语义分割 LR-ASPP网络学习笔记 (附代码)
论文地址:https://arxiv.org/abs/1905.02244
代码地址:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_segmentation/lraspp
1.是什么?
LR-ASPP是一个轻量级语义分割网络,它是在MobileNetV3论文中提出来的,非常适合移动端部署。相比于其他语义分割网络,LR-ASPP在精度上有所牺牲,但在速度上有很大的提升。LR-ASPP的推理时间在CPU上只需要0.3秒,而且它的网络结构也非常简单。
2.为什么?
LR-ASPP 和 DeepLab V3 中的 ASPP 都是用于语义分割任务的分割解码器,但它们在一些方面有不同的创新点和设计思路。
简化结构:LR-ASPP 相对于传统的 ASPP 结构进行了简化。传统的 ASPP 通常包含多个并行的卷积分支(DeepLab v2 中有 4 个,DeepLab v3 中有 5 个),每个分支使用不同膨胀率的膨胀卷积来捕捉不同尺度的上下文信息。而 LR-ASPP 通过减少分支数量和膨胀卷积的膨胀率,降低了计算复杂性,使得模型更适合在资源受限的移动设备上使用。
节省计算资源:由于在移动设备上计算资源有限,LR-ASPP 的设计考虑了计算效率的问题。相比于 DeepLab V3 中的 ASPP,LR-ASPP 在保持一定的性能的前提下,减少了计算量,使得模型能够更好地适应移动设备的硬件限制。
高效的语义分割:LR-ASPP 在移动设备上表现出较好的分割性能。它能够有效地捕捉不同尺度的上下文信息,从而更准确地对图像中的像素进行语义分类。同时,由于其计算效率的优势,LR-ASPP 在移动设备上可以实现实时的语义分割,适用于许多实际应用场景。
总体而言,LR-ASPP 是 MobileNetV3 中的一项创新,它在计算效率和性能之间取得了良好的平衡,为移动设备上的语义分割任务提供了高效而有效的解决方案。而 DeepLab V3 中的 ASPP 则是传统 ASPP 的一种改进版本,它在大规模计算资源的情况下可以取得较好的性能。
3.怎么样?
3.1网络结构
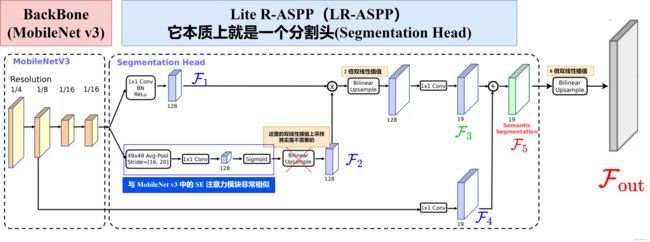
在语义分割任务中,Backbone 为 MobileNet v3,但进行了一些改动:
- Backbone 不再进行 32 倍下采样,而是仅进行 16 倍下采样
- Backbone 中最后的几个 BottleNet 中使用膨胀卷积
在一般的语义分割任务,Backbone 通常会进行 8 倍下采样,而 MobileNet v3 LR-ASPP 为了使模型更加轻量化,于是进行了 16 倍 下采样。3.2原理分析3.3代码实现
接下来我们看一下分割头(Segmentation Head),也就是 LR-ASPP。在 Backbone 输出上分成了两个分支,如上图所示:
【第一个分支】上面的分支通过一个简单的 1 × 1 卷积(bias=False)汉堡包结构,即 Conv -> BN -> ReLU,得到一个输出特征图 
【第二个分支】第二分支通过一个 核大小为 49 × 49 ,步长为 [ 16 , 20 ] 的全局平均池化层(AvgPooling Layer),之后再通过一个 1 × 1 的普通卷积(bias=False) + Sigmoid,得到一个输出特征图![]()
根据观察源码,
分支中的 Bilinear Upsample 其实是不需要的(正常来说,通过 Sigmoid 层后得到的就是长度为 128 的向量)

【第一次融合】![]() 之后,经过双线性插值进行 2 倍上采样,之后再经过普通的 1 × 1 1 \times 11×1 卷积,得到输出特征图
之后,经过双线性插值进行 2 倍上采样,之后再经过普通的 1 × 1 1 \times 11×1 卷积,得到输出特征图 
【第三个分支】将 Backbone 中经过 8 倍下采样的特征图拿出来,经过 普通的 1 × 1 卷积得到输出特征图![]()
【第二次融合】![]() ,得到 LR-ASPP 的输出特征图。
,得到 LR-ASPP 的输出特征图。
之后需要进行 8 倍双线性插值上采样得到和我输入图片一样大小的单通道图片,即![]()
3.2代码实现
mobilenet_backbone
from typing import Callable, List, Optional
import torch
from torch import nn, Tensor
from torch.nn import functional as F
from functools import partial
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class ConvBNActivation(nn.Sequential):
def __init__(self,
in_planes: int,
out_planes: int,
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
activation_layer: Optional[Callable[..., nn.Module]] = None,
dilation: int = 1):
padding = (kernel_size - 1) // 2 * dilation
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.ReLU6
super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
dilation=dilation,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer(inplace=True))
self.out_channels = out_planes
class SqueezeExcitation(nn.Module):
def __init__(self, input_c: int, squeeze_factor: int = 4):
super(SqueezeExcitation, self).__init__()
squeeze_c = _make_divisible(input_c // squeeze_factor, 8)
self.fc1 = nn.Conv2d(input_c, squeeze_c, 1)
self.fc2 = nn.Conv2d(squeeze_c, input_c, 1)
def forward(self, x: Tensor) -> Tensor:
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = F.relu(scale, inplace=True)
scale = self.fc2(scale)
scale = F.hardsigmoid(scale, inplace=True)
return scale * x
class InvertedResidualConfig:
def __init__(self,
input_c: int,
kernel: int,
expanded_c: int,
out_c: int,
use_se: bool,
activation: str,
stride: int,
dilation: int,
width_multi: float):
self.input_c = self.adjust_channels(input_c, width_multi)
self.kernel = kernel
self.expanded_c = self.adjust_channels(expanded_c, width_multi)
self.out_c = self.adjust_channels(out_c, width_multi)
self.use_se = use_se
self.use_hs = activation == "HS" # whether using h-swish activation
self.stride = stride
self.dilation = dilation
@staticmethod
def adjust_channels(channels: int, width_multi: float):
return _make_divisible(channels * width_multi, 8)
class InvertedResidual(nn.Module):
def __init__(self,
cnf: InvertedResidualConfig,
norm_layer: Callable[..., nn.Module]):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)
layers: List[nn.Module] = []
activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU
# expand
if cnf.expanded_c != cnf.input_c:
layers.append(ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer))
# depthwise
stride = 1 if cnf.dilation > 1 else cnf.stride
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=stride,
dilation=cnf.dilation,
groups=cnf.expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer))
if cnf.use_se:
layers.append(SqueezeExcitation(cnf.expanded_c))
# project
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity))
self.block = nn.Sequential(*layers)
self.out_channels = cnf.out_c
self.is_strided = cnf.stride > 1
def forward(self, x: Tensor) -> Tensor:
result = self.block(x)
if self.use_res_connect:
result += x
return result
class MobileNetV3(nn.Module):
def __init__(self,
inverted_residual_setting: List[InvertedResidualConfig],
last_channel: int,
num_classes: int = 1000,
block: Optional[Callable[..., nn.Module]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None):
super(MobileNetV3, self).__init__()
if not inverted_residual_setting:
raise ValueError("The inverted_residual_setting should not be empty.")
elif not (isinstance(inverted_residual_setting, List) and
all([isinstance(s, InvertedResidualConfig) for s in inverted_residual_setting])):
raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d, eps=0.001, momentum=0.01)
layers: List[nn.Module] = []
# building first layer
firstconv_output_c = inverted_residual_setting[0].input_c
layers.append(ConvBNActivation(3,
firstconv_output_c,
kernel_size=3,
stride=2,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
# building inverted residual blocks
for cnf in inverted_residual_setting:
layers.append(block(cnf, norm_layer))
# building last several layers
lastconv_input_c = inverted_residual_setting[-1].out_c
lastconv_output_c = 6 * lastconv_input_c
layers.append(ConvBNActivation(lastconv_input_c,
lastconv_output_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
self.features = nn.Sequential(*layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.classifier = nn.Sequential(nn.Linear(lastconv_output_c, last_channel),
nn.Hardswish(inplace=True),
nn.Dropout(p=0.2, inplace=True),
nn.Linear(last_channel, num_classes))
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def _forward_impl(self, x: Tensor) -> Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def mobilenet_v3_large(num_classes: int = 1000,
reduced_tail: bool = False,
dilated: bool = False) -> MobileNetV3:
"""
Constructs a large MobileNetV3 architecture from
"Searching for MobileNetV3" .
weights_link:
https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth
Args:
num_classes (int): number of classes
reduced_tail (bool): If True, reduces the channel counts of all feature layers
between C4 and C5 by 2. It is used to reduce the channel redundancy in the
backbone for Detection and Segmentation.
dilated: whether using dilated conv
"""
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
dilation = 2 if dilated else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride, dilation
bneck_conf(16, 3, 16, 16, False, "RE", 1, 1),
bneck_conf(16, 3, 64, 24, False, "RE", 2, 1), # C1
bneck_conf(24, 3, 72, 24, False, "RE", 1, 1),
bneck_conf(24, 5, 72, 40, True, "RE", 2, 1), # C2
bneck_conf(40, 5, 120, 40, True, "RE", 1, 1),
bneck_conf(40, 5, 120, 40, True, "RE", 1, 1),
bneck_conf(40, 3, 240, 80, False, "HS", 2, 1), # C3
bneck_conf(80, 3, 200, 80, False, "HS", 1, 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1, 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1, 1),
bneck_conf(80, 3, 480, 112, True, "HS", 1, 1),
bneck_conf(112, 3, 672, 112, True, "HS", 1, 1),
bneck_conf(112, 5, 672, 160 // reduce_divider, True, "HS", 2, dilation), # C4
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1, dilation),
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1, dilation),
]
last_channel = adjust_channels(1280 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
def mobilenet_v3_small(num_classes: int = 1000,
reduced_tail: bool = False,
dilated: bool = False) -> MobileNetV3:
"""
Constructs a large MobileNetV3 architecture from
"Searching for MobileNetV3" .
weights_link:
https://download.pytorch.org/models/mobilenet_v3_small-047dcff4.pth
Args:
num_classes (int): number of classes
reduced_tail (bool): If True, reduces the channel counts of all feature layers
between C4 and C5 by 2. It is used to reduce the channel redundancy in the
backbone for Detection and Segmentation.
dilated: whether using dilated conv
"""
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
dilation = 2 if dilated else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride, dilation
bneck_conf(16, 3, 16, 16, True, "RE", 2, 1), # C1
bneck_conf(16, 3, 72, 24, False, "RE", 2, 1), # C2
bneck_conf(24, 3, 88, 24, False, "RE", 1, 1),
bneck_conf(24, 5, 96, 40, True, "HS", 2, 1), # C3
bneck_conf(40, 5, 240, 40, True, "HS", 1, 1),
bneck_conf(40, 5, 240, 40, True, "HS", 1, 1),
bneck_conf(40, 5, 120, 48, True, "HS", 1, 1),
bneck_conf(48, 5, 144, 48, True, "HS", 1, 1),
bneck_conf(48, 5, 288, 96 // reduce_divider, True, "HS", 2, dilation), # C4
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1, dilation),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1, dilation)
]
last_channel = adjust_channels(1024 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
LR-ASPP
from collections import OrderedDict
from typing import Dict
import torch
from torch import nn, Tensor
from torch.nn import functional as F
from .mobilenet_backbone import mobilenet_v3_large
class IntermediateLayerGetter(nn.ModuleDict):
"""
Module wrapper that returns intermediate layers from a model
It has a strong assumption that the modules have been registered
into the model in the same order as they are used.
This means that one should **not** reuse the same nn.Module
twice in the forward if you want this to work.
Additionally, it is only able to query submodules that are directly
assigned to the model. So if `model` is passed, `model.feature1` can
be returned, but not `model.feature1.layer2`.
Args:
model (nn.Module): model on which we will extract the features
return_layers (Dict[name, new_name]): a dict containing the names
of the modules for which the activations will be returned as
the key of the dict, and the value of the dict is the name
of the returned activation (which the user can specify).
"""
_version = 2
__annotations__ = {
"return_layers": Dict[str, str],
}
def __init__(self, model: nn.Module, return_layers: Dict[str, str]) -> None:
if not set(return_layers).issubset([name for name, _ in model.named_children()]):
raise ValueError("return_layers are not present in model")
orig_return_layers = return_layers
return_layers = {str(k): str(v) for k, v in return_layers.items()}
# 重新构建backbone,将没有使用到的模块全部删掉
layers = OrderedDict()
for name, module in model.named_children():
layers[name] = module
if name in return_layers:
del return_layers[name]
if not return_layers:
break
super(IntermediateLayerGetter, self).__init__(layers)
self.return_layers = orig_return_layers
def forward(self, x: Tensor) -> Dict[str, Tensor]:
out = OrderedDict()
for name, module in self.items():
x = module(x)
if name in self.return_layers:
out_name = self.return_layers[name]
out[out_name] = x
return out
class LRASPP(nn.Module):
"""
Implements a Lite R-ASPP Network for semantic segmentation from
`"Searching for MobileNetV3"
`_.
Args:
backbone (nn.Module): the network used to compute the features for the model.
The backbone should return an OrderedDict[Tensor], with the key being
"high" for the high level feature map and "low" for the low level feature map.
low_channels (int): the number of channels of the low level features.
high_channels (int): the number of channels of the high level features.
num_classes (int): number of output classes of the model (including the background).
inter_channels (int, optional): the number of channels for intermediate computations.
"""
__constants__ = ['aux_classifier']
def __init__(self,
backbone: nn.Module,
low_channels: int,
high_channels: int,
num_classes: int,
inter_channels: int = 128) -> None:
super(LRASPP, self).__init__()
self.backbone = backbone
self.classifier = LRASPPHead(low_channels, high_channels, num_classes, inter_channels)
def forward(self, x: Tensor) -> Dict[str, Tensor]:
input_shape = x.shape[-2:]
features = self.backbone(x)
out = self.classifier(features)
out = F.interpolate(out, size=input_shape, mode="bilinear", align_corners=False)
result = OrderedDict()
result["out"] = out
return result
class LRASPPHead(nn.Module):
def __init__(self,
low_channels: int,
high_channels: int,
num_classes: int,
inter_channels: int) -> None:
super(LRASPPHead, self).__init__()
self.cbr = nn.Sequential(
nn.Conv2d(high_channels, inter_channels, 1, bias=False),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True)
)
self.scale = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(high_channels, inter_channels, 1, bias=False),
nn.Sigmoid()
)
self.low_classifier = nn.Conv2d(low_channels, num_classes, 1)
self.high_classifier = nn.Conv2d(inter_channels, num_classes, 1)
def forward(self, inputs: Dict[str, Tensor]) -> Tensor:
low = inputs["low"]
high = inputs["high"]
x = self.cbr(high)
s = self.scale(high)
x = x * s
x = F.interpolate(x, size=low.shape[-2:], mode="bilinear", align_corners=False)
return self.low_classifier(low) + self.high_classifier(x)
def lraspp_mobilenetv3_large(num_classes=21, pretrain_backbone=False):
# 'mobilenetv3_large_imagenet': 'https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth'
# 'lraspp_mobilenet_v3_large_coco': 'https://download.pytorch.org/models/lraspp_mobilenet_v3_large-d234d4ea.pth'
backbone = mobilenet_v3_large(dilated=True)
if pretrain_backbone:
# 载入mobilenetv3 large backbone预训练权重
backbone.load_state_dict(torch.load("mobilenet_v3_large.pth", map_location='cpu'))
backbone = backbone.features
# Gather the indices of blocks which are strided. These are the locations of C1, ..., Cn-1 blocks.
# The first and last blocks are always included because they are the C0 (conv1) and Cn.
stage_indices = [0] + [i for i, b in enumerate(backbone) if getattr(b, "is_strided", False)] + [len(backbone) - 1]
low_pos = stage_indices[-4] # use C2 here which has output_stride = 8
high_pos = stage_indices[-1] # use C5 which has output_stride = 16
low_channels = backbone[low_pos].out_channels
high_channels = backbone[high_pos].out_channels
return_layers = {str(low_pos): "low", str(high_pos): "high"}
backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
model = LRASPP(backbone, low_channels, high_channels, num_classes)
return model
参考:
[语义分割] LR-ASPP(MobileNet v3、轻量化、16倍下采样、膨胀卷积、ASPP、SE)
LR-ASPP论文