SeaTunnel批处理同步MySQL数据至ClickHouse

ClickHouse是一种OLAP类型的列式数据库管理系统,ClickHouse完美的实现了OLAP和列式数据库的优势,因此在大数据量的分析处理应用中ClickHouse表现很优秀。
SeaTunnel是一个分布式、高性能、易扩展、用于海量数据同步和转化的数据集成平台。用户只需要配置作业信息,就能完成数据的同步。提交作业后,源连接器负责并行读取数据并将数据发送到下游转换或直接发送到接收器,接收器将数据写入目标。
SeaTunnel任务配置及启动
本示例将MySQL的test数据库下bigtest表中的10000条数据,同步到ClickHouse数据库下default.jdbc中。
MySQL建表语句如下:
CREATE TABLE `bigtest` (
`id` int(11) NOT NULL,
`name` varchar(100) DEFAULT NULL,
`quantity` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
)
向MySQL中插入数据,格式如下:
insert into test.bigtest values(1,'banana',1);

ClickHouse建表语句如下:
CREATE TABLE default.jdbc
(
`id` Int32,
`name` String,
`quantity` Int32
)
ENGINE = MergeTree
ORDER BY id
1、下载jdbc
下载MySQLjdbc并放至 '$SEATNUNNEL_HOME/plugins/jdbc/'目录下
2、编写配置文件
在'$SEATNUNNEL_HOME/config'目录下,新建配置文件mysqltock.template
配置文件内容示例如下:
env {
execution.parallelism = 1
job.mode = "BATCH"
}
source {
jdbc {
url = "jdbc:mysql://localhost/test"
driver = "com.mysql.jdbc.Driver"
user = "root"
password = "123456"
query = "select * from bigtest"
}
}
sink {
clickhouse {
host = "localhost:8123"
database = "default"
table = "jdbc"
username = "default"
password = "123456"
}
}
3、启动任务
在'$SEATNUNNEL_HOME'目录下,使用启动命令:
./bin/seatunnel.sh --config ./config/mysqltock.template -e local
此命令将以 local (本地模式) 运行您的SeaTunnel作业。
当任务运行完毕,会出现本次任务的汇总信息:

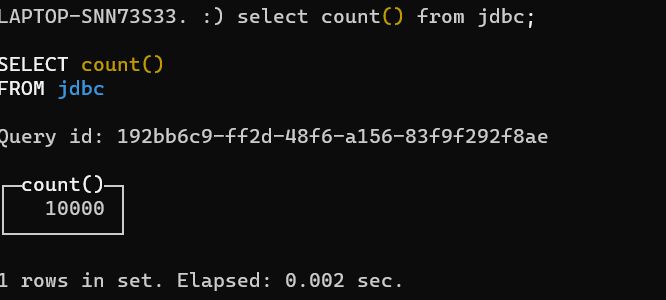
进入ClickHouse,select count() from jdbc查看写入情况,可以看到10000条测试数据已经写入ClickHouse。
总结
本章我们运用数据集成平台SeaTunnel实现了MySQL到ClickHouse的数据同步,使用SeaTunnel仅需要编写配置文件并下载对应的连接器即可。配置化、低代码、易维护是SeaTunnel最显著的特点。
接下来我们将介绍更多数据库到ClickHouse的数据同步流程……