《JavaScript高级程序设计》(红宝书)学习笔记第5-7章
第5章 基本引用类型
对象被认为是某个特定引用类型的实例。新对象通过使用 new 操作符后跟一个构造函数(constructor)来创建。构造函数就是用来创建新对象的函数,比如下面这行代码:
let now = new Date();
这行代码创建了引用类型 Date 的一个新实例,并将它保存在变量 now 中。Date()在这里就是构造函数,它负责创建一个只有默认属性和方法的简单对象。
5.1 Date
Date 类型将日期保存为自协调世界时(UTC,Universal Time Coordinated)时间 1970 年 1 月 1 日午夜(零时)至今所经过的毫秒数。
要创建日期对象,就使用 new 操作符来调用 Date 构造函数:
let now = new Date();
在不给 Date 构造函数传参数的情况下,创建的对象将保存当前日期和时间。要基于其他日期和时间创建日期对象,必须传入其毫秒表示(UNIX 纪元 1970 年 1 月 1 日午夜之后的毫秒数)ECMAScript为此提供了两个辅助方法:Date.parse()和 Date.UTC()
Date.parse()方法接收一个表示日期的字符串参数,尝试将这个字符串转换为表示该日期的毫秒数。ECMA-262 第 5 版定义了 Date.parse()应该支持的日期格式。所有实现都必须支持下列日期格式:
-
“月/日/年”,如"5/23/2019";
-
“月名 日, 年”,如"May 23, 2019";
-
“周几 月名 日 年 时:分:秒 时区”,如"Tue May 23 2019 00:00:00 GMT-0700";
-
ISO 8601 扩展格式“YYYY-MM-DDTHH:mm:ss.sssZ”,如 2019-05-23T00:00:00(只适用于兼容 ES5 的实现)。
比如,要创建一个表示“2019 年 5 月 23 日”的日期对象,可以使用以下代码:
let someDate = new Date(Date.parse("May 23, 2019"));
如果传给 Date.parse()的字符串并不表示日期,则该方法会返回 NaN。如果直接把表示日期的字符串传给 Date 构造函数,那么 Date 会在后台调用 Date.parse()。换句话说,下面这行代码跟前面那行代码是等价的:
let someDate = new Date("May 23, 2019");
这两行代码得到的日期对象相同。
Date.UTC()方法也返回日期的毫秒表示.传给 Date.UTC()的参数是年、零起点月数(1 月是 0,2 月是 1,以此类推)、日(1~31)、时(0-23)分、秒和毫秒。这些参数中,只有前两个(年和月)是必需的。如果不提供日,那么默认为 1 日。其他参数的默认值都是 0。下面是使用 Date.UTC()的两个例子:
// GMT 时间 2000 年 1 月 1 日零点
let y2k = new Date(Date.UTC(2000, 0));
// GMT 时间 2005 年 5 月 5 日下午 5 点 55 分 55 秒
let allFives = new Date(Date.UTC(2005, 4, 5, 17, 55, 55));
这个例子创建了两个日期 。第一个日期是 2000 年 1 月 1 日零点(GMT),2000 代表年,0 代表月(1 月)。因为没有其他参数(日取 1,其他取 0),所以结果就是该月第 1 天零点。第二个日期表示 2005年 5 月 5 日下午 5 点 55 分 55 秒(GMT)。虽然日期里面涉及的都是 5,但月数必须用 4,因为月数是零起点的。小时也必须是 17,因为这里采用的是 24 小时制,即取值范围是 0~23。其他参数就都很直观了。
与 Date.parse()一样,Date.UTC()也会被 Date 构造函数隐式调用,但有一个区别:这种情况下创建的是本地日期,不是 GMT 日期。不过 Date 构造函数跟 Date.UTC()接收的参数是一样的。因此,如果第一个参数是数值,则构造函数假设它是日期中的年,第二个参数就是月,以此类推。前面的例子也可以这样来写:
// 本地时间 2000 年 1 月 1 日零点
let y2k = new Date(2000, 0);
// 本地时间 2005 年 5 月 5 日下午 5 点 55 分 55 秒
let allFives = new Date(2005, 4, 5, 17, 55, 55);
以上代码创建了与前面例子相同的两个日期,但这次的两个日期是(由于系统设置决定的)本地时区的日期。
ECMAScript 还提供了 Date.now()方法,返回表示方法执行时日期和时间的毫秒数
// 起始时间
let start = Date.now();
// 调用函数
doSomething();
// 结束时间
let stop = Date.now(),
result = stop - start;
5.1.1 继承的方法
Date 类型的 toLocaleString()方法返回与浏览器运行的本地环境一致的日期和时间。这通常意味着格式中包含针对时间的 AM(上午)或 PM(下午),但不包含时区信息(具体格式可能因浏览器而不同)。
toString()方法通常返回带时区信息的日期和时间,而时间也是以 24 小时制(0~23)表示的。
下面给出了 toLocaleString()和 toString()返回的2019 年 2 月 1 日零点的示例(地区为"en-US"的 PST,即 Pacific Standard Time,太平洋标准时间)
toLocaleString() - 2/1/2019 12:00:00 AM
toString() - Thu Feb 1 2019 00:00:00 GMT-0800 (Pacific Standard Time)
Date 类型的 valueOf()方法根本就不返回字符串,这个方法被重写后返回的是日期的毫秒表示。因此,操作符(如小于号和大于号)可以直接使用它返回的值。比如下面的例子:
let date1 = new Date(2019, 0, 1); // 2019 年 1 月 1 日
let date2 = new Date(2019, 1, 1); // 2019 年 2 月 1 日
console.log(date1 < date2); // true
console.log(date1 > date2); // false
日期 2019 年 1 月 1 日在 2019 年 2 月 1 日之前,所以说前者小于后者没问题。因为 2019 年 1 月 1 日的毫秒表示小于 2019 年 2 月 1 日的毫秒表示,所以用小于号比较这两个日期时会返回 true。这也是确保日期先后的一个简单方式。
5.1.2 日期格式化方法
Date 类型有几个专门用于格式化日期的方法,它们都会返回字符串:
-
toDateString()显示日期中的周几、月、日、年(格式特定于实现);
-
toTimeString()显示日期中的时、分、秒和时区(格式特定于实现);
-
toLocaleDateString()显示日期中的周几、月、日、年(格式特定于实现和地区);
-
toLocaleTimeString()显示日期中的时、分、秒(格式特定于实现和地区);
-
toUTCString()显示完整的 UTC 日期(格式特定于实现)。
这些方法的输出与 toLocaleString()和 toString()一样,会因浏览器而异。因此不能用于在用户界面上一致地显示日期
5.1.3 日期/时间组件方法
Date 类型剩下的方法(见下表)直接涉及取得或设置日期值的特定部分。注意表中“UTC 日期”,指的是没有时区偏移(将日期转换为 GMT)时的日期。


5.2 RegExp
ECMAScript 通过 RegExp 类型支持正则表达式。正则表达式使用简洁语法来创建:
let expression = /pattern/flags;
这个正则表达式的 pattern(模式)可以是任何简单或复杂的正则表达式,包括字符类、限定符、分组、向前查找和反向引用。每个正则表达式可以带零个或多个 flags(标记),用于控制正则表达式的行为。下面给出了表示匹配模式的标记。
- g:全局模式,表示查找字符串的全部内容,而不是找到第一个匹配的内容就结束。
- i:不区分大小写,表示在查找匹配时忽略 pattern 和字符串的大小写。
- m:多行模式,表示查找到一行文本末尾时会继续查找。
- y:粘附模式,表示只查找从 lastIndex 开始及之后的字符串。
- u:Unicode 模式,启用 Unicode 匹配。
- s:dotAll 模式,表示元字符.匹配任何字符(包括\n 或\r)
剩余部分请自行看书
5.3 原始值包装类型
为了方便操作原始值,ECMAScript 提供了 3 种特殊的引用类型:Boolean、Number 和 String。每当用到某个原始值的方法或属性时,后台都会创建一个相应原始包装类型的对象,从而暴露出操作原始值的各种方法。来看下面的例子:
let s1 = "some text";
let s2 = s1.substring(2);
在这里,s1 是一个包含字符串的变量,它是一个原始值。第二行紧接着在 s1 上调用了 substring()方法,并把结果保存在 s2 中。我们知道,原始值本身不是对象,因此逻辑上不应该有方法,具体来说,当第二行访问 s1 时,是以读模式访问的,也就是要从内存中读取变量保存的值。在以读模式访问字符串值的任何时候,后台都会执行以下 3 步:
(1) 创建一个 String 类型的实例;
(2) 调用实例上的特定方法;
(3) 销毁实例。
可以把这 3 步想象成执行了如下 3 行 ECMAScript 代码:
let s1 = new String("some text");
let s2 = s1.substring(2);
s1 = null;
这种行为可以让原始值拥有对象的行为。对布尔值和数值而言,以上 3 步也会在后台发生,只不过使用的是 Boolean 和 Number 包装类型而已。
引用类型与原始值包装类型的主要区别在于对象的生命周期。在通过 new 实例化引用类型后,得到的实例会在离开作用域时被销毁,而自动创建的原始值包装对象则只存在于访问它的那行代码执行期间。这意味着不能在运行时给原始值添加属性和方法。比如下面的例子:
let s1 = "some text";
s1.color = "red";
console.log(s1.color); // undefined
这里的第二行代码尝试给字符串 s1 添加了一个 color 属性。可是,第三行代码访问 color 属性时,它却不见了。原因就是第二行代码运行时会临时创建一个 String 对象,而当第三行代码执行时,这个对象已经被销毁了。实际上,第三行代码在这里创建了自己的 String 对象,但这个对象没有 color 属性。
可以显式地使用 Boolean、Number 和 String 构造函数创建原始值包装对象。不过应该在确实必要时再这么做,否则容易让开发者疑惑,分不清它们到底是原始值还是引用值。在原始值包装类型的实例上调用 typeof 会返回"object",所有原始值包装对象都会转换为布尔值 true。
另外,Object 构造函数作为一个工厂方法,能够根据传入值的类型返回相应原始值包装类型的实例。比如:
let obj = new Object("some text");
console.log(obj instanceof String); // true
如果传给 Object 的是字符串,则会创建一个 String 的实例。如果是数值,则会创建 Number 的实例。布尔值则会得到 Boolean 的实例。注意,使用 new 调用原始值包装类型的构造函数,与调用同名的转型函数并不一样。例如:
let value = "25";
let number = Number(value); // 转型函数
console.log(typeof number); // "number"
let obj = new Number(value); // 构造函数
console.log(typeof obj); // "object"
在这个例子中,变量 number 中保存的是一个值为 25 的原始数值,而变量 obj 中保存的是一个Number 的实例。
虽然不推荐显式创建原始值包装类型的实例,但它们对于操作原始值的功能是很重要的。每个原始值包装类型都有相应的一套方法来方便数据操作。
5.3.1 Boolean
Boolean 是对应布尔值的引用类型。要创建一个 Boolean 对象,就使用 Boolean 构造函数并传入true 或 false,如下例所示:
let booleanObject = new Boolean(true);
Boolean 的实例会重写 valueOf()方法,返回一个原始值 true 或 false。toString()方法返回字符串"true"或"false"。
Boolean 对象在 ECMAScript 中用得很少。不仅如此,它们还容易引起误会,尤其是在布尔表达式中使用 Boolean 对象时,比如:
let falseObject = new Boolean(false);
let result = falseObject && true;
console.log(result); // true
let falseValue = false;
result = falseValue && true;
console.log(result); // false
在布尔算术中,false && true 等于 false。可是,这个表达式是对 falseObject 对象而不是对它表示的值(false)求值。所有对象在布尔表达式中都会自动转换为 true,因此 falseObject 在这个表达式里实际上表示一个 true 值。那么true && true 当然是 true。
除此之外,原始值和引用值(Boolean 对象)还有几个区别。首先,typeof 操作符对原始值返回"boolean",但对引用值返回"object"。同样,Boolean 对象是 Boolean 类型的实例,在使用instaceof 操作符时返回 true,但对原始值则返回 false,如下所示:
console.log(typeof falseObject); // object
console.log(typeof falseValue); // boolean
console.log(falseObject instanceof Boolean); // true
console.log(falseValue instanceof Boolean); // false
理解原始布尔值和 Boolean 对象之间的区别非常重要,强烈建议永远不要使用后者。
5.3.2 Number
Number 是对应数值的引用类型。要创建一个 Number 对象,就使用 Number 构造函数并传入一个数值,如下例所示:
let numberObject = new Number(10);
Boolean 类型一样,Number 类型重写了 valueOf()、toLocaleString()和 toString()方法。valueOf()方法返回 Number 对象表示的原始数值,另外两个方法返回数值字符串。toString()方法可选地接收一个表示基数的参数,并返回相应基数形式的数值字符串,如下所示:
let num = 10;
console.log(num.toString()); // "10"
console.log(num.toString(2)); // "1010"
console.log(num.toString(8)); // "12"
console.log(num.toString(10)); // "10"
console.log(num.toString(16)); // "a"
扩展:对比toString()与parseInt()
let num = 10;
let num1 = parseInt(num, 2);
console.log(num1); //2 按二进制解析
console.log(typeof num1);//number
let num2 = num.toString(2);
console.log(num2);//1010 解析为二进制
console.log(typeof num2);//string
除了继承的方法,Number 类型还提供了几个用于将数值格式化为字符串的方法。
toFixed()方法返回包含指定小数点位数的数值字符串,如:
let num = 10;
console.log(num.toFixed(2)); // "10.00"
这里的 toFixed()方法接收了参数 2,表示返回的数值字符串要包含两位小数。结果返回值为"10.00",小数位填充了 0。如果数值本身的小数位超过了参数指定的位数,则四舍五入到最接近的小数位:
let num = 10.005;
console.log(num.toFixed(2)); // "10.01"
补充;toFixed()可能会出现精度问题,比如:
let num = 1.4250;
console.log(num.toFixed(2)); //1.43
另一个用于格式化数值的方法是 toExponential(),返回以科学记数法(也称为指数记数法)表示的数值字符串。与 toFixed()一样,toExponential()也接收一个参数,表示结果中小数的位数。来看下面的例子:
let num = 10;
console.log(num.toExponential(1)); // "1.0e+1"
这段代码的输出为"1.0e+1"。一般来说,这么小的数不用表示为科学记数法形式。如果想得到数值最适当的形式,那么可以使用 toPrecision()。
toPrecision()方法会根据情况返回最合理的输出结果,可能是固定长度,也可能是科学记数法形式。这个方法接收一个参数,表示结果中数字的总位数(不包含指数)。来看几个例子:
let num = 99;
console.log(num.toPrecision(1)); // "1e+2"
console.log(num.toPrecision(2)); // "99"
console.log(num.toPrecision(3)); // "99.0"
在这个例子中,首先要用 1 位数字表示数值 99,得到"1e+2",也就是 100。因为 99 不能只用 1 位数字来精确表示,所以这个方法就将它舍入为 100,这样就可以只用 1 位数字(及其科学记数法形式)来表示了。用 2 位数字表示 99 得到"99",用 3 位数字则是"99.0"。本质上,toPrecision()方法会根据数值和精度来决定调用 toFixed()还是 toExponential()。为了以正确的小数位精确表示数值,这 3 个方法都会向上或向下舍入。
与 Boolean 对象类似,Number 对象也为数值提供了重要能力。但是,考虑到两者存在同样的潜在问题,因此并不建议直接实例化 Number 对象。在处理原始数值和引用数值时,typeof 和 instacnceof操作符会返回不同的结果,如下所示:
let numberObject = new Number(10);
let numberValue = 10;
console.log(typeof numberObject); // "object"
console.log(typeof numberValue); // "number"
console.log(numberObject instanceof Number); // true
console.log(numberValue instanceof Number); // false
原始数值在调用 typeof 时始终返回"number",而 Number 对象则返回"object"。类似地,Number对象是 Number 类型的实例,而原始数值不是。
**isInteger()**方法与安全整数Number.isSafeInteger()
ES6 新增了 Number.isInteger()方法,用于辨别一个数值是否保存为整数。有时候,小数位的 0可能会让人误以为数值是一个浮点值:
console.log(Number.isInteger(1)); // true
console.log(Number.isInteger(1.00)); // true
console.log(Number.isInteger(1.01)); // false
IEEE 754 数值格式有一个特殊的数值范围,在这个范围内二进制值可以表示一个整数值。这个数值范围从 Number.MIN_SAFE_INTEGER(-2^53 + 1)到 Number.MAX_SAFE_INTEGER(2^53 - 1)。对超出这个范围的数值,即使尝试保存为整数,IEEE 754 编码格式也意味着二进制值可能会表示一个完全不同的数值。为了鉴别整数是否在这个范围内,可以使用 Number.isSafeInteger()方法:
console.log(Number.isSafeInteger(-1 * (2 ** 53))); // false
console.log(Number.isSafeInteger(-1 * (2 ** 53) + 1)); // true
console.log(Number.isSafeInteger(2 ** 53)); // false
console.log(Number.isSafeInteger((2 ** 53) - 1)); // true
5.3.3 String
String 是对应字符串的引用类型。要创建一个 String 对象,使用 String 构造函数并传入一个数值,如下例所示:
let stringObject = new String("hello world");
String 对象的方法可以在所有字符串原始值上调用。3个继承的方法 valueOf()、toLocaleString()和 toString()都返回对象的原始字符串值。
每个 String 对象都有一个 length 属性,表示字符串中字符的数量。来看下面的例子:
let stringValue = "hello world";
console.log(stringValue.length); // "11"
注意,即使字符串中包含双字节字符(而不是单字节的 ASCII 字符),也仍然会按单字符来计数。
1.JavaScript 字符
JavaScript 字符串由 16 位码元(code unit)组成。对多数字符来说,每 16 位码元对应一个字符。换=句话说,字符串的 length 属性表示字符串包含多少 16 位码元:
let message = "abcde";
console.log(message.length); // 5
此外,charAt()方法返回给定索引位置的字符,由传给方法的整数参数指定。具体来说,这个方法查找指定索引位置的 16 位码元,并返回该码元对应的字符:
let message = "abcde";
console.log(message.charAt(2)); // "c"
使用 charCodeAt()方法可以查看指定码元的字符编码。这个方法返回指定索引位置的码元值,索引以整数指定。比如:
let message = "abcde";
// Unicode "Latin small letter C"的编码是 U+0063
console.log(message.charCodeAt(2)); // 99
// 十进制 99 等于十六进制 63
console.log(99 === 0x63); // true
fromCharCode()方法用于根据给定的 UTF-16 码元创建字符串中的字符。这个方法可以接受任意多个数值,并返回将所有数值对应的字符拼接起来的字符串:
// Unicode "Latin small letter A"的编码是 U+0061
// Unicode "Latin small letter B"的编码是 U+0062
// Unicode "Latin small letter C"的编码是 U+0063
// Unicode "Latin small letter D"的编码是 U+0064
// Unicode "Latin small letter E"的编码是 U+0065
console.log(String.fromCharCode(0x61, 0x62, 0x63, 0x64, 0x65)); // "abcde"
// 0x0061 === 97
// 0x0062 === 98
// 0x0063 === 99
// 0x0064 === 100
// 0x0065 === 101
console.log(String.fromCharCode(97, 98, 99, 100, 101)); // "abcde"
对于 U+0000~U+FFFF 范围内的字符,length、charAt()、charCodeAt()和 fromCharCode()返回的结果都跟预期是一样的。这是因为在这个范围内,每个字符都是用 16 位表示的,而这几个方法也都基于 16 位码元完成操作。只要字符编码大小与码元大小一一对应,这些方法就能如期工作。
这个对应关系在扩展到 Unicode 增补字符平面时就不成立了。在 Unicode 中称为基本多语言平面(BMP)。为了表示更多的字符,Unicode 采用了一个策略,即每个字符使用另外 16 位去选择一个增补平面。这种每个字符使用两个 16 位码元的策略称为代理对。
在涉及增补平面的字符时,前面讨论的字符串方法就会出问题。比如,下面的例子中使用了一个笑脸表情符号,也就是一个使用代理对编码的字符:
// "smiling face with smiling eyes" 表情符号的编码是 U+1F60A
// 0x1F60A === 128522
let message = "ab☺de";
console.log(message.length); // 6
console.log(message.charAt(1)); // b
console.log(message.charAt(2)); //
console.log(message.charAt(3)); //
console.log(message.charAt(4)); // d
console.log(message.charCodeAt(1)); // 98
console.log(message.charCodeAt(2)); // 55357
console.log(message.charCodeAt(3)); // 56842
console.log(message.charCodeAt(4)); // 100
console.log(String.fromCodePoint(0x1F60A)); // ☺
console.log(String.fromCharCode(97, 98, 55357, 56842, 100, 101)); // ab☺de
这些方法仍然将 16 位码元当作一个字符,事实上索引 2 和索引 3 对应的码元应该被看成一个代理对,只对应一个字符.fromCharCode()方法仍然返回正确的结果,因为它实际上是基于提供的二进制表示直接组合成字符串。浏览器可以正确解析代理对(由两个码元构成),并正确地将其识别为一个Unicode 笑脸字符。
为正确解析既包含单码元字符又包含代理对字符的字符串,可以使用 codePointAt()来代替charCodeAt()。跟使用 charCodeAt()时类似,codePointAt()接收 16 位码元的索引并返回该索引位置上的码点(code point)。码点是 Unicode 中一个字符的完整标识。比如,"c"的码点是 0x0063,而"☺"的码点是 0x1F60A。码点可能是 16 位,也可能是 32 位,而 codePointAt()方法可以从指定码元位置识别完整的码点。
let message = "ab☺de";
console.log(message.codePointAt(1)); // 98
console.log(message.codePointAt(2)); // 128522
console.log(message.codePointAt(3)); // 56842
console.log(message.codePointAt(4)); // 100
注意,如果传入的码元索引并非代理对的开头,就会返回错误的码点。这种错误只有检测单个字符的时候才会出现,可以通过从左到右按正确的码元数遍历字符串来规避。迭代字符串可以智能地识别代理对的码点:
console.log([..."ab☺de"]); // ["a", "b", "☺", "d", "e"]
与 charCodeAt()有对应的 codePointAt()一样,fromCharCode()也有一个对应的 fromCodePoint()。这个方法接收任意数量的码点,返回对应字符拼接起来的字符串:
console.log(String.fromCharCode(97, 98, 55357, 56842, 100, 101)); // ab☺de
console.log(String.fromCodePoint(97, 98, 128522, 100, 101)); // ab☺de
2.**normalize()**方法 想了解的可以自己看书
3.字符串操作方法
3.1 concat()方法 用于将一个或多个字符串拼接成一个新字符串,原字符串保持不变
举个例子:
let stringValue = "hello ";
let result = stringValue.concat("world");
console.log(result); // "hello world"
console.log(stringValue); // "hello"
在这个例子中,对 stringValue 调 用 concat()方法的结果是得到"hello world", 但stringValue 的值保持不变。
concat()方法可以接收任意多个参数,因此可以一次性拼接多个字符串,如下所示:
let stringValue = "hello ";
let result = stringValue.concat("world", "!");
console.log(result); // "hello world!"
console.log(stringValue); // "hello"
虽然 concat()方法可以拼接字符串,但更常用的方式是使用加号操作符(+)。而且多数情况下,对于拼接多个字符串来说,使用加号更方便。
3.2 slice()方法 返回调用它们的字符串的一个子字符串
接收参数:接收一或两个参数 第一个参数表示子字符串开始的位置,第二个参数是提取结束的位置(即该位置之前的字符会被提取出来)前闭后开[),省略第二个参数都意味着提取到字符串末尾 将所有负值参数都当成字符串长度加上负参数值。
返回结果:都不会修改调用它们的字符串,而只会返回提取到的原始新字符串值
3.3 substr()方法 返回调用它们的字符串的一个子字符串
接收参数:接收一或两个参数 第一个参数表示子字符串开始的位置,第二个参数表示返回的子字符串数量 任何情况下,省略第二个参数都意味着提取到字符串末尾 将第一个负参数值当成字符串长度加上该值,将第二个负参数值转换为 0
返回结果:都不会修改调用它们的字符串,而只会返回提取到的原始新字符串值
3.4 substring()方法 返回调用它们的字符串的一个子字符串
接收参数:接收一或两个参数 第一个参数表示子字符串开始的位置,第二个参数是提取结束的位置(即该位置之前的字符会被提取出来)前闭后开[),省略第二个参数都意味着提取到字符串末尾 将所有负参数值都转换为 0
返回结果:都不会修改调用它们的字符串,而只会返回提取到的原始新字符串值
举个例子(正数):
let stringValue = "hello world";
console.log(stringValue.slice(3)); // "lo world"
console.log(stringValue.substring(3)); // "lo world"
console.log(stringValue.substr(3)); // "lo world"
console.log(stringValue.slice(3, 7)); // "lo w"
console.log(stringValue.substring(3,7)); // "lo w"
console.log(stringValue.substr(3, 7)); // "lo worl"
在这个例子中,slice()、substr()和 substring()是以相同方式被调用的,而且多数情况下返回的值也相同。如果只传一个参数 3,则所有方法都将返回"lo world",因为"hello"中"l"位置为 3。如果传入两个参数 3 和 7,则 slice()和 substring()返回"lo w"(因为"world"中"o"在位置 7,不包含),而 substr()返回"lo worl",因为第二个参数对它而言表示返回的字符数。
举个例子(负数):
let stringValue = "hello world";
console.log(stringValue.slice(-3)); // "rld"
console.log(stringValue.substring(-3)); // "hello world"
console.log(stringValue.substr(-3)); // "rld"
console.log(stringValue.slice(3, -4)); // "lo w"
console.log(stringValue.substring(3, -4)); // "hel"
console.log(stringValue.substr(3, -4)); // "" (empty string)
在给 slice()和 substr()传入负参数时,它们的返回结果相同。这是因为-3 会被转换为 8(长度加上负参数),实际上调用的是 slice(8)和 substr(8)。而substring()方法返回整个字符串,因为-3 会转换为 0。在第二个参数是负值时,这 3 个方法各不相同。slice()方法将第二个参数转换为 7,实际上相当于调用 slice(3, 7),因此返回"lo w"。而 substring()方法会将第二个参数转换为 0,相当于调用substring(3, 0),等价于 substring(0, 3),这是substring()方法会将较小的参数作为起点,将较大的参数作为终点。对 substr()来说,第二个参数会被转换为 0,意味着返回的字符串包含零个字符,因而会返回一个空字符串。
4.字符串位置方法
有两个方法用于在字符串中定位子字符串:indexOf()和 lastIndexOf()。这两个方法从字符串中搜索传入的字符串,并返回位置(如果没找到,则返回-1)检索到目标字符串立即停止
两者的区别在于,indexOf()方法从字符串开头开始查找子字符串,而 lastIndexOf()方法从字符串末尾开始查找子字符串。
来看下面的例子:
let stringValue = "hello world";
console.log(stringValue.indexOf("o")); // 4 "hello"中的"o"
console.log(stringValue.lastIndexOf("o")); // 7 "world"中的"o"
这两个方法都可以接收可选的第二个参数,表示开始搜索的位置。这意味着,indexOf()会从这个参数指定的位置开始向字符串末尾搜索,忽略该位置之前的字符;lastIndexOf()则会从这个参数指定的位置开始向字符串开头搜索,忽略该位置之后直到字符串末尾的字符。下面看一个例子:
let stringValue = "hello world";
console.log(stringValue.indexOf("o", 6)); // 7
console.log(stringValue.lastIndexOf("o", 6)); // 4
在传入第二个参数 6 以后,结果跟前面的例子恰好相反。这一次,indexOf()返回 7,因为它从位置 6(字符"w")开始向后搜索字符串,在位置 7 找到了"o"。而 lastIndexOf()返回 4,因为它从位置 6 开始反向搜索至字符串开头,因此找到了"hello"中的"o"。
通过使用第二个参数并循环调用indexOf()或 lastIndexOf(),可以在字符串中找到所有的目标子字符串,如下所示:
let stringValue = "Lorem ipsum dolor sit amet, consectetur adipisicing elit";
let positions = new Array();
let pos = stringValue.indexOf("e"); //获取第一个"e"的位置
while(pos > -1) {
positions.push(pos);
pos = stringValue.indexOf("e", pos + 1); //从上一次返回的下一个字符开始搜索
}
console.log(positions); // [3,24,32,35,52]
5.字符串包含方法
ECMAScript 6 增加了 3 个用于判断字符串中是否包含另一个字符串的方法:startsWith()、endsWith()和 includes()。这些方法都会从字符串中搜索传入的字符串,并返回一个表示是否包含的布尔值。它们的区别在于,startsWith()检查开始于索引 0 的匹配项endsWith()检查开始于索引(string.length - substring.length)的匹配项,而 includes()检查整个字符串:
let message = "foobarbaz";
console.log(message.startsWith("foo")); // true
console.log(message.startsWith("bar")); // false
console.log(message.endsWith("baz")); // true
console.log(message.endsWith("bar")); // false
console.log(message.includes("bar")); // true
console.log(message.includes("qux")); // false
startsWith()和 includes()方法接收可选的第二个参数,表示开始搜索的位置。如果传入第二个参数,则意味着这两个方法会从指定位置向着字符串末尾搜索,忽略该位置之前的所有字符。下面是一个例子:
let message = "foobarbaz";
console.log(message.startsWith("foo")); // true
console.log(message.startsWith("foo", 1)); // false
console.log(message.includes("bar")); // true
console.log(message.includes("bar", 4)); // false
endsWith()方法接收可选的第二个参数,表示应该当作****字符串末尾的位置。如果不提供这个参数,那么默认就是字符串长度。如果提供这个参数,那么就好像字符串只有那么多字符一样:
let message = "foobarbaz";
console.log(message.endsWith("bar")); // false
console.log(message.endsWith("bar", 6)); // true
6.**trim()**方法
ECMAScript 在所有字符串上都提供了 trim()方法。这个方法会创建字符串的一个副本,删除前、后所有空格符,再返回结果。比如:
let stringValue = " hello world ";
let trimmedStringValue = stringValue.trim();
console.log(stringValue); // " hello world "
console.log(trimmedStringValue); // "hello world"
由于 trim()返回的是字符串的副本,因此原始字符串不受影响,即原本的前、后空格符都会保留。
另外,trimLeft()和 trimRight()方法分别用于从字符串开始和末尾清理空格符。
7.repeat()方法
ECMAScript 在所有字符串上都提供了 repeat()方法。这个方法接收一个整数参数,表示要将字符串复制多少次,然后返回拼接所有副本后的结果
let stringValue = "na ";
console.log(stringValue.repeat(16) + "batman");
// na na na na na na na na na na na na na na na na batman
8.padStart()**和 **padEnd()方法
padStart()和 padEnd()方法会复制字符串,如果小于指定长度,则在相应一边填充字符,直至满足长度条件。这两个方法的第一个参数是长度,第二个参数是可选的填充字符串,默认为空格
let stringValue = "foo";
console.log(stringValue.padStart(6)); // " foo"
console.log(stringValue.padStart(9, ".")); // "......foo"
console.log(stringValue.padEnd(6)); // "foo "
console.log(stringValue.padEnd(9, ".")); // "foo......"
可选的第二个参数并不限于一个字符。如果提供了多个字符的字符串,则会将其拼接并截断以匹配指定长度。此外,如果长度小于或等于字符串长度,则会返回原始字符串。
let stringValue = "foo";
console.log(stringValue.padStart(8, "bar")); // "barbafoo"
console.log(stringValue.padStart(2)); // "foo"
console.log(stringValue.padEnd(8, "bar")); // "foobarba"
console.log(stringValue.padEnd(2)); // "foo"
9.字符串迭代与解构
字符串的原型上暴露了一个@@iterator 方法,表示可以迭代字符串的每个字符。可以像下面这样手动使用迭代器:
let message = "abc";
let stringIterator = message[Symbol.iterator]();
console.log(stringIterator.next()); // {value: "a", done: false}
console.log(stringIterator.next()); // {value: "b", done: false}
console.log(stringIterator.next()); // {value: "c", done: false}
console.log(stringIterator.next()); // {value: undefined, done: true}
在 for-of 循环中可以通过这个迭代器按序访问每个字符:
for (const c of "abcde") {
console.log(c);
}
// a
// b
// c
// d
// e
有了这个迭代器之后,字符串就可以通过解构操作符来解构了。比如,可以更方便地把字符串分割为字符数组:
let message = "abcde";
console.log([...message]); // ["a", "b", "c", "d", "e"]
10.字符串大小写转换
涉及大小写转换,包括 4 个方法:toLowerCase()、toLocaleLowerCase()、toUpperCase()和toLocaleUpperCase()
toLowerCase()和toUpperCase()方法是原来就有的方法。toLocaleLowerCase()和 toLocaleUpperCase()方法旨在基于特定地区实现。
下面是几个例子:
let stringValue = "hello world";
console.log(stringValue.toLocaleUpperCase()); // "HELLO WORLD"
console.log(stringValue.toUpperCase()); // "HELLO WORLD"
console.log(stringValue.toLocaleLowerCase()); // "hello world"
console.log(stringValue.toLowerCase()); // "hello world"
通常,如果不知道代码涉及什么语言,则最好使用地区特定的转换方法。
11.**localeCompare()**方法
比较两个字符串,返回如下 3 个值中的一个
-
如果按照字母表顺序,字符串应该排在字符串参数前头,则返回负值。(通常是-1,具体还要看与实际值相关的实现。)
-
如果字符串与字符串参数相等,则返回 0。
-
如果按照字母表顺序,字符串应该排在字符串参数后头,则返回正值。(通常是 1,具体还要看与实际值相关的实现。)
下面是一个例子:
let stringValue = "yellow";
console.log(stringValue.localeCompare("brick")); // 1
console.log(stringValue.localeCompare("yellow")); // 0
console.log(stringValue.localeCompare("zoo")); // -1
在这里,字符串"yellow"与 3 个不同的值进行了比较:“brick”、“yellow"和"zoo”。"brick"按字母表顺序应该排在"yellow"前头,因此 localeCompare()返回 1。“yellow"等于"yellow”,因此"localeCompare()"返回 0。最后,"zoo"在"yellow"后面,因此 localeCompare()返回-1。
因为返回的具体值可能因具体实现而异,所以最好像下面的示例中一样使用 localeCompare():
function determineOrder(value) {
let result = stringValue.localeCompare(value);
if (result < 0) {
console.log(`The string 'yellow' comes before the string '${value}'.`);
} else if (result > 0) {
console.log(`The string 'yellow' comes after the string '${value}'.`);
} else {
console.log(`The string 'yellow' is equal to the string '${value}'.`);
}
}
determineOrder("brick");
determineOrder("yellow");
determineOrder("zoo");
localeCompare()的独特之处在于,实现所在的地区(国家和语言)决定了这个方法如何比较字符串。
5.4 单例内置对象
ECMA-262 对内置对象的定义是“任何由 ECMAScript 实现提供、与宿主环境无关,并在 ECMAScript程序开始执行时就存在的对象”。这就意味着,开发者不用显式地实例化内置对象,因为它们已经实例化好了。前面我们已经接触了大部分内置对象,包括 Object、Array 和 String。本节介绍 ECMA-262定义的另外两个单例内置对象:Global 和 Math。
5.4.1 Global
Global 对象是 ECMAScript 中最特别的对象,代码不会显式地访问它。ECMA-262 规定 Global对象为一种兜底对象,它所针对的是不属于任何对象的属性和方法。事实上,不存在全局变量或全局函数这种东西。在全局作用域中定义的变量和函数都会变成 Global 对象的属性 。本书前面介绍的函数,包括 isNaN()、isFinite()、parseInt()和 parseFloat(),实际上都是 Global 对象的方法。除了这些,Global 对象上还有另外一些方法。
1.URL 编码方法
encodeURI()和 encodeURIComponent()方法用于编码统一资源标识符(URI),以便传给浏览器。有效的 URI 不能包含某些字符,比如空格。使用 URI 编码方法来编码 URI 可以让浏览器能够理解它们,同时又以特殊的 UTF-8 编码替换掉所有无效字符。
ecnodeURI()方法用于对整个 URI 进行编码,比如"www.wrox.com/illegal value.js"。而encodeURIComponent()方法用于编码 URI 中单独的组件,比如前面 URL 中的"illegal value.js"。这两个方法的主要区别是,encodeURI()不会编码属于 URL 组件的特殊字符,比如冒号、斜杠、问号、井号,而 encodeURIComponent()会编码它发现的所有非标准字符。来看下面的例子:
let uri = "http://www.wrox.com/illegal value.js#start";
// "http://www.wrox.com/illegal%20value.js#start"
console.log(encodeURI(uri));
// "http%3A%2F%2Fwww.wrox.com%2Fillegal%20value.js%23start"
console.log(encodeURIComponent(uri));
这里使用 encodeURI()编码后,除空格被替换为%20 之外,没有任何变化。而 encodeURIComponent()方法将所有非字母字符都替换成了相应的编码形式。这就是使用 encodeURI()编码整个URI,但只使用 encodeURIComponent()编码那些会追加到已有 URI 后面的字符串的原因。
注意 一般来说,使用 encodeURIComponent()应该比使用 encodeURI()的频率更高,这是因为编码查询字符串参数比编码基准 URI 的次数更多。
encodeURI()和 encodeURIComponent()相对的是 decodeURI()和 decodeURIComponent()。decodeURI()只对使用 encodeURI()编码过的字符解码。例如,%20 会被替换为空格,但%23 不会被替换为井号(#),因为井号不是由 encodeURI()替换的。类似地,decodeURIComponent()解码所有被 encodeURIComponent()编码的字符,基本上就是解码所有特殊值。来看下面的例子:
let uri = "http%3A%2F%2Fwww.wrox.com%2Fillegal%20value.js%23start";
// http%3A%2F%2Fwww.wrox.com%2Fillegal value.js%23start
console.log(decodeURI(uri));
// http:// www.wrox.com/illegal value.js#start
console.log(decodeURIComponent(uri));
这里,uri 变量中包含一个使用 encodeURIComponent()编码过的字符串。首先输出的是使用decodeURI()解码的结果,可以看到只用空格替换了%20。然后是使用 decodeURIComponent()解码的结果,其中替换了所有特殊字符,并输出了没有包含任何转义的字符串。(这个字符串不是有效的 URL。)
2.eval()方法
最后一个方法可能是整个 ECMAScript 语言中最强大的了,它就是 eval()。这个方法就是一个完整的 ECMAScript 解释器,它接收一个参数,即一个要执行的 ECMAScript(JavaScript)字符串。来看一个例子:
eval("console.log('hi')");
//上面这行代码的功能与下一行等价:
console.log("hi");
当解释器发现 eval()调用时,会将参数解释为实际的 ECMAScript 语句,然后将其插入到该位置。通过 eval()执行的代码属于该调用所在上下文,被执行的代码与该上下文拥有相同的作用域链。这意味着定义在包含上下文中的变量可以在 eval()调用内部被引用,比如下面这个例子:
let msg = "hello world";
eval("console.log(msg)"); // "hello world"
这里,变量 msg 是在 eval()调用的外部上下文中定义的,而 console.log()显示了文本"hello world"。这是因为第二行代码会被替换成一行真正的函数调用代码。类似地,可以在 eval()内部定义一个函数或变量,然后在外部代码中引用,如下所示:
eval("function sayHi() { console.log('hi'); }");
sayHi(); //hi
这里,函数 sayHi()是在 eval()内部定义的。因为该调用会被替换为真正的函数定义,所以才可能在下一行代码中调用 sayHi()。对于变量也是一样的:
eval("let msg = 'hello world';");
console.log(msg); // Reference Error: msg is not defined
通过 eval()定义的任何变量和函数都不会被提升,这是因为在解析代码的时候,它们是被包含在一个字符串中的。它们只是在 eval()执行的时候才会被创建。
在严格模式下,在 eval()内部创建的变量和函数无法被外部访问。换句话说,最后两个例子会报错。同样,在严格模式下,赋值给 eval 也会导致错误:
"use strict";
eval = "hi"; // 导致错误
3.Global 对象属性
Global 对象有很多属性,其中一些前面已经提到过了。像 undefined、NaN 和 Infinity 等特殊值都是 Global 对象的属性。此外,所有原生引用类型构造函数,比如 Object 和 Function,也都是Global 对象的属性。下表列出了所有这些属性。


4.window 对象
虽然 ECMA-262 没有规定直接访问 Global 对象的方式,但浏览器将 window 对象实现为 Global对象的代理。因此,所有全局作用域中声明的变量和函数都变成了 window 的属性。来看下面的例子:
var color = "red";
function sayColor() {
console.log(window.color);
}
window.sayColor(); // "red"
这里定义了一个名为color的全局变量和一个名为sayColor()的全局函数。在sayColor()内部,通过 window.color 访问了 color 变量,说明全局变量变成了 window 的属性。接着,又通过 window对象直接调用了 window.sayColor()函数,从而输出字符串。
另一种获取 Global 对象的方式是使用如下的代码:
let global = function() {
return this;
}();
这段代码创建一个立即调用的函数表达式,返回了 this 的值。如前所述,当一个函数在没有明确(通过成为某个对象的方法,或者通过 call()/apply())指定 this 值的情况下执行时,this 值等于Global 对象。因此,调用一个简单返回 this 的函数是在任何执行上下文中获取 Global 对象的通用方式。
5.4.2 Math
ECMAScript 提供了 Math 对象作为保存数学公式、信息和计算的地方。Math 对象提供了一些辅助计算的属性和方法。
1.Math 对象属性
Math 对象有一些属性,主要用于保存数学中的一些特殊值。下表列出了这些属性。

2.min()和max()方法
min()和 max()方法用于确定一组数值中的最小值和最大值。这两个方法都接收任意多个参数,如下面的例子所示:
let max = Math.max(3, 54, 32, 16);
console.log(max); // 54
let min = Math.min(3, 54, 32, 16);
console.log(min); // 3
要知道数组中的最大值和最小值,可以像下面这样使用扩展操作符:
let values = [1, 2, 3, 4, 5, 6, 7, 8];
let max = Math.max(...val);
3.舍入方法
接下来是用于把小数值舍入为整数的 4 个方法:Math.ceil()、Math.floor()、Math.round()和 Math.fround()。这几个方法处理舍入的方式如下所述。
- Math.ceil()方法始终向上舍入为最接近的整数。
- Math.floor()方法始终向下舍入为最接近的整数。
- Math.round()方法执行四舍五入。
- Math.fround()方法返回数值最接近的单精度(32 位)浮点值表示。
举个例子:
console.log(Math.ceil(25.9)); // 26
console.log(Math.ceil(25.5)); // 26
console.log(Math.ceil(25.1)); // 26
console.log(Math.round(25.9)); // 26
console.log(Math.round(25.5)); // 26
console.log(Math.round(25.1)); // 25
console.log(Math.fround(0.4)); // 0.4000000059604645
console.log(Math.fround(0.5)); // 0.5
console.log(Math.fround(25.9)); // 25.899999618530273
console.log(Math.floor(25.9)); // 25
console.log(Math.floor(25.5)); // 25
console.log(Math.floor(25.1)); // 25
对于 25 和 26(不包含)之间的所有值,Math.ceil()都会返回 26,因为它始终向上舍入。Math.round()只在数值大于等于 25.5 时返回 26,否则返回 25。最后,Math.floor()对所有 25 和26(不包含)之间的值都返回 25。
4.**random()**方法
Math.random()方法返回一个 0~1 范围内的随机数,其中包含 0 但不包含 1。对于希望显示随机名言或随机新闻的网页,这个方法是非常方便的。可以基于如下公式使用 Math.random()从一组整数中随机选择一个数:
number = Math.floor(Math.random() * total_number_of_choices + first_possible_value)
//举个例子
let num = Math.floor(Math.random() * 10 + 1);//1-10
let num = Math.floor(Math.random() * 9 + 2);//2-10
//函数实现
function selectFrom(lowerValue, upperValue) {
let choices = upperValue - lowerValue + 1;
return Math.floor(Math.random() * choices + lowerValue);
}
let num = selectFrom(2,10);
console.log(num); // 2~10 范围内的值,其中包含 2 和 10
//从一个数组中随机选择一个元素就很容易
let colors = ["red", "green", "blue", "yellow", "black", "purple", "brown"];
let color = colors[selectFrom(0, colors.length-1)];
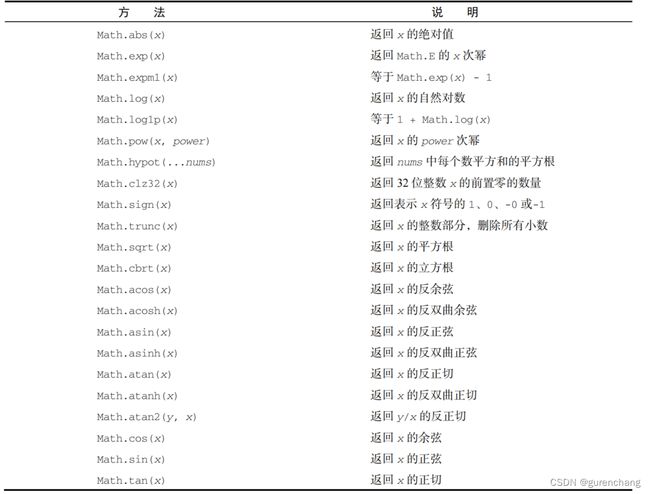
5.其他方法
Math 对象还有很多涉及各种简单或高阶数运算的方法。下表还是总结了 Math 对象的其他方法。
5.5 小结
JavaScript 中的对象称为引用值,几种内置的引用类型可用于创建特定类型的对象。
-
引用值与传统面向对象编程语言中的类相似,但实现不同。
-
Date 类型提供关于日期和时间的信息,包括当前日期、时间及相关计算。
-
RegExp 类型是 ECMAScript 支持正则表达式的接口,提供了大多数基础的和部分高级的正则表达式功能。
JavaScript 比较独特的一点是,函数实际上是 Function 类型的实例,也就是说函数也是对象。因为函数也是对象,所以函数也有方法,可以用于增强其能力。
由于原始值包装类型的存在,JavaScript 中的原始值可以被当成对象来使用。有 3 种原始值包装类型:Boolean、Number 和 String。它们都具备如下特点。
-
每种包装类型都映射到同名的原始类型。
-
以读模式访问原始值时,后台会实例化一个原始值包装类型的对象,借助这个对象可以操作相应的数据。
-
涉及原始值的语句执行完毕后,包装对象就会被销毁。
当代码开始执行时,全局上下文中会存在两个内置对象:Global 和 Math。其中,Global 对象在大多数 ECMAScript 实现中无法直接访问。不过,浏览器将其实现为 window 对象。所有全局变量和函数都是 Global 对象的属性。Math 对象包含辅助完成复杂计算的属性和方法。
第6章 集合引用类型
6.1 Object
大多数引用值的示例使用的是 Object 类型。Object 是 ECMAScript 中最常用的类型之一。很适合存储和在应用程序间交换数据。
显式地创建 Object 的实例有两种方式。第一种是使用 new 操作符和 Object 构造函数,如下所示:
let person = new Object();
person.name = "Nicholas";
person.age = 29;
另一种方式是使用对象字面量(object literal)表示法,比如:
let person = {
name: "Nicholas",
age: 29
};
在这个例子中,左大括号({)表示对象字面量开始,因为它出现在一个表达式上下文(expression context)中。在 ECMAScript 中,表达式上下文指的是期待返回值的上下文。赋值操作符表示后面要期待一个值,因此左大括号表示一个表达式的开始。同样是左大括号,如果出现在语句上下文(statement context)中,比如 if 语句的条件后面,则表示一个语句块的开始。
在对象字面量表示法中,属性名可以是字符串或数值,注意,数值属性会自动转换为字符串,比如:
let person = {
"name": "Nicholas",
"age": 29,
5: true
};
也可以用对象字面量表示法来定义一个只有默认属性和方法的对象,只要使用一对大括号,中间留空就行了:
let person = {}; // 与 new Object()相同
person.name = "Nicholas";
person.age = 29;
虽然使用哪种方式创建 Object 实例都可以,但实际上开发者更倾向于使用对象字面量表示法。这是因为对象字面量代码更少,看起来也更有封装所有相关数据的感觉。事实上,对象字面量已经成为给函数传递大量可选参数的主要方式,比如:
function displayInfo(args) {
let output = "";
if (typeof args.name == "string"){
output += "Name: " + args.name + "\n";
}
if (typeof args.age == "number") {
output += "Age: " + args.age + "\n";
}
alert(output);
}
displayInfo({
name: "Nicholas",
age: 29
});
displayInfo({
name: "Greg"
});
函数 displayInfo()接收一个名为 args 的参数。这个参数可能有属性 name 或 age,也可能两个属性都有或者都没有。函数内部会使用 typeof 操作符测试每个属性是否存在,然后根据属性有无构造并显示一条消息。然后,这个函数被调用了两次,每次都通过一个对象字面量传入了不同的数据。两种情况下,函数都正常运行。
注意:这种模式非常适合函数有大量可选参数的情况。一般来说,命名参数更直观,但在可选参数过多的时候就显得笨拙了。最好的方式是对必选参数使用命名参数,再通过一个对象字面量来封装多个可选参数。
虽然属性一般是通过点语法来存取的,这也是面向对象语言的惯例,但也可以使用中括号来存取属性。在使用中括号时,要在括号内使用属性名的字符串形式,比如:
console.log(person["name"]); // "Nicholas"
console.log(person.name); // "Nicholas"
从功能上讲,这两种存取属性的方式没有区别。使用中括号的主要优势就是可以通过变量访问属性,就像下面这个例子中一样:
let propertyName = "name";
console.log(person[propertyName]); // "Nicholas"
另外,如果属性名中包含可能会导致语法错误的字符,或者包含关键字/保留字时,也可以使用中括号语法。比如:
person["first name"] = "Nicholas";
因为"first name"中包含一个空格,所以不能使用点语法来访问。不过,属性名中是可以包含非字母数字字符的,这时候只要用中括号语法存取它们就行了。
通常,点语法是首选的属性存取方式,除非访问属性时必须使用变量。
6.2 Array
除了 Object,Array 应该就是 ECMAScript 中最常用的类型了。ECMAScript 数组是一组有序的数据,但跟其他语言不同的是,数组中每个槽位可以存储任意类型的数据。这意味着可以创建一个数组,它的第一个元素是字符串,第二个元素是数值,第三个是对象。ECMAScript 数组也是动态大小的,会随着数据添加而自动增长。]
6.2.1 创建数组
有几种基本的方式可以创建数组。一种是使用 Array 构造函数,比如:
let colors = new Array();
如果知道数组中元素的数量,那么可以给构造函数传入一个数值,然后 length 属性就会被自动创建并设置为这个值。比如,下面的代码会创建一个初始 length 为 20 的数组:
let colors = new Array(20);
也可以给 Array 构造函数传入要保存的元素。比如,下面的代码会创建一个包含 3 个字符串值的数组:
let colors = new Array("red", "blue", "green");
创建数组时可以给构造函数传一个值。因为如果这个值是数值,则会创建一个长度为指定数值的数组;而如果这个值是其他类型的,则会创建一个只包含该特定值的数组。下面看一个例子:
let colors = new Array(3); // 创建一个包含 3 个元素的数组
let names = new Array("Greg"); // 创建一个只包含一个元素,即字符串"Greg"的数组
在使用 Array 构造函数时,也可以省略 new 操作符。结果是一样的,比如:
let colors = Array(3); // 创建一个包含 3 个元素的数组
let names = Array("Greg"); // 创建一个只包含一个元素,即字符串"Greg"的数组
另一种创建数组的方式是使用数组字面量(array literal)表示法。数组字面量是在中括号中包含以逗号分隔的元素列表,如下面的例子所示:
let colors = ["red", "blue", "green"]; // 创建一个包含 3 个元素的数组
let names = []; // 创建一个空数组
let values = [1,2,]; // 创建一个包含 2 个元素的数组
注意:与对象一样,在使用数组字面量表示法创建数组不会调用 Array 构造函数
Array 构造函数还有两个 ES6 新增的用于创建数组的静态方法:from()和 of()。from()用于将类数组结构转换为数组实例,而 of()用于将一组参数转换为数组实例。
Array.from()的第一个参数是一个类数组对象,即任何可迭代的结构,或者有一个 length 属性和可索引元素的结构。这种方式可用于很多场合:
// 字符串会被拆分为单字符数组
console.log(Array.from("Matt")); // ["M", "a", "t", "t"]
// 可以使用 from()将集合和映射转换为一个新数组
const m = new Map().set(1, 2)
.set(3, 4);
const s = new Set().add(1)
.add(2)
.add(3)
.add(4);
console.log(Array.from(m)); // [[1, 2], [3, 4]]
console.log(Array.from(s)); // [1, 2, 3, 4]
// Array.from()对现有数组执行浅复制
const a1 = [1, 2, 3, 4];
const a2 = Array.from(a1);
console.log(a1); // [1, 2, 3, 4]
alert(a1 === a2); // false
// 可以使用任何可迭代对象
const iter = {
*[Symbol.iterator]() {
yield 1;
yield 2;
yield 3;
yield 4;
}
};
console.log(Array.from(iter)); // [1, 2, 3, 4]
// arguments 对象可以被轻松地转换为数组
function getArgsArray() {
return Array.from(arguments);
}
console.log(getArgsArray(1, 2, 3, 4)); // [1, 2, 3, 4]
// from()也能转换带有必要属性的自定义对象
const arrayLikeObject = {
0: 1,
1: 2,
2: 3,
3: 4,
length: 4
};
console.log(Array.from(arrayLikeObject)); // [1, 2, 3, 4]
Array.from()还接收第二个可选的映射函数参数。这个函数可以直接增强新数组的值,而无须像调用 Array.from().map()那样先创建一个中间数组。还可以接收第三个可选参数,用于指定映射函数中 this 的值。但这个重写的 this 值在箭头函数中不适用。
const a1 = [1, 2, 3, 4];
const a2 = Array.from(a1, x => x**2);
const a3 = Array.from(a1, function(x) {return x**this.exponent}, {exponent: 2});
console.log(a2); // [1, 4, 9, 16]
console.log(a3); // [1, 4, 9, 16]
Array.of()可以把一组参数转换为数组。这个方法用于替代在 ES6之前常用的 Array.prototype. slice.call(arguments),一种异常笨拙的将 arguments 对象转换为数组的写法:
console.log(Array.of(1, 2, 3, 4)); // [1, 2, 3, 4]
console.log(Array.of(undefined)); // [undefined]
6.2.2 数组空位
使用数组字面量初始化数组时,可以使用一串逗号来创建空位(hole)。ECMAScript 会将逗号之间相应索引位置的值当成空位,ES6 规范重新定义了该如何处理这些空位。可以像下面这样创建一个空位数组:
const options = [,,,,,]; // 创建包含 5 个元素的数组
console.log(options.length); // 5
console.log(options); // [,,,,,]
ES6 新增的方法和迭代器与早期 ECMAScript 版本中存在的方法行为不同。ES6 新增方法普遍将这些空位当成存在的元素,只不过值为 undefined:
const options = [1,,,,5];
for (const option of options) {
console.log(option === undefined);
}
// false
// true
// true
// true
// false
const a = Array.from([,,,]); // 使用 ES6 的 Array.from()创建的包含 3 个空位的数组
for (const val of a) {
alert(val === undefined);
}
// true
// true
// true
alert(Array.of(...[,,,])); // [undefined, undefined, undefined]
for (const [index, value] of options.entries()) {
alert(value);
}
// 1
// undefined
// undefined
// undefined
// 5
ES6 之前的方法则会忽略这个空位,但具体的行为也会因方法而异:
const options = [1,,,,5];
// map()会跳过空位置
console.log(options.map(() => 6)); // [6, undefined, undefined, undefined, 6]
// join()视空位置为空字符串
console.log(options.join('-')); // "1----5"
注意 由于行为不一致和存在性能隐患,因此实践中要避免使用数组空位。如果确实需要空位,则可以显式地用 undefined 值代替。
6.2.3 数组索引
要取得或设置数组的值,需要使用中括号并提供相应值的数字索引,如下所示:
let colors = ["red", "blue", "green"]; // 定义一个字符串数组
alert(colors[0]); // 显示第一项
colors[2] = "black"; // 修改第三项
colors[3] = "brown"; // 添加第四项
数组中元素的数量保存在 length 属性中,这个属性始终返回 0 或大于 0 的值,如下例所示:
let colors = ["red", "blue", "green"]; // 创建一个包含 3 个字符串的数组
let names = []; // 创建一个空数组
alert(colors.length); // 3
alert(names.length); // 0
数组 length 属性的独特之处在于,它不是只读的。通过修改 length 属性,可以从数组末尾删除或添加元素。来看下面的例子:
let colors = ["red", "blue", "green"]; // 创建一个包含 3 个字符串的数组
colors.length = 2;
alert(colors[2]); // undefined
如果将 length 设置为大于数组元素数的值,则新添加的元素都将以undefined 填充,如下例所示:
let colors = ["red", "blue", "green"]; // 创建一个包含 3 个字符串的数组
colors.length = 4;
alert(colors[3]); // undefined
使用 length 属性可以方便地向数组末尾添加元素,如下例所示:
let colors = ["red", "blue", "green"]; // 创建一个包含 3 个字符串的数组
colors[colors.length] = "black"; // 添加一种颜色(位置 3)
colors[colors.length] = "brown"; // 再添加一种颜色(位置 4)
数组中最后一个元素的索引始终是 length - 1,因此下一个新增槽位的索引就是 length。每次在数组最后一个元素后面新增一项,数组的 length 属性都会自动更新,以反映变化。这意味着第二行的 colors[colors.length]会在位置 3 添加一个新元素,下一行则会在位置 4 添加一个新元素。新的长度会在新增元素被添加到当前数组外部的位置上时自动更新。换句话说,就是 length 属性会更新为位置加上 1,如下例所示:
let colors = ["red", "blue", "green"]; // 创建一个包含 3 个字符串的数组
colors[99] = "black"; // 添加一种颜色(位置 99)
alert(colors.length); // 100
colors 数组有一个值被插入到位置 99,结果新 length 就变成了 100(99 + 1)。这中间的所有元素,即位置 3~98,实际上并不存在,因此在访问时会返回 undefined。
6.2.4 检测数组
一个经典的 ECMAScript 问题是判断一个对象是不是数组。在只有一个网页(因而只有一个全局作用域)的情况下,使用 instanceof 操作符就足矣:
if (value instanceof Array){
// 操作数组
}
ECMAScript 提供了 Array.isArray()方法。这个方法的目的就是确定一个值是否为数组,而不用管它是在哪个全局执行上下文中创建的。来看下面的例子:
if (Array.isArray(value)){
// 操作数组
}
6.2.5 迭代器方法
ES6 中,Array 的原型上暴露了 3 个用于检索数组内容的方法:keys()、values()和entries()。keys()返回数组索引的迭代器,values()返回数组元素的迭代器,而 entries()返回索引/值对的迭代器:
const a = ["foo", "bar", "baz", "qux"];
// 因为这些方法都返回迭代器,所以可以将它们的内容
// 通过 Array.from()直接转换为数组实例
const aKeys = Array.from(a.keys());
const aValues = Array.from(a.values());
const aEntries = Array.from(a.entries());
console.log(aKeys); // [0, 1, 2, 3]
console.log(aValues); // ["foo", "bar", "baz", "qux"]
console.log(aEntries); // [[0, "foo"], [1, "bar"], [2, "baz"], [3, "qux"]]
使用 ES6 的解构可以非常容易地在循环中拆分键/值对:
const a = ["foo", "bar", "baz", "qux"];
for (const [idx, element] of a.entries()) {
alert(idx);
alert(element);
}
// 0
// foo
// 1
// bar
// 2
// baz
// 3
// qux
6.2.6 复制和填充方法
ES6 新增了两个方法:批量复制方法 copyWithin(),以及填充数组方法 fill()。这两个方法的函数签名类似,都需要指定既有数组实例上的一个范围,包含开始索引,不包含结束索引。使用这个方法不会改变数组的大小。
使用 fill()方法可以向一个已有的数组中插入全部或部分相同的值。开始索引用于指定开始填充的位置,它是可选的。如果不提供结束索引,则一直填充到数组末尾。负值索引从数组末尾开始计算。也可以将负索引想象成数组长度加上它得到的一个正索引:前闭后开
const zeroes = [0, 0, 0, 0, 0];
// 用 5 填充整个数组
zeroes.fill(5);
console.log(zeroes); // [5, 5, 5, 5, 5]
zeroes.fill(0); // 重置
// 用 6 填充索引大于等于 3 的元素
zeroes.fill(6, 3);
console.log(zeroes); // [0, 0, 0, 6, 6]
zeroes.fill(0); // 重置
// 用 7 填充索引大于等于 1 且小于 3 的元素
zeroes.fill(7, 1, 3);
console.log(zeroes); // [0, 7, 7, 0, 0];
zeroes.fill(0); // 重置
// 用 8 填充索引大于等于 1 且小于 4 的元素
// (-4 + zeroes.length = 1)
// (-1 + zeroes.length = 4)
zeroes.fill(8, -4, -1);
console.log(zeroes); // [0, 8, 8, 8, 0];
fill()静默忽略超出数组边界、零长度及方向相反的索引范围:
const zeroes = [0, 0, 0, 0, 0];
// 索引过低,忽略
zeroes.fill(1, -10, -6);
console.log(zeroes); // [0, 0, 0, 0, 0]
// 索引过高,忽略
zeroes.fill(1, 10, 15);
console.log(zeroes); // [0, 0, 0, 0, 0]
// 索引反向,忽略
zeroes.fill(2, 4, 2);
console.log(zeroes); // [0, 0, 0, 0, 0]
// 索引部分可用,填充可用部分
zeroes.fill(4, 3, 10)
console.log(zeroes); // [0, 0, 0, 4, 4]
copyWithin()会按照指定范围浅复制数组中的部分内容,然后将它们插入到指定索引开始的位置。开始索引和结束索引则与 fill()使用同样的计算方法:第一个参数表示插入的位置,第二个参数表示开始复制的位置,第三个参数表示结束复制的位置,前闭后开
let ints,
reset = () => ints = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
reset();
// 从 ints 中复制索引 0 开始的内容,插入到索引 5 开始的位置
// 在源索引或目标索引到达数组边界时停止
ints.copyWithin(5);
console.log(ints); // [0, 1, 2, 3, 4, 0, 1, 2, 3, 4]
reset();
// 从 ints 中复制索引 5 开始的内容,插入到索引 0 开始的位置
ints.copyWithin(0, 5);
console.log(ints); // [5, 6, 7, 8, 9, 5, 6, 7, 8, 9]
reset();
// 从 ints 中复制索引 0 开始到索引 3 结束的内容
// 插入到索引 4 开始的位置
ints.copyWithin(4, 0, 3);
alert(ints); // [0, 1, 2, 3, 0, 1, 2, 7, 8, 9]
reset();
// JavaScript 引擎在插值前会完整复制范围内的值
// 因此复制期间不存在重写的风险
ints.copyWithin(2, 0, 6);
alert(ints); // [0, 1, 0, 1, 2, 3, 4, 5, 8, 9]
reset();
// 支持负索引值,与 fill()相对于数组末尾计算正向索引的过程是一样的
ints.copyWithin(-4, -7, -3);
alert(ints); // [0, 1, 2, 3, 4, 5, 3, 4, 5, 6]
copyWithin()静默忽略超出数组边界、零长度及方向相反的索引范围:
let ints,
reset = () => ints = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
reset();
// 索引过低,忽略
ints.copyWithin(1, -15, -12);
alert(ints); // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
reset()
// 索引过高,忽略
ints.copyWithin(1, 12, 15);
alert(ints); // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
reset();
// 索引反向,忽略
ints.copyWithin(2, 4, 2);
alert(ints); // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
reset();
// 索引部分可用,复制、填充可用部分
ints.copyWithin(4, 7, 10)
alert(ints); // [0, 1, 2, 3, 7, 8, 9, 7, 8, 9];
6.2.7 转换方法
所有对象都有 toLocaleString()、toString()和 valueOf()方法。其中,valueOf()返回的还是数组本身。而 toString()返回由数组中每个值的等效字符串拼接而成的一个逗号分隔的字符串。也就是说,对数组的每个值都会调用其 toString()方法,以得到最终的字符串。来看下面的例子:
let colors = ["red", "blue", "green"]; // 创建一个包含 3 个字符串的数组
alert(colors.toString()); // red,blue,green
alert(colors.valueOf()); // red,blue,green
alert(colors); // red,blue,green
首先是被显式调用的 toString()和 valueOf()方法,它们分别返回了数组的字符串表示,即将所有字符串组合起来,以逗号分隔。最后一行代码直接用 alert()显示数组,因为 alert()期待字符串,所以会在后台调用数组的 toString()方法,从而得到跟前面一样的结果。
toLocaleString()方法也可能返回跟 toString()和 valueOf()相同的结果,但也不一定。在调用数组的 toLocaleString()方法时,会得到一个逗号分隔的数组值的字符串。它与另外两个方法唯一的区别是,为了得到最终的字符串,会调用数组每个值的 toLocaleString()方法,而不是toString()方法。看下面的例子:
let person1 = {
toLocaleString() {
return "Nikolaos";
},
toString() {
return "Nicholas";
}
};
let person2 = {
toLocaleString() {
return "Grigorios";
},
toString() {
return "Greg";
}
};
let people = [person1, person2];
alert(people); // Nicholas,Greg
alert(people.toString()); // Nicholas,Greg
alert(people.toLocaleString()); // Nikolaos,Grigorios
这里定义了两个对象 person1 和 person2,它们都定义了 toString()和 toLocaleString()方法,而且返回不同的值。然后又创建了一个包含这两个对象的数组 people。在将数组传给 alert()时,输出的是"Nicholas,Greg",这是因为会在数组每一项上调用 toString()方法,而在调用数组的 toLocaleString()方法时,结果变成了"Nikolaos, Grigorios",这是因为调用了数组每一项的 toLocaleString()方法。
继承的方法 toLocaleString()以及 toString()都返回数组值的逗号分隔的字符串。如果想使用不同的分隔符,则可以使用 join()方法。join()方法接收一个参数,即字符串分隔符,返回包含所有项的字符串。来看下面的例子:
let colors = ["red", "green", "blue"];
alert(colors.join(",")); // red,green,blue
alert(colors.join("||")); // red||green||blue
这里在 colors 数组上调用了 join()方法,得到了与调用 toString()方法相同的结果。传入逗号,结果就是逗号分隔的字符串。最后一行给 join() 传入了双竖线,得到了字符串"red||green||blue"。如果不给 join()传入任何参数,或者传入 undefined,则仍然使用逗号作为分隔符.
注意:如果数组中某一项是 null 或 undefined,则在 join()、toLocaleString()、toString()和 valueOf()返回的结果中会以空字符串表示。
6.2.8 栈方法
数组对象可以像栈一样,也就是一种限制插入和删除项的数据结构。栈是一种后进先出(LIFO,Last-In-First-Out)的结构,也就是最近添加的项先被删除。数据项的插入(称为推入,push)和删除(称为弹出,pop)只在栈顶发生。ECMAScript 数组提供了 push()和 pop()方法,以实现类似栈的行为。
push()方法接收任意数量的参数,并将它们添加到数组末尾,返回数组的最新长度。pop()方法则用于删除数组的最后一项,同时减少数组的 length 值,返回被删除的项。来看下面的例子:
let colors = new Array(); // 创建一个数组
let count = colors.push("red", "green"); // 推入两项
alert(count); // 2
count = colors.push("black"); // 再推入一项
alert(count); // 3
let item = colors.pop(); // 取得最后一项
alert(item); // black
alert(colors.length); // 2
栈方法可以与数组的其他任何方法一起使用,如下例所示:
let colors = ["red", "blue"];
colors.push("brown"); // 再添加一项
colors[3] = "black"; // 添加一项
alert(colors.length); // 4
let item = colors.pop(); // 取得最后一项
alert(item); // black
6.2.9 队列方法
队列以先进先出(FIFO,First-In-First-Out)形式限制访问。队列在列表末尾添加数据,但从列表开头获取数据。因为有了在数据末尾添加数据的 push()方法,所以要模拟队列就差一个从数组开头取得数据的方法了。这个数组方法叫 shift(),它会删除数组的第一项并返回它,然后数组长度减 1。使用 shift()和 push(),可以把数组当成队列来使用:
let colors = new Array(); // 创建一个数组
let count = colors.push("red", "green"); // 推入两项
alert(count); // 2
count = colors.push("black"); // 再推入一项
alert(count); // 3
let item = colors.shift(); // 取得第一项
alert(item); // red
alert(colors.length); // 2
ECMAScript 也为数组提供了 unshift()方法。unshift()就是执行跟 shift()相反的操作:在数组开头添加任意多个值,然后返回新的数组长度。通过使用 unshift()和 pop(),可以在相反方向上模拟队列,即在数组开头添加新数据,在数组末尾取得数据,如下例所示:
let colors = new Array(); // 创建一个数组
let count = colors.unshift("red", "green"); // 从数组开头推入两项
alert(count); // 2
count = colors.unshift("black"); // 再推入一项
alert(count); // 3
let item = colors.pop(); // 取得最后一项
alert(item); // green
alert(colors.length); // 2
6.2.10 排序方法
数组有两个方法可以用来对元素重新排序:reverse()和 sort()。顾名思义,reverse()方法就是将数组元素反向排列。比如:
let values = [1, 2, 3, 4, 5];
values.reverse();
alert(values); // 5,4,3,2,1
默认情况下,sort()会按照升序重新排列数组元素,即最小的值在前面,最大的值在后面。为此,sort()会在每一项上调用 String()转型函数,然后比较字符串来决定顺序。即使数组的元素都是数值,也会先把数组转换为字符串再比较、排序。比如:
let values = [0, 1, 5, 10, 15];
values.sort();
alert(values); // 0,1,10,15,5
一开始数组中数值的顺序是正确的,但调用 sort()会按照这些数值的字符串形式重新排序。因此,即使 5 小于 10,但字符串"10"在字符串"5"的前头,所以 10 还是会排到 5 前面。很明显,这在多数情况下都不是最合适的。为此,sort()方法可以接收一个比较函数,用于判断哪个值应该排在前面。
比较函数接收两个参数,如果第一个参数应该排在第二个参数前面,就返回负值;如果两个参数相等,就返回 0;如果第一个参数应该排在第二个参数后面,就返回正值。下面是使用简单比较函数的一个例子:
function compare(value1, value2) {
if (value1 < value2) {
return -1;
} else if (value1 > value2) {
return 1;
} else {
return 0;
}
}
这个比较函数可以适用于大多数数据类型,可以把它当作参数传给 sort()方法,如下所示
let values = [0, 1, 5, 10, 15];
values.sort(compare);
alert(values); // 0,1,5,10,15
在给 sort()方法传入比较函数后,数组中的数值在排序后保持了正确的顺序。当然,比较函数也可以产生降序效果,只要把返回值交换一下即可:
function compare(value1, value2) {
if (value1 < value2) {
return 1;
} else if (value1 > value2) {
return -1;
} else {
return 0;
}
}
let values = [0, 1, 5, 10, 15];
values.sort(compare);
alert(values); // 15,10,5,1,0
此外,这个比较函数还可简写为一个箭头函数:
let values = [0, 1, 5, 10, 15];
values.sort((a, b) => a < b ? 1 : a > b ? -1 : 0);
alert(values); // 15,10,5,1,0
在这个修改版函数中,如果第一个值应该排在第二个值后面则返回 1,如果第一个值应该排在第二个值前面则返回1。交换这两个返回值之后,较大的值就会排在前头,数组就会按照降序排序。当然,如果只是想反转数组的顺序,reverse()更简单也更快。‘’
注意:reverse()和 sort()都返回调用它们的数组的引用。
如果数组的元素是数值,或者是其 valueOf()方法返回数值的对象(如 Date 对象),这个比较函数还可以写得更简单,因为这时可以直接用第二个值减去第一个值:
function compare(value1, value2){
return value2 - value1;
}
比较函数就是要返回小于 0、0 和大于 0 的数值,因此减法操作完全可以满足要求。
6.2.11 操作方法
对于数组中的元素,我们有很多操作方法。比如,concat()方法可以在现有数组全部元素基础上创建一个新数组。它首先会创建一个当前数组的副本,然后再把它的参数添加到副本末尾,最后返回这个新构建的数组。如果传入一个或多个数组,则 concat()会把这些数组的每一项都添加到结果数组。如果参数不是数组,则直接把它们添加到结果数组末尾。来看下面的例子:
let colors = ["red", "green", "blue"];
let colors2 = colors.concat("yellow", ["black", "brown"]);
console.log(colors); // ["red", "green","blue"] 原数组保持不变
console.log(colors2); // ["red", "green", "blue", "yellow", "black", "brown"]
打平数组参数的行为可以重写,方法是在参数数组上指定一个特殊的符号:Symbol.isConcatSpreadable。这个符号能够阻止 concat()打平参数数组。相反,把这个值设置为 true 可以强制打平类数组对象:
let colors = ["red", "green", "blue"];
let newColors = ["black", "brown"];
let moreNewColors = {
[Symbol.isConcatSpreadable]: true,
length: 2,
0: "pink",
1: "cyan"
};
newColors[Symbol.isConcatSpreadable] = false;
// 强制不打平数组
let colors2 = colors.concat("yellow", newColors);
// 强制打平类数组对象
let colors3 = colors.concat(moreNewColors);
console.log(colors); // ["red", "green", "blue"]
console.log(colors2); // ["red", "green", "blue", "yellow", **["black", "brown"]**]
console.log(colors3); // ["red", "green", "blue", **"pink", "cyan"**]
方法 slice()用于创建一个包含原有数组中一个或多个元素的新数组。slice()方法可以接收一个或两个参数:返回元素的开始索引和结束索引。如果只有一个参数,则 slice()会返回该索引到数组末尾的所有元素。如果有两个参数,则 slice()返回从开始索引到结束索引对应的所有元素,其中不包含结束索引对应的元素(前闭后开)。记住,这个操作不影响原始数组。来看下面的例子:
let colors = ["red", "green", "blue", "yellow", "purple"];
let colors2 = colors.slice(1);
let colors3 = colors.slice(1, 4);
alert(colors2); // green,blue,yellow,purple
alert(colors3); // green,blue,yellow
注意:如果 slice()的参数有负值,那么就以数值长度加上这个负值的结果确定位置。比如,在包含 5 个元素的数组上调用 slice(-2,-1),就相当于调用 slice(3,4)。如果结束位置小于开始位置,则返回空数组。
或许最强大的数组方法就属 splice()了,使用它的方式可以有很多种。splice()的主要目的是在数组中间插入元素,但有 3 种不同的方式使用这个方法:
-
删除。需要给 splice()传 2 个参数:要删除的第一个元素的位置和要删除的元素数量。可以从数组中删除任意多个元素,比如 splice(0, 2)会删除前两个元素。
-
插入。需要给 splice()传 3 个参数:开始位置、0(要删除的元素数量)和要插入的元素,可以在数组中指定的位置插入元素。第三个参数之后还可以传第四个、第五个参数,乃至任意多个要插入的元素。比如,splice(2, 0, “red”, “green”)会从数组位置 2 开始插入字符串"red"和"green"。
-
替换。splice()在删除元素的同时可以在指定位置插入新元素,同样要传入 3 个参数:开始位置、要删除元素的数量和要插入的任意多个元素。要插入的元素数量不一定跟删除的元素数量一致。比如,splice(2, 1, “red”, “green”)会在位置 2 删除一个元素,然后从该位置开始向数组中插入"red"和"green"。
splice()方法始终返回从数组中被删除的元素(如果没有删除元素,则返回空数组)。以下示例展示了上述 3 种使用方式。
let colors = ["red", "green", "blue"];
let removed = colors.splice(0,1); // 删除第一项
alert(colors); // green,blue
alert(removed); // red,只有一个元素的数组
removed = colors.splice(1, 0, "yellow", "orange"); // 在位置 1 插入两个元素
alert(colors); // green,yellow,orange,blue
alert(removed); // 空数组
removed = colors.splice(1, 1, "red", "purple"); // 插入两个值,删除一个元素
alert(colors); // green,red,purple,orange,blue
alert(removed); // yellow,只有一个元素的数组
6.2.12 搜索和位置方法
ECMAScript 提供两类搜索数组的方法:按严格相等搜索和按断言函数搜索
1.严格相等
ECMAScript 提供了 3 个严格相等的搜索方法:indexOf()、lastIndexOf()和 includes()。其中,前两个方法在所有版本中都可用,而第三个方法是 ECMAScript 7 新增的。这些方法都接收两个参数:要查找的元素和一个可选的起始搜索位置。indexOf()和 includes()方法从数组前头(第一项)开始向后搜索,而 lastIndexOf()从数组末尾(最后一项)开始向前搜索。
indexOf()和 lastIndexOf()都返回要查找的元素在数组中的位置,如果没找到则返回-1。includes()返回布尔值,表示是否至少找到一个与指定元素匹配的项。在比较第一个参数跟数组每一项时,会使用全等(===)比较,也就是说两项必须严格相等。下面来看一些例子:
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
alert(numbers.indexOf(4)); // 3
alert(numbers.lastIndexOf(4)); // 5
alert(numbers.includes(4)); // true
alert(numbers.indexOf(4, 4)); // 5
alert(numbers.lastIndexOf(4, 4)); // 3
alert(numbers.includes(4, 7)); // false
let person = { name: "Nicholas" };
let people = [{ name: "Nicholas" }];
let morePeople = [person];
alert(people.indexOf(person)); // -1
alert(morePeople.indexOf(person)); // 0
alert(people.includes(person)); // false
alert(morePeople.includes(person)); // true
2.断言函数
ECMAScript 也允许按照定义的断言函数搜索数组,每个索引都会调用这个函数。断言函数的返回值决定了相应索引的元素是否被认为匹配。
断言函数接收 3 个参数:元素、索引和数组本身。其中元素是数组中当前搜索的元素,索引是当前元素的索引,而数组就是正在搜索的数组。断言函数返回真值,表示是否匹配。
find()和 findIndex()方法使用了断言函数。这两个方法都从数组的最小索引开始。find()返回第一个匹配的元素,findIndex()返回第一个匹配元素的索引。这两个方法也都接收第二个可选的参数,用于指定断言函数内部 this 的值。
const people = [
{
name: "Matt",
age: 27
},
{
name: "Nicholas",
age: 29
}
];
alert(people.find((element, index, array) => element.age < 28));
// {name: "Matt", age: 27}
alert(people.findIndex((element, index, array) => element.age < 28));
// 0
找到匹配项后,这两个方法都不再继续搜索。
const evens = [2, 4, 6];
// 找到匹配后,永远不会检查数组的最后一个元素
evens.find((element, index, array) => {
console.log(element);
console.log(index);
console.log(array);
return element === 4;
});
// 2
// 0
// [2, 4, 6]
// 4
// 1
// [2, 4, 6]
6.2.13 迭代方法
ECMAScript 为数组定义了 5 个迭代方法。每个方法接收两个参数:以每一项为参数运行的函数,以及可选的作为函数运行上下文的作用域对象(影响函数中 this 的值)。传给每个方法的函数接收 3个参数:数组元素、元素索引和数组本身。因具体方法而异,这个函数的执行结果可能会也可能不会影响方法的返回值。数组的 5 个迭代方法如下。
-
every():对数组每一项都运行传入的函数,如果对每一项函数都返回 true,则这个方法返回 true。
-
filter():对数组每一项都运行传入的函数,函数返回 true 的项会组成数组之后返回。
-
forEach():对数组每一项都运行传入的函数,没有返回值。
-
map():对数组每一项都运行传入的函数,返回由每次函数调用的结果构成的数组。
-
some():对数组每一项都运行传入的函数,如果有一项函数返回 true,则这个方法返回 true。
这些方法都不改变调用它们的数组。
在这些方法中,every()和 some()是最相似的,都是从数组中搜索符合某个条件的元素。对 every()来说,传入的函数必须对每一项都返回 true,它才会返回 true;否则,它就返回 false。而对 some()来说,只要有一项让传入的函数返回 true,它就会返回 true。下面是一个例子:
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
let everyResult = numbers.every((item, index, array) => item > 2);
alert(everyResult); // false
let someResult = numbers.some((item, index, array) => item > 2);
alert(someResult); // true
every()返回 false 是因为并不是每一项都能达到要求。而 some()返回 true 是因为至少有一项满足条件
filter()方法基于给定的函数来决定某一项是否应该包含在它返回的数组中。适合从数组中筛选满足给定条件的元素,比如,要返回一个所有数值都大于 2 的数组,可以使用如下代码:
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
let filterResult = numbers.filter((item, index, array) => item > 2);
alert(filterResult); // 3,4,5,4,3
map()方法也会返回一个数组。这个数组的每一项都是对原始数组中同样位置的元素运行传入函数而返回的结果。适合创建一个与原始数组元素一一对应的新数组,例如,可以将一个数组中的每一项都乘以 2,并返回包含所有结果的数组,如下所示:
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
let mapResult = numbers.map((item, index, array) => item * 2);
alert(mapResult); // 2,4,6,8,10,8,6,4,2
forEach()方法。只会对每一项运行传入的函数,没有返回值。本质上,forEach()方法相当于使用 for 循环遍历数组。比如:
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
numbers.forEach((item, index, array) => {
// 执行某些操作
});
6.2.14 归并方法
ECMAScript 为数组提供了两个归并方法:reduce()和 reduceRight()。这两个方法都会迭代数组的所有项,并在此基础上构建一个最终返回值。reduce()方法从数组第一项开始遍历到最后一项。而 reduceRight()从最后一项开始遍历至第一项。
这两个方法都接收两个参数:对每一项都会运行的归并函数,以及可选的以之为归并起点的初始值。传给 reduce()和 reduceRight()的函数接收 4 个参数:上一个归并值、当前项、当前项的索引和数组本身。这个函数返回的任何值都会作为下一次调用同一个函数的第一个参数。如果没有给这两个方法传入可选的第二个参数(作为归并起点值),则第一次迭代将从数组的第二项开始,因此传给归并函数的第一个参数是数组的第一项,第二个参数是数组的第二项。可以使用 reduce()函数执行累加数组中所有数值的操作,比如:
let values = [1, 2, 3, 4, 5];
let sum = values.reduce((prev, cur, index, array) => prev + cur);
alert(sum); // 15
第一次执行归并函数时,prev 是 1,cur 是 2。第二次执行时,prev 是 3(1 + 2),cur 是 3(数组第三项)。如此递进,直到把所有项都遍历一次,最后返回归并结果。
reduceRight()方法与之类似,只是方向相反。来看下面的例子:
let values = [1, 2, 3, 4, 5];
let sum = values.reduceRight(function(prev, cur, index, array){
return prev + cur;
});
alert(sum); // 15
在这里,第一次调用归并函数时 prev 是 5,而 cur 是 4。当然,最终结果相同,因为归并操作都是简单的加法。
究竟是使用 reduce()还是 reduceRight(),只取决于遍历数组元素的方向。除此之外,这两个方法没什么区别。
6.4 Map
Map 是一种新的集合类型,为这门语言带来了真正的键/值存储机制。Map 的大多数特性都可以通过 Object 类型实现,但二者之间还是存在一些细微的差异。具体实践中使用哪一个,值得细细甄别。
6.4.1 基本 API
使用 new 关键字和 Map 构造函数可以创建一个空映射:
const m = new Map();
如果想在创建的同时初始化实例,可以给 Map 构造函数传入一个可迭代对象,需要包含键/值对数组。可迭代对象中的每个键/值对都会按照迭代顺序插入到新映射实例中:
// 使用嵌套数组初始化映射
const m1 = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"]
]);
alert(m1.size); // 3
// 使用自定义迭代器初始化映射
const m2 = new Map({
[Symbol.iterator]: function*() {
yield ["key1", "val1"];
yield ["key2", "val2"];
yield ["key3", "val3"];
}
});
alert(m2.size); // 3
// 映射期待的键/值对,无论是否提供
const m3 = new Map([[]]);
alert(m3.has(undefined)); // true
alert(m3.get(undefined)); // undefined
初始化之后,可以使用 set()方法再添加键/值对。另外,可以使用 get()(记得带引号)和 has()进行查询,可以通过 size 属性获取映射中的键/值对的数量,还可以使用 delete()和 clear()删除值。
const m = new Map();
alert(m.has("firstName")); // false
alert(m.get("firstName")); // undefined
alert(m.size); // 0
m.set("firstName", "Matt")
.set("lastName", "Frisbie");
alert(m.has("firstName")); // true
alert(m.get("firstName")); // Matt
alert(m.size); // 2
m.delete("firstName"); // 只删除这一个键/值对
alert(m.has("firstName")); // false
alert(m.has("lastName")); // true
alert(m.size); // 1
m.clear(); // 清除这个映射实例中的所有键/值对
alert(m.has("firstName")); // false
alert(m.has("lastName")); // false
alert(m.size); //
set()方法返回映射实例,因此可以把多个操作连缀起来,包括初始化声明:
const m = new Map().set("key1", "val1");
m.set("key2", "val2")
.set("key3", "val3");
alert(m.size); // 3
Object 只能使用数值、字符串或符号作为键不同,Map 可以使用任何 JavaScript 数据类型作为键。Map 内部使用 SameValueZero 比较操作,基本上相当于使用严格对象相等的标准来检查键的匹配性。与 Object 类似,映射的值是没有限制的。
const m = new Map();
const functionKey = function() {};
const symbolKey = Symbol();
const objectKey = new Object();
m.set(functionKey, "functionValue");
m.set(symbolKey, "symbolValue");
m.set(objectKey, "objectValue");
alert(m.get(functionKey)); // functionValue
alert(m.get(symbolKey)); // symbolValue
alert(m.get(objectKey)); // objectValue
// SameValueZero 比较意味着独立实例不冲突
alert(m.get(function() {})); // undefined
与严格相等一样,在映射中用作键和值的对象及其他“集合”类型,在自己的内容或属性被修改时仍然保持不变:
const m = new Map();
const objKey = {},
objVal = {},
arrKey = [],
arrVal = [];
m.set(objKey, objVal);
m.set(arrKey, arrVal);
objKey.foo = "foo";
objVal.bar = "bar";
arrKey.push("foo");
arrVal.push("bar");
console.log(m.get(objKey)); // {bar: "bar"} //get键获取的是值
console.log(m.get(arrKey)); // ["bar"]
SameValueZero 比较也可能导致意想不到的冲突:
const m = new Map();
const a = 0/"", // NaN
b = 0/"", // NaN
pz = +0,
nz = -0;
alert(a === b); // false
alert(pz === nz); // true
m.set(a, "foo");
m.set(pz, "bar");
alert(m.get(b)); // foo
alert(m.get(nz)); // bar
6.4.2 顺序与迭代
与 Object 类型的一个主要差异是,Map 实例会维护键值对的插入顺序,因此可以根据插入顺序执行迭代操作。
映射实例可以提供一个迭代器(Iterator),能以插入顺序生成[key, value]形式的数组。可以通过 entries()方法(或者 Symbol.iterator 属性,它引用 entries())取得这个迭代器:
const m = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"]
]);
alert(m.entries === m[Symbol.iterator]); // true
for (let pair of m.entries()) {
alert(pair);
}
// [key1,val1]
// [key2,val2]
// [key3,val3]
for (let pair of m[Symbol.iterator]()) {
alert(pair);
}
// [key1,val1]
// [key2,val2]
// [key3,val3]
因为 entries()是默认迭代器,所以可以直接对映射实例使用扩展操作,把映射转换为数组:
const m = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"]
]);
console.log([...m]); // [[key1,val1],[key2,val2],[key3,val3]]
如果不使用迭代器,而是使用回调方式,则可以调用映射的 forEach(callback, opt_thisArg)方法并传入回调,依次迭代每个键/值对。传入的回调接收可选的第二个参数,这个参数用于重写回调内部 this 的值:
const m = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"]
]);
m.forEach((val, key) => alert(`${key} -> ${val}`));
// key1 -> val1
// key2 -> val2
// key3 -> val3
keys()和 values()分别返回以插入顺序生成键和值的迭代器:
const m = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"]
]);
for (let key of m.keys()) {
alert(key);
}
// key1
// key2
// key3
for (let key of m.values()) {
alert(key);
}
// value1
// value2
// value3
键和值在迭代器遍历时是可以修改的,但映射内部的引用则无法修改。当然,这并不妨碍修改作为键或值的对象内部的属性,因为这样并不影响它们在映射实例中的身份:
const m1 = new Map([
["key1", "val1"]
]);
// 作为键的字符串原始值是不能修改的
for (let key of m1.keys()) {
key = "newKey";
alert(key); // newKey
alert(m1.get("key1")); // val1
console.log(m1.get("newKey")); //undefined
}
const keyObj = {id: 1};
const m = new Map([
[keyObj, "val1"]
]);
// 修改了作为键的对象的属性,但对象在映射内部仍然引用相同的值
for (let key of m.keys()) {
key.id = "newKey";
alert(key); // {id: "newKey"}
alert(m.get(keyObj)); // val1
}
alert(keyObj); // {id: "newKey"}
6.4.3 选择 Object 还是 Map
对于多数 Web 开发任务来说,选择 Object 还是 Map 只是个人偏好问题,影响不大。不过,对于在乎内存和性能的开发者来说,对象和映射之间确实存在显著的差别。
1.内存占用
Object 和 Map 的工程级实现在不同浏览器间存在明显差异,但存储单个键/值对所占用的内存数量都会随键的数量线性增加。批量添加或删除键/值对则取决于各浏览器对该类型内存分配的工程实现。不同浏览器的情况不同,但给定固定大小的内存,Map 大约可以比 Object 多存储 50%的键/值对。
2.插入性能
向 Object 和 Map 中插入新键/值对的消耗大致相当,不过插入 Map 在所有浏览器中一般会稍微快一点儿。对这两个类型来说,插入速度并不会随着键/值对数量而线性增加。如果代码涉及大量插入操作,那么显然 Map 的性能更佳。
3.查找速度
与插入不同,从大型 Object 和 Map 中查找键/值对的性能差异极小,但如果只包含少量键/值对,则 Object 有时候速度更快。在把 Object 当成数组使用的情况下(比如使用连续整数作为属性),浏览器引擎可以进行优化,在内存中使用更高效的布局。这对 Map 来说是不可能的。对这两个类型而言,查找速度不会随着键/值对数量增加而线性增加。如果代码涉及大量查找操作,那么某些情况下可能选择 Object 更好一些。
4.删除性能
使用 delete 删除 Object 属性的性能一直以来饱受诟病,目前在很多浏览器中仍然如此。为此,出现了一些伪删除对象属性的操作,包括把属性值设置为 undefined 或 null。但很多时候,这都是一种讨厌的或不适宜的折中。而对大多数浏览器引擎来说,Map 的 delete()操作都比插入和查找更快。如果代码涉及大量删除操作,那么毫无疑问应该选择 Map。
6.5 WeakMap
ECMAScript 6 新增的“弱映射”(WeakMap)是一种新的集合类型,为这门语言带来了增强的键/值对存储机制。WeakMap 是 Map 的“兄弟”类型,其 API 也是 Map 的子集。WeakMap 中的“weak”(弱),描述的是 JavaScript 垃圾回收程序对待“弱映射”中键的方式。
6.5.1 基本 API
可以使用 new 关键字实例化一个空的 WeakMap:
const wm = new WeakMap();
弱映射中的键只能是 Object 或者继承自 Object 的类型,尝试使用非对象设置键会抛出TypeError。值的类型没有限制。
如果想在初始化时填充弱映射,则构造函数可以接收一个可迭代对象,其中需要包含键/值对数组。可迭代对象中的每个键/值都会按照迭代顺序插入新实例中:
const key1 = {id: 1},
key2 = {id: 2},
key3 = {id: 3};
// 使用嵌套数组初始化弱映射
const wm1 = new WeakMap([
[key1, "val1"],
[key2, "val2"],
[key3, "val3"]
]);
alert(wm1.get(key1)); // val1
alert(wm1.get(key2)); // val2
alert(wm1.get(key3)); // val3
// 初始化是全有或全无的操作
// 只要有一个键无效就会抛出错误,导致整个初始化失败
const wm2 = new WeakMap([
[key1, "val1"],
["BADKEY", "val2"],
[key3, "val3"]
]);
// TypeError: Invalid value used as WeakMap key
typeof wm2;
// ReferenceError: wm2 is not defined
// 原始值可以先包装成对象再用作键
const stringKey = new String("key1");
const wm3 = new WeakMap([
stringKey, "val1"
]);
alert(wm3.get(stringKey)); // "val1"
初始化之后可以使用 set()再添加键/值对,可以使用 get()和 has()查询,还可以使用 delete()删除:
const wm = new WeakMap();
const key1 = {id: 1},
key2 = {id: 2};
alert(wm.has(key1)); // false
alert(wm.get(key1)); // undefined
wm.set(key1, "Matt")
.set(key2, "Frisbie");
alert(wm.has(key1)); // true
alert(wm.get(key1)); // Matt
wm.delete(key1); // 只删除这一个键/值对
alert(wm.has(key1)); // false
alert(wm.has(key2)); // true
set()方法返回弱映射实例,因此可以把多个操作连缀起来,包括初始化声明:
const key1 = {id: 1},
key2 = {id: 2},
key3 = {id: 3};
const wm = new WeakMap().set(key1, "val1");
wm.set(key2, "val2")
.set(key3, "val3");
alert(wm.get(key1)); // val1
alert(wm.get(key2)); // val2
alert(wm.get(key3)); // val3
6.5.2 弱键
WeakMap 中“weak”表示弱映射的键是“弱弱地拿着”的。意思就是,这些键不属于正式的引用,不会阻止垃圾回收。但要注意的是,弱映射中值的引用可不是“弱弱地拿着”的。**只要键存在,键/值对就会存在于映射中,并被当作对值的引用,因此就不会被当作垃圾回收。**来看下面的例子:
const wm = new WeakMap();
wm.set({}, "val");
set()方法初始化了一个新对象并将它用作一个字符串的键。因为没有指向这个对象的其他引用,所以当这行代码执行完成后,这个对象键就会被当作垃圾回收。然后,这个键/值对就从弱映射中消失了,使其成为一个空映射。在这个例子中,因为值也没有被引用,所以这对键/值被破坏以后,值本身也会成为垃圾回收的目标。再看一个稍微不同的例子:
const wm = new WeakMap();
const container = {
key: {}
};
wm.set(container.key, "val");
function removeReference() {
container.key = null;
}
这一次,container 对象维护着一个对弱映射键的引用,因此这个对象键不会成为垃圾回收的目标。不过,如果调用了 removeReference(),就会摧毁键对象的最后一个引用,垃圾回收程序就可以把这个键/值对清理掉。
6.5.3 不可迭代键
因为 WeakMap 中的键/值对任何时候都可能被销毁,所以没必要提供迭代其键/值对的能力。当然,也用不着像 clear()这样一次性销毁所有键/值的方法。WeakMap 确实没有这个方法。因为不可能迭代,所以也不可能在不知道对象引用的情况下从弱映射中取得值。即便代码可以访问 WeakMap 实例,也没办法看到其中的内容。
WeakMap 实例之所以限制只能用对象作为键,是为了保证只有通过键对象的引用才能取得值。如果允许原始值,那就没办法区分初始化时使用的字符串字面量和初始化之后使用的一个相等的字符串了。
6.5.4 使用弱映射
1.私有变量
弱映射造就了在 JavaScript 中实现真正私有变量的一种新方式。前提很明确:私有变量会存储在弱映射中,以对象实例为键,以私有成员的字典为值。
下面是一个示例实现:
const wm = new WeakMap();
class User {
constructor(id) {
this.idProperty = Symbol('id');
this.setId(id);
}
setPrivate(property, value) {
const privateMembers = wm.get(this) || {};
privateMembers[property] = value;
wm.set(this, privateMembers);
}
getPrivate(property) {
return wm.get(this)[property];
}
setId(id) {
this.setPrivate(this.idProperty, id);
}
getId() {
return this.getPrivate(this.idProperty);
}
}
const user = new User(123);
alert(user.getId()); // 123
user.setId(456);
alert(user.getId()); // 456
// 并不是真正私有的
alert(wm.get(user)[user.idProperty]); // 456
对于上面的实现,外部代码只需要拿到对象实例的引用和弱映射,就可以取得“私有”变量了。为了避免这种访问,可以用一个闭包把 WeakMap 包装起来,这样就可以把弱映射与外界完全隔离开了:
const User = (() => {
const wm = new WeakMap();
class User {
constructor(id) {
this.idProperty = Symbol('id');
this.setId(id);
}
setPrivate(property, value) {
const privateMembers = wm.get(this) || {};
privateMembers[property] = value;
wm.set(this, privateMembers);
}
getPrivate(property) {
return wm.get(this)[property];
}
setId(id) {
this.setPrivate(this.idProperty, id);
}
getId(id) {
return this.getPrivate(this.idProperty);
}
}
return User;
})();
const user = new User(123);
alert(user.getId()); // 123
user.setId(456);
alert(user.getId()); // 456
这样,拿不到弱映射中的健,也就无法取得弱映射中对应的值。虽然这防止了前面提到的访问,但整个代码也完全陷入了 ES6 之前的闭包私有变量模式
2.DOM 节点元数据
因为 WeakMap 实例不会妨碍垃圾回收,所以非常适合保存关联元数据。来看下面这个例子,其中使用了常规的 Map:
const m = new Map();
const loginButton = document.querySelector('#login');
// 给这个节点关联一些元数据
m.set(loginButton, {disabled: true});
假设在上面的代码执行后,页面被 JavaScript 改变了,原来的登录按钮从 DOM 树中被删掉了。但由于映射中还保存着按钮的引用,所以对应的 DOM 节点仍然会逗留在内存中,除非明确将其从映射中删除或者等到映射本身被销毁。
如果这里使用的是弱映射,如以下代码所示,那么当节点从 DOM 树中被删除后,垃圾回收程序就可以立即释放其内存(假设没有其他地方引用这个对象):
const wm = new WeakMap();
const loginButton = document.querySelector('#login');
// 给这个节点关联一些元数据
wm.set(loginButton, {disabled: true});
6.6 Set
Set 在很多方面都像是加强的 Map,这是因为它们的大多数 API 和行为都是共有的。
6.6.1 基本 API
使用 new 关键字和 Set 构造函数可以创建一个空集合:
const m = new Set();
如果想在创建的同时初始化实例,则可以给 Set 构造函数传入一个可迭代对象,其中需要包含插入到新集合实例中的元素:
// 使用数组初始化集合
const s1 = new Set(["val1", "val2", "val3"]);
alert(s1.size); // 3
// 使用自定义迭代器初始化集合
const s2 = new Set({
[Symbol.iterator]: function*() {
yield "val1";
yield "val2";
yield "val3";
}
});
alert(s2.size); // 3
初始化之后,可以使用 add()增加值,使用 has()查询,通过 size 取得元素数量,以及使用 delete()和 clear()删除元素:
const s = new Set();
alert(s.has("Matt")); // false
alert(s.size); // 0
s.add("Matt")
.add("Frisbie");
alert(s.has("Matt")); // true
alert(s.size); // 2
s.delete("Matt");
alert(s.has("Matt")); // false
alert(s.has("Frisbie")); // true
alert(s.size); // 1
s.clear(); // 销毁集合实例中的所有值
alert(s.has("Matt")); // false
alert(s.has("Frisbie")); // false
alert(s.size); // 0
add()返回集合的实例,所以可以将多个添加操作连缀起来,包括初始化:
const s = new Set().add("val1");
s.add("val2")
.add("val3");
alert(s.size); // 3
与 Map 类似,Set 可以包含任何 JavaScript 数据类型作为值。集合也使用 SameValueZero 操作,基本上相当于使用严格对象相等的标准来检查值的匹配性。
const s = new Set();
const functionVal = function() {};
const symbolVal = Symbol();
const objectVal = new Object();
s.add(functionVal);
s.add(symbolVal);
s.add(objectVal);
alert(s.has(functionVal)); // true
alert(s.has(symbolVal)); // true
alert(s.has(objectVal)); // true
// SameValueZero 检查意味着独立的实例不会冲突
alert(s.has(function() {})); // false
add()和 delete()操作是幂等的。delete()返回一个布尔值,表示集合中是否存在要删除的值:
const s = new Set();
s.add('foo');
alert(s.size); // 1
s.add('foo');
alert(s.size); // 1
// 集合里有这个值
alert(s.delete('foo')); // true
// 集合里没有这个值
alert(s.delete('foo')); // false
6.6.2 顺序与迭代
Set 会维护值插入时的顺序,因此支持按顺序迭代。
集合实例可以提供一个迭代器(Iterator),能以插入顺序生成集合内容。可以通过 values()方法及其别名方法 keys()(或者 Symbol.iterator 属性,它引用 values())取得这个迭代器:
const s = new Set(["val1", "val2", "val3"]);
console.log(s.values === s[Symbol.iterator]); // true
console.log(s.keys === s[Symbol.iterator]); // true
console.log(s.keys === s.values);//true
for (let value of s.values()) {
alert(value);
}
// val1
// val2
// val3
for (let value of s[Symbol.iterator]()) {
alert(value);
}
// val1
// val2
// val3
因为 values()是默认迭代器,所以可以直接对集合实例使用扩展操作,把集合转换为数组:
const s = new Set(["val1", "val2", "val3"]);
console.log([...s]); // ["val1", "val2", "val3"]
集合的 entries()方法返回一个迭代器,可以按照插入顺序产生包含两个元素的数组,这两个元素是集合中每个值的重复出现:
const s = new Set(["val1", "val2", "val3"]);
for (let pair of s.entries()) {
console.log(pair);
}
// ["val1", "val1"]
// ["val2", "val2"]
// ["val3", "val3"]
如果不使用迭代器,而是使用回调方式,则可以调用集合的 forEach()方法并传入回调,依次迭代每个键/值对。传入的回调接收可选的第二个参数,这个参数用于重写回调内部 this 的值:
const s = new Set(["val1", "val2", "val3"]);
s.forEach((val, dupVal) => alert(`${val} -> ${dupVal}`));
// val1 -> val1
// val2 -> val2
// val3 -> val3
修改集合中值的属性不会影响其作为集合值的身份:
const s1 = new Set(["val1"]);
// 字符串原始值作为值不会被修改
for (let value of s1.values()) {
value = "newVal";
alert(value); // newVal
alert(s1.has("val1")); // true
}
const valObj = {id: 1};
const s2 = new Set([valObj]);
// 修改值对象的属性,但对象仍然存在于集合中
for (let value of s2.values()) {
value.id = "newVal";
alert(value); // {id: "newVal"}
alert(s2.has(valObj)); // true
}
alert(valObj); // {id: "newVal"}
6.6.3 定义正式集合操作
从各方面来看,Set 跟 Map 都很相似,只是 API 稍有调整。唯一需要强调的就是集合的 API 对自身的简单操作。很多开发者都喜欢使用 Set 操作,但需要手动实现:或者是子类化 Set,或者是定义一个实用函数库。要把两种方式合二为一,可以在子类上实现静态方法,然后在实例方法中使用这些静态方法。在实现这些操作时,需要考虑几个地方。
-
某些 Set 操作是有关联性的,因此最好让实现的方法能支持处理任意多个集合实例。
-
Set 保留插入顺序,所有方法返回的集合必须保证顺序。
-
尽可能高效地使用内存。扩展操作符的语法很简洁,但尽可能避免集合和数组间的相互转换能够节省对象初始化成本。
-
不要修改已有的集合实例。union(a, b)或 a.union(b)应该返回包含结果的新集合实例
class XSet extends Set {
union(...sets) {
return XSet.union(this, ...sets)
}
intersection(...sets) {
return XSet.intersection(this, ...sets);
}
difference(set) {
return XSet.difference(this, set);
}
symmetricDifference(set) {
return XSet.symmetricDifference(this, set);
}
cartesianProduct(set) {
return XSet.cartesianProduct(this, set);
}
powerSet() {
return XSet.powerSet(this);
}
// 返回两个或更多集合的并集
static union(a, ...bSets) {
const unionSet = new XSet(a);
for (const b of bSets) {
for (const bValue of b) {
unionSet.add(bValue);
}
}
return unionSet;
}
// 返回两个或更多集合的交集
static intersection(a, ...bSets) {
const intersectionSet = new XSet(a);
for (const aValue of intersectionSet) {
for (const b of bSets) {
if (!b.has(aValue)) {
intersectionSet.delete(aValue);
}
}
}
return intersectionSet;
}
// 返回两个集合的差集
static difference(a, b) {
const differenceSet = new XSet(a);
for (const bValue of b) {
if (a.has(bValue)) {
differenceSet.delete(bValue);
}
}
return differenceSet;
}
// 返回两个集合的对称差集
static symmetricDifference(a, b) {
// 按照定义,对称差集可以表达为
return a.union(b).difference(a.intersection(b));
}
// 返回两个集合(数组对形式)的笛卡儿积
// 必须返回数组集合,因为笛卡儿积可能包含相同值的对
static cartesianProduct(a, b) {
const cartesianProductSet = new XSet();
for (const aValue of a) {
for (const bValue of b) {
cartesianProductSet.add([aValue, bValue]);
}
}
return cartesianProductSet;
}
// 返回一个集合的幂集
static powerSet(a) {
const powerSet = new XSet().add(new XSet());
for (const aValue of a) {
for (const set of new XSet(powerSet)) {
powerSet.add(new XSet(set).add(aValue));
}
}
return powerSet;
}
}
6.7 WeakSet
ECMAScript 6 新增的“弱集合”(WeakSet)是一种新的集合类型,为这门语言带来了集合数据结构。WeakSet 是 Set 的“兄弟”类型,其 API 也是 Set 的子集。WeakSet 中的“weak”(弱),描述的是 JavaScript 垃圾回收程序对待“弱集合”中值的方式。
6.7.1 基本 API
可以使用 new 关键字实例化一个空的 WeakSet:
const ws = new WeakSet();
弱集合中的值只能是 Object 或者继承自 Object 的类型,尝试使用非对象设置值会抛出 TypeError。如果想在初始化时填充弱集合,则构造函数可以接收一个可迭代对象,其中需要包含有效的值。可迭代对象中的每个值都会按照迭代顺序插入到新实例中:
const val1 = {id: 1},
val2 = {id: 2},
val3 = {id: 3};
// 使用数组初始化弱集合
const ws1 = new WeakSet([val1, val2, val3]);
alert(ws1.has(val1)); // true
alert(ws1.has(val2)); // true
alert(ws1.has(val3)); // true
// 初始化是全有或全无的操作
// 只要有一个值无效就会抛出错误,导致整个初始化失败
const ws2 = new WeakSet([val1, "BADVAL", val3]);
// TypeError: Invalid value used in WeakSet
typeof ws2;
// ReferenceError: ws2 is not defined
// 原始值可以先包装成对象再用作值
const stringVal = new String("val1");
const ws3 = new WeakSet([stringVal]);
alert(ws3.has(stringVal)); // true
初始化之后可以使用 add()再添加新值,可以使用 has()查询,还可以使用 delete()删除:
const ws = new WeakSet();
const val1 = {id: 1},
val2 = {id: 2};
alert(ws.has(val1)); // false
ws.add(val1)
.add(val2);
alert(ws.has(val1)); // true
alert(ws.has(val2)); // true
ws.delete(val1); // 只删除这一个值
alert(ws.has(val1)); // false
alert(ws.has(val2)); // true
add()方法返回弱集合实例,因此可以把多个操作连缀起来,包括初始化声明:
const val1 = {id: 1},
val2 = {id: 2},
val3 = {id: 3};
const ws = new WeakSet().add(val1);
ws.add(val2)
.add(val3);
alert(ws.has(val1)); // true
alert(ws.has(val2)); // true
alert(ws.has(val3)); // true
6.7.2 弱值
WeakSet 中“weak”表示弱集合的值是“弱弱地拿着”的。意思就是,这些值不属于正式的引用,不会阻止垃圾回收。
来看下面的例子:
const ws = new WeakSet();
ws.add({});
add()方法初始化了一个新对象,并将它用作一个值。因为没有指向这个对象的其他引用,所以当这行代码执行完成后,这个对象值就会被当作垃圾回收。然后,这个值就从弱集合中消失了,使其成为一个空集合。
再看一个稍微不同的例子:
const ws = new WeakSet();
const container = {
val: {}
};
ws.add(container.val);
function removeReference() {
container.val = null;
}
6.7.3 不可迭代值
因为 WeakSet 中的值任何时候都可能被销毁,所以没必要提供迭代其值的能力。当然,也用不着像 clear()这样一次性销毁所有值的方法。WeakSet 确实没有这个方法。因为不可能迭代,所以也不可能在不知道对象引用的情况下从弱集合中取得值。即便代码可以访问 WeakSet 实例,也没办法看到其中的内容。
WeakSet 之所以限制只能用对象作为值,是为了保证只有通过值对象的引用才能取得值。如果允许原始值,那就没办法区分初始化时使用的字符串字面量和初始化之后使用的一个相等的字符串了。
6.7.4 使用弱集合
相比于 WeakMap 实例,WeakSet 实例的用处没有那么大。不过,弱集合在给对象打标签时还是有价值的。
来看下面的例子,这里使用了一个普通 Set:
const disabledElements = new Set();
const loginButton = document.querySelector('#login');
// 通过加入对应集合,给这个节点打上“禁用”标签
disabledElements.add(loginButton);
这样,通过查询元素在不在 disabledElements 中,就可以知道它是不是被禁用了。不过,假如元素从 DOM 树中被删除了,它的引用却仍然保存在 Set 中,因此垃圾回收程序也不能回收它。
为了让垃圾回收程序回收元素的内存,可以在这里使用 WeakSet:
const disabledElements = new WeakSet();
const loginButton = document.querySelector('#login');
// 通过加入对应集合,给这个节点打上“禁用”标签
disabledElements.add(loginButton);
这样,只要 WeakSet 中任何元素从 DOM 树中被删除,垃圾回收程序就可以忽略其存在,而立即释放其内存(假设没有其他地方引用这个对象)
6.8 迭代与扩展操作
4 种原生集合类型定义了默认迭代器:
-
Array
-
所有定型数组(就是6.3,我这里不做介绍,想了解的请看书)
-
Map
-
Set
很简单,这意味着上述所有类型都支持顺序迭代,都可以传入 for-of 循环:
let iterableThings = [
Array.of(1, 2),
typedArr = Int16Array.of(3, 4),
new Map([[5, 6], [7, 8]]),
new Set([9, 10])
];
for (const iterableThing of iterableThings) {
for (const x of iterableThing) {
console.log(x);
}
}
// 1
// 2
// 3
// 4
// [5, 6]
// [7, 8]
// 9
// 10
这意味着所有这些类型都兼容扩展操作符。扩展操作符在对可迭代对象执行浅复制时特别有用,只需简单的语法就可以复制整个对象:
let arr1 = [1, 2, 3];
let arr2 = [...arr1];
console.log(arr1); // [1, 2, 3]
console.log(arr2); // [1, 2, 3]
console.log(arr1 === arr2); // false
对于期待可迭代对象的构造函数,只要传入一个可迭代对象就可以实现复制:
let map1 = new Map([[1, 2], [3, 4]]);
let map2 = new Map(map1);
console.log(map1); // Map(2) { 1 => 2, 3 => 4 }
console.log(map2); // Map(2) { 1 => 2, 3 => 4 }
当然,也可以构建数组的部分元素:
let arr1 = [1, 2, 3];
let arr2 = [0, ...arr1, 4, 5];
console.log(arr2); // [0, 1, 2, 3, 4, 5]
浅复制意味着只会复制对象引用:
let arr1 = [{}];
let arr2 = [...arr1];
arr1[0].foo = 'bar';
console.log(arr2[0]); // { foo: 'bar' }
上面的这些类型都支持多种构建方法,比如 Array.of()和 Array.from()静态方法。在与扩展操作符一起使用时,可以非常方便地实现互操作:
let arr1 = [1, 2, 3];
// 把数组复制到定型数组
let typedArr1 = Int16Array.of(...arr1);
let typedArr2 = Int16Array.from(arr1);
console.log(typedArr1); // Int16Array [1, 2, 3]
console.log(typedArr2); // Int16Array [1, 2, 3]
// 把数组复制到映射
let map = new Map(arr1.map((x) => [x, 'val' + x]));
console.log(map); // Map(3) { 1 => 'val1', 2 => 'val2', 3 => 'val3' }
// 把数组复制到集合
let set = new Set(typedArr2);
console.log(set); // Set {1, 2, 3}
// 把集合复制回数组
let arr2 = [...set];
console.log(arr2); // [1, 2, 3]
6.9 小结
JavaScript 中的对象是引用值,可以通过几种内置引用类型创建特定类型的对象。
-
引用类型与传统面向对象编程语言中的类相似,但实现不同。
-
Object 类型是一个基础类型,所有引用类型都从它继承了基本的行为。
-
Array 类型表示一组有序的值,并提供了操作和转换值的能力。
-
定型数组包含一套不同的引用类型,用于管理数值在内存中的类型。
-
Date 类型提供了关于日期和时间的信息,包括当前日期和时间以及计算。
-
RegExp 类型是 ECMAScript 支持的正则表达式的接口,提供了大多数基本正则表达式以及一些高级正则表达式的能力。
JavaScript 比较独特的一点是,函数其实是 Function 类型的实例,这意味着函数也是对象。由于函数是对象,因此也就具有能够增强自身行为的方法。
因为原始值包装类型的存在,所以 JavaScript 中的原始值可以拥有类似对象的行为。有 3 种原始值包装类型:Boolean、Number 和 String。它们都具有如下特点。
-
每种包装类型都映射到同名的原始类型。
-
在以读模式访问原始值时,后台会实例化一个原始值包装对象,通过这个对象可以操作数据。
-
涉及原始值的语句只要一执行完毕,包装对象就会立即销毁。
JavaScript 还有两个在一开始执行代码时就存在的内置对象:Global 和 Math。其中,Global 对象在大多数 ECMAScript 实现中无法直接访问。不过浏览器将 Global 实现为 window 对象。所有全局变量和函数都是 Global 对象的属性。Math 对象包含辅助完成复杂数学计算的属性和方法。
ECMAScript 6 新增了一批引用类型:Map、WeakMap、Set 和 WeakSet。这些类型为组织应用程序数据和简化内存管理提供了新能力。
第7章 迭代器与生成器
7.1 理解迭代
在 JavaScript 中,计数循环就是一种最简单的迭代:
for (let i = 1; i <= 10; ++i) {
console.log(i);
}
循环是迭代机制的基础,这是因为它可以指定迭代的次数,以及每次迭代要执行什么操作。每次循环都会在下一次迭代开始之前完成,而每次迭代的顺序都是事先定义好的。
迭代会在一个有序集合上进行。(“有序”可以理解为集合中所有项都可以按照既定的顺序被遍历到,特别是开始和结束项有明确的定义。)数组是 JavaScript 中有序集合的最典型例子。
let collection = ['foo', 'bar', 'baz'];
for (let index = 0; index < collection.length; ++index) {
console.log(collection[index]);
}
因为数组有已知的长度,且数组每一项都可以通过索引获取,所以整个数组可以通过递增索引来遍历。由于如下原因,通过这种循环来执行例程并不理想。
-
迭代之前需要事先知道如何使用数据结构。数组中的每一项都只能先通过引用取得数组对象,然后再通过[]操作符取得特定索引位置上的项。这种情况并不适用于所有数据结构。
-
遍历顺序并不是数据结构固有的。通过递增索引来访问数据是特定于数组类型的方式,并不适用于其他具有隐式顺序的数据结构。
ES5 新增了 Array.prototype.forEach()方法,向通用迭代需求迈进了一步(但仍然不够理想):
let collection = ['foo', 'bar', 'baz'];
collection.forEach((item) => console.log(item));
// foo
// bar
// baz
这个方法解决了单独记录索引和通过数组对象取得值的问题。不过,没有办法标识迭代何时终止。因此这个方法只适用于数组,而且回调结构也比较笨拙。
在 ECMAScript 较早的版本中,执行迭代必须使用循环或其他辅助结构。随着代码量增加,代码会变得越发混乱。很多语言都通过原生语言结构解决了这个问题,开发者无须事先知道如何迭代就能实现迭代操作。这个解决方案就是迭代器模式。JavaScript 在 ECMAScript 6 以后支持了迭代器模式。
7.2 迭代器模式
迭代器模式描述了一个方案,即可以把有些结构称为“可迭代对象”(iterable),因为它们实现了正式的 Iterable 接口,而且可以通过迭代器 Iterator 消费。
可迭代对象是一种抽象的说法。基本上,可以把可迭代对象理解成数组或集合这样的集合类型的对象。它们包含的元素都是有限的,而且都具有无歧义的遍历顺序:
// 数组的元素是有限的
// 递增索引可以按序访问每个元素
let arr = [3, 1, 4];
// 集合的元素是有限的
// 可以按插入顺序访问每个元素
let set = new Set().add(3).add(1).add(4);
不过,可迭代对象不一定是集合对象,也可以是仅仅具有类似数组行为的其他数据结构,比如本章开头提到的计数循环。该循环中生成的值是暂时性的,但循环本身是在执行迭代。计数循环和数组都具有可迭代对象的行为。
任何实现 Iterable 接口的数据结构都可以被实现 Iterator 接口的结构“消费”(consume)。迭代器(iterator)是按需创建的一次性对象。每个迭代器都会关联一个可迭代对象,而迭代器会暴露迭代器关联可迭代对象的 API。迭代器无须了解与其关联的可迭代对象的结构,只需要知道如何取得连续的值。这种概念上的分离正是 Iterable 和 Iterator 的强大之处。
7.2.1 可迭代协议
实现 Iterable 接口(可迭代协议)要求同时具备两种能力:支持迭代的自我识别能力和创建实现Iterator 接口的对象的能力。在 ECMAScript 中,这意味着必须暴露一个属性作为“默认迭代器”,而且这个属性必须使用特殊的 Symbol.iterator 作为键。这个默认迭代器属性必须引用一个迭代器工厂函数,调用这个工厂函数必须返回一个新迭代器。
很多内置类型都实现了 Iterable 接口:
-
字符串
-
数组
-
映射
-
集合
-
arguments 对象
-
NodeList 等 DOM 集合类型
检查是否存在默认迭代器属性可以暴露这个工厂函数:
let num = 1;
let obj = {};
// 这两种类型没有实现迭代器工厂函数
console.log(num[Symbol.iterator]); // undefined
console.log(obj[Symbol.iterator]); // undefined
let str = 'abc';
let arr = ['a', 'b', 'c'];
let map = new Map().set('a', 1).set('b', 2).set('c', 3);
let set = new Set().add('a').add('b').add('c');
let els = document.querySelectorAll('div');
// 这些类型都实现了迭代器工厂函数
console.log(str[Symbol.iterator]); // f values() { [native code] }
console.log(arr[Symbol.iterator]); // f values() { [native code] }
console.log(map[Symbol.iterator]); // f values() { [native code] }
console.log(set[Symbol.iterator]); // f values() { [native code] }
console.log(els[Symbol.iterator]); // f values() { [native code] }
// 调用这个工厂函数会生成一个迭代器
console.log(str[Symbol.iterator]()); // StringIterator {}
console.log(arr[Symbol.iterator]()); // ArrayIterator {}
console.log(map[Symbol.iterator]()); // MapIterator {}
console.log(set[Symbol.iterator]()); // SetIterator {}
console.log(els[Symbol.iterator]()); // ArrayIterator {}
实际写代码过程中,不需要显式调用这个工厂函数来生成迭代器。实现可迭代协议的所有类型都会自动兼容接收可迭代对象的任何语言特性。接收可迭代对象的原生语言特性包括:
-
for-of 循环
-
数组解构
-
扩展操作符
-
Array.from()
-
创建集合
-
创建映射
-
Promise.all()接收由期约组成的可迭代对象
-
Promise.race()接收由期约组成的可迭代对象
-
yield*操作符,在生成器中使用
这些原生语言结构会在后台调用提供的可迭代对象的这个工厂函数,从而创建一个迭代器:
let arr = ['foo', 'bar', 'baz'];
// for-of 循环
for (let el of arr) {
console.log(el);
}
// foo
// bar
// baz
// 数组解构
let [a, b, c] = arr;
console.log(a, b, c); // foo, bar, baz
// 扩展操作符
let arr2 = [...arr];
console.log(arr2); // ['foo', 'bar', 'baz']
// Array.from()
let arr3 = Array.from(arr);
console.log(arr3); // ['foo', 'bar', 'baz']
// Set 构造函数
let set = new Set(arr);
console.log(set); // Set(3) {'foo', 'bar', 'baz'}
// Map 构造函数
let pairs = arr.map((x, i) => [x, i]);
console.log(pairs); // [['foo', 0], ['bar', 1], ['baz', 2]]
let map = new Map(pairs);
console.log(map); // Map(3) { 'foo'=>0, 'bar'=>1, 'baz'=>2 }
如果对象原型链上的父类实现了 Iterable 接口,那这个对象也就实现了这个接口:
class FooArray extends Array {}
let fooArr = new FooArray('foo', 'bar', 'baz');
for (let el of fooArr) {
console.log(el);
}
// foo
// bar
// baz
7.2.2 迭代器协议
迭代器是一种一次性使用的对象,用于迭代与其关联的可迭代对象。迭代器 API 使用 next()方法在可迭代对象中遍历数据。每次成功调用 next(),都会返回一个 IteratorResult 对象,其中包含迭代器返回的下一个值。若不调用 next(),则无法知道迭代器的当前位置。
next()方法返回的迭代器对象 IteratorResult 包含两个属性:done 和 value。done 是一个布尔值,表示是否还可以再次调用 next()取得下一个值;value 包含可迭代对象的下一个值(done 为false),或者 undefined(done 为 true)。done: true 状态称为“耗尽”。可以通过以下简单的数组来演示:
// 可迭代对象
let arr = ['foo', 'bar'];
// 迭代器工厂函数
console.log(arr[Symbol.iterator]); // f values() { [native code] }
// 迭代器
let iter = arr[Symbol.iterator]();
console.log(iter); // ArrayIterator {}
// 执行迭代
console.log(iter.next()); // { done: false, value: 'foo' }
console.log(iter.next()); // { done: false, value: 'bar' }
console.log(iter.next()); // { done: true, value: undefined }
这里通过创建迭代器并调用 next()方法按顺序迭代了数组,直至不再产生新值。迭代器并不知道怎么从可迭代对象中取得下一个值,也不知道可迭代对象有多大。只要迭代器到达 done: true 状态,后续调用 next()就一直返回同样的值了:
let arr = ['foo'];
let iter = arr[Symbol.iterator]();
console.log(iter.next()); // { done: false, value: 'foo' }
console.log(iter.next()); // { done: true, value: undefined }
console.log(iter.next()); // { done: true, value: undefined }
console.log(iter.next()); // { done: true, value: undefined }
每个迭代器都表示对可迭代对象的一次性有序遍历。不同迭代器的实例相互之间没有联系,只会独立地遍历可迭代对象:
let arr = ['foo', 'bar'];
let iter1 = arr[Symbol.iterator]();
let iter2 = arr[Symbol.iterator]();
console.log(iter1.next()); // { done: false, value: 'foo' }
console.log(iter2.next()); // { done: false, value: 'foo' }
console.log(iter2.next()); // { done: false, value: 'bar' }
console.log(iter1.next()); // { done: false, value: 'bar' }
迭代器并不与可迭代对象某个时刻的快照绑定,而仅仅是使用游标来记录遍历可迭代对象的历程。如果可迭代对象在迭代期间被修改了,那么迭代器也会反映相应的变化:
let arr = ['foo', 'baz'];
let iter = arr[Symbol.iterator]();
console.log(iter.next()); // { done: false, value: 'foo' }
// 在数组中间插入值
arr.splice(1, 0, 'bar');
console.log(iter.next()); // { done: false, value: 'bar' }
console.log(iter.next()); // { done: false, value: 'baz' }
console.log(iter.next()); // { done: true, value: undefined }
注意:迭代器维护着一个指向可迭代对象的引用,因此迭代器会阻止垃圾回收程序回收可迭代对象。
“迭代器”的概念有时候容易模糊,因为它可以指通用的迭代,也可以指接口,还可以指正式的迭\代器类型。下面的例子比较了一个显式的迭代器实现和一个原生的迭代器实现。
// 这个类实现了可迭代接口(Iterable)
// 调用默认的迭代器工厂函数会返回
// 一个实现迭代器接口(Iterator)的迭代器对象
class Foo {
[Symbol.iterator]() {
return {
next() {
return { done: false, value: 'foo' };
}
}
}
}
let f = new Foo();
// 打印出实现了迭代器接口的对象
console.log(f[Symbol.iterator]()); // { next: f() {} }
// Array 类型实现了可迭代接口(Iterable)
// 调用 Array 类型的默认迭代器工厂函数
// 会创建一个 ArrayIterator 的实例
let a = new Array();
// 打印出 ArrayIterator 的实例
console.log(a[Symbol.iterator]()); // Array Iterator {}
与 Iterable 接口类似,任何实现 Iterator 接口的对象都可以作为迭代器使用。下面这个例子中的 Counter 类只能被迭代一定的次数:
class Counter {
// Counter 的实例应该迭代 limit 次
constructor(limit) {
this.count = 1;
this.limit = limit;
}
next() {
if (this.count <= this.limit) {
return { done: false, value: this.count++ };
} else {
return { done: true, value: undefined };
}
}
[Symbol.iterator]() {
return this;
}
}
let counter = new Counter(3);
for (let i of counter) {
console.log(i);
}
// 1
// 2
// 3
这个类实现了 Iterator 接口,但不理想。这是因为它的每个实例只能被迭代一次:
for (let i of counter) { console.log(i); }
// 1
// 2
// 3
for (let i of counter) { console.log(i); }
// (nothing logged)
为了让一个可迭代对象能够创建多个迭代器,必须每创建一个迭代器就对应一个新计数器。为此,可以把计数器变量放到闭包里,然后通过闭包返回迭代器:
class Counter {
constructor(limit) {
this.limit = limit;
}
[Symbol.iterator]() {
let count = 1,
limit = this.limit;
return {
next() {
if (count <= limit) {
return { done: false, value: count++ };
} else {
return { done: true, value: undefined };
}
}
};
}
}
let counter = new Counter(3);
for (let i of counter) { console.log(i); }
// 1
// 2
// 3
for (let i of counter) { console.log(i); }
// 1
// 2
// 3
每个以这种方式创建的迭代器也实现了 Iterable 接口。Symbol.iterator 属性引用的工厂函数会返回相同的迭代器:
let arr = ['foo', 'bar', 'baz'];
let iter1 = arr[Symbol.iterator]();
console.log(iter1[Symbol.iterator]); // f values() { [native code] }
let iter2 = iter1[Symbol.iterator]();
console.log(iter1 === iter2); // true
因为每个迭代器也实现了 Iterable 接口,所以它们可以用在任何期待可迭代对象的地方,比如for-of 循环:
let arr = [3, 1, 4];
let iter = arr[Symbol.iterator]();
for (let item of arr ) { console.log(item); }
// 3
// 1
// 4
for (let item of iter ) { console.log(item); }
// 3
// 1
// 4
7.2.4 提前终止迭代器
可选的 return()方法用于指定在迭代器提前关闭时执行的逻辑。执行迭代的结构在想让迭代器知道它不想遍历到可迭代对象耗尽时,就可以“关闭”迭代器。可能的情况包括:
-
for-of 循环通过 break、continue、return 或 throw 提前退出;
-
解构操作并未消费所有值。
return()方法必须返回一个有效的 IteratorResult 对象。简单情况下,可以只返回{ done: true }。因为这个返回值只会用在生成器的上下文中,所以本章后面再讨论这种情况。
如下面的代码所示,内置语言结构在发现还有更多值可以迭代,但不会消费这些值时,会自动调用return()方法。
class Counter {
constructor(limit) {
this.limit = limit;
}
[Symbol.iterator]() {
let count = 1,
limit = this.limit;
return {
next() {
if (count <= limit) {
return { done: false, value: count++ };
} else {
return { done: true };
}
},
return() {
console.log('Exiting early');
return { done: true };
}
};
}
}
let counter1 = new Counter(5);
for (let i of counter1) {
if (i > 2) {
break;
}
console.log(i);
}
// 1
// 2
// Exiting early
let counter2 = new Counter(5);
try {
for (let i of counter2) {
if (i > 2) {
throw 'err';
}
console.log(i);
}
} catch(e) {}
// 1
// 2
// Exiting early
let counter3 = new Counter(5);
let [a, b] = counter3;
// Exiting early
如果迭代器没有关闭,则还可以继续从上次离开的地方继续迭代。比如,数组的迭代器就是不能关闭的:
let a = [1, 2, 3, 4, 5];
let iter = a[Symbol.iterator]();
for (let i of iter) {
console.log(i);
if (i > 2) {
break
}
}
// 1
// 2
// 3
for (let i of iter) {
console.log(i);
}
// 4
// 5
因为 return()方法是可选的,所以并非所有迭代器都是可关闭的。要知道某个迭代器是否可关闭,可以测试这个迭代器实例的 return 属性是不是函数对象。不过,仅仅给一个不可关闭的迭代器增加这个方法并不能让它变成可关闭的。这是因为调用 return()不会强制迭代器进入关闭状态。即便如此,return()方法还是会被调用。
let a = [1, 2, 3, 4, 5];
let iter = a[Symbol.iterator]();
iter.return = function() {
console.log('Exiting early');
return { done: true };
};
for (let i of iter) {
console.log(i);
if (i > 2) {
break
}
}
// 1
// 2
// 3
// 提前退出
for (let i of iter) {
console.log(i);
}
// 4
// 5
7.3 生成器
生成器是 ECMAScript 6 新增的一个极为灵活的结构,拥有在一个函数块内暂停和恢复代码执行的能力。使用生成器可以自定义迭代器和实现协程。
7.3.1 生成器基础
生成器的形式是一个函数,函数名称前面加一个星号(*)表示它是一个生成器。只要是可以定义函数的地方,就可以定义生成器。
// 生成器函数声明
function* generatorFn() {}
// 生成器函数表达式
let generatorFn = function* () {}
// 作为对象字面量方法的生成器函数
let foo = {
* generatorFn() {}
}
// 作为类实例方法的生成器函数
class Foo {
* generatorFn() {}
}
// 作为类静态方法的生成器函数
class Bar {
static * generatorFn() {}
}
注意 箭头函数不能用来定义生成器函数。
标识生成器函数的星号不受两侧空格的影响:
// 等价的生成器函数:
function* generatorFnA() {}
function *generatorFnB() {}
function * generatorFnC() {}
// 等价的生成器方法:
class Foo {
*generatorFnD() {}
* generatorFnE() {}
}
调用生成器函数会产生一个生成器对象。生成器对象一开始处于暂停执行(suspended)的状态。与迭代器相似,生成器对象也实现了 Iterator 接口,因此具有 next()方法。调用这个方法会让生成器开始或恢复执行。
function* generatorFn() {}
const g = generatorFn();
console.log(g); // generatorFn {}
console.log(g.next); // f next() { [native code] }
next()方法的返回值类似于迭代器,有一个 done 属性和一个 value 属性。函数体为空的生成器函数中间不会停留,调用一次 next()就会让生成器到达 done: true 状态。
function* generatorFn() {}
let generatorObject = generatorFn();
console.log(generatorObject); // generatorFn {}
console.log(generatorObject.next()); // { done: true, value: undefined }
value 属性是生成器函数的返回值,默认值为 undefined,可以通过生成器函数的返回值指定:
function* generatorFn() {
return 'foo';
}
let generatorObject = generatorFn();
console.log(generatorObject); // generatorFn {}
console.log(generatorObject.next()); // { done: true, value: 'foo' }
生成器函数只会在初次调用 next()方法后开始执行,如下所示:
console.log('foobar');
}
// 初次调用生成器函数并不会打印日志
let generatorObject = generatorFn();
generatorObject.next(); // foobar
生成器对象实现了 Iterable 接口,它们默认的迭代器是自引用的:
function* generatorFn() {}
console.log(generatorFn);
// f* generatorFn() {}
console.log(generatorFn()[Symbol.iterator]);
// f [Symbol.iterator]() {native code}
console.log(generatorFn());
// generatorFn {}
console.log(generatorFn()[Symbol.iterator]());
// generatorFn {}
const g = generatorFn();
console.log(g === g[Symbol.iterator]());
// true
7.3.2 通过 yield 中断执行
yield 关键字可以让生成器停止和开始执行,也是生成器最有用的地方。生成器函数在遇到 yield关键字之前会正常执行。遇到这个关键字后,执行会停止,函数作用域的状态会被保留。停止执行的生成器函数只能通过在生成器对象上调用 next()方法来恢复执行:
function* generatorFn() {
yield;
}
let generatorObject = generatorFn();
console.log(generatorObject.next()); // { done: false, value: undefined }
console.log(generatorObject.next()); // { done: true, value: undefined }
此时的yield 关键字有点像函数的中间返回语句,它生成的值会出现在 next()方法返回的对象里。通过 yield 关键字退出的生成器函数会处在 done: false 状态;通过 return 关键字退出的生成器函数会处于 done: true 状态。
function* generatorFn() {
yield 'foo';
yield 'bar';
return 'baz';
}
let generatorObject = generatorFn();
console.log(generatorObject.next()); // { done: false, value: 'foo' }
console.log(generatorObject.next()); // { done: false, value: 'bar' }
console.log(generatorObject.next()); // { done: true, value: 'baz' }
生成器函数内部的执行流程会针对每个生成器对象区分作用域。在一个生成器对象上调用 next()不会影响其他生成器:
function* generatorFn() {
yield 'foo';
yield 'bar';
return 'baz';
}
let generatorObject1 = generatorFn();
let generatorObject2 = generatorFn();
console.log(generatorObject1.next()); // { done: false, value: 'foo' }
console.log(generatorObject2.next()); // { done: false, value: 'foo' }
console.log(generatorObject2.next()); // { done: false, value: 'bar' }
console.log(generatorObject1.next()); // { done: false, value: 'bar' }
yield 关键字只能在生成器函数内部使用,用在其他地方会抛出错误。类似函数的 return 关键字,yield 关键字必须直接位于生成器函数定义中,出现在嵌套的非生成器函数中会抛出语法错误:
// 有效
function* validGeneratorFn() {
yield;
}
// 无效
function* invalidGeneratorFnA() {
function a() {
yield;
}
}
// 无效
function* invalidGeneratorFnB() {
const b = () => {
yield;
}
}
// 无效
function* invalidGeneratorFnC() {
(() => {
yield;
})();
}
1.生成器对象作为可迭代对象
在生成器对象上显式调用 next()方法的用处并不大。其实,如果把生成器对象当成可迭代对象,那么使用起来会更方便:
function* generatorFn() {
yield 1;
yield 2;
yield 3;
}
for (const x of generatorFn()) {
console.log(x);
}
// 1
// 2
// 3
在需要自定义迭代对象时,这样使用生成器对象会特别有用。比如,我们需要定义一个可迭代对象,而它会产生一个迭代器,这个迭代器会执行指定的次数。使用生成器,可以通过一个简单的循环来实现:
function* nTimes(n) {
while(n--) {
yield;
}
}
for (let _ of nTimes(3)) {
console.log('foo');
}
// foo
// foo
// foo
传给生成器的函数可以控制迭代循环的次数。在 n 为 0 时,while 条件为假,循环退出,生成器函数返回。
2.使用 yield 实现输入和输出
除了可以作为函数的中间返回语句使用,yield 关键字还可以作为函数的中间参数使用。上一次让生成器函数暂停的 yield 关键字会接收到传给 next()方法的第一个值。这里有个地方不太好理解——第一次调用 next()传入的值不会被使用,因为这一次调用是为了开始执行生成器函数:
function* generatorFn(initial) {
console.log(initial);
console.log(yield);
console.log(yield);
}
let generatorObject = generatorFn('foo');
generatorObject.next('bar'); // foo
generatorObject.next('baz'); // baz
generatorObject.next('qux'); // qux
//yield 关键字可以同时用于输入和输出,如下例所示:
function* generatorFn() {
return yield 'foo';
}
let generatorObject = generatorFn();
console.log(generatorObject.next()); // { done: false, value: 'foo' }
console.log(generatorObject.next('bar')); // { done: true, value: 'bar' }
因为函数必须对整个表达式求值才能确定要返回的值,所以它在遇到 yield 关键字时暂停执行并计算出要产生的值:“foo”。下一次调用 next()传入了"bar",作为交给同一个 yield 的值。然后这个值被确定为本次生成器函数要返回的值。
yield 关键字并非只能使用一次。比如,以下代码就定义了一个无穷计数生成器函数:
for (let i = 0;;++i) {
yield i;
}
}
let generatorObject = generatorFn();
console.log(generatorObject.next().value); // 0
console.log(generatorObject.next().value); // 1
console.log(generatorObject.next().value); // 2
console.log(generatorObject.next().value); // 3
console.log(generatorObject.next().value); // 4
console.log(generatorObject.next().value); // 5
...
假设我们想定义一个生成器函数,它会根据配置的值迭代相应次数并产生迭代的索引。初始化一个新数组可以实现这个需求,但不用数组也可以实现同样的行为:
function* nTimes(n) {
for (let i = 0; i < n; ++i) {
yield i;
}
}
for (let x of nTimes(3)) {
console.log(x);
}
// 0
// 1
// 2
//使用 while 循环也可以,而且代码稍微简洁一点:
function* nTimes(n) {
let i = 0;
while(n--) {
yield i++;
}
}
for (let x of nTimes(3)) {
console.log(x);
}
// 0
// 1
// 2
//使用生成器也可以实现范围和填充数组:
function* range(start, end) {
while(end > start) {
yield start++;
}
}
for (const x of range(4, 7)) {
console.log(x);
}
// 4
// 5
// 6
function* zeroes(n) {
while(n--) {
yield 0;
}
}
console.log(Array.from(zeroes(8))); // [0, 0, 0, 0, 0, 0, 0, 0]
3.产生可迭代对象
可以使用星号增强 yield 的行为,让它能够迭代一个可迭代对象,从而一次产出一个值:
// 等价的 generatorFn:
// function* generatorFn() {
// for (const x of [1, 2, 3]) {
// yield x;
// }
// }
function* generatorFn() {
yield* [1, 2, 3];
}
let generatorObject = generatorFn();
for (const x of generatorFn()) {
console.log(x);
}
// 1
// 2
// 3
与生成器函数的星号类似,yield 星号两侧的空格不影响其行为:
function* generatorFn() {
yield* [1, 2];
yield *[3, 4];
yield * [5, 6];
}
for (const x of generatorFn()) {
console.log(x);
}
// 1
// 2
// 3
// 4
// 5
// 6
因为 yield*实际上只是将一个可迭代对象序列化为一连串可以单独产出的值,所以这跟把 yield放到一个循环里没什么不同。下面两个生成器函数的行为是等价的:
function* generatorFnA() {
for (const x of [1, 2, 3]) {
yield x;
}
}
for (const x of generatorFnA()) {
console.log(x);
}
// 1
// 2
// 3
function* generatorFnB() {
yield* [1, 2, 3];
}
for (const x of generatorFnB()) {
console.log(x);
}
// 1
// 2
// 3
yield*的值是关联迭代器返回 done: true 时的 value 属性。对于普通迭代器来说,这个值是undefined:
function* generatorFn() {
console.log('iter value:', yield* [1, 2, 3]);
}
for (const x of generatorFn()) {
console.log('value:', x);
}
// value: 1
// value: 2
// value: 3
// iter value: undefined
对于生成器函数产生的迭代器来说,这个值就是生成器函数返回的值:
yield 'foo';
return 'bar';
}
function* outerGeneratorFn(genObj) {
console.log('iter value:', yield* innerGeneratorFn());
}
for (const x of outerGeneratorFn()) {
console.log('value:', x);
}
// value: foo
// iter value: bar
4.使用 **yield***实现递归算法
yield*最有用的地方是实现递归操作,此时生成器可以产生自身。看下面的例子:
function* nTimes(n) {
if (n > 0) {
yield* nTimes(n - 1);
yield n - 1;
}
}
for (const x of nTimes(3)) {
console.log(x);
}
// 0
// 1
// 2
在这个例子中,每个生成器首先都会从新创建的生成器对象产出每个值,然后再产出一个整数。结果就是生成器函数会递归地减少计数器值,并实例化另一个生成器对象。从最顶层来看,这就相当于创建一个可迭代对象并返回递增的整数。
7.3.3 生成器作为默认迭代器
因为生成器对象实现了 Iterable 接口,而且生成器函数和默认迭代器被调用之后都产生迭代器,所以生成器格外适合作为默认迭代器。下面是一个简单的例子,这个类的默认迭代器可以用一行代码产出类的内容:
class Foo {
constructor() {
this.values = [1, 2, 3];
}
* [Symbol.iterator]() {
yield* this.values;
}
}
const f = new Foo();
for (const x of f) {
console.log(x);
}
// 1
// 2
// 3
这里,for-of 循环调用了默认迭代器(它恰好又是一个生成器函数)并产生了一个生成器对象。这个生成器对象是可迭代的,所以完全可以在迭代中使用。
7.3.4 提前终止生成器
与迭代器类似,生成器也支持“可关闭”的概念。一个实现 Iterator 接口的对象一定有 next()方法,还有一个可选的 return()方法用于提前终止迭代器。生成器对象除了有这两个方法,还有第三个方法:throw()。
function* generatorFn() {}
const g = generatorFn();
console.log(g); // generatorFn {}
console.log(g.next); // f next() { [native code] }
console.log(g.return); // f return() { [native code] }
console.log(g.throw); // f throw() { [native code] }
return()和 throw()方法都可以用于强制生成器进入关闭状态。
1.return()
return()方法会强制生成器进入关闭状态。提供给 return()方法的值,就是终止迭代器对象的值:
function* generatorFn() {
for (const x of [1, 2, 3]) {
yield x;
}
}
const g = generatorFn();
console.log(g); // generatorFn {}
console.log(g.return(4)); // { done: true, value: 4 }
console.log(g); // generatorFn {}
与迭代器不同,所有生成器对象都有 return()方法,只要通过它进入关闭状态,就无法恢复了。后续调用 next()会显示 done: true 状态,而提供的任何返回值都不会被存储或传播:
续调用 next()会显示 done: true 状态,而提供的任何返回值都不会被存储或传播:
function* generatorFn() {
for (const x of [1, 2, 3]) {
yield x;
}
}
const g = generatorFn();
console.log(g.next()); // { done: false, value: 1 }
console.log(g.return(4)); // { done: true, value: 4 }
console.log(g.next()); // { done: true, value: undefined }
console.log(g.next()); // { done: true, value: undefined }
console.log(g.next()); // { done: true, value: undefined }
for-of 循环等内置语言结构会忽略状态为 done: true 的 IteratorObject 内部返回的值。
function* generatorFn() {
for (const x of [1, 2, 3]) {
yield x;
}
}
const g = generatorFn();
for (const x of g) {
if (x > 1) {
g.return(4);
}
console.log(x);
}
// 1
// 2
2.throw()
throw()方法会在暂停的时候将一个提供的错误注入到生成器对象中。如果错误未被处理,生成器就会关闭:
function* generatorFn() {
for (const x of [1, 2, 3]) {
yield x;
}
}
const g = generatorFn();
console.log(g); // generatorFn {}
try {
g.throw('foo');
} catch (e) {
console.log(e); // foo
}
console.log(g); // generatorFn {}
不过,假如生成器函数内部处理了这个错误,那么生成器就不会关闭,而且还可以恢复执行。错误处理会跳过对应的 yield,因此在这个例子中会跳过一个值。比如:
function* generatorFn() {
for (const x of [1, 2, 3]) {
try {
yield x;
} catch(e) {}
}
}
const g = generatorFn();
console.log(g.next()); // { done: false, value: 1}
g.throw('foo');
console.log(g.next()); // { done: false, value: 3}
在这个例子中,生成器在 try/catch 块中的 yield 关键字处暂停执行。在暂停期间,throw()方法向生成器对象内部注入了一个错误:字符串"foo"。这个错误会被 yield 关键字抛出。因为错误是在生成器的 try/catch 块中抛出的,所以仍然在生成器内部被捕获。可是,由于 yield 抛出了那个错误,生成器就不会再产出值 2。此时,生成器函数继续执行,在下一次迭代再次遇到 yield 关键字时产出了值 3。
注意:如果生成器对象还没有开始执行,那么调用 throw()抛出的错误不会在函数内部被捕获,因为这相当于在函数块外部抛出了错误。
7.4 小结
迭代是一种所有编程语言中都可以看到的模式。ECMAScript 6 正式支持迭代模式并引入了两个新的语言特性:迭代器和生成器。
迭代器是一个可以由任意对象实现的接口,支持连续获取对象产出的每一个值。任何实现 Iterable接口的对象都有一个 Symbol.iterator 属性,这个属性引用默认迭代器。默认迭代器就像一个迭代器工厂,也就是一个函数,调用之后会产生一个实现 Iterator 接口的对象。
迭代器必须通过连续调用 next()方法才能连续取得值,这个方法返回一个 IteratorObject。这个对象包含一个 done 属性和一个 value 属性。前者是一个布尔值,表示是否还有更多值可以访问;后者包含迭代器返回的当前值。这个接口可以通过手动反复调用 next()方法来消费,也可以通过原生消费者,比如 for-of 循环来自动消费。
生成器是一种特殊的函数,调用之后会返回一个生成器对象。生成器对象实现了 Iterable 接口,因此可用在任何消费可迭代对象的地方。生成器的独特之处在于支持 yield 关键字,这个关键字能够暂停执行生成器函数。使用 yield 关键字还可以通过 next()方法接收输入和产生输出。在加上星号之后,yield 关键字可以将跟在它后面的可迭代对象序列化为一连串值。