轻松搭建基于服务网格的 AI 应用,然后开始玩
作者:尹航
在 2023 年的云栖大会中,阿里云服务网格 ASM 推出了《两全其美:Sidecarless 与 Sidecar 模式融合的服务网格新形态》主题演讲,并在演讲中展示了一个基于服务网格 ASM 各项能力构建的 DEMO AI 应用。该应用集中展示了 ASM 在模型服务、请求处理、请求路由和安全中心集成单点登录等各项能力,且这些能力还完全是以 Sidecarless 的形态来实现的。
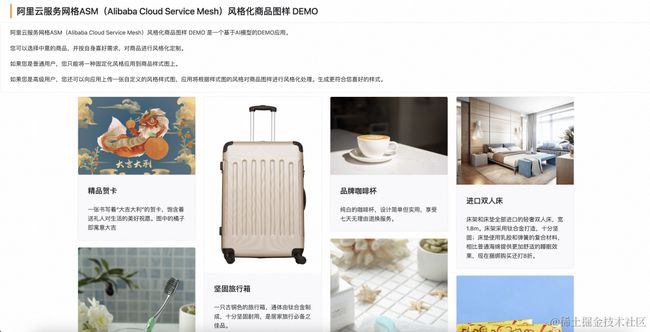

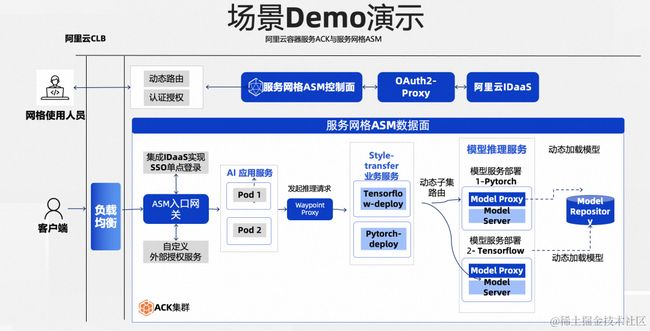
看完我们的演示,您也许也会想尝试一下,从零开始构建这样的一个应用来玩玩吧!当然!我们向您保证,我们能搭出来的东西,您一定也能搭出来。本文就是这样一篇给各位的入门指引,我们这就开始吧!
从零开始搭建一个基于服务网格 ASM 的 AI 应用
1、前提条件
一个 ACK 集群、一个 ASM 实例以及相关的 istioctl 等工具是一切的根基,我们先来准备一些实验环境。
- 已创建 ASM 实例,且实例版本在 1.18.0.131 及以上。具体操作,请参见创建 ASM 实例 [ 1] 。在创建服务网格页面配置数据面模式时,选中启用 Ambient Mesh 模式。
- 已创建 Kubernetes 集群,且满足 Kubernetes 集群及配置要求 [ 2] 。关于创建集群的具体操作,请参见创建 Kubernetes 专有版集群 [ 3] 或创建 Kubernetes 托管版集群 [ 4] 。
- 已添加集群到 ASM 实例。具体操作,请参见添加集群到 ASM 实例 [ 5] 。
- 已按照实际操作系统及平台,下载 Istioctl 服务网格调试工具。详细信息,请参见 Istio [ 6] 。
2、搭建模型推理服务
1)开启 ASM 的多模型推理服务生态集成能力
对于一个基于 AI 模型推理的应用服务来说,将训练好的模型快速转化为弹性、灵活的模型推理服务无疑是工作的重心之一。
作为应用感知的下一代云原生基础设施,服务网格 ASM 也通过其丰富的生态集成能力、集成了云原生推理服务框架 KServe(参考 ASM 集成云原生推理服务框架 KServe [ 7] )、为 AI 模型推理的服务化提供了一站式解决方案。
在服务网格 ASM 的最新版本中,我们 alpha 阶段地引入了模型推理服务集成的多模型服务框架(modelmesh)。在全新的 modelmesh 服务框架之内,不同的模型、其推理将交给多个运行时工作负载来完成。每个运行时支持不同的模型格式;并且可以同时提供多个模型的推理服务。当我们使用 InferenceService 资源定义一个模型后,模型文件将根据模型的格式、动态地加载到对应的运行时工作负载之中。一个运行时可以同时提供多个模型的推理服务。
我们可以通过以下步骤来集成多模型推理服务框架 modelmesh:
-
在 ASM 实例中创建一个名为 modelmesh-serving 的全局命名空间(参考管理全局命名空间 [ 8] )
-
要使用这个能力,我们首先使用 kubectl 连接到 ASM 实例(参考通过控制面 kubectl 访问 Istio 资源 [ 9] )
-
使用以下这个文件,创建 asmkserveconfig.yaml
apiVersion: istio.alibabacloud.com/v1beta1
kind: ASMKServeConfig
metadata:
name: default
spec:
enabled: true
multiModel: true
tag: v0.11.0
- 使用 kubectl 执行以下命令,打开模型推理服务框架集成
kubectl apply -f asmkserveconfig.yaml
执行完此步骤后,我们可以看到 ACK 集群中出现一个 modelmesh-serving 命名空间,内部包含有模型推理 Servicemodelmesh-serving、以及提供服务的各种运行时工作负载,这就代表模型推理服务已经就绪。
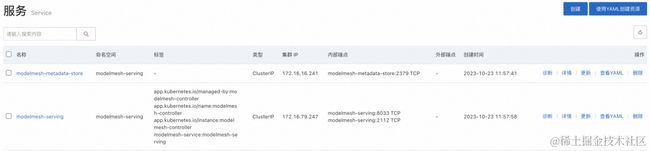

2)准备模型文件,声明推理服务
模型推理服务框架就绪后,接下来我们需要准备好训练的模型文件,并将模型加载到运行时工作负载中,成为可以对外暴露的推理服务。
- 准备模型文件
机器学习模型在经过训练后,可以通过各种序列化方式被保存下来(例如:saved_model、pkl 等),模型推理服务器可以加载并利用这些模型文件对外提供训练好的机器学习模型的推理服务。
在本 DEMO 应用中,我们也需要准备这样的模型文件。事实上,我们准备了两个训练好的模型。这两个模型分别基于 tensorflow 与 pytorch,其中 pytorch 模型生成的图片风格固定,而 tensorflow 模型可以抽取图片风格,进行不同的风格化处理。
模型的获取也非常简单,不需要大家去自己训练了。我们只需要通过 Tensorflow 和 Pytorch 的官方渠道即可获取了。
- TensorFlow 模型可通过 Tensorflow Hub 获取,访问这里来下载:https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2
- 至于 Pytorch 模型,我们在本例中使用了官方 DEMO 例子中的模型,并将其转换成了 ONNX 格式。我们可以参考这个教程来下载并转换模型文件:https://pytorch.org/tutorials/advanced/ONNXLive.html(注意:在转换成 ONNX 模型的一步,我们是使用了 512*512 的图片作为输入,注意输入图片尺寸,这个对 ONNX 格式的模型很重要)。demo 中提供四种固定风格的模型,我们可以任选一款,在我们的 demo 中选择了 candy 模型。
下载到本地后,我们随便找个路径作为根目录,新建一个 tensorflow 文件夹和一个 pytorch 文件夹,分别保存两个模型的文件。我们将两个模型的模型文件保存成如下的文件夹结构,方便后续操作。
Tensorflow 模型大概长这样:

Pytorch 模型则是这样的:

在根目录运行 ls -R 指令,可以看到如下的文件结构:
$ ls -R
pytorch tensorflow
./pytorch:
style-transfer
./pytorch/style-transfer:
candy.onnx
./tensorflow:
style-transfer
./tensorflow/style-transfer:
saved_model.pb variables
./tensorflow/style-transfer/variables:
variables.data-00000-of-00002 variables.data-00001-of-00002 variables.index
- 将模型文件加载到 PVC
首先创建一个存储类,前往容器服务控制台的 存储 > 存储类,创建一个存储类:

接着创建 PVC,前往容器服务控制台 存储 > 存储声明,用刚刚创建的存储类来创建一个存储声明 PVC,名字就叫 my-models-pvc。
- 创建一个 pod 用来将模型文件拷贝到 PVC 里
前往容器服务控制台的工作负载 > 容器组,点击“使用 YAML 创建”,并在 YAML 框中输入以下内容,点击“创建”来创建一个 pod。
apiVersion: v1
kind: Pod
metadata:
name: "pvc-access"
namespace: modelmesh-serving
spec:
containers:
- name: main
image: ubuntu
command: ["/bin/sh", "-ec", "sleep 10000"]
volumeMounts:
- name: "my-pvc"
mountPath: "/mnt/models"
volumes:
- name: "my-pvc"
persistentVolumeClaim:
claimName: "my-models-pvc"
- 使用 kubectl cp 将模型文件通过 pod 拷贝进 PVC
首先使用 kubectl 连接至 ACK 集群(参考获取集群 KubeConfig 并通过 kubectl 工具连接集群 [ 10] )。
接下来在刚才的模型文件根目录处,打开命令行,运行以下指令:
kubectl cp -n modelmesh-serving tensorflow pvc-access:/mnt/models/
kubectl cp -n modelmesh-serving pytorch pvc-access:/mnt/models/
接下来执行以下命令,确定拷贝已经成功:
kubectl exec -n modelmesh-serving pvc-access -- ls /mnt/models
预期得到以下内容,就说明模型文件已经被拷贝到 PVC 里了。
pytorch
tensorflow
- 使用 InferenceService 自定义资源创建模型推理服务
使用以下内容,创建 isvc.yaml 文件
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: tf-style-transfer
namespace: modelmesh-serving
annotations:
serving.kserve.io/deploymentMode: ModelMesh
#serving.kserve.io/secretKey: myoss
spec:
predictor:
model:
modelFormat:
name: tensorflow
storage:
parameters:
type: pvc
name: my-models-pvc
path: tensorflow/style-transfer/
---
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: pt-style-transfer
namespace: modelmesh-serving
annotations:
serving.kserve.io/deploymentMode: ModelMesh
spec:
predictor:
model:
modelFormat:
name: onnx
storage:
parameters:
type: pvc
name: my-models-pvc
path: pytorch/style-transfer/
isvc.yaml 中声明了两个 InferenceService,分别对应 Tensorflow 和 Pytorch 模型的推理服务声明。
使用以下命令,在 ACK 集群中创建模型推理服务。
kubectl apply -f isvc.yaml
我们可以观察到在集群中,支持 Tensorflow 和 Pytorch 这两个模型的运行时工作负责 Pod 被动态扩容拉起,并开始加载对应支持格式的模型。在此 DEMO 示例中,我们用 InferenceService 分别声明了 Tensorflow 和 ONNX 格式的模型文件,因此,可以看到,对应拉起的运行时是 triton-2.x 运行时和 ovms-1.x 运行时。
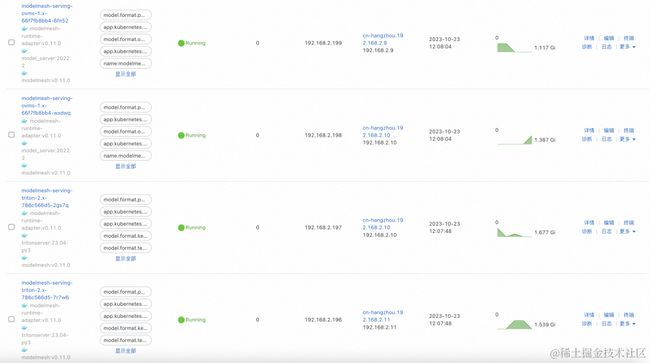
当运行时启动与模型加载都完成后,使用 kubectl 获取 InferenceService,可以看到两个 InferenceService 也都对应处于就绪状态:
$ kubectl get isvc -n modelmesh-serving
NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE
pt-style-transfer grpc://modelmesh-serving.modelmesh-serving:8033 True 11d
tf-style-transfer grpc://modelmesh-serving.modelmesh-serving:8033 True 11d
3)在集群中部署业务服务
在模型推理服务的前面就是我们的业务服务了,分别是 style-transfer 业务服务和最前方的 AI 应用服务,我们接下来就需要在集群中部署这些服务以及服务的工作负载。
- 使用 kubectl 连接到 ACK 集群,并使用如下命令创建一个命名空间来部署应用
kubectl create namespace apsara-demo
- 使用以下内容,创建 ai-apps.yaml 文件
apiVersion: v1
kind: ServiceAccount
metadata:
name: ai-backend
namespace: apsara-demo
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: style-transfer
namespace: apsara-demo
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: ai-backend
name: ai-backend
namespace: apsara-demo
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: ai-backend
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: ai-backend
spec:
serviceAccountName: ai-backend
containers:
- image: 'registry.cn-hangzhou.aliyuncs.com/build-test/asm-apsara:g56a99cd1-aliyun'
imagePullPolicy: IfNotPresent
name: ai-backend
ports:
- containerPort: 8000
name: http
protocol: TCP
resources:
requests:
cpu: 250m
memory: 512Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: style-transfer
name: style-transfer-tf
namespace: apsara-demo
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: style-transfer
model-format: tensorflow
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: style-transfer
model-format: tensorflow
spec:
serviceAccountName: style-transfer
containers:
- image: >-
registry.cn-hangzhou.aliyuncs.com/build-test/style-transfer-tf:g78d00b1c-aliyun
imagePullPolicy: IfNotPresent
name: style-transfer-tf
env:
- name: MODEL_SERVER
value: istio-ingressgateway.istio-system.svc.cluster.local:8008
- name: MODEL_NAME
value: tf-style-transfer
ports:
- containerPort: 8000
name: http
protocol: TCP
resources:
requests:
cpu: 250m
memory: 512Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: style-transfer
name: style-transfer-torch
namespace: apsara-demo
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: style-transfer
model-format: pytorch
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: style-transfer
model-format: pytorch
spec:
serviceAccountName: style-transfer
containers:
- image: >-
registry.cn-hangzhou.aliyuncs.com/build-test/style-transfer-torch:g78d00b1c-aliyun
imagePullPolicy: IfNotPresent
name: style-transfer-torch
env:
- name: MODEL_SERVER
value: istio-ingressgateway.istio-system.svc.cluster.local:8008
- name: MODEL_NAME
value: pt-style-transfer
ports:
- containerPort: 8000
name: http
protocol: TCP
resources:
requests:
cpu: 250m
memory: 512Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
---
apiVersion: v1
kind: Service
metadata:
labels:
app: ai-backend
name: ai-backend-svc
namespace: apsara-demo
spec:
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: http
port: 8000
protocol: TCP
targetPort: 8000
selector:
app: ai-backend
type: ClusterIP
---
apiVersion: v1
kind: Service
metadata:
labels:
app: style-transfer
name: style-transfer
namespace: apsara-demo
spec:
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: http
port: 8000
protocol: TCP
targetPort: 8000
selector:
app: style-transfer
sessionAffinity: None
type: ClusterIP
- 使用 kubectl 执行以下命令来部署上方文件中声明的应用服务
kubectl apply -f ai-apps.yaml
4)创建 ASM 网关、waypoint 网格代理,并部署生效流量规则
部署的最后一部分都有关服务网格,具体来说有以下部分:
- ASM 入口网关。
- 网格 waypoint 代理,它是 Sidecarless 的服务网格能力载体。
- 服务网格流量规则,这些规则将生效到 ASM 网关和 waypoint 代理,保证流量路径按照我们的设计运行。
- 部署 ASM 入口网关
我们可参考创建入口网关 [ 11] ,来创建 ASM 入口网关。我们需要创建两个 ASM 入口网关,其中一个叫 api-ingresgateway,服务类型为 LoadBalancer,网关上需要开启 80 端口;另一个叫 ingressgateway,服务类型为 ClusterIP,网关上需要开启 8008 端口。其余网关配置保持默认即可。
都创建完成后,我们应该可以在 ASM 入口网关页面看到这样的显示:
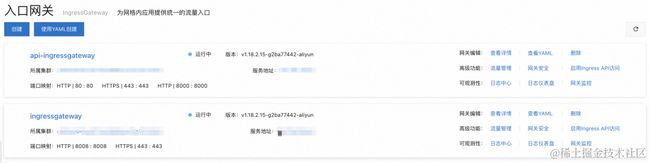
-
开启 apsara-demo 命名空间的 Ambient Mesh 模式
-
- 登录 ASM 控制台 [ 12] ,在左侧导航栏,选择服务网格 > 网格管理。
- 在网格管理页面,单击目标实例名称,然后在左侧导航栏,选择网格实例 > 全局命名空间。
- 在全局命名空间页面,单击从 Kubernetes 集群同步自动注入, 选择数据面 ACK 集群后单击确定。
- 在全局命名空间页面的数据面模式列,单击 apsara-demo 命名空间对应的切换为 Ambient Mesh 模式, 然后在确认对话框,单击确定。
-
部署 waypoint 代理
使用 kubectl 连接到 ACK 集群,然后使用前提条件中安装的 istioctl 工具,执行以下指令:
istioctl x waypoint apply --service-account style-transfer -n apsara-demo
执行完成后,我们可以使用 kubectl 列出集群中的无状态工作负载。
kubectl get deploy -n apsara-demo
预期输出:
NAME READY UP-TO-DATE AVAILABLE AGE
ai-backend 1/1 1 1 13d
style-transfer-istio-waypoint 1/1 1 1 13d
style-transfer-tf 1/1 1 1 13d
style-transfer-torch 1/1 1 1 13d
可以看到集群中除了我们刚才部署的 AI 应用以及 style-transfer 应用的工作负载外,还增加了一个名为 style-transfer-istio-waypoint 的工作负载,这就是服务网格的 waypoint 代理,它是以独立的工作负载方式部署在集群中的,所提供的所有能力也都是 Sidecarless 的。
- 部署服务网格规则
① 使用以下内容,创建 modelsvc-routing.yaml 文件
# make sure voyage is 1.13.4.13 or higher
apiVersion: networking.istio.io/v1beta1
kind: Gateway
metadata:
name: grpc-gateway
namespace: modelmesh-serving
spec:
selector:
istio: ingressgateway
servers:
- hosts:
- '*'
port:
name: grpc
number: 8008
protocol: GRPC
- hosts:
- '*'
port:
name: http
number: 80
protocol: HTTP
---
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: vs-modelmesh-serving-service
namespace: modelmesh-serving
spec:
gateways:
- grpc-gateway
hosts:
- '*'
http:
- headerToDynamicSubsetKey:
- header: x-model-format-tensorflow
key: model.format.tensorflow
- header: x-model-format-pytorch
key: model.format.pytorch
match:
- port: 8008
name: default
route:
- destination:
host: modelmesh-serving
port:
number: 8033
---
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: dr-modelmesh-serving-service
namespace: modelmesh-serving
spec:
host: modelmesh-serving-service
trafficPolicy:
loadBalancer:
dynamicSubset:
subsetSelectors:
- keys:
- model.format.tensorflow
- keys:
- model.format.pytorch
---
apiVersion: istio.alibabacloud.com/v1beta1
kind: ASMGrpcJsonTranscoder
metadata:
name: grpcjsontranscoder-for-kservepredictv2
namespace: istio-system
spec:
builtinProtoDescriptor: kserve_predict_v2
isGateway: true
portNumber: 8008
workloadSelector:
labels:
istio: ingressgateway
---
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
labels:
asm-system: 'true'
provider: asm
name: grpcjsontranscoder-increasebufferlimit
namespace: istio-system
spec:
configPatches:
- applyTo: LISTENER
match:
context: GATEWAY
listener:
portNumber: 8008
proxy:
proxyVersion: ^1.*
patch:
operation: MERGE
value:
per_connection_buffer_limit_bytes: 100000000
workloadSelector:
labels:
istio: ingressgateway
modelsvc-routing.yaml 中主要包含的是针对集群中的模型推理服务的流量规则。这主要包含两部分规则:
- 针对模型推理服务中不同运行时工作负载的动态子集路由能力高
- 针对 kserve v2 推理接口的 JSON/HTTP - gRPC 请求转码能力
我们将在下一个大章节介绍这些能力的细节。
② 使用 kubectl 连接 ASM 实例,执行以下命令,部署 modelsvc-routing 流量规则
kubectl apply -f modelsvc-routing.yaml
③ 使用以下内容,创建 app-routing.yaml 文件
apiVersion: networking.istio.io/v1beta1
kind: Gateway
metadata:
name: ai-app-gateway
namespace: apsara-demo
spec:
selector:
istio: api-ingressgateway
servers:
- hosts:
- '*'
port:
name: http
number: 8000
protocol: HTTP
- hosts:
- '*'
port:
name: http-80
number: 80
protocol: HTTP
---
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: ai-app-vs
namespace: apsara-demo
spec:
gateways:
- ai-app-gateway
hosts:
- '*'
http:
- route:
- destination:
host: ai-backend-svc
port:
number: 8000
---
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: style-transfer-vs
namespace: apsara-demo
spec:
hosts:
- style-transfer.apsara-demo.svc.cluster.local
http:
- match:
- headers:
user_class:
exact: premium
route:
- destination:
host: style-transfer.apsara-demo.svc.cluster.local
port:
number: 8000
subset: tensorflow
- route:
- destination:
host: style-transfer.apsara-demo.svc.cluster.local
port:
number: 8000
subset: pytorch
---
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: style-transfer-dr
namespace: apsara-demo
spec:
host: style-transfer.apsara-demo.svc.cluster.local
subsets:
- labels:
model-format: tensorflow
name: tensorflow
- labels:
model-format: pytorch
name: pytorch
app-routing.yaml 中主要包含的是对 AI 应用服务和 style-transfer 服务的路由规则。其中包括一个对 style-transfer 不同工作负载进行根据用户身份分流的能力。
④ 使用 kubectl 连接 ASM 实例,执行以下命令,部署 app-routing 流量规则
kubectl apply -f app-routing.yaml
⑤ 将 ASM 网关对接阿里云 iDaas 应用身份服务,轻松实现单点登录
搭建整个应用的最后一步位于应用的总入口,也就是 ASM 入口网关。在这里,我们还需要将网关与阿里云 iDaas 的 OIDC 应用进行对接,对整个应用进行一个单点登录的配置。
我们可以参考这篇文档来进行对接的操作:ASM 集成阿里云 IDaaS 实现网格内应用单点登录 [ 13] 。
值得注意的是,我们使用用户 jwt claim 中的额外字段 user_type 来完成用户身份的识别,这需要进行如下操作:
点击云身份服务的扩展字段,添加扩展字段(扩展字段名称和 OIDC 登陆后返回的字段名称均可以自定义,这里扩展字段定义为 user_type,OIDC 登陆后返回字段名称会在后面定义为 user_class):
然后编辑用户信息,为指定用户设置该字段:
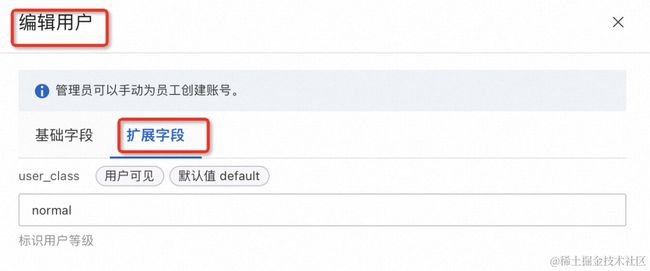
设置好该字段后,需要配置在 OIDC 登陆成功后,返回该字段。进入 OIDC 应用设置,点击登录访问 tab,点击“显示高级配置”。在这里设置新增一个 OIDC 登陆成功后返回的 key-value 对,key 是 user_type,value 是 user_class 的值。

我们披星戴月我们奋不顾身,终于!我们的 AI 应用搭好了!可以看到,从零开始搭建这样一套集成了模型推理的业务服务确实不能一步登天,不过服务网格 ASM 在这其中通过一些生态集成的能力,以及完善的 Web UI,将很多步骤进行了简化。
3、Try it out!
在 ASM 控制台的网格管理页面,我们可以直接看到 api-ingressgateway 的服务地址:
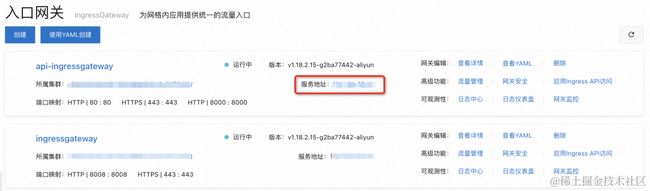
整个应用的访问入口就是 http://{ASM 网关服务地址}/home。用浏览器打开它,就可以开始玩我们的 AI 应用了~
服务网格如何帮助我们
这个章节会简要介绍在这个 DEMO 中,服务网格 ASM 开启了怎样的一些能力,帮助我们做到更多。也就是我们在云栖大会中为大家介绍的内容。
1、针对模型服务运行时的动态子集路由
在 AI 应用的构建中,如何将训练好的模型转化为可靠的推理服务是工作的重心,因此我们首先介绍这个 DEMO 中的模型推理服务。
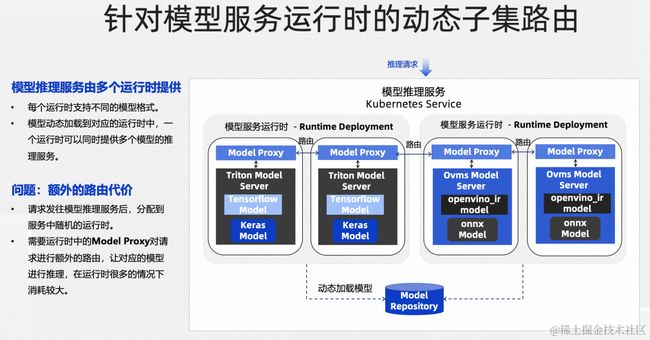
在模型推理服务的整体框架中,由一个整体的 k8s Service 对外提供所有模型的推理。然而,模型有很多格式种类、如何将类似 sklearn、tensorflow、pytorch 等等不同种类的模型统一成 API 相同的推理服务呢?这就要使用不同的运行时。
在统一的模型推理 Service 之下,不同的模型、其推理将交给多个运行时工作负载来完成。每个运行时支持不同的模型格式;并且可以同时提供多个模型的推理服务。当我们使用 InferenceService 资源定义一个模型后,模型文件将根据模型的格式、动态地加载到对应的运行时工作负载之中。一个运行时可以同时提供多个模型的推理服务。
通过这种方式,能够实现高弹性、高灵活性、低消耗的模型推理服务部署。
然而这种方式也存在问题,即存在额外的路由代价。由于 k8s Service 的机制,请求发往模型推理服务后,k8s 不会区分请求的模型格式、而是会随机将请求分发到不同的运行时工作负载,也就无法保证请求能够正确发往可提供服务的运行时。这就需要在运行时中注入额外的 model-proxy,用来进行额外的路由操作、保证请求的正确响应,在运行时规模增大的情况下会造成消耗和性能问题。
这也正是服务网格的重要价值所在。服务网格通过数据面的网格代理,能够动态识别模型推理服务内部、支持不同模型格式的运行时。并在推理请求发出时,根据请求元数据寻找匹配的运行时分组,保证请求能够直接发向正确的运行时,在不额外增加运维成本的同时降低系统路由消耗,这被称作动态子集路由能力。
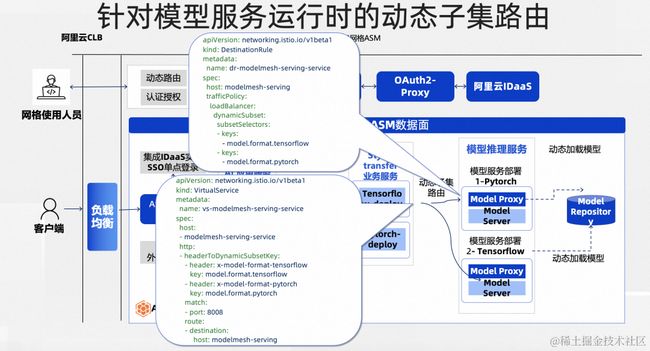
要实现动态子集路由能力,我们只需要使用针对服务配置的 DestinationRule 资源与 VirtualService 资源即可。
对运行时的识别主要通过工作负载的标签,声明一系列模型格式相关的标签,服务网格就将以这些标签为依据、对运行时进行动态分组。在目标规则 DestinationRule 中,主要声明了一系列的标签信息,这些标签将成为工作负载的分组依据。
在下方的虚拟服务 VirtualService 中,我们可以看到基于标签动态分组的路由配置。具体来说,服务网格能够利用请求 header 信息生成请求元数据,元数据包含目标工作负载的标签信息,可以与工作负载的分组进行匹配。
在这个 DEMO 中,我们将请求中以 x-model-format 开头的 header 转换为请求元数据,并与 DestinationRule 中声明的工作负载分组进行匹配,找到请求应该发往的分组。
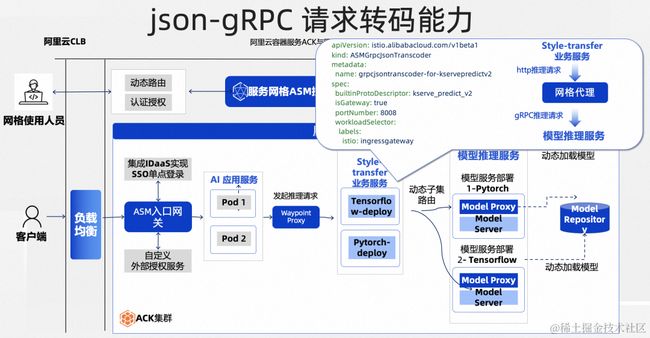
2、Json/http - gRPC 请求转码能力
在实现了动态子集路由的网格代理之上,我们还配置了 json to grpc 的转码能力。
当前,模型推理服务器大多都只实现了 gRPC 协议的服务,而对于依赖模型推理的业务服务来说,则可能是以 restful 等方式来实现服务之间的相互调用。因此,在业务服务调用模型推理服务时,可能存在协议不兼容、导致难以调用的情况。
通过在服务网格中配置 json to grpc 转码能力,原本只能通过 grpc 协议访问的模型推理服务、现在也可以通过 http 传输 json 数据的方式来访问。
如图所示,我们只需要声明 grpc 服务的 proto 描述,集群中的网格代理将替我们完成 restful 请求中 json 数据到 gRPC 请求体的动态转换,为集群中的服务调用增添更多的灵活性,解决调用协议的兼容问题。
3、基于用户身份的 Sidecarless 流量路由能力
让我们将目光投向调用链路的前端,针对 AI 应用服务调用 style-transfer 业务服务的这一环,我们也发挥服务网格的能力,实现了基于用户身份的流量分流。
调用链路的上游是集群中的 style-transfer 业务服务,对于这个业务服务,我们针对 tensorflow 和 pytorch 两种模型,分别提供了名为 style-transfer-tf 和 style-transfer-torch 的不同工作负载,负责将下游应用传入的图片处理为模型可以接受的张量、并交给依赖的模型进行推理。而服务网格负责根据用户身份信息,将下游传输的数据交给不同的工作负载。
我们来看相关配置,首先,还是通过目标规则 DestinationRule 将中台业务服务下不同的工作负载进行分组。接着,虚拟服务 VirtualService 将根据请求中的用户信息,将流量发往不同的工作负载,用不同的模型对请求进行响应。其中请求的用户信息则是用户的 jwt claim,由 OIDC 应用提供。
在本 DEMO 中,服务网格的运用完全基于 Sidecarless 模式,上述能力是通过独立部署的网格代理 waypoint 实现的,也就是说,这些能力的实现不需要任何业务感知,能够大大提高服务网格的运维效率。

4、ASM 网关集成 OIDC 应用实现单点登录能力
最后,在整个调用链路的最前端就是作为流量入口的 ASM 网关。
DEMO 在 ASM 网关上实现了与 OIDC 应用的快速对接来配置单点登录。本次 DEMO 中使用阿里云 idaas 应用身份服务。通过将网关与 OIDC 应用进行对接,网关后的应用无需自己实现身份认证、即可对集群中的应用完成单点登录并拿到用户身份。
如图所示:在服务网格 ASM 中,通过一个完善的 Web 界面即可快速配置与已有 OIDC 应用的对接,这能够大大降低单点登录系统的实现与运维成本,提升运维效率。

小结
最后让我们简单总结一下。在此次的 DEMO 应用中,服务网格 ASM 针对服务调用链路上不同服务的特性以及业务需求,能够灵活配置不同的流量路由以及流量处理规则,快捷地完成应用的各项运维工作;同时,这些能力的生效也是完全基于 Sidecarless 模式,对业务几乎无感知,服务网格进一步沉淀为应用的流量基础设施。作为业务入口的 ASM 入口网关,在满足基础的路由和安全能力之外,还提供丰富的生态集成、证书管理等增强能力,并都辅以完备的 Web 界面帮助用户进行快速配置。
大家可以根据自身需求,选择使用服务网格的相应能力,Let Service Mesh helps you to achieve more!有关更多的产品能力,欢迎参考官方文档 [ 14] 。
相关链接:
[1] 创建 ASM 实例
https://help.aliyun.com/zh/asm/user-guide/create-an-asm-instance#task-2370657
[2] Kubernetes 集群及配置要求
https://help.aliyun.com/zh/asm/user-guide/restrictions-on-use#rwA6T
[3] 创建 Kubernetes 专有版集群
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/create-an-ack-dedicated-cluster#steps-7hk-mqa-7wa
[4] 创建 Kubernetes 托管版集群
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/create-an-ack-managed-cluster-2
[5] 添加集群到 ASM 实例
https://help.aliyun.com/zh/asm/getting-started/add-a-cluster-to-an-asm-instance-1#task-2372122
[6] Istio
https://github.com/istio/istio/releases/tag/1.18.2
[7] ASM 集成云原生推理服务框架 KServe
https://help.aliyun.com/zh/asm/user-guide/integrate-the-cloud-native-inference-service-kserve-with-asm
[8] 管理全局命名空间
https://help.aliyun.com/zh/asm/user-guide/manage-global-namespaces
[9] 通过控制面 kubectl 访问 Istio 资源
https://help.aliyun.com/zh/asm/user-guide/use-kubectl-on-the-control-plane-to-access-istio-resources
[10] 获取集群 KubeConfig 并通过 kubectl 工具连接集群
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/obtain-the-kubeconfig-file-of-a-cluster-and-use-kubectl-to-connect-to-the-cluster
[11] 创建入口网关
https://help.aliyun.com/zh/asm/user-guide/create-an-ingress-gateway?spm=a2c4g.11186623.0.i1
[12] ASM 控制台
https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Fservicemesh.console.aliyun.com%2F&lang=zh
[13] ASM 集成阿里云 IDaaS 实现网格内应用单点登录
https://help.aliyun.com/zh/asm/user-guide/integrate-alibaba-cloud-idaas-with-asm-to-implement-single-sign-on
[14] 官方文档
https://help.aliyun.com/zh/asm
点击此处,即可访问服务网格 ASM 产品详情页。