论文阅读——X-Decoder
Generalized Decoding for Pixel, Image, and Language
Towards a Generalized Multi-Modal Foundation Model
1、概述
X-Decoder没有为视觉和VL任务开发统一的接口,而是建立了一个通用的解码范式,该范式可以通过采用共同的(例如语义)但尊重自然差异(例如空间掩码与序列语言)来无缝连接任务,从而全面显著改进不同的分割和VL工作。
输入:两个查询,(i) generic non-semantic queries that aim to decode segmentation masks for universal segmentation,(ii) newly introduced textual queries to make the decoder language-aware for a diverse set of language-related vision tasks
输出:两种类型,像素级别和token级别。
2、X-Decoder
2.1 Formulation
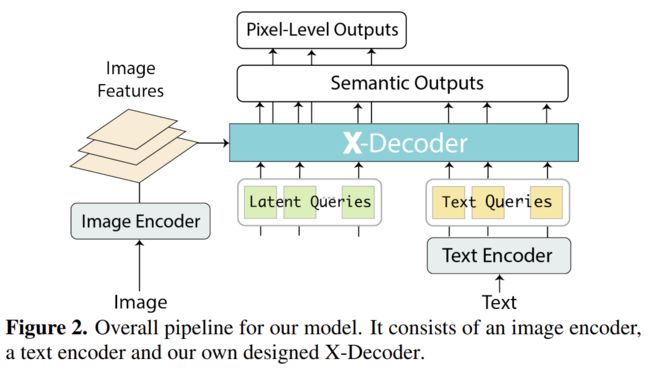
图片: 经过image encoder
经过image encoder  得到特征
得到特征![]() ,文本T经过text encoder
,文本T经过text encoder  编码为
编码为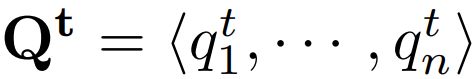 ,长度为n,非语义查询或者潜在查询
,长度为n,非语义查询或者潜在查询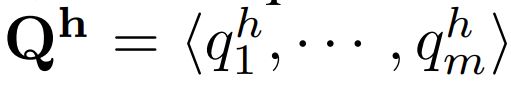 ,输入X-Decoder输出:
,输入X-Decoder输出:
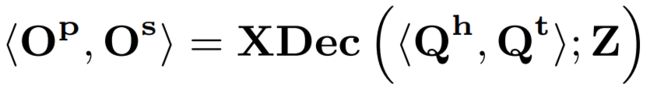
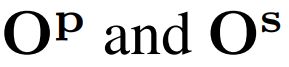 分别是像素级别masks和token级别语义.
分别是像素级别masks和token级别语义.
在许多以前的统一编码器-解码器模型中,图像和文本在编码器侧融合。这种设计不仅使全局图像-文本对比学习难以解决,而且使生成预训练也难以解决。相反,通过完全解耦图像和文本编码器,并将输出全部用作查询,X-Decoder可以从图像内监督和图像间监督中学习,这对于学习更强的像素级表示和支持不同粒度的任务至关重要。
2.2 Unification of Tasks

Generic Segmentation:
Referring Segmentation: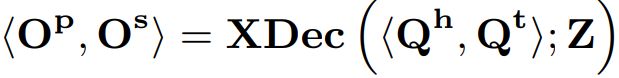 ,与一般分割类似,只使用与潜在查询相对应的前m个解码输出。
,与一般分割类似,只使用与潜在查询相对应的前m个解码输出。
Image-Text Retrieval: ,
,
Image Captioning and VQA: ,这两个任务有两个不同:Captioning遵循因果掩mask策略,而VQA则不遵循。其次,使用Os中的所有输出作为字幕,但仅使用最后一个输出来预测VQA的答案。
,这两个任务有两个不同:Captioning遵循因果掩mask策略,而VQA则不遵循。其次,使用Os中的所有输出作为字幕,但仅使用最后一个输出来预测VQA的答案。
之前的一系列工作探索了序列解码接口进行统一。然而,在这项工作中,我们提倡通过功能而不是接口来实现统一,即我们最大限度地共享不同任务的共同部分,同时保持单个任务的其余部分不变。
2.3 Unified Architecture
 ,不同level的特征
,不同level的特征
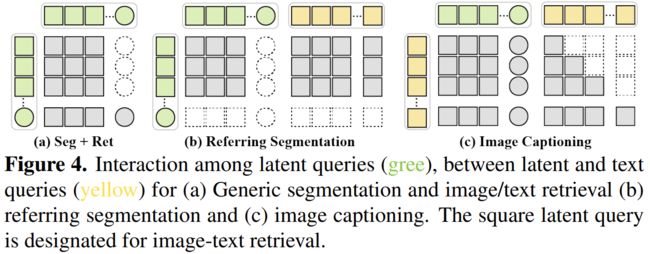
在每一层:先和视觉特征做交叉注意力,然后潜在查询和文本查询做自注意力:

其中,对第一个公式,所有查询和视觉特征做交叉注意力,对于潜在查询,使用masked cross-attention mechanism,对文本查询使用全部注意力。
对第二个公式,(i) 我们使用最后一个潜在查询来提取全局图像表示,剩余的用于一般分割;(ii)对于图像Caption,每个文本查询可以和其自身、前面的文字、所有潜在查询做自注意力;(iii)对于参考分割,潜在查询与所有文本查询做注意力。
对,m个潜在查询输出mask,对于语义输出,为潜在查询和文本查询预测输出,
2.4 End-to-End Pre-training
两种类型的损失函数:Semantic Loss,Mask Loss
1)Semantic Loss:
三个任务对应三个损失函数:
对image-text retrieval,计算语言图片相对损失。最后一个有效的token feature ![]() 代表文本,记作
代表文本,记作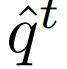 ,用潜在特征的表示全局图片的特征表示图片,记作
,用潜在特征的表示全局图片的特征表示图片,记作 ,对minibatch B获得B对特征对:
,对minibatch B获得B对特征对: ,然后计算点乘得到
,然后计算点乘得到 ,然后计算双向交叉熵:
,然后计算双向交叉熵:

y是class labels。
对于mask classification,包括“background”在内C个类别编码为C个文本查询,提取每个查询最后一个有效特征作为概念表示,然后取对应前(m-1)个潜在查询的decoder输出,计算这些输出和概念表示的点乘,得到 ,最后计算交叉熵损失:
,最后计算交叉熵损失: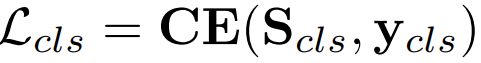 。
。
对于image captioning,提取所有词汇向量,大小为V,X-Decoder最后n个语义输出,计算点乘得到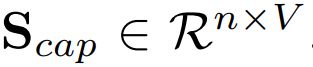 ,和GT的写一个token的id
,和GT的写一个token的id  计算交叉熵
计算交叉熵 。
。
2)Mask Loss
用Hungarian matching找到和前(m − 1)个输出匹配的GT,使用BCE和DICE计算损失。
3 实验
100 latent queries and 9 decoder layers for segmentation, and we add one additional latent query for image-level task。
Focal-T and DaViT-B/L as the vision encoder