【机器学习】Boosting算法-梯度提升算法(Gradient Boosting)

一、原理
梯度提升算法是一种集成学习方法,它可以将多个弱分类器或回归器组合成一个强分类器或回归器,提高预测性能。梯度提升算法的核心思想是利用损失函数的负梯度作为残差的近似值,然后用一个基学习器拟合这个残差,再将其加到之前的模型上,从而不断地减小损失函数的值。梯度提升算法有以下几个特点:
梯度提升算法可以用任何可微分的损失函数,如平方误差、绝对误差、交叉熵等,这使得它比其他基于指数损失函数的算法更加灵活和通用。
梯度提升算法可以用任何基学习器,如决策树、神经网络、支持向量机等,这使得它比其他基于单一类型的基学习器的算法更加强大和多样化。
梯度提升算法可以通过调整学习率、迭代次数、树的深度等参数来控制模型的复杂度和过拟合程度,这使得它比其他缺乏正则化手段的算法更加稳定和可控。
1.1 梯度提升算法


1.2 四种梯度提升算法实现


1.3 回归问题



1.4 分类问题
对于分类问题损失函数为log-loss 梯度提升算法推导

对于分类问题梯度提升算法损失函数的具体形式

1.5 梯度提升算法对于分类问题和回归问题的区别

1.6 XGBoost 算法推导

1.7 AdaBoost与梯度提升对比

1.8 梯度提升优缺点

二、示例代码
2.1 使用四种不同的基于梯度提升树的回归器来预测波士顿房价数据集的房价,并比较它们的均方误差。
指定版本python安装梯度提升算法框架(python3.12不支持)
首先,导入所需的库和模块,包括 numpy,sklearn,以及四种回归器的库。
然后,使用 sklearn.datasets.load_boston 函数来加载波士顿房价数据集,这是一个经典的回归问题的数据集,包含 506 个样本,13 个特征,和 1 个目标变量,即房价的中位数。
接着,使用 sklearn.model_selection.train_test_split 函数来划分训练集和测试集,设置测试集的比例为 0.2,随机数种子为 42,以保证结果的可复现性。
然后,定义一个字典 regressors,存储四种不同的回归器的实例,分别是 GBDT,CatBoost,LightGBM,和 XGBoost。这四种回归器都是基于梯度提升树的集成学习方法,它们的共同点是都使用加法模型和贪心算法来逐步增加树的数量,每次迭代都要求解一个新的树,使得目标函数最小化。它们的不同点是在损失函数,正则化项,树的结构,分裂点的选择,以及并行化和优化等方面有各自的特点和优势。
最后,使用一个 for 循环来遍历 regressors 字典中的每个回归器,对于每个回归器,执行以下步骤:
使用 fit 方法来训练回归器,传入训练集的特征和目标变量,得到一个训练好的模型。
使用 predict 方法来预测测试集的房价,传入测试集的特征,得到一个预测值的数组。
使用 sklearn.metrics.mean_squared_error 函数来计算预测值和真实值之间的均方误差,这是一个常用的回归问题的评价指标,表示预测误差的平方的均值,越小越好。
使用 print 函数来打印回归器的名称和均方误差的值,保留两位小数。
# 导入所需的库和模块
import numpy as np
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import GradientBoostingRegressor # GBDT
from catboost import CatBoostRegressor # CatBoost
from lightgbm import LGBMRegressor # LightGBM
from xgboost import XGBRegressor # XGBoost
# 加载波士顿房价数据集
X, y = load_boston(return_X_y=True)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义不同的回归器
regressors = {
"GBDT": GradientBoostingRegressor(random_state=42),
"CatBoost": CatBoostRegressor(random_state=42, verbose=0),
"LightGBM": LGBMRegressor(random_state=42),
"XGBoost": XGBRegressor(random_state=42)
}
# 训练和评估不同的回归器
for name, reg in regressors.items():
# 训练回归器
reg.fit(X_train, y_train)
# 预测测试集
y_pred = reg.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
# 打印结果
print(f"{name} MSE: {mse:.2f}")输出结果:
GBDT MSE: 6.21
CatBoost MSE: 7.72
[LightGBM] [Info] Auto-choosing row-wise multi-threading, the overhead of testing was 0.000745 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 1030
[LightGBM] [Info] Number of data points in the train set: 404, number of used features: 13
[LightGBM] [Info] Start training from score 22.796535
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
……
……
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
LightGBM MSE: 8.34
XGBoost MSE: 6.912.2 基于GBDT(Gradient Boosting Decision Trees)算法的分类与回归示例
2.2.1 使用梯度提升分类器(GradientBoostingClassifier)对成人收入数据集(adult_GBDT_Data)进行分类,并评估不同的参数组合对模型性能的影响
导入所需的模块和数据,包括sklearn.ensemble中的GradientBoostingClassifier,numpy,prettytable,matplotlib等,以及自定义的adult_GBDT_Data模块。
定义一些辅助函数,如Tom,ConfuseMatrix,fmse,用于计算混淆矩阵和F1度量等评价指标。
定义Train函数,用于训练一个梯度提升分类器,并返回训练集和验证集上的F1度量。
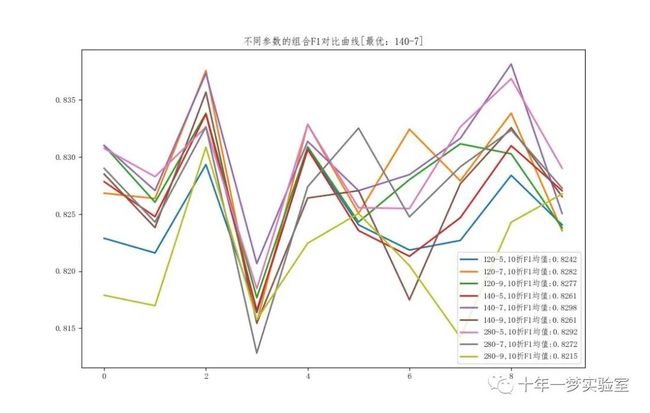
定义Zuhe函数,用于遍历不同的弱模型个数(models)和树的层数(cengs)的组合,使用交叉验证的方法评估每种组合的平均F1度量,并返回最优的参数组合和对应的折数。
定义duibi函数,用于绘制不同参数组合的F1对比曲线,并保存图片。
定义recspre函数,用于根据最优的参数组合,重新训练一个梯度提升分类器,并在预测数据集(predict_data)上进行预测,输出混淆矩阵和F1度量,精确率,召回率等指标。
在主函数中,调用Zuhe函数,得到最优的参数组合和折数,调用duibi函数,绘制对比曲线,调用recspre函数,进行预测和评估。
# adult_GBDT_Data.py
import pandas as pd # 导入pandas库,用于数据处理
import numpy as np # 导入numpy库,用于数值计算
# 训练数据文件路径
train_path = 'Boosting\Adult_Train.csv' # 定义训练数据的文件路径,文件格式为csv
# 预测数据文件路径
pre_path = 'Boosting\Adult_Test.csv' # 定义预测数据的文件路径,文件格式为csv
# 读取并且处理确缺失数据
def ReadHandle(filepath, miss='fill'): # 定义处理数据的函数,参数为文件路径和缺失值处理方式
data = pd.read_csv(r'%s' % filepath) # 读取csv文件,返回一个pandas的DataFrame对象
data = data.replace('?', np.nan) # 将数据中的'?'替换为numpy的nan值,表示缺失值
# 处理缺失值
if miss == 'del': # 如果缺失值处理方式为'del',则删除掉缺失值
miss_data = data.dropna(how='any') # 使用dropna方法,删除掉任何含有缺失值的行或列
else: # 否则,使用'fill'方式,即填充缺失值
miss_data = data.fillna(method='ffill') # 使用fillna方法,使用前一个有效值来填充缺失值,method='ffill'表示向前填充
return miss_data # 返回处理后的数据
# 将字符串字段进行数字编码,
def Digitcode(traindata, predixdata): # 定义数字编码的函数,参数为训练数据和预测数据
# 数字编码
for ikey in traindata: # 遍历训练数据的每一列
if traindata[ikey].dtype == 'object': # 如果列的数据类型为object,即字符串类型,那么进行数字编码
numb = sorted(list(set(list(traindata[ikey].values)))) # 将列的所有值去重并排序,得到一个列表
exdict = {ji: numb.index(ji) for ji in numb} # 生成一个字典,将每个值映射为其在列表中的索引,即数字编码
if ikey == 'Money': # 如果列的名称为'Money',因为sklearn支持字符串类别
predixdata[ikey] = ['%s' % gfi[:-1] for gfi in predixdata[ikey]] # 因为测试数据文件中Money的值多个点,所以去掉最后一个点
else: # 否则,对训练数据和预测数据的该列进行数字编码
predixdata[ikey] = [exdict[fi] for fi in predixdata[ikey]] # 使用字典的映射关系,将预测数据的该列的值替换为数字
traindata[ikey] = [exdict[fi] for fi in traindata[ikey]] # 使用字典的映射关系,将训练数据的该列的值替换为数字
return traindata, predixdata.values # 返回数字编码后的训练数据和预测数据
# 读取的数据
read_train = ReadHandle(train_path) # 调用ReadHandle函数,读取并处理训练数据文件,返回一个DataFrame对象
read_pre = ReadHandle(pre_path) # 调用ReadHandle函数,读取并处理预测数据文件,返回一个DataFrame对象
# 经过处理的数据
han_train, predict_data = Digitcode(read_train, read_pre) # 调用Digitcode函数,对训练数据和预测数据进行数字编码,返回两个数组
# 将训练数据进行K折交叉验证,根据F1度量确定最佳的
# 然后再进行预测数据的计算,输出混淆矩阵以及精确率、召回率,F1度量
def kfold(trdata, k=10): # 定义K折交叉验证的函数,参数为训练数据和折数
vadata = trdata.values # 将训练数据转换为数组
legth = len(vadata) # 获取训练数据的长度
datadict = {} # 定义一个空字典,用于存储每一折的数据
signnuber = np.arange(legth) # 生成一个从0到长度的整数序列,用于索引
for hh in range(k): # 遍历每一折
datadict[hh] = {} # 初始化该折的数据字典
np.random.shuffle(vadata) # 对训练数据进行随机打乱
yanzhneg = np.random.choice(signnuber, int(legth / k), replace=False) # 从整数序列中随机选择一部分作为验证集的索引,不重复
oneflod_yan = vadata[yanzhneg] # 根据索引,获取验证集的数据
oneflod_xun = vadata[[hdd for hdd in signnuber if hdd not in yanzhneg]] # 根据索引,获取训练集的数据,即剩余的数据
# 训练数据和验证数据
datadict[hh]['train'] = oneflod_xun # 将训练集的数据存储到该折的数据字典中
datadict[hh]['test'] = oneflod_yan # 将验证集的数据存储到该折的数据字典中
return datadict # 返回包含所有折的数据的字典
# 存储K折交叉验证的数据字典
dt_data = kfold(han_train) # 调用kfold函数,对训练数据进行K折交叉验证,返回一个数据字典# GBDT_Classify_adult.py
# 导入adult_GBDT_Data模块,该模块包含了成年人收入数据集
import adult_GBDT_Data as data
# 引入GBDT分类模型,该模型是一种基于梯度提升的集成学习方法
from sklearn.ensemble import GradientBoostingClassifier
# 导入numpy模块,该模块提供了科学计算的基本功能
import numpy as np
# 导入prettytable模块,该模块可以格式化输出混淆矩阵
from prettytable import PrettyTable as PT
# 导入pylab和matplotlib模块,这些模块可以绘制不同参数下F1度量的对比曲线
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 显示中文
mpl.rcParams['axes.unicode_minus'] = False # 显示负号
import matplotlib.pyplot as plt
# 根据K折交叉的结果确定比较好的参数组合,然后给出预测数据集的结果
# 主要的参数就是随机森林中树的个数和特征的个数,其他参数均使用默认值
# 弱模型中树的层数
cengs = [5, 7, 9]
# 弱模型的个数
models = [120, 140, 280]
# 混淆矩阵的函数
def Tom(reallist, prelist):
'''
:param reallist: 真实的类别列表
:param prelist: 预测的类别列表
:return: 每个类别预测为所有类别的个数字典
'''
# 创建一个空字典,用于存储每个类别预测为所有类别的个数
coundict = {}
# 遍历真实类别列表中的所有不重复的类别
for jj in list(set(reallist)):
# 在字典中创建一个以该类别为键的子字典
coundict[jj] = {}
# 遍历真实类别列表中的所有不重复的类别
for hh in list(set(reallist)):
# 在子字典中创建一个以该类别为键的值,该值为真实类别为jj且预测类别为hh的样本个数
coundict[jj][hh] = len([i for i, j in zip(reallist, prelist) if i == jj and j == hh])
# 返回字典
return coundict
# 定义输出混淆矩阵的函数
def ConfuseMatrix(reallist, prelist):
'''
:param reallist: 真实的类别列表
:param prelist: 预测的类别列表
:return: 输出混淆矩阵
'''
# 调用Tom函数,得到每个类别预测为所有类别的个数字典
zidian = Tom(reallist, prelist)
# 对字典的键进行排序,得到类别的列表
lieming = sorted(zidian.keys())
# 创建一个prettytable对象,用于输出混淆矩阵
table = PT(['混淆矩阵'] + ['预测%s'% d for d in lieming])
# 遍历类别列表
for jj in lieming:
# 向表格中添加一行,包括真实类别和预测为各个类别的个数
table.add_row(['实际%s' % jj] + [zidian[jj][kk] for kk in lieming])
# 返回表格对象
return table
# 计算F1度量的函数
def fmse(realist, prelist): # 对于多类别每个类都要计算召回率
'''
:param realist: 真实的类别列表
:param prelist: 预测的类别列表
:return: F1度量
'''
# 调用Tom函数,得到每个类别预测为所有类别的个数字典
condict = Tom(realist, prelist)
# 初始化总样本数和正确预测数为0
zongshu = 0
zhengque = 0
# 创建一个空列表,用于存储每个类别的召回率
zhao_cu = []
# 遍历字典中的每个类别
for cu in condict:
# 初始化该类别的真实样本数和正确预测数为0
zq = 0
zs = 0
# 遍历字典中的每个类别
for hh in condict[cu]:
# 获取该类别预测为hh的样本个数
geshu = condict[cu][hh]
# 如果cu和hh相同,说明预测正确,累加正确预测数
if cu == hh:
zhengque += geshu
zq = geshu
# 累加总样本数
zongshu += geshu
# 累加该类别的真实样本数
zs += geshu
# 计算该类别的召回率,并添加到列表中
zhao_cu.append(zq / zs)
# 计算精确率
jingque = zhengque / zongshu
# 计算类别召回率的平均值
zhaohui = np.mean(np.array(zhao_cu))
# f1度量
f_degree = 2 * jingque * zhaohui / (jingque + zhaohui)
# 返回F1度量,精确率和召回率
return f_degree, jingque, zhaohui
# 训练函数
def Train(data, modelcount, censhu, yanzhgdata):
# 创建一个GBDT分类模型对象,指定损失函数,弱模型的个数,树的层数,学习率和特征的个数
model = GradientBoostingClassifier(loss='deviance', n_estimators=modelcount, max_depth=censhu, learning_rate=0.1, max_features='sqrt')
# 使用训练数据拟合模型
model.fit(data[:, :-1], data[:, -1])
# 给出训练数据的预测值
train_out = model.predict(data[:, :-1])
# 计算训练数据的F1度量
train_mse = fmse(data[:, -1], train_out)[0]
# 给出验证数据的预测值
add_yan = model.predict(yanzhgdata[:, :-1])
# 计算验证数据的F1度量
add_mse = fmse(yanzhgdata[:, -1], add_yan)[0]
# 打印训练数据和验证数据的F1度量
print(train_mse, add_mse)
# 返回训练数据和验证数据的F1度量
return train_mse, add_mse
# 定义一个函数,用于确定最优的参数组合
def Zuhe(datadict, tre=models, ce=cengs):
# 创建一个空字典,用于存储不同参数组合的F1度量的均值
savedict = {}
# 创建一个空字典,用于存储不同参数组合的F1度量的列表
sacelist = {}
# 遍历弱模型的个数
for t in tre:
# 遍历树的层数
for j in ce:
# 打印当前的参数组合
print(t, j)
# 创建一个空列表,用于存储不同折数的验证数据的F1度量
sumlist = []
# 因为要展示折数,因此要按序开始
# 对数据字典的键进行排序,得到折数的列表
ordelist = sorted(list(datadict.keys()))
# 遍历折数的列表
for jj in ordelist:
# 调用训练函数,传入训练数据,验证数据,弱模型的个数和树的层数,得到训练数据和验证数据的F1度量
xun, ya = Train(datadict[jj]['train'], t, j, datadict[jj]['test'])
# 只选择验证数据较大的
# 将验证数据的F1度量添加到列表中
sumlist.append(ya)
# 将参数组合和对应的F1度量的列表存入字典中
sacelist['%s-%s' % (t, j)] = sumlist
# 计算F1度量的列表的均值,并存入另一个字典中
savedict['%s-%s' % (t, j)] = np.mean(np.array(sumlist))
# 在结果字典中选择最大的F1度量的均值,得到最优的参数组合
zuixao = sorted(savedict.items(), key=lambda fu: fu[1], reverse=True)[0][0]
# 然后再选出此方法中和值最大的折数
xiao = sacelist[zuixao].index(max(sacelist[zuixao]))
# 返回最优的参数组合,最优的折数和F1度量的字典
return zuixao, xiao, sacelist
# 定义一个函数,用于根据字典绘制不同参数组合的F1度量的对比曲线
def duibi(exdict, you):
# 创建一个图形对象,指定大小
plt.figure(figsize=(11, 7))
# 遍历字典中的每个参数组合
for ii in exdict:
# 绘制折数和F1度量的折线图,添加标签
plt.plot(list(range(len(exdict[ii]))), exdict[ii], \
label='%s,%d折F1均值:%.4f' % (ii, len(exdict[ii]), np.mean(np.array(exdict[ii]))), lw=2)
# 显示图例
plt.legend()
# 添加标题,显示最优的参数组合
plt.title('不同参数的组合F1对比曲线[最优:%s]' % you)
# 保存图像到指定路径
plt.savefig(r'C:\Users\cxy\Desktop\GBDT_adult.jpg')
# 返回提示信息
return '不同方法对比完毕'
# 定义一个函数,用于根据获得最优参数组合绘制真实和预测值的对比曲线
def recspre(estrs, predata, datadict, zhe):
# 将参数组合分割为弱模型的个数和树的层数
mo, ze = estrs.split('-')
# 创建一个GBDT分类模型对象,指定损失函数,弱模型的个数,树的层数,学习率和特征的个数
model = GradientBoostingClassifier(loss='deviance', n_estimators=int(mo), max_depth=int(ze), learning_rate=0.1)
# 使用最优的折数的训练数据拟合模型
model.fit(datadict[zhe]['train'][:, :-1], datadict[zhe]['train'][:, -1])
# 预测预测数据的类别
yucede = model.predict(predata[:, :-1])
# 计算混淆矩阵并打印
print(ConfuseMatrix(predata[:, -1], yucede))
# 返回预测数据的F1度量,精确率和召回率
return fmse(predata[:, -1], yucede)
# 主函数
if __name__ == "__main__":
# 调用Zuhe函数,得到最优的参数组合,最优的折数和F1度量的字典
zijian, zhehsu, xulie = Zuhe(data.dt_data)
# 调用duibi函数,绘制方法组合的对比曲线
duibi(xulie, zijian)
# 调用recspre函数,计算预测数据的f1度量,精确率以及召回率
f1, jing, zhao = recspre(zijian, data.predict_data, data.dt_data, zhehsu)
# 打印结果
print('F1度量:{}, 精确率:{}, 召回率:{}'.format(f1, jing, zhao))
输出结果:

2.2.2 使用GBDT回归模型对PM2.5的数据进行预测和分析
对一个包含空气质量数据的文件进行预处理,生成训练和预测数据集
导入 pandas 和 numpy 库
读取数据文件,使用 pd.read_csv 函数
定义 DeleteTargetNan 函数,用于删除目标变量 pm2.5 为空值的行,并用均值填充其他列的缺失值,最后将目标变量放在最后一列
定义 Shanchu 函数,用于删除不需要的字段,如 No
定义 Digit 函数,用于将字符串类型的属性转换为数字编码
对原始数据调用 DeleteTargetNan, Shanchu, Digit 函数,得到处理后的数据集 third
定义 fenge 函数,用于将数据集按照 8:2 的比例分为训练和预测数据集,其中训练数据集再分为 K 折,用于交叉验证
对 third 数据集调用 fenge 函数,得到 dt_data 和 predict_data,分别是 K 折交叉的训练数据和预测数据
import pandas as pd # 导入 pandas 库,用于数据处理
import numpy as np # 导入 numpy 库,用于数值计算
# 读取数据文件
data = pd.read_csv('Boosting\PRSA_data_2010.1.1-2014.12.31.csv')
# 因为Pm2.5是目标数据,如有缺失值直接删除这一条记录
# 删除目标值为空值的行的函数, 其他列为缺失值则自动填充的函数,并将目标变量放置在数据集最后一列
def DeleteTargetNan(exdata, targetstr):
if exdata[targetstr].isnull().any(): # 如果目标列有空值
loc = exdata[targetstr][data[targetstr].isnull().values == True].index.tolist() # 找到空值所在的行索引
exdata = exdata.drop(loc) # 删除这些行
exdata = exdata.fillna(exdata.mean()) # 其他列的空值用平均值填充
targetnum = exdata[targetstr].copy() # 复制目标列
del exdata[targetstr] # 删除原来的目标列
exdata[targetstr] = targetnum # 将目标列添加到数据集的最后一列
return exdata # 返回处理后的数据集
# 删除原始数据中不需要的字段名
def Shanchu(exdata, aiduan=['No']):
for ai in aiduan: # 对于每个不需要的字段名
if ai in exdata.keys(): # 如果在数据集中存在
del exdata[ai] # 删除该字段
return exdata # 返回处理后的数据集
# 将数据中的属性值为字符串的进行数字编码,因为独热编码对决策树而言不那么重要
def Digit(eadata):
for jj in eadata: # 对于每个属性
try:
eadata[jj].values[0] + 1 # 尝试将第一个值加一
except TypeError: # 如果出现类型错误,说明该属性值为字符串
numlist = list(set(list(eadata[jj].values))) # 将该属性的所有不同值转换为列表
zhuan = [numlist.index(jj) for jj in eadata[jj].values] # 将每个值替换为其在列表中的索引
eadata[jj] = zhuan # 更新该属性的值
return eadata # 返回处理后的数据集
first = DeleteTargetNan(data, 'pm2.5') # 调用删除目标值为空值的函数
two = Shanchu(first) # 调用删除不需要的字段的函数
third = Digit(two) # 调用数字编码的函数
# 将数据集按照8:2的比例分为训练、预测数据集。其中训练数据集再分为K份,进行K折交叉验证
def fenge(exdata, k=10, per=[0.8, 0.2]):
lent = len(exdata) # 获取数据集的长度
alist = np.arange(lent) # 生成一个从0到长度减一的数组
np.random.shuffle(alist) # 随机打乱数组
xunlian_sign = int(lent * per[0]) # 计算训练数据集的大小
xunlian = np.random.choice(alist, xunlian_sign, replace=False) # 从数组中随机选择训练数据集的索引,不重复
yuce = np.array([i for i in alist if i not in xunlian]) # 剩下的索引为预测数据集的索引
save_dict = {} # 创建一个空字典,用于存储K折交叉验证的数据
for jj in range(k): # 对于每一折
save_dict[jj] = {} # 创建一个子字典
length = len(xunlian) # 获取训练数据集的长度
# 随机选
yuzhi = int(length / k) # 计算每一折的大小
yan = np.random.choice(xunlian, yuzhi, replace=False) # 从训练数据集中随机选择一折的索引,不重复
tt = np.array([i for i in xunlian if i not in yan]) # 剩下的索引为训练数据集的索引
save_dict[jj]['train'] = exdata[tt] # 将训练数据集存入子字典
save_dict[jj]['test'] = exdata[yan] # 将测试数据集存入子字典
return save_dict, exdata[yuce] # 返回字典和预测数据集
deeer = fenge(third.values) # 调用分割数据集的函数
dt_data = deeer[0] # 获取K折交叉验证的数据
predict_data = deeer[1] # 获取预测数据集引入数据,使用pm25_GBDT_Data模块提供的数据集,包括训练数据和预测数据。
引入GBDT回归模型,使用sklearn.ensemble中的GradientBoostingRegressor类,以及sklearn.metrics中的mean_squared_error函数计算MSE。
定义训练函数,接受训练数据、模型参数和验证数据作为输入,返回训练数据和验证数据的MSE。
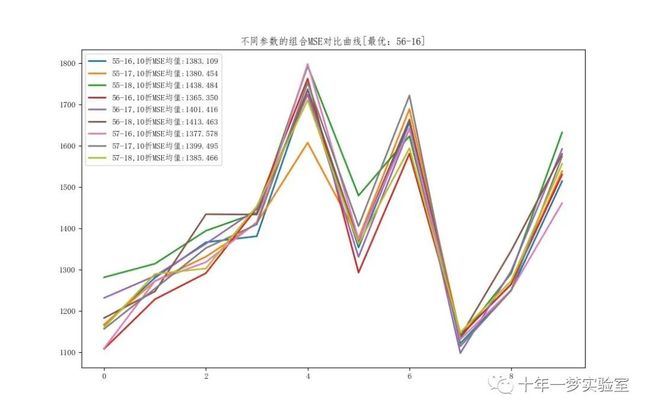
定义最终确定组合的函数,接受数据字典、弱模型的个数和树的层数作为输入,使用K折交叉验证的方法,遍历不同的参数组合,返回最优的参数组合、最小的MSE对应的折数和每种参数组合的MSE序列。
根据字典绘制曲线,使用matplotlib.pyplot模块,绘制不同参数组合的MSE对比曲线,标注最优的参数组合。
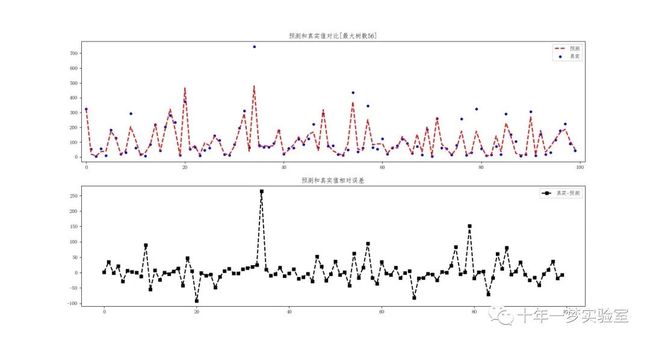
根据最优参数组合绘制真实和预测值的对比曲线,使用预测数据和最小MSE对应的训练数据,训练最优的GBDT回归模型,绘制真实值和预测值的对比曲线,以及真实值和预测值的相对误差曲线。
定义主函数,调用上述函数,完成数据的预测和分析。
# 引入数据
import pm25_GBDT_Data as data # 导入pm25_GBDT_Data模块,该模块包含了用于训练和预测的数据
# 引入GBDT回归模型
from sklearn.ensemble import GradientBoostingRegressor # 导入sklearn库中的梯度提升回归模型,该模型是一种集成学习方法,可以用多个弱模型组合成一个强模型
from sklearn.metrics import mean_squared_error as mse # 导入sklearn库中的均方误差函数,该函数可以用来评估模型的预测性能
import numpy as np # 导入numpy库,该库提供了多种数学和科学计算的功能
# 绘制不同参数下MSE的对比曲线
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 显示中文
mpl.rcParams['axes.unicode_minus'] = False # 显示负号
import matplotlib.pyplot as plt # 导入matplotlib库中的pyplot模块,该模块提供了绘图的功能
# 根据K折交叉的结果确定比较好的参数组合,然后给出预测数据真实值和预测值的对比
# 更改的参数一是框架的参数,二是弱模型的参数
# 弱模型中树的层数
cengs = [16, 17, 18] # 定义一个列表,存储不同的树的层数,用于调整弱模型的复杂度
# 定义弱模型的个数
models = [55, 56, 57] # 定义一个列表,存储不同的弱模型的个数,用于调整集成模型的强度
# 训练函数 _SUPPORTED_LOSS = ('ls', 'lad', 'huber', 'quantile')
def Train(data, modelcount, censhu, yanzhgdata): # 定义一个训练函数,接受四个参数:data是训练数据,modelcount是弱模型的个数,censhu是树的层数,yanzhgdata是验证数据
model = GradientBoostingRegressor(loss='ls', n_estimators=modelcount, max_depth=censhu, learning_rate=0.12, subsample=0.8) # 创建一个梯度提升回归模型,设置损失函数为最小二乘法,弱模型的个数为modelcount,树的层数为censhu,学习率为0.12,子采样比例为0.8
model.fit(data[:, :-1], data[:, -1]) # 使用训练数据的特征和标签拟合模型
# 给出训练数据的预测值
train_out = model.predict(data[:, :-1]) # 使用训练数据的特征预测训练数据的标签
# 计算MSE
train_mse = mse(data[:, -1], train_out) # 使用均方误差函数计算训练数据的真实标签和预测标签之间的误差
# 给出验证数据的预测值
add_yan = model.predict(yanzhgdata[:, :-1]) # 使用验证数据的特征预测验证数据的标签
# 计算MSE
add_mse = mse(yanzhgdata[:, -1], add_yan) # 使用均方误差函数计算验证数据的真实标签和预测标签之间的误差
print(train_mse, add_mse) # 打印训练数据和验证数据的误差
return train_mse, add_mse # 返回训练数据和验证数据的误差
# 最终确定组合的函数
def Zuhe(datadict, tre=models, tezhen=cengs): # 定义一个确定最优参数组合的函数,接受三个参数:datadict是一个字典,存储了不同折数的训练数据和验证数据,tre是一个列表,存储了不同的弱模型的个数,tezhen是一个列表,存储了不同的树的层数
# 存储结果的字典
savedict = {} # 定义一个空字典,用于存储不同参数组合的均方误差的均值
# 存储序列的字典
sacelist = {} # 定义一个空字典,用于存储不同参数组合的均方误差的序列
for t in tre: # 遍历弱模型的个数
for te in tezhen: # 遍历树的层数
print(t, te) # 打印当前的参数组合
sumlist = [] # 定义一个空列表,用于存储不同折数的验证数据的误差
# 因为要展示折数,因此要按序开始
ordelist = sorted(list(datadict.keys())) # 将datadict的键(即折数)排序并转换为列表
for jj in ordelist: # 遍历折数
xun, ya = Train(datadict[jj]['train'], t, te, datadict[jj]['test']) # 调用训练函数,传入当前折数的训练数据和验证数据,以及当前的参数组合,返回训练数据和验证数据的误差
# 根据验证数据的误差确定最佳的组合
sumlist.append(ya) # 将验证数据的误差添加到列表中
sacelist['%s-%s' % (t, te)] = sumlist # 将当前参数组合和对应的误差列表存储到sacelist字典中
savedict['%s-%s' % (t, te)] = np.mean(np.array(sumlist)) # 将当前参数组合和对应的误差列表的均值存储到savedict字典中
# 在结果字典中选择最小的
zuixao = sorted(savedict.items(), key=lambda fu: fu[1])[0][0] # 对savedict字典按照值(即误差均值)进行排序,取出第一个元素(即最小的误差均值)的键(即最优的参数组合)
# 然后再选出此方法中和值最小的折数
xiao = sacelist[zuixao].index(min(sacelist[zuixao])) # 在sacelist字典中根据最优的参数组合找到对应的误差列表,然后在列表中找到最小的误差,返回其索引(即最优的折数)
return zuixao, xiao, sacelist # 返回最优的参数组合,最优的折数,和误差列表的字典
# 定义一个函数 duibi,用于绘制不同参数组合的 MSE 对比曲线
# 参数 exdict 是一个字典,存储了不同参数组合的 MSE 列表
# 参数 you 是一个字符串,表示最优的参数组合
def duibi(exdict, you):
# 创建一个 11 x 7 的图形
plt.figure(figsize=(11, 7))
# 遍历 exdict 中的每个参数组合
for ii in exdict:
# 绘制 MSE 随数据量变化的曲线,添加标签
plt.plot(list(range(len(exdict[ii]))), exdict[ii], \
label='%s,%d折MSE均值:%.3f' % (ii, len(exdict[ii]), np.mean(np.array(exdict[ii]))), lw=2)
# 显示图例
plt.legend()
# 添加标题,显示最优的参数组合
plt.title('不同参数的组合MSE对比曲线[最优:%s]' % you)
# 保存图形到指定路径
plt.savefig(r'C:\Users\cxy\Desktop\GBDT_pm25.jpg')
# 返回一个字符串,表示对比完成
return '不同方法对比完毕'
# 定义一个函数 recspre,用于绘制真实值和预测值的对比曲线
# 参数 exstr 是一个字符串,表示最优的参数组合,格式为 "树的数量-树的深度"
# 参数 predata 是一个数组,表示预测数据,最后一列是真实值
# 参数 datadict 是一个字典,存储了不同折数的训练数据和测试数据
# 参数 zhe 是一个整数,表示使用哪一折的数据
# 参数 count 是一个整数,表示要展示的数据条数,默认为 100
def recspre(exstr, predata, datadict, zhe, count=100):
# 根据 exstr 分割出树的数量和树的深度
tree, te = exstr.split('-')
# 创建一个梯度提升回归模型,设置损失函数、树的数量、树的深度、学习率和子采样比例
model = GradientBoostingRegressor(loss='ls', n_estimators=int(tree), max_depth=int(te), learning_rate=0.12, subsample=0.8)
# 使用指定折数的训练数据拟合模型,最后一列是目标值
model.fit(datadict[zhe]['train'][:, :-1], datadict[zhe]['train'][:, -1])
# 使用模型对预测数据进行预测,忽略最后一列的真实值
yucede = model.predict(predata[:, :-1])
# 为了便于展示,从预测结果中随机选择 count 条数据
zongleng = np.arange(len(yucede))
randomnum = np.random.choice(zongleng, count, replace=False)
# 获取选中的预测值和真实值
yucede_se = list(np.array(yucede)[randomnum])
yuce_re = list(np.array(predata[:, -1])[randomnum])
# 绘制对比图
plt.figure(figsize=(17, 9))
# 创建一个 2 x 1 的子图,第一个子图显示预测值和真实值的曲线
plt.subplot(2, 1, 1)
# 用红色虚线绘制预测值的曲线,添加标签
plt.plot(list(range(len(yucede_se))), yucede_se, 'r--', label='预测', lw=2)
# 用蓝色点绘制真实值的散点图,添加标签
plt.scatter(list(range(len(yuce_re))), yuce_re, c='b', marker='.', label='真实', lw=2)
# 设置 x 轴的范围
plt.xlim(-1, count + 1)
# 显示图例
plt.legend()
# 添加标题,显示树的数量
plt.title('预测和真实值对比[最大树数%d]' % int(tree))
# 第二个子图显示真实值和预测值的相对误差
plt.subplot(2, 1, 2)
# 用黑色虚线绘制真实值减去预测值的曲线,添加标签
plt.plot(list(range(len(yucede_se))), np.array(yuce_re) - np.array(yucede_se), 'k--', marker='s', label='真实-预测', lw=2)
# 显示图例
plt.legend()
# 添加标题
plt.title('预测和真实值相对误差')
# 保存图形到指定路径
plt.savefig(r'C:\Users\cxy\Desktop\duibi.jpg')
# 返回一个字符串,表示对比完成
return '预测真实对比完毕'
# 主函数
if __name__ == "__main__":
# 调用 Zuhe 函数,得到最优的参数组合、折数和 MSE 字典
zijian, zhehsu, xulie = Zuhe(data.dt_data)
# 调用 duibi 函数,绘制不同参数组合的 MSE 对比曲线
duibi(xulie, zijian)
# 调用 recspre 函数,绘制真实值和预测值的对比曲线
recspre(zijian, data.predict_data, data.dt_data, zhehsu)输出结果:
2.3 四种梯度提升算法:GBDT, CatBoost, LightGBM, XGBoost 参数设置
GBDT(Gradient Boosting Decision Tree)是一种基于梯度提升的集成学习算法,它使用决策树作为弱学习器,通过迭代地拟合残差来提高预测性能。GBDT 的主要参数有:
n_estimators:弱学习器的数量,即决策树的数量。增加该参数可以提高模型的复杂度和拟合程度,但也可能导致过拟合。learning_rate:学习率,即每个弱学习器的贡献系数。减小该参数可以降低过拟合的风险,但也需要增加n_estimators以保持足够的拟合程度。max_depth:决策树的最大深度。增加该参数可以增加模型的非线性和拟合能力,但也可能导致过拟合。min_samples_split:决策树内部节点进行分裂所需的最小样本数。增加该参数可以防止过拟合,但也可能导致欠拟合。min_samples_leaf:决策树叶节点所需的最小样本数。增加该参数可以防止过拟合,但也可能导致欠拟合。subsample:用于训练每个弱学习器的样本比例。减小该参数可以降低方差,但也可能增加偏差。max_features:用于分裂每个决策树节点的特征数量。减小该参数可以降低过拟合的风险,但也可能降低模型的表达能力。
XGBoost(Extreme Gradient Boosting)是一种优化的 GBDT 实现,它使用了更高效的数据结构和并行计算,同时引入了正则化项和剪枝策略来防止过拟合。XGBoost 的主要参数有:
n_estimators:同 GBDT。learning_rate:同 GBDT。max_depth:同 GBDT。min_child_weight:决策树叶节点的最小权重和,相当于 GBDT 中的min_samples_leaf乘以样本权重。增加该参数可以防止过拟合,但也可能导致欠拟合。subsample:同 GBDT。colsample_bytree:相当于 GBDT 中的max_features,表示用于训练每棵树的特征比例。减小该参数可以降低过拟合的风险,但也可能降低模型的表达能力。reg_alpha:L1 正则化项的系数,用于惩罚模型的复杂度。增加该参数可以使模型更稀疏,但也可能损失一些信息。reg_lambda:L2 正则化项的系数,用于惩罚模型的复杂度。增加该参数可以防止过拟合,但也可能降低模型的灵活性。
LightGBM(Light Gradient Boosting Machine)是一种基于梯度提升的高效的分布式机器学习框架,它使用了基于直方图的算法和基于叶子的生长策略,可以大大提高训练速度和减少内存消耗。LightGBM 的主要参数有:
n_estimators:同 GBDT。learning_rate:同 GBDT。num_leaves:决策树的最大叶子数,相当于 GBDT 中的max_depth的指数倍。增加该参数可以增加模型的复杂度和拟合程度,但也可能导致过拟合。min_child_samples:同 GBDT 中的min_samples_leaf。subsample:同 GBDT。colsample_bytree:同 XGBoost。reg_alpha:同 XGBoost。reg_lambda:同 XGBoost。
CatBoost(Categorical Boosting)是一种基于梯度提升的机器学习框架,它专注于处理分类特征,使用了一种称为目标编码的技术来减少类别扩展的影响,同时使用了随机感知梯度提升算法来降低过拟合的风险。CatBoost 的主要参数有:
iterations:同 GBDT 中的n_estimators。learning_rate:同 GBDT。depth:同 GBDT 中的max_depth。l2_leaf_reg:同 XGBoost 中的reg_lambda。subsample:同 GBDT。random_strength:用于平衡每个样本的权重,相当于 GBDT 中的subsample的倒数。增加该参数可以降低过拟合的风险,但也可能降低模型的表达能力。one_hot_max_size:用于对类别特征进行独热编码的阈值,如果类别数小于该值,则使用独热编码,否则使用目标编码。增加该参数可以增加模型的非线性和拟合能力,但也可能导致维度灾难。
三、梯度提升算法在制造业中的应用
梯度提升算法在制造业中的一些应用场景。梯度提升算法是一种集成学习方法,它可以将多个弱分类器或回归器组合成一个强分类器或回归器,提高预测性能。梯度提升算法的核心思想是利用损失函数的负梯度作为残差的近似值,然后用一个基学习器拟合这个残差,再将其加到之前的模型上,从而不断地减小损失函数的值。梯度提升算法有以下几个特点:
梯度提升算法可以用任何可微分的损失函数,如平方误差、绝对误差、交叉熵等,这使得它比其他基于指数损失函数的算法更加灵活和通用。
梯度提升算法可以用任何基学习器,如决策树、神经网络、支持向量机等,这使得它比其他基于单一类型的基学习器的算法更加强大和多样化。
梯度提升算法可以通过调整学习率、迭代次数、树的深度等参数来控制模型的复杂度和过拟合程度,这使得它比其他缺乏正则化手段的算法更加稳定和可控。
在制造业中,梯度提升算法也有一些有趣和有用的应用,例如:
产品设计:梯度提升算法可以用于辅助工程师进行产品设计,通过设置期望的参数和性能等约束条件,利用人工智能算法,自动生成多种可行性方案,并筛选出最优的设计方案¹。
故障诊断:梯度提升算法可以用于对制造过程中的故障进行诊断,通过分析传感器数据,识别出异常模式,并提供相应的解决方案²。
质量检测:梯度提升算法可以用于对制造产品的质量进行检测,通过图像分析,检测出产品的缺陷或瑕疵,并提供相应的评估和反馈³。
你可以在以下网页中找到更多关于梯度提升算法在制造业中的应用的信息:
智能制造的人工智能8大应用场景
[基于AdaBoost的故障诊断方法及其应用]

参考网址
(1) 【机器学习】梯度提升机GBM详解 - 知乎 - 知乎专栏. https://zhuanlan.zhihu.com/p/460598556.
(2) 机器学习随笔——分类与回归的联系与区别 - 知乎. https://zhuanlan.zhihu.com/p/589535856.
(3) 机器学习教程 之 梯度提升方法:GBDT处理分类问题-CSDN博客. https://blog.csdn.net/liangjun_feng/article/details/80668461.
(4) 机器学习算法之——梯度提升(Gradient Boosting)原理讲解及Python实现 - 知乎. https://zhuanlan.zhihu.com/p/108641227.
(5) 梯度提升与梯度下降_梯度提升和梯度下降的区别-CSDN博客. https://blog.csdn.net/qq_42003997/article/details/103682921.
(6) Gradient Boosting with Scikit-Learn, XGBoost, LightGBM, and CatBoost. https://machinelearningmastery.com/gradient-boosting-with-scikit-learn-xgboost-lightgbm-and-catboost/.
(7) When to Choose CatBoost Over XGBoost or LightGBM [Practical Guide]. https://neptune.ai/blog/when-to-choose-catboost-over-xgboost-or-lightgbm.
(8) GBDT、XGBoost、LightGBM 的使用及参数调优 - 知乎 - 知乎专栏. https://zhuanlan.zhihu.com/p/33700459.
(9) 从结构到性能,一文概述XGBoost、Light GBM和CatBoost的同与不同 - 知乎. https://zhuanlan.zhihu.com/p/34698733.
(10) 大战三回合:XGBoost、LightGBM和Catboost一决高低 - 知乎. https://zhuanlan.zhihu.com/p/72686522.
(11) GBDT: https://scikit-learn.org/stable/modules/ensemble.html#gradient-boosting
(12) CatBoost: https://catboost.ai/
(13) LightGBM: https://lightgbm.readthedocs.io/en/latest/
(14) XGBoost: https://xgboost.readthedocs.io/en/latest/
(15) 梯度提升算法 Gradient Boosting https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
(16) https://scikit-learn.org/stable/auto_examples/ensemble/plot_gradient_boosting_quantile.html#sphx-glr-auto-examples-ensemble-plot-gradient-boosting-quantile-py
(17) 集成算法 https://scikit-learn.org.cn/view/90.html#
(18) 机器学习中的梯度提升 https://www.geeksforgeeks.org/ml-gradient-boosting/
(19) 梯度提升 https://deepai.org/machine-learning-glossary-and-terms/gradient-boosting
The End