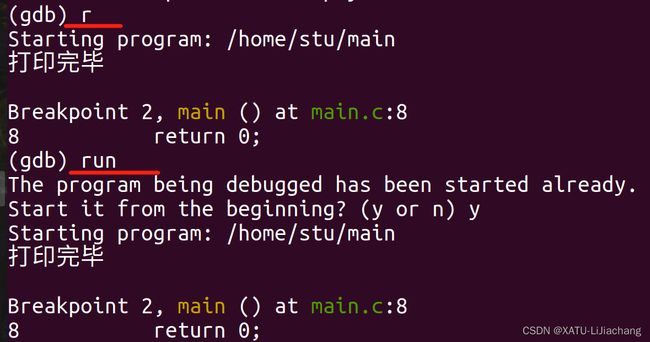
- r/run :运行代码至断点处
- n/next :逐行运行
5.p 变量
- p 变量:实时查看变量信息

6.结束调试
- q/quit :结束调试


7.调试命令(全)
1. l //显示 main 函数所在的文件的源代码
2. list 文件名:num //显示 filename 文件 num 行上下的源代码
3. b 行号 //给指定行添加断点
4. b 函数名 //给指点函数的第一有效行添加一个断点
5. info break //显示断点信息
6. delete 断点号 //删除指定断点
7. disable 断点号 //将断点设定为无效的,不加断点号,将所有断点设置为无效
8. enable 断点号 //将断点设定为有效的,不加断点号,将所有断点设置为有效
9. r(run) //运行程序
10. n(next) //单步执行
11. c (continue) //继续执行,直接执行到下一个断点处
12. s //进入将要被调用的函数中执行
13. finish //跳出函数
14. q //退出调试
15. p val //打印变量 val 的值
16. p &val //打印变量 val 的地址
17. p a+b //打印表达式的值
18. p arr(数组名) //打印数组所有元素的值
19. p *parr@len //用指向数组的指针打印数组所有元素的值
20. display //自动显示,参数和 p 命令一样
21. info display //显示自动显示信息
22. undisplay + 编号 //删除指定的自动显示
23. ptype val //显示变量类型
24. bt //显示函数调用栈