Concept Learners for Few-Shot Learning笔记(ICLR 2021)
Concept Learners for Few-Shot Learning
- Background —— Few shot learning
-
- meta-learning
- Few-Shot learning 与 传统监督学习的区别
- Related Work —— Prototypical Network
- Motivation
- Method
-
- 符号定义
- 公式原理
- Experimental Results
- References
这是2021年斯坦福大学在ICLR上发表的一篇论文“Concept Learners for Few-Shot Learning”。由于我们人类认知的核心在于 结构化的、可重用的概念,在学习辨别一个新的东西时,我们已经具备了一些关键概念,可以根据以前学习过的概念进行组合进而快速学习这种新东西。例如,当我们学习识别新的鸟类物种时,我们已经具备了对一些关键概念的认识,如翅膀、嘴巴和羽毛。然后我们专注于这些特定的概念,并结合它们来快速学习一个新的物种。而现有的元学习方法缺少这种结构和组合性,当机器具有这种结构化的认知时,就能提高元学习的泛化能力。 受人类认知的结构化形式的启发,本文提出了一种元学习方法——COMET,该方法尝试沿着人类可解释的概念维度学习新的表示以提高模型泛化能力,它能够学习高层概念到半结构化度量空间的映射,并有效地结合概念学习的输出。
Background —— Few shot learning
介绍本文的工作之前,我先详细的介绍一下什么是小样本学习以及什么是元学习。首先举个例子说明一下什么是小样本学习。大多数人分辨不出犰狳和穿山甲,但是只要看一下下图左边的四张图片,正常人都能做出正确的判断。既然人类能够做出正确的分类,那计算机能不能做出正确的分类呢?也就是说如果数据集中如果每个类只有一两个样本,计算机有没有可能做出像人一样的正确分类呢?
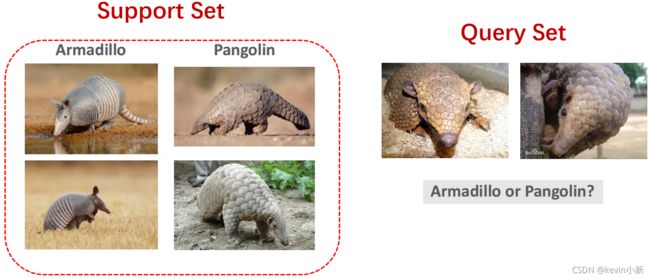
而且我们人类可以
- few-shot: 从很少的图片中抽象出一个新的概念,比如我们可以在看过几张熊猫和长颈鹿图片之后(假设我们之前不知道这两种动物的特征),快速分辨后续图片中的熊猫和长颈鹿。
- zero-shot: 甚至可以不看图片就可以学习到一个新的概念,比如告诉你条纹马叫做斑马。
但是现在的主流的深度学习技术需要大量的数据来训练一个好的模型。当训练集中每个类别的样本数量较少时,也就是在小样本情况下,使用传统的方式训练的模型很容易陷入到过拟合问题中,目前解决小样本问题的主流方法主要都是基于元学习(meta-learning) 的。所以接下来我将介绍一下什么是元学习(meta-learning)。
meta-learning
元学习也叫learn to learn,就是让模型学会学习。举个例子,你带小朋友去动物园,小朋友看到水里有个毛茸茸的动物很喜欢,他从来没见过这种动物,所以他想知道这种动物叫什么。虽然小朋友从来没有见过这种动物,但是他学过怎么区分事物,他有自主学习的能力。现在你给他一些卡片,每张卡片上有一个动物的图片和名字。小朋友既没有见过卡片上的动物也没有见过眼前水里面的动物,但是小朋友很聪明,他把卡片翻一遍就知道水里面的动物是水獭了。他做出判断的依据是眼前水里的动物和卡片上的水獭长得很像。去动物园之前小朋友就有了自主学习的能力,他知道怎么判断事物之间的异同。培养小朋友自主学习区分不同的动物就是meta-learning。小朋友虽然没有见过水獭,但是他只要把卡片翻一遍就知道眼前的动物是水獭了。在meta-learning中水里未知的动物叫做query,给小朋友的卡片是support set。在这个例子中,教小朋友学会区分不同的动物就是meta-learning。特别的当支持集中有N个类别,每个类别包含K个样本,我们称这种任务称为N-way K-shot任务。
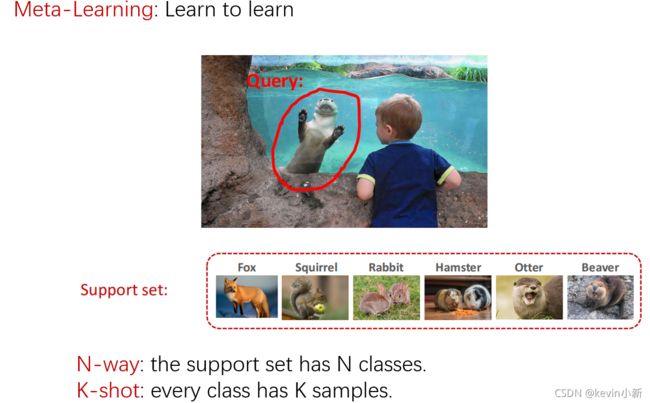
Few-Shot learning 与 传统监督学习的区别
下面我们来看看传统监督学习和小样本学习的区别。传统监督学习是这样的,首先拿一个训练集来学习一个模型,模型学习好之后可以拿模型来做预测。给模型看左边这张测试图片让模型来做预测,这张图片没有出现在训练集中,模型没有见过这张图片,但是测试图片的类别包含在训练集中。这个测试样本是哈士奇,训练样本中有哈士奇这一类,包含上百种哈士奇的图片。虽然模型没见过这张测试图片,但是模型见过上百张哈士奇的图片,所以模型可以很容易判断出测试图片为哈士奇。
小样本学习是一个不同的问题,模型不但没有见过这张query图片,甚至没有见过任何兔子,训练集中没有兔子这个类别,这就是小样本学习与传统监督学习主要的区别。我们需要给模型提供更多的信息,也就是support set,通过对比query和support set中包含的样本,模型可以发现query与第三张图片相似度最高,所以模型就知道query图片为兔子类别。
也就是说对于给定的一个大数据集,小样本学习的目的不是为了让模型学会知道什么是大象什么是老虎,并不是让模型学会识别没见过的大象和老虎,小样本学习的目的是为了让模型学会理解事物的异同,学会区分不同的事物。也就是给两张图片,不是让模型识别两张图片是什么,而是让模型识知道两张图片是相同的事物还是不同的事物。
与传统的监督学习不同,小样本学习将数据集按照类别互斥划分为训练集和测试集,分别进行元训练和元测试两个阶段。
小样本学习大都采用情景式的元学习策略,也就是遵循训练和测试阶段相匹配的原则。由于在测试时通常使用每个类较少的样本,所以在训练时也仅用每个类别中很少的样本进行训练。训练过程中,模型会从数据集中采样出很多有不同类别样本组成的任务,每个任务都会采样得到不同支持集和查询集,模型的目标就是通过支持集的学习学会分辨查询集中的样本与支持集中哪一类最相似。所以总体来看,训练过程中包含了不同的类别组合,通过这种机制学习,使得模型学会了从不同类别样本组成的任务中提取共性部分,比如理解事物的异同、比较样本相似等。所以在元测试阶段面对新类别样本时,该模型也能较好地进行分类。

Related Work —— Prototypical Network
我之前写过关于Prototypical Network的阅读笔记,可以参考这篇文章:Prototypical Networks for Few-shot Learning阅读笔记
本文的方法就是在每个概念学习器中学习一个原型网络结构,最后在通过集成进行分类。所以我们先来了解一下原型网络的原理。
原型网络是一种基于度量学习的小样本分类算法,其将每个类别的支持集样本数据映射到一个嵌入空间中,并且提取他们的“均值”来表示每个类的原型(prototypical),使用欧几里得距离作为距离度量的标准,度量查询集样本 x q x_q xq到每个类原型 c k c_k ck之间的距离,进而进行分类。如图所示,对于支持集中的每个样本,原型网络通过计算特定嵌入空间中支持集样本的均值来表示该类别,对于查询集样本,我们计算该样本到支持集每个类别原型的距离进而进行分类。

Motivation
接下来看一下本文的研究动机,作者提出人类为什么能够快速学习呢,是因为我们人类是以可重用的结构化概念进行学习的,在学习辨别一个新的东西时,我们已经具备了一些关键概念,可以根据以前学习过的概念进行组合进而快速学习这种新东西。例如,当我们学习识别新的鸟类物种时,我们已经具备了对一些关键概念的认识,如翅膀、嘴巴和羽毛。然后我们专注于这些特定的概念,并结合它们来快速学习一个新的物种。而现有的元学习方法缺少这种结构和组合性,当机器具有这种结构化的认知时,就能提高元学习的泛化能力。
受人类认知的结构化形式的启发,本文提出了一种元学习方法,它能够沿着人类可解释的维度进行学习。三个关键方面使得COMET方法具有很强的泛化能力:(1)半结构化表示学习,(2)用概念原型描述的特定于概念的度量空间,以及(3)对多个模型的集成,提高了基础学习的概括能力。这些高级概念可以以完全无监督的方式发现,或者使用外部知识库来定义,并且允许这些概念具有许多噪声。模型可以通过分配局部和全局概念重要性分数来学习这些概念中的哪些子集是重要的。COMET是第一个与领域无关的可解释元学习方法。
如图所示,也就是说对于每一幅图像,我们可以将其分为多个概念,每个概念独立的学习嵌入函数,计算该图片中每个概念到概念原型之间的距离,然后集成所有概念上的信息进而进行分类。

Method
符号定义
首先说明一下符号定义。每个样本中含有N个先验知识的概念 C = { c ( j ) } 1 N C=\left \{c^{(j)}\right \}_1^{N} C={c(j)}1N, j j j代表概念的编号。对于每个概念 c ( j ) ∈ { 0 , 1 } D c^{(j)} \in \left \{0, 1\right \}^{D} c(j)∈{0,1}D都是一个0和1组成的二元向量,维数D为输入图像的维数(例如 3 × 64 × 64 3\times64\times64 3×64×64),其中 c i j = 1 c_i^{j}=1 cij=1表示第 i i i维用于表示第 j j j个概念,也就是说对于一个图像,其中 c i j = 1 c_i^{j}=1 cij=1的部分代表该概念的像素位置,也就是相当于一个筛子,过滤掉不相关的像素点。每个概念 j j j都有一个单独的嵌入函数 f θ ( j ) f_\theta ^{(j)} fθ(j)对概念进行特征提取。
下图本文深度COMET架构图。在每个概念维度上,COMET都使用独立的概念学习器来学习概念嵌入,并将其与概念原型进行比较。概念嵌入函数 f θ ( j ) f_\theta ^{(j)} fθ(j)对应图1中的concept learners,是由深度神经网络参数化的非线性函数。给定一个数据点 x q x_q xq,计算它的概念嵌入,并估计它到每个类的概念原型的距离。然后,通过对概念嵌入和概念原型之间的距离求和来聚合所有概念上的信息。
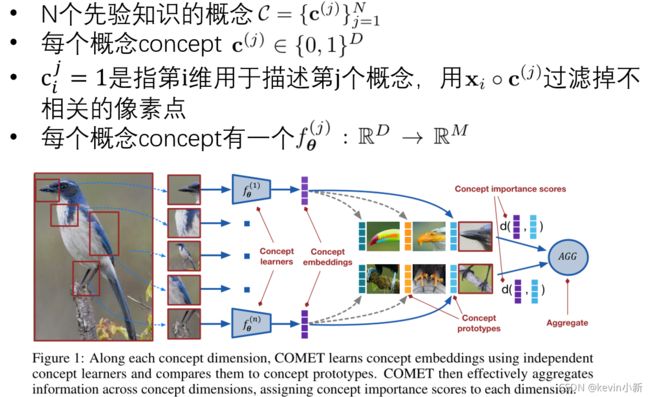
公式原理
下面是本文的计算公式,我们通过公式计算出支持集中每个类别 k k k的第 j j j个概念原型 P k ( j ) P_k^{(j)} Pk(j)。和原型网络计算一样只不过计算的是概念,原型网络计算的是整个图像。
x i ⊙ c ( j ) x_i \odot c^{(j)} xi⊙c(j)表示按位相乘,也就是通过筛子 c ( j ) c^{(j)} c(j)得到每个概念。然后对于每个查询集样本 x q x_q xq,我们通过对查询集每个概念原型j到支持集类别 k k k的概念原型 j j j之间的距离进行求和,也就是分子表示样本 x q x_q xq到支持集类别k的距离;然后在通过softmax函数,将其到支持集中每个类别 k k k之间的距离转换为概率的形式,也就是对于查询集样本 x q x_q xq, P θ ( y = k ∣ x q ) P_\theta(y=k|x_q) Pθ(y=k∣xq)表示模型预测 x q x_q xq为 k k k类的一个概率,然后再通过交叉熵损失函数 L θ = − l o g P θ ( y = k ∣ x q ) L_\theta=-log P_\theta (y=k|x_q) Lθ=−logPθ(y=k∣xq)进行参数的梯度更新。

Experimental Results
作者用三个完全不同的领域:计算机视觉、自然语言处理和生物学,来评估COMET模型的性能。
在计算机视觉领域,作者使用的是CUB数据集,它是细粒度的鸟类数据集。
在NLP领域,作者将COMET应用于由新闻文章组成的基准文本分类数据集Reuters。 在生物学领域,作者使用了一个跨器官细胞类型分类任务和数据集Tabula Muris。
对于CUB数据集,作者根据基于部件的注释定义概念,比如鸟的嘴、翅膀、尾巴等。对于Reuters数据集,作者对每个单词根据wordNet层次结构中的上位词进行概念的定义。对于Tabula Muris数据集,作者使用基因本体定义概念,这是一种在层次结构词汇表中描述基因功能角色的资源。
显示了本文方法的结果,可以看出本文方法的优越性。

为了证明COMET的性能确实来自概念学习者而不是额外的权重,作者将COMET与原型网络的集成进行比较,并进一步评估COMET在所有概念中共享权重的性能表2是作者在每个概念原型之间共享参数,ProtoNetEns表示使用多个原型网络进行集成学习。

下图显示了概念数量对于模型预测准确率的影响,对于CUB数据集,作者根据其可见性频率添加概念,而在Tabula Muris中,随机选择一些概念进行添加。随着概念数量的增多,模型的准确率也逐渐的增加。
为了证明本文的方法对大量重叠概念的鲁棒性,作者通过将概念数量扩展到1500个,从而允许许多冗余关系。即使在这种情况下,COMET与从单个级别获得的190个概念相比,也略微改善了结果。这些结果表明,即使在概念数量较少、不完整以及存在许多重叠和冗余概念的情况下,COMET的性能也优于其他方法

为了证明本文方法COMET能够正确识别重要的类级概念,作者在CUB数据集上进行了实验。也就是给定一个类别的鸟,计算所有样本的同一个概念到相应原型概念之间的平均距离,选出贡献度最大的鸟类概念。对于每种鸟类,COMET 都会找到最相关的概念。例如,“嘴”被选为“长尾小鹦鹉”最相关的概念,长尾小鹦鹉以其近乎圆形的嘴而闻名;“腹部”代表的有“栗颊林莺”,因腹部有老虎条纹而闻名;而“翠鸟”确实有其独特的“前额”,其蓬松的羽冠位于头顶。这证实了COMET正确识别了重要的类级概念。

该图是使用局部概念和全局概念对给定的图像进行距离排序的一个实验,给定一个固定的概念,应用COMET根据图像概念到概念原型的距离对图像进行排序。我们可以看出,使用局部概念可以很好地表达概念原型图像,正确的反映出相关的概念。而使用整体图像作为概念进行排序往往反映背景相似性,不能提供直观的解释。

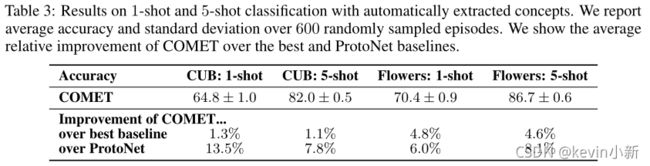
COMET在将人类验证的概念作为外部知识提供方面取得了显著的成果,作者也研究了COMET在自动推断概念方面的性能作者使用自动生成概念的方法进行试验。下图是模型在CUB数据集上生成的30个概念。使用自动生成的概念进行试验,结果仍然比对比方法的结果好,这也进一步证明了本文方法的有效性。

References
原文链接
代码github链接
COMET | 概念学习使机器具有人的思维方式
其他学者对这篇论文的视频解读
few-shot learning基本概念
Prototypical Networks for Few-shot Learning阅读笔记