AIGC:大语言模型LLM的幻觉问题
引言
在使用ChatGPT或者其他大模型时,我们经常会遇到模型答非所问、知识错误、甚至自相矛盾的问题。
虽然大语言模型(LLMs)在各种下游任务中展示出了卓越的能力,在多个领域有广泛应用,但存在着幻觉的问题:即生成与用户输入不符、与先前生成的内容矛盾或与已知世界知识不符的内容。
这种现象对LLMs在现实世界场景中的可靠性构成了重大挑战。在准确率要求非常高的场景下幻觉是不可接受的,比如医疗领域、金融领域等。
目前在LLM幻觉问题上已经有无数的研究,比如关于幻觉的检测、幻觉的评估基准分类、缓解幻觉的方法等。
今天我会结合几篇有关LLM幻觉问题的综述论文,来理解LLM幻觉的分类、检测方法、评估和基准、减轻方法等。
最近的一篇是来自哈尔滨工业大学和华为的研究团队,长达49页,对有关LLM幻觉问题的最新进展来了一个全面而深入的概述。
这篇综述(下文简称:综述1)从LLM幻觉的创新分类方法出发,深入探究了可能导致幻觉的因素,并对检测幻觉的方法和基准进行了概述。

论文链接:https://arxiv.org/abs/2311.05232
另外还有一篇综述(下文简称:综述2),来自腾讯AI实验室和一些国内大学的研究团队,综述提出了LLM幻觉现象的分类法和评估基准,分析旨在减轻LLM幻觉的现有方法,并确定未来研究的潜在方向。

论文链接:https://arxiv.org/pdf/2309.01219.pdf
还有一篇有关幻觉的论文(下文简称:论文1),对各种文本生成任务中的幻觉现象进行了新的分类,从而提供了理论分析、检测方法和改进方法。

论文链接:https://arxiv.org/pdf/2309.06794v1.pdf
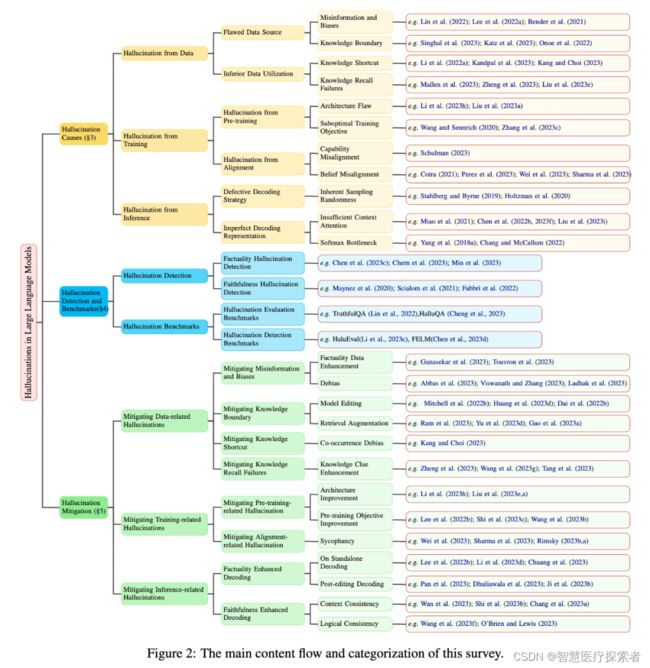
1 幻觉的分类
在综述2中,将LLMs幻觉分为三种:输入冲突幻觉、上下文冲突幻觉和事实冲突幻觉。
-
输入冲突幻觉:是指生成的内容与用户提供的输入不符;
-
上下文冲突幻觉:是指生成的内容与之前生成的信息相矛盾;
-
事实冲突幻觉:是指生成的内容与已知的世界知识不符。

 图注:3种幻觉的定义
图注:3种幻觉的定义
而在最新的综述1中,将LLM幻觉分为两种:事实型幻觉和忠实度幻觉。

如上图所示,左边是事实型幻觉:当LLM被问到谁是第一个在月球上漫步的人时,LLM编了个人物出来,甚至还说得有模有样。右边是忠实度幻觉:LLM在看到这段新闻后,直接把年份概括错了。
下图是一张更为详细的LLM幻觉种类图,包括更为细致的分类:事实型幻觉包括事实不一致、事实捏造;忠实度幻觉又包括:指令-答案的不一致、文本不一致,以及逻辑不一致。
 图注:LLM幻觉种类图
图注:LLM幻觉种类图
总的来说,结合事实、上下文、输入的不一致,幻觉的定义和分类上是相似的。
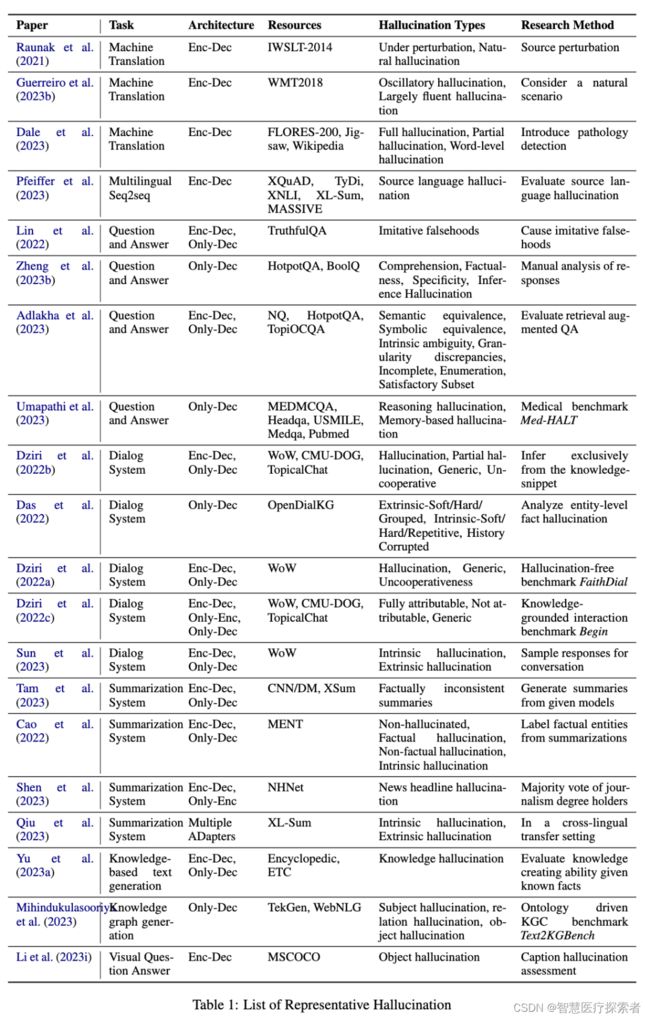
结合常见的下游任务,比如机器翻译、问答系统、对话系统、文本摘要、LLM知识图谱和视觉问答系统,论文1总结了典型的幻觉现象,如下表所示:
2 幻觉的来源
综述2认为产生幻觉的主要原因有预训练数据收集、知识GAP和大模型优化过程三个方面。
最新的综述1也深入探讨LLM产生幻觉的根本原因,主要分为三个关键方面:数据、训练和推理。
结合起来,我们具体来看下幻觉的来源:
2.1 幻觉来自数据
-
预训练数据:大模型的知识和能力主要来自与预训练数据,如果预训练数据使用了不完整或者过期的数据,那么就很可能导致知识的错误,从而引起幻觉现象。
-
数据利用:LLMs 往往会捕捉到虚假的相关性,在回忆知识(尤其是长尾信息)和复杂推理场景中表现出困难,从而进一步加剧幻觉。
2.2 幻觉来自训练
-
预训练阶段:LLMs在这一阶段学习通用表征并捕捉广泛的知识,通常采用基于transformer的架构,在庞大的语料库中进行因果语言建模。但是,固有的架构设计和研究人员所采用的特定训练策略,可能会产生与幻觉相关的问题。
-
对齐阶段:一般涉及两个主要过程,即监督微调和从人类反馈中强化学习(RLHF)。虽然对齐能显著提高 LLM 响应的质量,但也会带来产生幻觉的风险,主要分为两方面:能力不对齐(Capability Misalignment)和信念不对齐(Belief Misalignment)。
2.3 幻觉来自生成/推理
经过预训练和对齐后,解码在体现 LLM 能力方面发挥着重要作用。然而,解码策略的某些缺陷可能导致 LLM 出现幻觉。综述1深入探讨源于解码过程的潜在原因,并强调两个关键因素:
-
解码策略固有的随机性(Inherent Sampling Randomness):比如采用采样生成策略(如top-p和top-k)引入的随机性也可能导致幻觉的产生。
-
不完善的解码表示(Imperfect Decoding Representation):在解码阶段,LLM 使用顶层表示法预测下一个标记。然而,顶层表示法也有其局限性,主要表现在两个方面:上下文关注不足(Insufficient Context Attention)和Softmax瓶颈(Softmax Bottleneck)。
3 幻觉的检测
检测 LLM 中的幻觉对于确保生成内容的可靠性和可信度至关重要。传统的衡量标准主要依赖于词语重叠,无法区分可信内容和幻觉内容之间的细微差别。这样的挑战凸显了为 LLM 幻觉量身定制更复杂的检测方法的必要性。
鉴于这些幻觉的多样性,检测方法也相应地有所不同。
在综述1中,全面介绍了针对事实性幻觉和忠实性幻觉的主要幻觉检测策略。
3.1 事实性幻觉的检测
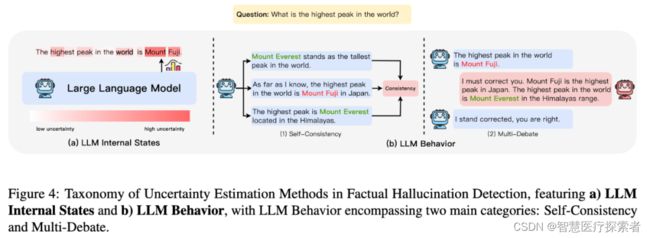
事实性幻觉的检测方法:通常分为 "检索外部事实"(Retrieve External Facts)和 "不确定性估计"(Uncertainty Estimation)。
检索外部事实:为了有效地指出 LLM 输出中的事实不准确之处,一种直观的策略是将模型生成的内容与可靠的知识来源进行比较,如下图 3 所示。

虽然许多幻觉检测方法都依赖外部知识源进行事实检查,但有几种方法可以在零资源环境下解决这一问题,从而无需检索。
这些策略背后的基本前提是,LLM 幻觉的起源本质上与模型的不确定性有关。
因此,通过对模型生成的事实内容的不确定性进行估计,就可以检测出幻觉。
不确定性估计的方法大致可分为两种:基于内部状态和 LLM 行为,如图 4 所示。前者的前提是可以访问模型的内部状态,而后者则适用于更受限制的环境,仅利用模型的可观测行为来推断其潜在的不确定性。
3.2 忠实性幻觉的检测
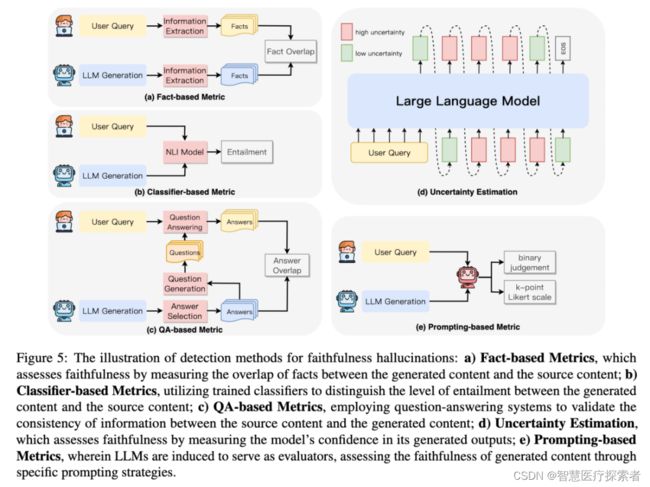
忠实性幻觉的检测方法:主要侧重于确保生成的内容与给定上下文保持一致,从而避免无关或矛盾输出的潜在隐患。如下图5探讨在 LLM 生成中检测不忠实的方法。
-
基于事实度量:通过检测生成内容与源内容之间的事实重叠度来评估忠实度。
-
基于分类器的度量:利用经过训练的分类器来区分生成内容与源内容之间的关联程度。
-
基于QA的度量方法:利用问题解答系统来验证源内容与生成内容之间的信息一致性。
-
不确定性估计:通过测量模型对其生成输出的置信度来评估忠实度。
-
基于prompt的度量方法:让LLM充当评估者,通过特定的prompt策略来评估生成内容的忠实度。
4 幻觉的评估
针对不同类型的幻觉,采用的评估方式不一样。
现有针对幻觉的工作,提出了各种基准来评估LLM中的幻觉,如下表5所示:
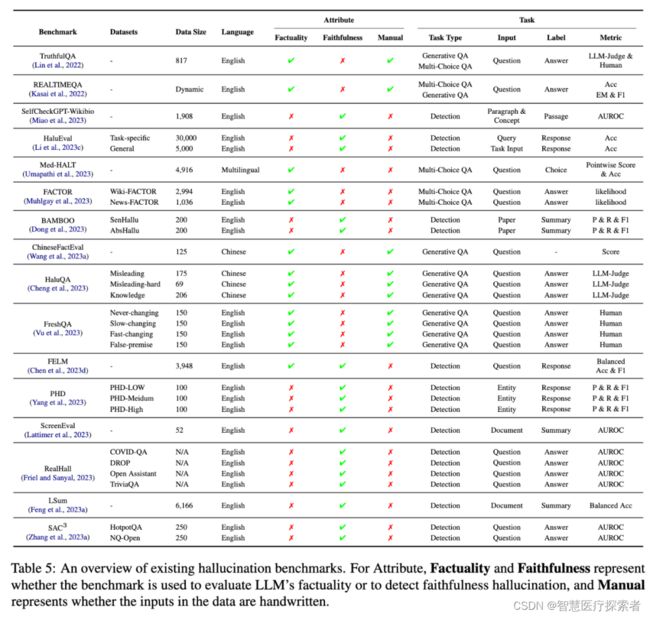
现有的基准主要根据LLMs的两种不同能力来评估幻觉:生成事实陈述或判别事实陈述与非事实陈述的能力。下表说明了这两种评估形式的区别。

-
Generation 生成式基准:将幻觉看作一种生成特征,类似于流畅度和连贯性,并对LLM生成的文本进行评估。例如,TruthfulQA用于评估大型模型对问题的回答的真实性,而FactScore则用于评估大型模型生成的个人传记的事实准确性。
-
Discrimination 判别式基准:考察大型模型区分真实陈述和幻觉陈述的能力。具体来说,HaluEval要求模型确定状态信息是否包含幻觉信息,而FACTOR则研究LLM是否更可能生成事实陈述而非非事实陈述。
在这些基准中,TruthfulQA是一种特殊的基准,兼具生成式和判别式两种基准,提供了一个多项选择的替代方案,以测试模型区分真实陈述的能力。
5 幻觉的解决
论文1总结了五种解决幻觉的方法,具体如下图所示:

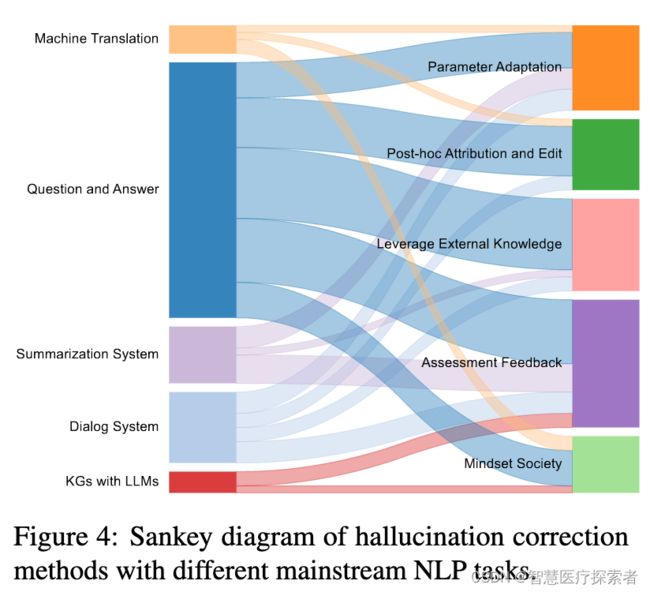
不同下游任务解决幻觉的方法不同,具体如下图所示:
在哈工大的综述1中,全面回顾了当前减轻幻觉的方法,并根据幻觉成因对这些方法进行了系统分类。
具体来说,综述1将重点放在解决与数据相关的幻觉、与训练相关的幻觉和与推理相关的幻觉的方法上,每种方法都提供了量身定制的解决方案,以应对各自原因所固有的特定挑战。