推荐系统综述--初识推荐系统(美研面试专用)
1. 引言
随着信息技术和互联网技术的发展,人们从信息匮乏时代步入了信息过载时代,在这种时代背景下,人们越来越难从大量的信息中找到自身感兴趣的信息,信息也越来越难展示给可能对它感兴趣的用户,而推荐系统的任务就是连接用户和信息,创造价值。
当用户没有明确目标时,比如寻找感兴趣的音乐,用户只能通过一些预先设定的类别或标签去寻找他可能感兴趣的音乐,但面对如此之多音乐,用户很难在短时间内找出真正感兴趣的音乐。这时就需要一个自动化的工具,来分析用户曾经收听的音乐,进而寻找出用户可能感兴趣的音乐推荐给用户,这就是个性化推荐系统的工作。
推荐系统能够更好的发掘长尾信息,即将冷门物品推荐给用户。热门物品通常代表绝大多数用户的兴趣,而冷门物品往往代表一小部分用户的个性化需求,在电商平台火热的时代,由冷门物品带来的营业额甚至超过热门物品,发掘长尾信息是推荐系统的重要研究方向。
目前,推荐系统已广泛应用于诸多领域,其中最典型的便是电子商务领域。同时,伴随着机器学习、深度学习的发展,工业界和学术界对推荐系统的研究热情更加高涨,形成了一门独立的学科。
2. 发展历史
1994 年明尼苏达大学GroupLens研究组推出第一个自动化推荐系统 GroupLens[1]。提出了将协同过滤作为推荐系统的重要技术,这也是最早的自动化协同过滤推荐系统之一。
1997 年 Resnick 等人[2]首次提出推荐系统(recommendersystem,RS)一词,自此,推荐系统一词被广泛引用,并且推荐系统开始成为一个重要的研究领域。
1998年亚马逊(Amazon.com)上线了基于物品的协同过滤算法,将推荐系统推向服务千万级用户和处理百万级商品的规模,并能产生质量良好的推荐。
2003年亚马逊的Linden等人发表论文,公布了基于物品的协同过滤算法[3],据统计推荐系统的贡献率在20%~30%之间[4]。
2005年Adomavicius 等人的综述论文[5] 将推荐系统分为3个主要类别,即基于内容的推荐、基于协同过滤的推荐和混合推荐的方法,并提出了未来可能的主要研究方向。
2006 年10月,北美在线视频服务提供商 Netflix 宣布了一项竞赛,任何人只要能够将它现有电影推荐算法 Cinematch 的预测准确度提高10%,就能获得100万美元的奖金。该比赛在学术界和工业界引起了较大的关注,参赛者提出了若干推荐算法,提高推荐准确度,极大地推动了推荐系统的发展。
2007年第一届ACM 推荐系统大会在美国举行,到2017年已经是第11届。这是推荐系统领域的顶级会议,提供了一个重要的国际论坛来展示推荐系统在不同领域的最近研究成果、系统和方法。
2016年,YouTube发表论文[6],将深度神经网络应用推荐系统中,实现了从大规模可选的推荐内容中找到最有可能的推荐结果。
近年来,推荐系统被广泛的应用于电子商务推荐、个性化广告推荐、新闻推荐等诸多领域,如人们经常使用的淘宝、今日头条、豆瓣影评等产品。
3. 研究现状
经过二十多年的积累和沉淀,推荐系统成功应用到了诸多领域,RecSys会议上最常提及的应用落地场景为:在线视频、社交网络、在线音乐、电子商务、互联网广告等,这些领域是推荐系统大展身手的舞台,也是近年来业界研究和应用推荐系统的重要实验场景。
伴随着推荐系统的发展,人们不仅仅满足于分析用户的历史行为对用户进行建模,转而研究混合推荐模型,致力于通过不同的推荐方法来解决冷启动、数据极度稀疏等问题,国内知名新闻客户端今日头条采用了内容分析、用户标签、评估分析等方法打造了拥有上亿用户的推荐引擎。
移动互联网的崛起为推荐系统提供了更多的数据,如移动电商数据[6]、移动社交数据、地理数据[7]等,成为了社交推荐的新的尝试。
随着推荐系统的成功应用,人们越来越多的关注推荐系统的效果评估和算法的健壮性、安全性等问题。2015年,Alan Said 等人在RecSys会议上发表论[8],阐述了一种清晰明了的推荐结果评价方式,同年,FrankHopfgartner等人发表论文[9],讨论了基于流式数据的离线评价方式和对照试验,掀起了推荐算法评估的研究热潮。
近年来,机器学习和深度学习等领域的发展,为推荐系统提供了方法指导。RecSys会议自2016年起开始举办定期的推荐系统深度学习研讨会,旨在促进研究和鼓励基于深度学习的推荐系统的应用。
2017年AlexandrosKaratzoglou等人在论文[10]中介绍了深度学习在推荐系统中的应用,描述了基于深度学习的内容推荐和协同过滤推荐方法,深度学习成为当前推荐系统研究的热点。
4. 推荐方式和效果评估
推荐系统在为用户推荐物品时通常有两种方式:
4.1 评分预测
此方法一般通过学习用户对物品的历史评分,预测用户可能会为他没有进行评分的物品打多少分,通常用于在线视频、音乐等服务的推荐。
评分预测的效果评估一般通过均方根误差(RMSE)和平均绝对误差(MAE)计算。对于测试集T中的一个用户u和物品i,令rui是用户u对物品i的实际评分,而ȓui是推荐系统给出的预测评分,则:
 RMSE(root mean square error): 方 均 根
RMSE(root mean square error): 方 均 根

4.2 TopN推荐
此方法一般不考虑评分,而是为用户提供一个个性化推荐列表,通过预测用户对物品的兴趣度对列表进行排序,选取其中前N个物品推荐给用户,通常用于电子商务、社交网络、互联网广告推荐。
TopN推荐一般通过准确率(precision)、召回率(recall)和F1值(平衡分数)度量。令R(u)是为用户推荐的物品列表,T(u)是用户在测试集上的行为列表。

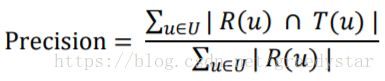

5. 推荐算法
根据推荐系统使用数据的不同,推荐算法可分为基于用户行为推荐、基于内容推荐、基于社交网络推荐等。
主流的推荐系统算法可以分为协同过滤推荐(Collaborative Filtering Recommendation)、基于内容推荐(Content-basedRecommendation)和混合推荐三种。
5.1 基于用户行为推荐
用户行为蕴藏着很多模式,著名的“啤酒和尿布”的故事就是用户行为模式的良好体现。基于用户行为推荐的主要思想是利用已有用户的历史行为数据(显式反馈或隐式反馈),预测当前用户可能感兴趣的物品,其中显式反馈主要为用户评分,隐式反馈主要包括浏览、搜索等。
基于用户行为的推荐算法也称为协同过滤算法(Collaborative Filtering Recommendation),是推荐领域应用最广泛的算法,该算法不需要预先获得用户或物品的特征数据,仅依赖于用户的历史行为数据对用户进行建模,从而为用户进行推荐。协同过滤算法主要包括基于用户的协同过滤(User-Based CF)、基于物品的协同过滤(Item-Based CF)、隐语义模型(Latent Factor Model)等。其中基于用户和物品的协同过滤是通过统计学方法对数据进行分析的,因此也称为基于内存的协同过滤或基于邻域的协同过滤;隐语义模型是采用机器学习等算法,通过学习数据得出模型,然后根据模型进行预测和推荐,是基于模型的协同过滤。
5.1.1 基于用户的协同过滤(User-Based CF)
基于用户的协同过滤(下文简称UserCF)的基本思想为:给用户推荐和他兴趣相似的用户感兴趣的物品。当需要为一个用户A(下文称A)进行推荐时,首先,找到和A兴趣相似的用户集合(用U表示),然后,把集合U中用户感兴趣而A没有听说过(未进行过操作)的物品推荐给A。算法分为两个步骤:首先,计算用户之间的相似度,选取最相似的N个用户,然后,根据相似度计算用户评分。
用户相似度计算基于用户的协同过滤算法的重要内容,主要可以通过余弦相似度、杰卡德系数等方式进行计算。
假设:给定用户u和v,令N(u)表示用户u有过正反馈的物品集合,令N(v)为用户v有过正反馈的物品集合,则用户u和v之间的相似度可以通过如下方式计算:
余弦相似度:

Jaccard相似度:
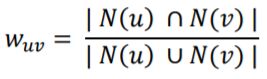
5.1.2 基于物品的协同过滤(Item-Based CF)
基于物品的协同过滤(下文简称ItemCF)是目前应用最为广泛的算法,该算法的基本思想为:给用户推荐和他们以前喜欢的物品相似的物品,这里所说的相似并非从物品的内容角度出发,而是基于一种假设:喜欢物品A的用户大多也喜欢物品B代表着物品A和物品B相似。基于物品的协同过滤算法能够为推荐结果做出合理的解释,比如电子商务网站中的“购买该物品的用户还购买了…”。
5.1.3 隐语义模型(Latent Factor Model)
隐语义模型方法是目前应用最为广泛的协同过滤算法之一,在显式反馈(如评分)推荐系统中,能够达到很好的精度。它的基本思想是通过机器学习方法从用户-物品评分矩阵中分解为两个低阶矩阵,表示对用户兴趣和物品的隐含分类特征,通过隐含特征预测用户评分。训练过程中通常采用随机梯度下降(SGD)算法最小化损失函数,最后通过模型预测用户评分。矩阵分解(Matrix Factorization)是隐语义模型最成功的一种实现。
5.2 基于内容推荐
基于内容推荐的基本思想是为用户推荐与他感兴趣的内容相似的物品,比如用户喜欢励志类电影,那么系统会直接为他推荐《阿甘正传》这部电影,这个过程综合考虑了用户兴趣和电影内容,因此不需要提供用户的历史行为数据,这能够很好地解决新用户的冷启动问题。基于内容推荐的关键问题是对用户兴趣特征和物品特征进行建模,主要方法由向量空间模型、线性分类、线性回归等。
基于内容推荐需要预先提供用户和物品的特征数据,比如电影推荐系统,需要提供用户感兴趣的电影类别、演员、导演等数据作为用户特征,还需要提供电影的内容属性、演员、导演、时长等数据作为电影的特征,这些需要进行预处理的数据在实际应用中往往有很大的困难,尤其是多媒体数据(视频、音频、图像等),在预处理过程中很难对物品的内容进行准确的分类和描述,且在数据量很大的情况下,预处理效率会很低下。针对以上不足,[25]提出了基于标签的推荐方法,可以由专家或用户为物品打标签,实现对物品的分类。
基于内容产生的推荐往往和用户已经处理的物品具有很大的相似度,不利于用户在推荐系统中获得惊喜,这也是推荐系统的一个重要研究方向。
5.3 混合推荐
推荐算法虽然都可以为用户进行推荐,但每一种算法在应用中都有不同的效果。UserCF的推荐结果能够很好的在广泛的兴趣范围中推荐出热门的物品,但却缺少个性化;ItemCF能够在用户个人的兴趣领域发掘出长尾物品,但却缺乏多样性;基于内容推荐依赖于用户特征和物品特征,但能够很好的解决用户行为数据稀疏和新用户的冷启动问题;矩阵分解能够自动挖掘用户特征和物品特征,但却缺乏对推荐结果的解释,因此,每种推荐方法都各有利弊,相辅相成。
实际应用的推荐系统通常都会使用多种推荐算法,比如使用基于内容或标签的推荐算法来解决新用户的冷启动问题和行为数据稀疏问题,在拥有了一定的用户行为数据后,根据业务场景的需要综合使用UserCF、ItemCF、矩阵分解或其他推荐算法进行离线计算和模型训练,通过采集用户的社交网络数据、时间相关数据、地理数据等综合考虑进行推荐,保证推荐引擎的个性化,提高推荐引擎的健壮性、实时性、多样性和新颖性。让推荐系统更好地为用户服务。
https://www.dataapplab.com/algorithm-principle-overview-of-recommender-systems/
6. 总结和展望
推荐系统的发展一方面精确的匹配了用户与信息,降低了人们在信息过载时代获取信息的成本,但由推荐系统主导的内容分发,如新闻推荐等,也为用户带来了消极影响。2017年9月19日,人民日报点名批评国内知名内容分发平台今日头条,强调别以技术之名糊弄网民和群众,可见推荐系统的发展不仅需要满足用户多元化、个性化的需求,而且需要对信息进行严格的监管和过滤,提高推荐系统的健壮性。近年来,RecSys会议上越来越多地收录了关于用户隐私、推荐引擎健壮性、信息过滤等方面的论文,这是未来推荐系统发展的一个重要研究方向。
目前,深度神经网络发展迅速,为推荐系统提供了新的特征提取、排序方法,越来越多的推荐引擎将深度神经网络与传统的推荐算法进行了结合,用于解决数据稀疏、推荐排序等问题,深度神经网络和推荐系统的结合将是推荐系统未来的主要研究方向。
综上所述,推荐系统是一个庞大的信息系统,它不仅仅只依赖于推荐引擎的工作,而且依赖于业务系统、日志系统等诸多方面,并结合了网络安全、数据挖掘等多个研究领域,能够为企业和用户带来价值,是一个值得深入研究的领域。
参考文献
[1] Resnick P,Iacovou N, Suchak M, et al. GroupLens: an open architecture for collaborativefiltering of netnews[C] Proceedings of the 1994 ACM Conference on ComputerSupported Cooperative Work, Oct 22-26, 1994. New York, NY, USA: ACM, 1994:175-186.
[2] Resnick P, Varian H R. Recommender systems[J].Communications of the ACM, 1997, 40(3): 56-58.
[3] G. Linden, B. Smith, and J. York, “Amazon.comRecommendations: Item-to-Item Collaborative Filtering,” IEEE InternetComputing, vol. 7, no. 1, 2003, pp. 76–80.
[4] Linden G, Smith B, York J. Amazon.comrecommendations: item-to-item collaborative filtering[J]. IEEE Internet Computing,2003, 7(1): 76-80.
[5] Adomavicius G, Tuzhilin A. Toward the nextgeneration of recommender systems: a survey of the state-of-the-art and possibleextensions[J]. IEEE Transactions on Knowledge and Data Engineering, 2005,17(6): 734-749.
[6] Cremonesi P, Tripodi A, Turrin R. Cross-DomainRecommender Systems.[C] IEEE, International Conference on Data MiningWorkshops. IEEE, 2012:496-503.
[7] Huiji Gao, Jiliang Tang, Huan Liu. Personalizedlocation recommendation on location-based social networks[J]. 2014:399-400.
[8] Said A. Replicable Evaluation of RecommenderSystems[C] ACM Conference on Recommender Systems. ACM, 2015:363-364.
[9] Hopfgartner F, Kille B, Heintz T, et al.Real-time Recommendation of Streamed Data[C] ACM Conference on RecommenderSystems. ACM, 2015:361-362.
[10] Karatzoglou A, Hidasi B. Deep Learning forRecommender Systems[C] the Eleventh ACM Conference. ACM, 2017:396-397.
[11] Simon Funk. Funk-SVD [EB/OL]. http://sifter.org/~simon/journal/20061211.html,2006-12-11
[12] 朱扬勇, 孙婧. 推荐系统研究进展[J]. 计算机科学与探索, 2015, 9(5):513-525.
[13] 杨阳, 向阳, 熊磊. 基于矩阵分解与用户近邻模型的协同过滤推荐算法[J]. 计算机应用, 2012,32(2):395-398.
[14] 项亮. 推荐系统实践[M]. 北京: 人民邮电出版社, 2012.