- 以下内容基于 t o r c h t e x t 0.8.0 D o c s \rm torchtext~0.8.0~Docs torchtext 0.8.0 Docs 展开。
文章目录
- Field类功能.
- 构造参数.
- 成员函数 build_vocab.
- Embedding.
Field类功能.
- F i e l d \rm Field Field 类对可以用张量 T e n s o r \rm Tensor Tensor 表示的常见文本处理数据类型进行处理,包含一个 V o c a b \rm Vocab Vocab 词表对象,该对象对 F i e l d \rm Field Field 中的文本数据及其向量化表示进行定义。 F i e l d \rm Field Field 对象还包含用于定义如何对数据类型进行数字化的其他参数,例如分词 T o k e n i z a t i o n \rm Tokenization Tokenization 方法和应该生成的张量类型。
构造参数.
sequential: Whether the datatype represents sequential data. If False,
no tokenization is applied. Default: True.
- 【 s e q u e n t i a l \rm sequential sequential】数据是否为序列化数据,例如最常见的文本序列,如果非序列数据,则无法进行分词 T o k e n i z a t i o n . \rm Tokenization. Tokenization. 该参数默认为 T r u e . \rm True. True.
use_vocab: Whether to use a Vocab object. If False, the data in this
field should already be numerical. Default: True.
- 【 u s e _ v o c a b \rm use\_vocab use_vocab】数据是否需要词表对象 V o c a b \rm Vocab Vocab,如果不需要,那么必须保证数据是已经完成数值化的。该参数默认为 T r u e . \rm True. True.
init_token: A token that will be prepended to every example using this
field, or None for no initial token. Default: None.
eos_token: A token that will be appended to every example using this
field, or None for no end-of-sentence token. Default: None.
- 【 i n i t _ t o k e n / e o s _ t o k e n \rm init\_token/eos\_token init_token/eos_token】分别表示每一段序列的 i n i t i a l t o k e n \rm initial~token initial token 和 e n d − o f − s e n t e n c e t o k e n \rm end-of-sentence~token end−of−sentence token,默认为 N o n e \rm None None 表示不进行特殊的起始、终末附加。
fix_length: A fixed length that all examples using this field will be
padded to, or None for flexible sequence lengths. Default: None.
- 【 f i x _ l e n g t h \rm fix\_length fix_length】设置每段文本的长度,过长会被截断,过短会进行填充。默认为 N o n e \rm None None 表示使用不等长文本。
lower: Whether to lowercase the text in this field. Default: False.
- 【 l o w e r \rm lower lower】是否将文本全部转化为小写。
tokenize: The function used to tokenize strings using this field into
sequential examples. If "spacy", the SpaCy tokenizer is
used. If a non-serializable function is passed as an argument,
the field will not be able to be serialized. Default: string.split.
- 【 t o k e n i z e \rm tokenize tokenize】用于进行分词的具体方法,默认为 P y t h o n \rm Python Python 标准的字符串对象分割函数 s p l i t ( ) . \rm split(). split(). 也可以进行特殊指定,例如 t o k e n i z e = ′ s p a c y ′ \rm tokenize='spacy' tokenize=′spacy′ 则表示使用 S p a C y \rm SpaCy SpaCy 的分词方法。
preprocessing: The Pipeline that will be applied to examples
using this field after tokenizing but before numericalizing. Many
Datasets replace this attribute with a custom preprocessor.
Default: None.
postprocessing: A Pipeline that will be applied to examples using
this field after numericalizing but before the numbers are turned
into a Tensor. The pipeline function takes the batch as a list, and
the field's Vocab.
Default: None.
- 【 p r e p r o c e s s i n g / p o s t p r o c e s s i n g \rm preprocessing/postprocessing preprocessing/postprocessing】指明该 F i e l d \rm Field Field 对象中数据在数值化前、数值化后 (转化为张量之前) 进行的流水线处理。默认均为 N o n e . \rm None. None.
tokenizer_language: The language of the tokenizer to be constructed.
Various languages currently supported only in SpaCy.
- 【 t o k e n i z e r _ l a n g u a g e \rm tokenizer\_language tokenizer_language】分词器的语言种类,目前仅有 S p a C y \rm SpaCy SpaCy 支持多种语言类型。
pad_token: The string token used as padding. Default: "".
unk_token: The string token used to represent OOV words. Default: "".
- 【 p a d _ t o k e n / u n k _ t o k e n \rm pad\_token/unk\_token pad_token/unk_token】分别代表用于填充时使用的 t o k e n \rm token token 和处理未知词时使用的 t o k e n . \rm token. token. 其中 O O V \rm OOV OOV 是 o u t − o f − v a c a b u l a r y \rm out-of-vacabulary out−of−vacabulary 的简写,二者的默认值分别为 < p a d > , < u n k > . \rm ,. <pad>,<unk>.
batch_first: Whether to produce tensors with the batch dimension first.
Default: False.
- 【 b a t c h _ f i r s t \rm batch\_first batch_first】是否将数据的批大小作为张量的第一维度,默认是 F a l s e . \rm False. False.
pad_first: Do the padding of the sequence at the beginning. Default: False.
truncate_first: Do the truncating of the sequence at the beginning. Default: False
- 【 p a d _ f i r s t / t r u n c a t e _ f i r s t \rm pad\_first/truncate\_first pad_first/truncate_first】分别表示是否对序列在开头进行填充和截断,默认均为 F a l s e \rm False False,填充和截断都在序列尾进行。
stop_words: Tokens to discard during the preprocessing step. Default: None
- 【 s t o p _ w o r d s \rm stop\_words stop_words】预处理过程中丢弃的词,往往是一些无意义的虚词。
is_target: Whether this field is a target variable.
Affects iteration over batches. Default: False
- 【 i s _ t a r g e t \rm is\_target is_target】标记该 F i e l d \rm Field Field 中的数据是否为目标变量,会影响到后续批处理时的迭代,默认为 F a l s e . \rm False. False.
- 通常在进行自然语言处理,例如情感分类器训练时,并不会用到上面的所有参数,绝大部分参数保持默认值即可。例如下面是实例化两个 F i e l d \rm Field Field 对象的代码,分别对应文本数据和标签数据:
TEXT = data.Field(lower = True,batch_first = True,fix_length = 20)
LABEL = data.Field(sequential = False)
- 文本数据显然是序列数据,因此 s e q u e n t i a l \rm sequential sequential 保持默认值即可;而标签数据是表明输入数据情感类别的数据,其取值为 { 0 , 1 , 2 } \{0,1,2\} {0,1,2} ,表示未知、正面、负面,因此需要将 s e q u e n t i a l \rm sequential sequential 置 F a l s e . \rm False. False.
成员函数 build_vocab.
- 一个调用 b u i l d _ v o c a b ( ) \rm build\_vocab() build_vocab() 方法的实例如下:
TEXT.build_vocab(train,
vectors = GloVe(name = '6B',dim = 300),
max_size = 10000,
min_freq = 10)
LABEL.build_vocab(train)
- 其中 G l o v e ( n a m e = ′ 6 B ′ , d i m = 300 ) \rm Glove(name='6B',dim=300) Glove(name=′6B′,dim=300) 用于下载并导入预训练好的词向量 g l o v e . 6 b . 300 d . \rm glove.6b.300d. glove.6b.300d.
- b u i l d _ v o c a b ( ) \rm build\_vocab() build_vocab() 方法中通过训练数据集 t r a i n \rm train train 构建词表,并且通过 m a x _ s i z e \rm max\_size max_size 指定其中词频最大的前 10000 10000 10000 个词纳入考虑。这里 v e c t o r s = G l o V e ( . . . ) \rm vectors=GloVe(...) vectors=GloVe(...) 表示使用预训练好的词向量进行初始化。注意这里仅仅是将预训练好的词向量作为初始化,并未在模型中实际使用该预训练词向量,如果不使用形如下面的语句将 g l o v e . 6 b . 300 d \rm glove.6b.300d glove.6b.300d 等预训练词向量导入,则词向量通常会由网络中 E m b e d d i n g \rm Embedding Embedding 层负责训练。
model.embedding.weight.data = TEXT.vocab.vectors
model.embedding.weight.requires_grad = False
Embedding.
- 构建词表时选定的词嵌入向量维度关系到网络中嵌入层 E m b e d d i n g \rm Embedding Embedding 的构造参数, P y T o r c h − E m b e d d i n g \rm PyTorch-Embedding PyTorch−Embedding 的构造参数如下所示:
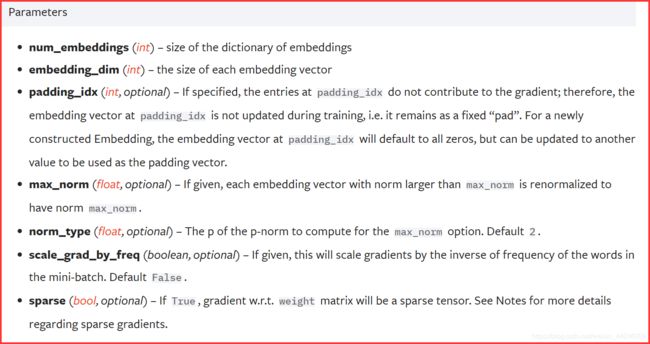
- 如果不指定 E m b e d d i n g \rm Embedding Embedding 层的权重参数,那么会基于标准正态分布进行随机初始化。

- E m b e d d i n g \rm Embedding Embedding 层在前向传播时可以理解为执行查表操作 —— 将序列中的单词替换为 E m b e d d i n g \rm Embedding Embedding 层的词嵌入向量(本质上就是该层权重).
