labelImg数据标注及yolov5的训练和测试
labelImg数据标注及yolov5的训练和测试
一、labelImg数据标注的使用
数据标注主要针对于哪个地方是什么,一般像隐私类的是不能标注的,如鲁迅的故居可以标,但是张三的住所就不能进行标注。
labelImg是数据标注主要使用的工具。
1、首先使用python labelImg.py打开labelImg标注工具。

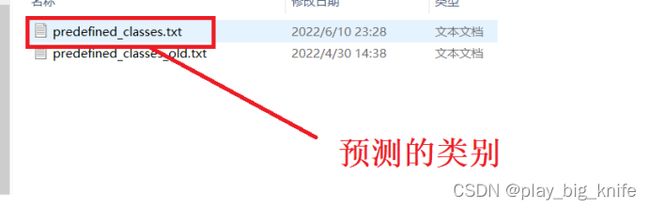
2、你可以打开labelImg目录下的data目录,目录下predefined_classes.txt可以定义预测的类别。
3、定义类别后,打开点击目录。
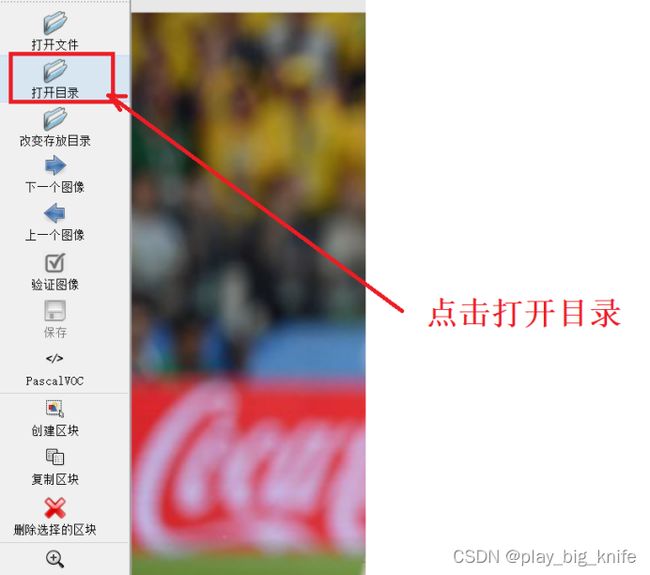
4、打开目录后,右边点击图像。

5、在中心有图片,可以选中左侧的“创建区块”标注图片中的类别。如下图。

接下来可以在图形中框出图片的分类区域。框选后出现类别的选框,如下图框选足球后出现的选框。
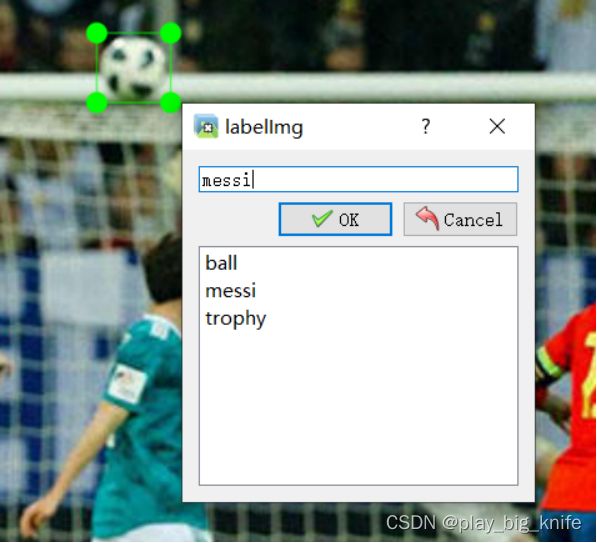
点击合适的分类后,OK即可。

OK点击后,需要保留框架的相关标注,按ctrl+S,保存后是xml文件格式。

点击保存后,在文件夹下产生一个与图片同名的xml文件。如下图。

打开xml文件后,可以看到图片的标注信息。

可以看到object识别,有坐标,有分类。
二、构建yolo5的项目步骤
直接拉取git clone https://github.com/ultralytics/yolov5.git

这时可以配置免验证。git config --global http.sslVerify "false"把项目中的ssl验证设置成false
然后git clone拉取yolo5模型文件
git clone https://github.com/ultralytics/yolov5.git
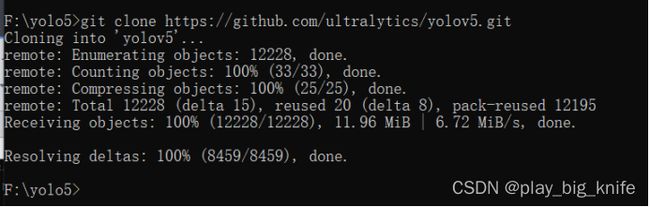
如果Timeout错误,就多次git,git网站的连接有问题,如下图所示。

拉取git 成功后,会在当前目录下产生require.txt文件,通过conda来安装require.txt文件。
conda install --yes --file requirements.txt
通过pip3 install 安装项目所需要的相关模块。
pip3 install -r requirements.txt
安装结束后可以自定义标签
新建一个VOCdevkit目录,下面有VOC2017文件夹,在VOC2017下两个文件夹。
Annotation标签,和JPEGImages图片文件,如下图所示。
Annotation目录下的标签文件。

JPEGImage标签下的文件如下图:
注意,图片需要等大,再则训练集中的数据容易识别,不然工作量很大。

xml文件中的坐标需要转换成YOLO格式的txt标记,如下图所示。

具体计算方法如下。

注意xml中width和height就是图片的总宽度和总高度。

通过该计算方法得到xml文件中的坐标需要转换成YOLO格式的txt标记的代码。

了解xml转换成YOLO格式txt标记后,生成训练集和验证集文件。
注意,目录结构可以建一个YOLO5目录,在YOLO5目录下有preparedata.py的py文件,同时也有一个目录VOCdevkit,然后执行python preparedata.py,就会在这样的目录下生成测试集和验证集。


.yolov5train.txt和yolov5val.txt分别给出了训练图片文件和测试图片文件的列表,含有每个图片的路径和文件名。
在data目录下,有一个voc.yaml中修改成voc-ball.yaml,其修改内容如下,此处可以删除下面的内容。

在models目录下建立yolov5s-ball.yaml,也可以把yolov5s.yaml改名为yolov5s-ball.yaml。其内容如下。

注意原yolov5s.yaml下面的内容不能删除。在训练时需要先验窗口。
修改后训练模型
注意执行训练模型前的路径:

还要注意在yolov5的文件夹下有一个weights目录,其下有一个权重文件yolo5s.pt,如下图。

接下来执行yolo5模型的训练。


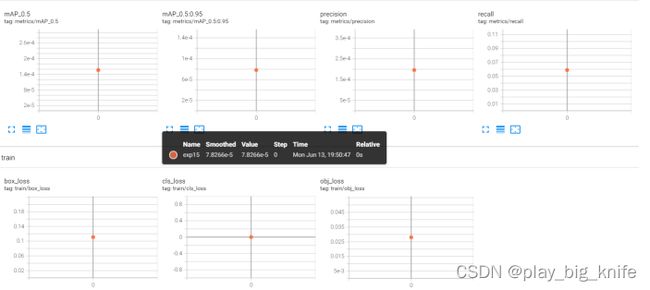
训练过程可视化:
训练过程可以通过另起一个anaconda窗口,在yolov5目录下执行。

显示出tenrowborad的模板如下图。
其会训练50次,每次训练终端如图所示。

Tensorboard图形会有曲线表示。

训练后测试图片。

训练后测试视频:
