NLP论文阅读记录 - 以大语言模型为参考学习总结
文章目录
- 前言
- 0、论文摘要
- 一、Introduction
-
- 1.1目标问题
- 1.2相关的尝试
- 1.3本文贡献
- 二.相关工作
-
- 2.1文本生成模型的训练方法
- 2.2 基于LLM的自动评估
- 2.3 LLM 蒸馏和基于 LLM 的数据增强
- 三.本文方法
-
- 3.1 Summarize as Large Language Models
-
- 3.1.1 前提
- 3.1.2 大型语言模型作为参考
-
- 具有准参考摘要的 MLE
- 3.1.3 从基于法学硕士的评估中学习
-
- 对比学习
- 用于总结质量评估的 GPTcore
- 用于摘要质量评估的 GPTRank
- 四 实验效果
-
- 4.1数据集
- 4.2 对比模型
- 4.3实施细节
- 4.4评估指标
- 4.5 实验结果
-
- 4.5.1 通过 GPTcore 学习
- 4.5.2 使用 GPTRank 学习
- 4.5.3 比较研究
- 4.5.4 人类评估和荟萃分析
-
- 4.5.4.1 人类评估集合
- 4.5.4.2 结果分析
- 4.5.4.3 基于法学硕士的评估的荟萃分析
- 五 总结
-
- 局限
前言

On Learning to Summarize with Large Language Models as References(2305)
code
paper
0、论文摘要
最近的研究发现,与常用摘要数据集中的原始参考摘要相比,大型语言模型 (LLM) 生成的摘要更受人类注释者的青睐。
因此,我们研究了一种新的文本摘要模型学习设置,将法学硕士视为这些数据集的参考或黄金标准预言机。
为了检查与这种新的学习环境相一致的标准实践,我们研究了两种基于 LLM 的模型训练摘要质量评估方法,并采用对比学习训练方法来利用 LLM 引导的学习信号。
我们在 CNN/DailyMail 和 XSum 数据集上的实验表明,在基于 LLM 的评估下,较小的摘要模型可以实现与 LLM 类似的性能。
然而,我们发现,尽管我们提出的训练方法带来了有希望的改进,但较小的模型在人类评估下仍无法达到 LLM 级别的性能。
与此同时,我们对这种新的学习环境进行了荟萃分析,揭示了人类评估与基于法学硕士的评估之间的差异,强调了我们研究的这种以法学硕士为参考设置的好处和风险。
一、Introduction
1.1目标问题
最近的研究(Liu 等人,2023b;Zhang 等人,2023)发现大型语言模型(LLM),如 GPT-3.5(Ouyang 等人,2022),可以生成人类注释者更喜欢的摘要在无参考的人类评估环境中与广泛使用的数据集(例如 CNN/DailyMail(Nallapati 等人,2016)和 XSum(Narayan 等人,2018))的参考摘要进行比较。现有参考摘要的质量问题有效地限制了在其上训练的摘要模型的性能上限,这可能会导致监督摘要模型与法学硕士之间的性能差距,正如相关工作所观察到的那样(Goyal 等人,2022 年;Liang 等人)等人,2022;Liu 等人,2023b;Zhang 等人,2023)。
1.2相关的尝试
1.3本文贡献
因此,我们研究了文本摘要模型的新学习设置,其中法学硕士被认为是摘要任务的参考或黄金标准预言机。这种 LLMa 参考设置通常在模型训练和评估方面对文本生成模型的学习设置引入了有趣的变化,因此我们研究了与这种转变相一致的标准实践(§2)。
具体来说,传统的摘要模型学习设置通常围绕单个参考摘要进行——在训练中,标准训练算法最大似然估计(MLE)要求模型预测参考摘要标记;在评估中,像ROUGE(Lin,2004)这样的自动评估指标通过将系统输出与参考摘要进行比较来估计系统输出的质量。相比之下,法学硕士提供了所有可能的候选摘要的目标概率分布或质量测量。因此,法学硕士可以为任意候选人分配质量分数,这使得超越 MLE 的训练技术成为可能,例如对比学习(Liu 等人,2022b)和强化学习(Paulus 等人,2018;Stiennon 等人,2020;Pang) He, 2021),并为模型评估提供了评估模型输出质量的预言机。
适应这种变化,我们研究了两种使用LLM进行摘要质量评估的方法:
(1)GPTScore(Fu et al., 2023),它将候选摘要的LLM预测概率作为其质量得分;
(2) GPTRank,我们提出的一种新方法,要求法学硕士提供不同摘要的质量排名,受到最近基于法学硕士评估的工作 (Liu et al., 2023a) 的启发。
通过这两种评估方法,我们采用对比学习方法进行模型训练,以有效利用LLM提供的监督信号。使用所提出的方法,我们是能够训练较小的摘要模型,例如 BART(Lewis 等人,2020),以匹配基于 LLM 的评估下的 LLM 表现(§3)。
研究了新的法学硕士作为参考设置后,我们对该设置本身进行了荟萃分析(§4)。具体来说,我们使用人群和专家注释器对法学硕士和法学硕士引导的较小模型进行人工评估,并使用评估结果来评估基于法学硕士的评估方法的可靠性。我们的分析揭示了法学硕士参考设置的好处和风险。
一方面,较小的模型确实可以受益于LLM的指导和对比学习方法。
另一方面,基于 LLM 的评估无法与人类评估保持一致,因为人类评估仍然更喜欢 LLM 而不是较小的模型,而它们在基于 LLM 的评估下实现了相似的性能。
总之,我们的贡献如下:
(1) 我们凭经验证明,当使用更好的参考资料 (LLM) 和学习方法(对比学习)以较小的预算进行训练时,BART 等较小模型的性能可以得到改善。1
(2) 我们的荟萃分析强调了 LLM 的局限性基于的培训和评估方法。它表明较小的摘要模型尚无法与法学硕士在人类评估下的表现相匹配,这需要进一步检查和改进这种新的学习环境。2
二.相关工作
2.1文本生成模型的训练方法
文本生成模型的标准 MLE 训练有两个主要局限性:
(1)训练目标(即交叉熵损失)与评估标准(例如 ROUGE)之间存在差异;
(2)教师强制(Williams and Zipser,1989)训练方式与评估过程中自回归生成行为之间的差异,称为暴露偏差(Bengio et al.,2015;Ranzato et al.,2016)。因此,人们提出了超越 MLE 的训练方法来解决这两个限制。其中一系列方法是基于强化学习(RL)的,可以优化文本面向特定奖励函数的生成模型 (Ranzato et al., 2016; Bahdanau et al., 2016; Li et al., 2016; Paulus et al., 2018; Li et al., 2019; Stiennon et al., 2020;庞和何,2021)。除了强化学习之外,还开发了基于监督学习的训练方法,例如最小风险训练(Shen et al., 2016; Wieting et al., 2019),针对具有各种奖励信号的序列级优化(Wiseman 和 Rush) ,2016 年;Edunov 等人,2018 年)。最近,还采用了对比学习(Hadsell et al., 2006),它通过要求模型区分正(好)和负(坏)例子来增强模型能力(Yang et al., 2019;Pan et al., 2019) .,2021;Cao 和 Wang,2021;Liu 和 Liu,2021;Sun 和 Li,2021;Liu 等人,2022b;Zhao 等人,2022;Zhang 等人,2022b)。
沿着这条道路的最新工作探索了使用对比学习来使法学硕士与人类反馈保持一致(Yuan 等人,2023;Zhao 等人,2023),作为基于人类反馈的强化学习的替代方案(Stiennon 等人,2020;Zhao 等人,2023)。欧阳等人,2022)。
2.2 基于LLM的自动评估
最近的工作探索了使用法学硕士进行自动 NLP 评估。 GPTScore(Fu et al., 2023)利用 LLM 预测的文本序列概率作为质量得分。另一方面,一系列工作(Chiang 和 yi Lee,2023;Gao 等,2023;Chen 等,2023;Wang 等,2023;Luo 等,2023)。例如,G-Eval (Liu et al., 2023a) 提出了使用 LLM 执行文本完成任务的评估方法,例如预测李克特量表评估或成对比较的答案。值得注意的是,其中一些研究(Fu et al., 2023;Liu et al., 2023a;Gao et al., 2023;Chen et al., 2023;Wang et al., 2023)都评估了基于LLM的评估方法在摘要人类评估基准 SummEval (Fabbri et al., 2021) 上进行研究,发现基于 LLM 的评估比以前的方法如 ROUGE 或 BERTScore (Zhang* et al., 2020) 与人类判断具有更高的相关性。除了摘要评估之外,基于 LLM 的评估也已用于文本分类任务(Gilardi 等人,2023)和 RL 代理的奖励设计(Kwon 等人,2023)。
2.3 LLM 蒸馏和基于 LLM 的数据增强
为了提高较小的 NLP 模型的性能,相关工作提出了提取 LLM 并使用 LLM 进行数据增强的方法(Wang et al., 2021;Ding et al., 2022;Kang et al., 2023)。具体来说,工作线(Shrid-哈尔等人,2022;李等人,2022; Hsieh 等人,2023)使用法学硕士生成最终答案和任务相关描述,以训练推理任务的较小模型。至于与文本摘要相关的工作,Wang 等人。 (2021) 介绍了使用 GPT-3(Brown 等人,2020)生成参考摘要,而 Gekhman 等人。 (2023) 提出使用 LLM 来注释摘要事实一致性 (Maynez et al., 2020),用于训练较小的事实一致性评估模型。
三.本文方法
3.1 Summarize as Large Language Models
3.1.1 前提
神经抽象摘要模型 g 旨在生成总结源文档 D 信息的文本序列 S:S ← g(D)。当 g 是自回归生成模型时,它将给定源文档 D 的候选摘要 S 的概率分解为

其中 si 是 S 中的第 i 个标记,S0 是特殊的序列开始 (BOS) 标记,S
g 的标准训练算法是带有单个参考(黄金标准)摘要 S* 的最大似然估计 (MLE)。与等式。 1、本例的 MLE 优化相当于最小化以下交叉熵损失:
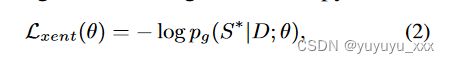
其中 θ 是 g 的可学习参数。
3.1.2 大型语言模型作为参考
类似于等式。 1、自回归LLM h定义了文本摘要的目标分布:
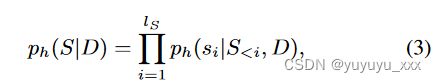
这与单个参考摘要定义的点质量分布不同。因此,交叉熵损失变为

其中 S 是可能输出的集合(候选摘要)。 Kim 和 Rush (2016) 将这种设置称为序列级知识蒸馏。在实践中,计算方程。 4 是棘手的,因为 S 是无限的。因此,我们研究了三种类型的方法来近似方程的优化过程。 4.
具有准参考摘要的 MLE
我们的基线方法将 LLM h 的贪婪解码结果视为准参考摘要,并使用 MLE 优化摘要模型 g。具体来说,损失函数变为
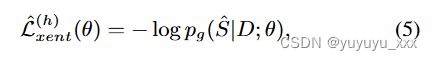
其中 ˆ S 是 h 的贪心解码结果:
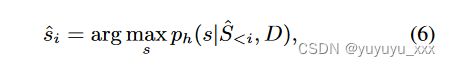
其中 s 表示词汇表中的标记。
3.1.3 从基于法学硕士的评估中学习
除了准参考摘要之外,参考法学硕士可以为模型训练提供更丰富的监督信号,因为它们可以用来评估任何候选摘要的质量。
因此,我们采用对比学习方法 BRIO (Liu et al., 2022b),它可以利用 LLM 指导进行模型训练,并探索两种基于 LLM 的评估方法,即最近推出的 GPTScore (Fu et al., 2023) ,还有一个我们稍后会介绍的新方法,GPTRank。
对比学习
我们采用对比损失(Liu et al., 2022b)来更好地利用LLM监督信号,它设定了以下目标:给定两个候选摘要S1、S2,如果S1从基于LLM的评估方法中获得更高的质量分数,概括模型 g 还应该为 S1 分配更高的概率(方程 1)。更详细地说,该损失是用一组候选摘要 Sc 定义的,该集合按 LLM 分配的质量分数排序,并且摘要模型 g 的任务是为更好的候选者分配至少两倍的概率:

对应于以下保证金损失:
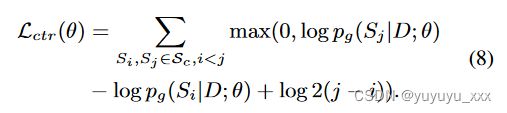
在实践中,我们观察到方程中对数概率的大小。 8 高度依赖于候选人摘要的长度。因此,我们对等式进行修改。 8 基于长度归一化对数概率 ̄ pg :

和等式。 8 改为

其中 λ 是近似平均摘要长度的缩放因子。继刘等人之后。 (2022b),我们将交叉熵损失(等式 5)与对比损失结合起来作为多任务损失:

其中 α 是对比损失的权重。
用于总结质量评估的 GPTcore
对比学习目标(方程 10)需要从参考法学硕士中获取真实的候选人总结质量分数。因此,我们首先采用GPTScore(Fu et al., 2023)进行总结质量评估。具体来说,GPTScore 将参考 LLM h 预测的候选摘要的长度归一化条件对数概率解释为其质量分数,即
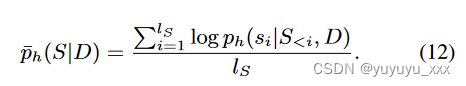
因此,方程中使用的候选摘要集合 Sc。 10 基于(归一化)目标分布(方程 3)进行排序,使得对于任何 Si,Sj ∈ Sc,i < j, ̄ ph(Si|D) > ̄ ph(Sj|D)。我们在图 1 中提供了 GPTScore 的说明。

用于摘要质量评估的 GPTRank
最近的工作,例如 G-Eval (Liu et al., 2023a),没有利用 LLM 的预测概率,而是将自动评估制定为 LLM 的文本完成或填充任务。例如,给定源文章和摘要,可以要求法学硕士提供摘要的数字质量分数。然而,正如刘等人。 (2023a) 发现 LLM 预测分数不够多样化且候选人摘要不同可能会获得相同的分数,我们向法学硕士提出排名任务。
所提出的评估方法 GPTRank 要求法学硕士为同一来源文章的不同候选摘要列表提供排名。此外,由于最近的工作(Liu et al., 2022a, 2023a)发现语言生成模型可以受益于评估任务的自我解释阶段,因此我们提示法学硕士在提供实际排名之前首先生成解释。然后将该排名用于对比训练(等式 10)。我们在图 2 中提供了使用 GPTRank 的示例。

四 实验效果
我们以多个法学硕士作为较小模型的参考进行实验,并比较不同训练方法的性能。
4.1数据集
我们在 CNN/DailyMail (CNNDM) 数据集上进行实验。使用原始验证集进行模型训练和评估,并使用100个测试示例进行基于LLM的评估。法学硕士被提示生成三句话摘要,以近似原始摘要风格,并使用 0 采样温度来近似贪婪解码过程(等式 6)3。
4.2 对比模型
4.3实施细节
模型训练从在原始 CNNDM 数据集上微调的 BART4 检查点开始。我们选择BART是因为它使用广泛且规模相对较小。
微调过程包括三个步骤:
(1) 热启动。我们使用 ChatGPT5 生成 10K 个用于微调的摘要和 1K 个用于验证的摘要,并通过 MLE 训练对原始 BART 检查点进行微调(等式 5)。
(2) MLE 培训。使用步骤 (1) 中的微调检查点,我们继续对不同 LLM 生成的准参考摘要进行 MLE 训练来微调模型。
(3)对比训练。从步骤 (2) 继续,我们使用多任务、对比学习目标不断微调模型(等式 11)。方程式的候选摘要。 10 个是从步骤(2)中训练的检查点生成的,并且不同的光束搜索(Vijayakumar 等人,2018)用于为每个数据点生成 8 个候选点。6
我们注意到,为了更公平的比较,在以下部分中,我们比较步骤(2)和步骤(3)中检查点的性能)在预算方面使用相似数量的数据进行训练。
关于检查点选择,对于 MLE 训练,我们使用验证集上的交叉熵损失作为标准,而对于对比训练,我们使用对比损失(等式 10)。
自动评估
对于基于参考的评估,我们报告系统输出与参考 LLM 生成的(准)参考摘要之间的 ROUGE-1/2 F1 分数。
对于无参考评估,我们使用 GPTScore(Fu 等人,2023)或 GPTRank(图 2)。特别是,对于 GPTScore,我们报告了对数概率的非标准化和标准化总和。
4.4评估指标
4.5 实验结果
4.5.1 通过 GPTcore 学习
我们首先使用 GPTScore 来研究学习。
我们选择的参考 LLM 是 OpenAI 的 text-davinci-003 (GPT3D3),因为它的 API 提供了对预测对数概率的访问。
使用 GPT3D3,可以生成大约 2K 个摘要用于 MLE 训练,并生成 200 个数据点用于对比学习。

我们在表中报告了测试集上的模型性能。 1. 比较以下模型的性能:
(1) GPT3D3,
(2) 在原始 CNNDM 数据集上微调的 BART 检查点,
(3) GPT3D2(OpenAI 的text-davinci-002),
(4) 7B Alpaca 检查点,7
(5) ChatGPT。
我们得出以下观察结果:
(1)与原始 BART 检查点相比,根据 GPTScore 或 ROUGE 衡量,对 LLM 的准参考摘要进行 MLE 训练可以有效提高模型性能。它表明,使用更好的参考摘要进行训练可以缩小较小的摘要模型和法学硕士之间的性能差距。
(2)对比学习得到的模型(BRIO.GPT3D3)可以比通过MLE训练微调的模型(BART.GPT3D3)获得明显更好的GPTScore,证明了对比学习对于近似参考LLM目标分布的有效性。
(3) BRIO.GPT3D3 已经可以达到与参考 LLM (GPT3D3) 本身类似的 GPTScore,同时仅通过对比学习对 100 个示例进行训练,这显示了进一步缩小性能差距的有希望的路径。
4.5.2 使用 GPTRank 学习
我们现在使用 GPTRank 进行模型训练和评估的实验。我们选择的参考 LLM 是 ChatGPT 8 和 GPT4 (OpenAI, 2023),因为它们在摘要评估方面表现出了最先进的性能 (Liu et al., 2023a)。9
对于对比学习,使用 500 或 1000 个数据点模型训练ChatGPT和GPT4分别作为参考LLM,并使用100个数据点进行验证。
为了进行更准确的评估,我们选择ChatGPT作为基线模型,并使用LLM在不同系统和ChatGPT之间进行配对比较。此外,我们允许法学硕士预测两个摘要之间的平局。10以 ChatGPT 作为参考 LLM 的结果如表 2 所示。

结果与我们在第 3.2 节中观察到的结果类似:
(1)使用更好的参考进行训练有助于提高摘要模型的性能。
(2) 对比学习比标准 MLE 训练更有效,因为用对比学习训练的模型 (BRIO.ChatGPT) 可以优于其对应模型 (BART.ChatGPT)。
(3)在ChatGPT本身的评估下,BRIO.ChatGPT在与基线模型ChatGPT的比较中赢得了一半以上,这表明对比学习可以针对特定的评估指标(即GPTRank)有效地优化摘要模型。
除了使用ChatGPT作为参考LLM之外,我们还使用GPT4作为GPTRank的骨干模型进行实验。我们在选项卡中报告结果。 3,并注意以下几点:
(1)使用不同的LLM时,GPTRank的评估结果不同。例如,虽然 BRIO.ChatGPT 在 Tab 中的 ChatGPT 评估下优于 ChatGPT。 2、GPTRank与GPT4仍然更喜欢ChatGPT。
(2)使用对比学习和GPT4作为参考LLM训练的模型检查点(BRIO.GPT4)在GPT4的评估下能够优于ChatGPT,这也表明BRIO.GPT4可以优于BRIO.ChatGPT。它显示了选择用于对比训练的适当评估方法的重要性。
(3) BRIO.ChatGPT 的性能优于 BART.GPT4,尽管 BRIO.ChatGPT 是使用据称较弱的参考 LLM 进行训练的,这表明了对比学习的优势以及使用更好的训练方法的重要性。
4.5.3 比较研究
我们研究了我们的训练方法在主干模型和数据格式的选择方面的泛化能力。
FLAN-T5 实验
我们重复第 3.3 节中的实验,但使用 30 亿个 FLANT5(Chung 等人,2022)模型11 作为骨干模型。

结果在选项卡中。
图 4 表明,对于模型性能而言,训练算法可能比模型大小更重要,因为 BRIO.GPT4 的性能优于 T5.GPT4。
通过对比学习训练的 FLAN-T5 检查点 T5BRIO.GPT4 取得了很强的性能。然而,我们注意到它的摘要比其他系统的摘要要长得多,这使得结果更难以解释,因为最近的工作发现人类和基于法学硕士的摘要评估中的摘要评级和长度之间存在很强的相关性。(Liu 等人,2023b; Rajani 等人,2023)。进一步的讨论在附录 A.4 中。

XSum 实验我们现在在另一个常用数据集 XSum(Narayan et al., 2018)上进行实验。我们遵循原始的 XSum 数据格式,让模型生成一句话摘要。实验设置与§3.1 和§3.3 中的类似,更多细节参见附录A.5。结果如表所示。
图 5 显示了类似的趋势,即使用更好的参考进行训练有助于提高模型性能。
我们注意到,对比学习的增益在 XSum 上是微不足道的(BART.GPT4 与 BRIO.GPT4),这可能是因为与 CNNDM 相比,BART.GPT4 和 ChatGPT 之间的性能差距较小,这限制了改进空间。
4.5.4 人类评估和荟萃分析
在第 3 节中,我们已经证明,在基于 LLM 的评估下,通过对比学习训练的较小摘要模型可以实现与 LLM 相当甚至更好的性能。然而,法学硕士和人工评估之间的一致性仍然需要检查。因此,我们首先对第 3 节中的模型性能进行人类评估,然后对 LLM 与人类的一致性进行荟萃分析。
4.5.4.1 人类评估集合
评估设计为了实现更直接、更稳健的比较并降低任务难度,我们将人类评估制定为两个不同系统之间的成对比较任务。
摘要对在三个方面进行比较:(1)显着性,(2)连贯性,以及(3)总体偏好/质量,其中注释者需要选择哪个摘要更好(允许并列)。详细的方面定义见附录 B.1。人群注释集合 我们使用 Amazon Mechanical Turk12 (MTurk) 进行人群注释集合。每个数据示例都由三名注释者进行注释,他们为一项任务提供两分钟的时间并获得相应的补偿。参与的众批标注者需要通过相关资质测试,并具有评估摘要质量的经验。我们为 100 个测试示例的集合选择了三个系统对,其中 ChatGPT 是基线 LLM,并将第 3.3 节中的三个 BART 检查点与 ChatGPT 进行比较:BART、BART.GPT4 和 BRIO.GPT4。为了检查注释者间的一致性,我们按照 Goyal 等人的方法计算了 Krippendorff 的 alpha (Krippendorff, 2011) 和 MASI 距离 (Passonneau, 2006)。 (2022)。我们发现平均一致性为 0.064,接近 Goyal 等人报告的一致性 (0.05)。 (2022)类似的评估设置。
专家评
审众批注释的低一致性引起了人们对注释质量的担忧性。相关工作(Goyal et al., 2022;Zhang et al., 2023)也观察到了类似的现象,并认为一致性低可能是由于人类评估固有的主观性和不同系统的性能差距较小造成的。然而,较低的一致性使得验证注释质量变得非常困难。13因此,三位共同作者14进行了仔细的专家评估,以更好地理解这一现象并提供更可信的评估结果。
我们选择了 50 个测试示例,对三个人群评估的系统组以及 BART.GPT4 和 BRIO.GPT4 之间的附加组进行配对比较。经过仔细注释后,我们发现专家注释者的平均一致性为0.044,这再次证实了相关工作中关于摘要评估固有主观性的假设(Goyal et al., 2022;Zhang et al., 2023) 。此外,专家们在 58% 的情况下达成一致,与最近工作中的一致水平 (65%) 类似 (Rafailov et al., 2023)。我们在附录 B.2 中提供了进一步的分析,其中显示了两种主要情况:(1)注释者一致赞成 LLM 摘要的情况; (2) LLM 和较小的 LM 都具有良好性能的情况,导致注释者偏好不同。虽然通过更受限制的评估协议可能会取得更高的一致性,但我们认为这种更高的一致性可能是“人为的”,并且无法反映人类偏好的多样化分布。
4.5.4.2 结果分析
人群注释和专家评估结果见表 1。 6 和选项卡。分别为 7 个。
我们注意到:
(1)以LLM为参考训练的模型(BART.GPT4和BRIO.GPT4)可以大幅优于在原始CNNDM数据集上训练的BART检查点,显示了以更好的参考进行训练的重要性。
(2)在专家评估的直接比较中,BRIO.GPT4在三个方面都优于BART.GPT4,这证明了LLM反馈的对比学习的有效性。
(3) 尽管 BART.GPT4 和 BRIO.GPT4 受到基于 ChatGPT(表 2)或 GPT4 的评估方法的青睐,但在人类评估下它们都无法超越 ChatGPT
(表 3)。这一结果凸显了人类评估与基于法学硕士的评估之间的差异,我们将在下一节中进一步研究这一差异。
4.5.4.3 基于法学硕士的评估的荟萃分析
我们使用专家评估结果来评估基于LLM的评估以及人群注释的性能,通过计算它们与专家评估的多数票的一致性。除了 GPTScore 和 GPTRank 之外,我们还比较了 G-Eval 的性能(Liu et al., 2023a)。用于 GPTRank 和 G-Eval 的提示是特定于方面的。更多详细信息参见附录 B.3。这些协议在表中报告。如图8所示,呈现出以下趋势:
(1)基于LLM的评估方法性能各异,GPT4优于ChatGPT。
(2)GPT4Rank已经可以超越个体众包工作者的表现,而众包工作者的多数投票仍然达到最高的一致性。
五 总结
在这项工作中,我们研究了一种新的文本摘要模型学习设置,其中法学硕士被设置为参考。在这种情况下,我们利用基于LLM的评估方法通过对比学习来指导模型训练,并凭经验证明我们方法的效率和有效性。此外,我们对基于法学硕士的评估的可靠性进行了人类评估和荟萃分析,揭示了其作为更好的培训参考的好处以及在与人类评估保持一致方面的局限性。我们相信我们的研究结果揭示了将法学硕士可靠地应用于较小的、特定于任务的 NLP 模型的整个开发循环(即训练-验证-评估)的方向。
局限
我们报告的基于 LLM 的评估结果来自 OpenAI 的 API,可能会发生变化。因此,我们的实验的可重复性是有限的。
为了缓解这个问题,我们将发布训练数据、模型输出以及法学硕士和人工评估结果,以方便未来的工作。
我们进行的基于法学硕士的评估和人工评估都可能是资源密集型的,需要大量的时间和预算。
因此,我们在选择评估样本量时,力求在评估结果的可靠性与时间和预算的约束之间找到平衡。更大规模的评估可能会产生更可靠的结果,我们将其留给未来在这个方向上更专注的工作。
我们选择不将汇总事实一致性作为人类评估和基于法学硕士评估的荟萃分析中的个人质量方面。
相关工作(Tang et al., 2022;Zhang et al., 2023)发现CNNDM数据集上的事实错误率较低,尤其是LLM摘要。在我们的专家评估过程中,作者也没有发现事实一致性方面存在重大缺陷。因此,需要更大的样本量来评估事实一致性,以了解错误模式,这超出了本工作的范围。然而,我们认为这样的评估对于更好地理解法学硕士和法学硕士指导模型的总结质量非常重要,我们希望这项工作的成果(例如系统输出)可以成为未来这方面工作的有用资源。话题。