Multimodal Foundation Models:From Specialists to General-Purpose Assistants(Chapter 5)
Multimodal Foundation Models:From Specialists to General-Purpose Assistants
Chapter 5 Large Multimodal Models: Training with LLM
5.1 Background
5.1.1 Image-to-Text Generative Models

LMMs当前主要形式是图生文模型,模型结构和训练目标如相似,如上图。
5.1.2 Case Studies
Case study I: LMM trained with image-text pairwise instances:GIT,BLIP2
Case study II: LMM trained with interleaved image-text sequence instances:Flamingo
Multimodal in-context-learning:Flamingo最吸引人的方面可能是新兴的特性:多模式上下文学习。上下文学习能力使Flamingo成为多模式领域的GPT-3模型。
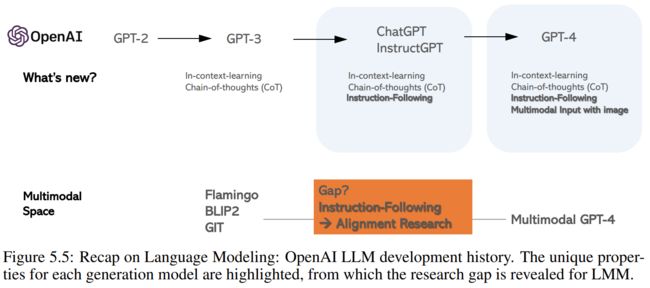
5.1.3 OpenAI Multimodal GPT-4 and Research Gaps
上图显示了GPT4有复杂推理的能力。
回顾OpenAI的大模型,有几个关键的观察结果:(i)GPT-2是BERT时代的自回归对应物,用于预训练然后微调范式。与GPT-2相比,GPT-3 是一个在网络规模的文本语料库上训练的175B模型,它在冻结模型中表现出两个新兴特性:上下文学习和思想链推理(CoT)。(ii)ChatGPT和InstructGPT通过在高质量的教学遵循数据上微调基础语言模型GPT-3/GPT-3.5,并通过人类反馈的强化学习,用奖励模型来改进它们,展示了LLM的教学遵循和与人类意图一致的重要性。(iii)GPT-4不仅提高了以前模型的语言能力,还允许视觉信号作为视觉理解和推理的额外输入。我们看到,新一代模型保持/改进了前一代模型的现有属性,并启用了新的属性。
从GPT-3到GPT-4,我们看到了两个新的属性:指令跟随instruction-following和多模态输入。这揭示了现有LMM(如Flamingo)与多模式GPT-4之间的差距:如何在多模式空间中进行指令跟随和对齐研究。
5.2 Pre-requisite: Instruction Tuning in Large Language Models

Traditional language data:seq2seq数据表示,也是NLP研究中的传统数据格式,其中结构中的任务是隐含的。基于每个数据域,训练各个模型。或者有时一个模型在多个数据域上使用多任务目标进行训练,而不指定任务指令。对于这两种情况,模型很难在零样本模式下推广到新任务,因为它们没有经过训练来理解任务指令,因此无法区分和推广在测试期间要执行的任务。
Instructional language data:最近,研究人员开始在模型训练中明确添加任务指令。一种新的数据格式:指令输入输出三元组。
5.2.1 Instruction Tuning

self-instruct是一种简单有效的方法:人类创建一些示例(即种子示例)作为上下文,并要求LLM(如GPT-3或GPT-4)创建更多遵循提示中所述要求的指令和响应。可以进一步选择机器生成的指令跟随数据,以在下一次数据生成迭代中在上下文学习的提示下进行构建。该过程重复进行,直到收集到给定数量的样本为止。由于API调用相对较低的成本和较高的响应速度(与人工注释相比),自我构造在研究界变得越来越有利。
5.2.2 Self-Instruct and Open-Source LLMs
 作者推荐这篇文章:LLM Tulu
作者推荐这篇文章:LLM Tulu
Quick assessment of LLM chatbots:有这么个数据集:Vicuna-Instructions-80,这是一个包含80个问题的数据集,除了通用指令外,指令还分为8类,包括知识、数学、费米、反事实、角色扮演、通用、编码、写作和常识。
以数据为中心的人工智能:这些开源LLM的开发是以数据为核心的,而不是以模型为中心的。随着训练目标和网络架构与类似GPT的模型变得相似甚至相同,关键的差异因素是数据。
5.3 Instruction-Tuned Large Multimodal Models
Data Creation
三种类型的指令数据:(i)多回合对话,以便用户可以与模型聊天;(ii)详细描述,使得可以从模型生成长形式的响应;以及(iii)复杂推理,它更多地是关于图像的含义,而不是图像内容。
Network Architecture and Training
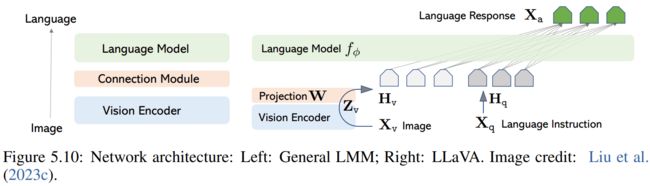
作者花了几段篇幅写LLaVA模型,包括结构和性能。
5.4 Advanced Topics
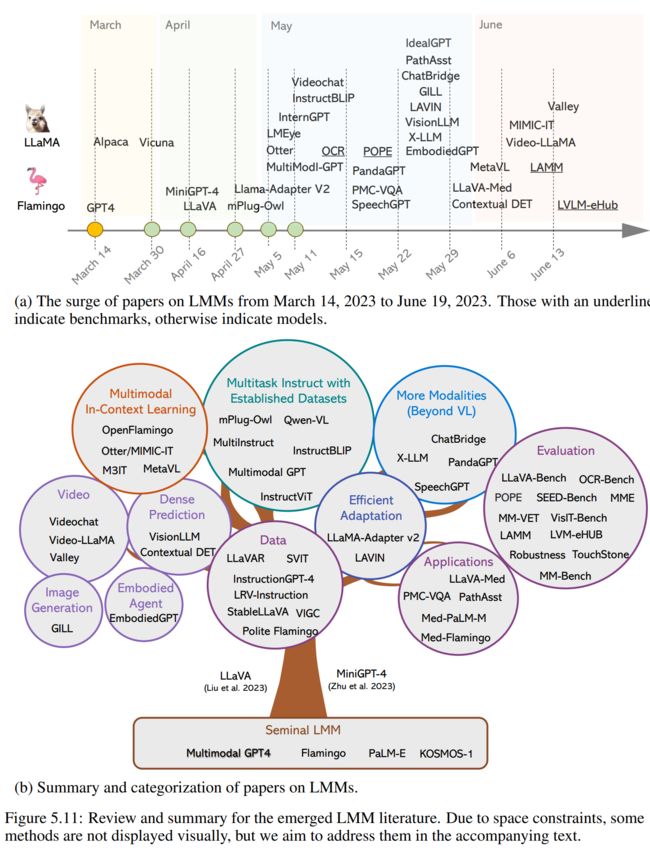
More Modalities (Beyond VL)
除了视觉外扩展更多模态,如语音,3D等。
Improving Visual Instruction Data Quantity and Quality
Multitask Instruct with Established Academic Datasets/Tasks:如InstructionBLIP
Multimodal In-Context-Learning:如OpenFlamingo。涉及两个数据集:Multimodal C4 dataset,MIMIC-IT。
Parameter-Efficient Training:QLoRA,LLaVA codebase。当将LLaVA扩展到33B和65B时,当使用大约150K的指令数据进行训练并使用LLaVA Bench进行评估时,LoRA/QLoRA可以在全模态调谐的情况下实现类似的性能。
Benchmarks

5.5 How Close We Are To OpenAI Multimodal GPT-4?
开源社区已经为各种新功能快速开发了各种模型和原型,例如,LLaVA/Mini-GPT4为构建多模式聊天机器人铺平了道路,其中一些例子再现了OpenAI GPT-4技术报告中的结果;CM3leon、Emu、GILL扩展了LMM用于端到端图像生成,据我们所知,这是当前GPT-4没有表现出的能力。